구성요소
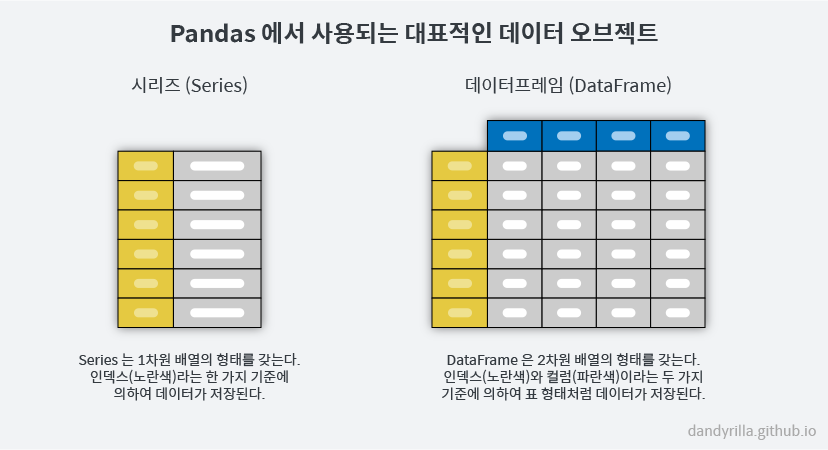
DataFrame
- column, row로 구성되는 2차원의 데이터셋
Series
- 1개의 컬럼값으로 구성된 1차원의 데이터 셋
read_csv()
- csv를 읽어온다.
sep을 이용해 delimiter설정 가능. default = ','
titanicTrain = pd.read_csv('../train.csv')head()
- 앞줄만 보기
titanicTrain.head(3)
dictionary to DataFrame
dic1 = {'Name': ['Chulmin', 'Eunkyung','Jinwoong','Soobeom'],
'Year': [2011, 2016, 2015, 2015],
'Gender': ['Male', 'Female', 'Male', 'Male']
}
# 딕셔너리의 키값이 컬럼명이 된다.
# 딕셔너리를 dataFrame으로 변환
dfDic = pd.DataFrame(dic1)
print(dfDic)
print("#"*30)
# 새로운 컬럼명 추가
dfDic = pd.DataFrame(dic1, columns=['Name','Year','Gender','Age'])
print(dfDic)
print("#"*30)
# 인덱스를 새로운 값으로 할당
dfDic = pd.DataFrame(dic1, index=['one','two','three','four'])
print(dfDic)
print("#"*30)
# 컬럼정보
print(dfDic.columns)
# 인덱스 정보
print(dfDic.index)
# 실제 인덱스 array조회
print(dfDic.index.values)추출
DataFrame의 []연산자 안에 한개의 컬럼만 입력하면 Series 객체 반환
series =titanicTrain['Name']
print(series.head())
print('type: ' , type(series)) # type: <class 'pandas.core.series.Series'>DataFrame의 []연산자 안에 여러 컬럼배열 입력하면 해당 컬럼만 있는 DataFreme 반환
series2 = titanicTrain[['Name', 'Age']]
print(series2.head())
print('type: ' , type(series2)) #type: <class 'pandas.core.frame.DataFrame'>
print("#"*30)
# 1개여도 배열 안에 넣으면 DataFrame 타입으로 리턴
series =titanicTrain[['Name']]
print(series.head())
print('type: ' , type(series)) #type: <class 'pandas.core.frame.DataFrame'>
print("#"*30)shape
- DataFrame, Series의 크기
print(titanicTrain.shape)
print(series.shape)info
- DataFrame의 컬럼명, 데이터 타입, null건수, 데이터 건수 등
print(titanicTrain.info())describe
- 데이터 값들의 평균, 표준편차(std), 4분위 분포도 제공 (null값은 빠져서 계산)
print(titanicTrain.describe())
print("#"*30)vaule_counts()
- 동일한 개별데이터 값이 몇건이 있는지(개별 데이터 값의 분포도)
- Series객체에서만 호출될 수 있다. 각각의 개별데이터값은 유일한 값이기 때문에 인덱스로 사용된다.
placeCount = titanicTrain['Age'].value_counts()
print(placeCount)
print("#"*30)sort_values()
by=정렬할 컬럼,ascending=True/False
print(titanicTrain.sort_values(by=['Name','Age'],ascending=False).head())타입 변환
list to DataFrame
dfList = pd.DataFrame(list, columns=colNames)
ndarray to DataFrame
dfArray = pd.DataFrame(array, columns=colNames)
dict to DataFrame
dfDict = pd.DataFrame(dict)
DataFrame to ndarray
- DataFrame객체의 values속성을 이용해 변환
DataFrame to list
-
DataFrame -> array -> list 순으로 변환
-
ndarray.tolist()
DataFrame to Dictonary
- DataFrame.to_dict()
DataFrame 데이터 삭제 :: drop()
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
-
axis
- row 삭제시 0, 컬럼 삭제시 1
-
inplace
- 원본 데이터프레임은 유지하고 드롭된 객체를 리턴할 경우 False
Index
-
DataFrame, Series의 레코드를 고유하게 식별하는 객체
-
DataFrame.index, Series.index를 통해 추출
-
Series 객체에 연산함수를 적용할 때 Index는 연산에서 제외됨. 오직 유니크 식별용으로 사용
-
reset_index(): 새롭게 인덱스를 연속 숫자형으로 할당하며 기존 인덱스는index라는 새로운 컬럼 명으로 추가
