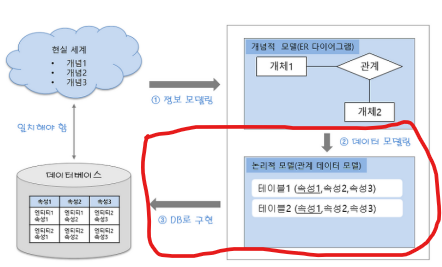
데이터 모델링은 개념적 -> 논리적 -> 물리적 단계로 이루어지는데,
오늘은 완성된 개념적 모델링(ER-Diagram)을 바탕으로
논리적 모델링(관계 데이터 모델)하는 방법과 개념에 대해 알아봅시다!
DB로 구현 직전!!까지
이미지 출처 - https://mangkyu.tistory.com/27
논리적 모델링
-
DB 시스템에서 데이터를 저장하는 이론적인 방법
-
데이터베이스에 데이터가 어떻게 구조화되어 저장되는지 결정
-
가장 많이 사용되는 모델
-관계 데이터 모델 (relational data model)
관계 데이터 모델
- 수학의 집합이론에 그건하여 탄탄한 이론적 토대
- 관계 데이터 모델이 적용된 SQL 언어는 비절차적인 언어로 원하는 데이터를 쉽게 표현
절차지향 언어: 명령어가 순차적으로 실행하는 것에 중점
장점 - 프로그램 흐름 파악이 쉽다. 순서대로 실행되기 때문에 속도가 빠름
단점 - 유지보수 어려움, 코드 순서가 바뀌면 동일한 결과 보장 어려움
객체지향 언어: 기능별로 모듈화, 중복 연산X, 모듈 재활용
객체간 관계와 기능에 중심을 둔 언어
절자치향 언어의 단점을 보완하기 위해 생긴 언어라고 해도 객체지향이 무조건
우수한 것은 아님, 특징이 다름
어느 곳에 어떻게 활용할 것인가에 따라서 적절한 방식이 있음
비절차적 언어: 개발자가 처리절차를 정하지 않고, 원하는 결과를 정의하고 요청하는 언어- 관계 데이터 모델은 데이터를 2차원 테이블 형태인 릴레이션으로 표현
2차원 테이블 형태 -> 데이터를 행과 열의 형태로 표현하여 관계를 나타내는 방법- ex. 고객 정보는 고객 릴레이션, 주문 정보는 주문 릴레이션, 상품 정보는 상품 릴레이션

관계 데이터 모델의 개념을 크게 4가지로 나누어 알아보자.
- 릴레이션
- 릴레이션 스키마와 인스턴스
- 릴레이션 특징
- 관계 데이터 모델
릴레이션
- 행과 열로 구성된 테이블
- "관계"라고 하지 않음
ER-Model에선 Relation이 관계임
관계 데이터 모델에서 관계는 Relationship 이다.
릴레이션 '내'에서 생성되는 관계 또는 릴레이션 간에 생성되는 관계이다.
릴레이션 스키마와 인스턴스
- tuple(논리적) = row(물리적) = 행
단일 행, Cadinality는 튜플의 개수- 속성 = Attribute(논리적) = Colomn(물리적) = 열
단일 열, Entity의 특성이나 속성을 의미
Dgree는 Attribute의 개수
릴레이션 모델에서 모든 속성 값은 원자값(Atomic Value)이어야 한다.
이는 속성 값이 더 이상 분해되지 않는 최소한의 단위여야 한다는 것을 의미함- 스키마
릴레이션에 어떤 정보가 담길지 정의, 테이블의 헤더
표기법: 릴레이션 이름(속성A, 속성B, ...)
ex. Customer(이름, 주소, 전화번호, 포인트, 등급)- 인스턴스
릴레이션의 스키마에 실제로 저장된 데이터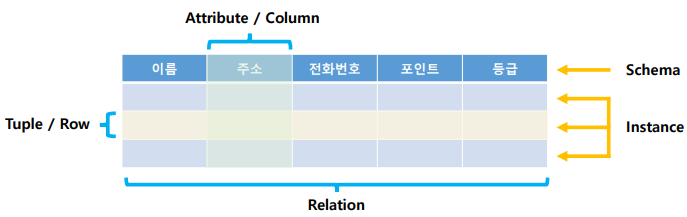
릴레이션(Relation) 특징
- 속성은 단일 값을 가짐
- 속성은 서로 다른 이름을 가짐
- 한 속성의 값은 모두 같은 도메인 값을 가짐
- 속성의 순서는 상관 없음
- 릴레이션 내의 중복된 튜플 허용 안됨
- 튜플 순서 상관 없음
+도메인(Domain)이란??
1. 릴레이션의 각 속성이 가질 수 있는 값의 집합
2. 속성의 데이터 타입과 제약 조건을 정의하는 개념
ex1. "이름"이라는 속성의 도메인은 문자열의 집합
ex2. "나이"라는 속성의 도메인은 양의 정수의 집합
ex3. "성별"이라는 속성의 도메인은 남자와 여자 두 가지 값 중 하나만을 가져야 함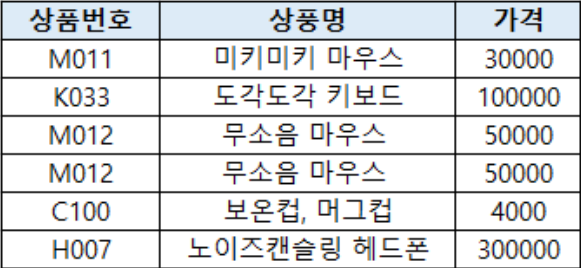
위 이미지의 경우 속성은 단일값을 가져야 한다는 것을 위반(보온컵, 머그컵)하였고,
릴레이션 내의 중복된 튜플(M012, 무소음 마우스, 50000)이 있다.
마무리
오늘 배운 관계 데이터 모델을 간단히 정리해보자!
스키마는 릴레이션의 구조를 정의하며, 열(Column)의 이름, 데이터 타입 및 제약 조건 등을 정의한다는 것을 알 수 있다.
스키마는 릴레이션의 내포를 나타냄인스턴스는 릴레이션에 포함된 실제 데이터 값들을 의미하는 것으로 외연이라고도 부른다는 것을 알 수 있다.
외연: 릴레이션에 포함된 모든 행(row)의 집합을 의미relation ,attribute, tuple은 논리적인 경우에 부르고,
table, column, row는 물리적인 경우에 부른다고 알고 있으면 외우기 편하다.
이전 글에서 서술한 것을 다시 한 번 정리해 보자면,
개념적 모델링인 ER-Model에서의 카디널리티(관계 대응 수)와
논리적 모델링인 튜플의 개수를 나타내는 카디널리티는 전혀 다르다.
데이터베이스는 공부할 때 마다 느끼는 거지만..
동음이의어(카디널리티 등)도 있고..
동형이의어(튜플,로우,행 등)도 많아서 너무 헷갈린다.
조금이라도 헷갈린다면,
계속해서 내 머릿속에 개념이 바로 잡힐 수 있게!!
벨로그를 작성할 때 만큼이라도 스스로에게 강조를 해야겠다.
끝!!

혹시 지금 취업하셨나용....??