자연어처리를 하기에 앞서 가장 데이터를 분석하겠다는 사람이 가장 먼저 접하게되는 가장 기본적인 기술이 크롤링이다. Beautifulsoup이라는 모듈을 사용한다.
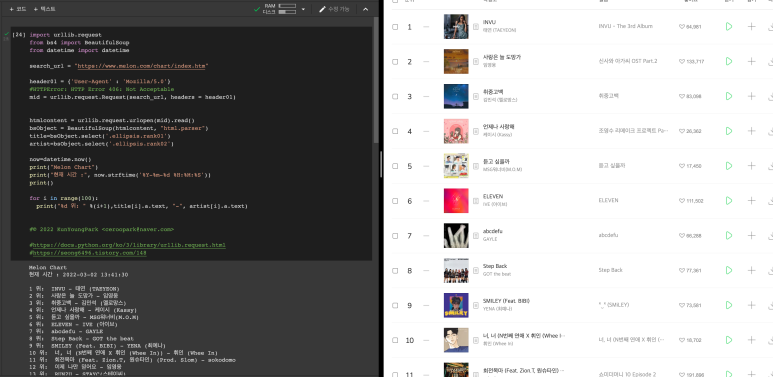
import urllib.request
from bs4 import BeautifulSoup
from datetime import datetime
search_url = "https://www.melon.com/chart/index.htm"
header01 = {'User-Agent' : 'Mozilla/5.0'}
#HTTPError: HTTP Error 406: Not Acceptable
mid = urllib.request.Request(search_url, headers = header01)
htmlcontent = urllib.request.urlopen(mid).read()
bsObject = BeautifulSoup(htmlcontent, "html.parser")
title=bsObject.select('.ellipsis.rank01')
artist=bsObject.select('.ellipsis.rank02')
now=datetime.now()
print("Melon Chart")
print("현재 시간 :", now.strftime('%Y-%m-%d %H:%M:%S'))
print()
for i in range(100):
print("%d 위: " %(i+1),title[i].a.text, "-", artist[i].a.text)
© 2022 KunYoungPark <ceroopark@naver.com>
#https://docs.python.org/ko/3/library/urllib.request.html
#https://seong6496.tistory.com/148코드를 입력하세요
"406 Not Acceptable(접수할 수 없음)"
처음 코딩 크롤링 접근을 했을 때 위와 같은 오류가 발생하였다.
구글링 통해서 확인한 바로는 기계적 크롤링으로 인한 서버 과부화 문제로
크롤링이 막혀있다는 것 이었다.
이에 따라, 서버에 크롤링을 하는 주체가 사람이라고 값을 넣어줘야한다는데,
이게 위 코드의
header01 = {'User-Agent' : 'Mozilla/5.0'}
#HTTPError: HTTP Error 406: Not Acceptable
mid = urllib.request.Request(search_url, headers = header01)
부분이다.
참조 사이트
https://docs.python.org/ko/3/library/urllib.request.html
https://seong6496.tistory.com/148~~

저도 개발자인데 같이 교류 많이 해봐요 ㅎㅎ! 서로 화이팅합시다!