데이터 살펴보기
파이토치를 활용하여 20개의 심슨 캐릭터들 사진에 대한 학습을 통한 객체 탐지를 진행해볼 계획이며, 데이터셋은 Pascal VOC와 COCO와 같은 형식으로 데이터셋 이미지 파일에 대한 정보를 담고 있는 파일인 annotation.txt가 포함되어 있으며, 파일에는 각 이미지의 경로와 해당 이미지에 대한 객체의 위치, 클래스의 정보가 저장되어 있다. 이 정보를 이용하여 신경망 모델을 학습시키거나 테스트할 때 입력 데이터와 정답 데이터를 생성할 수 있다.
Yolo 직접 구현
YOLO 알고리즘을 PyTorch로 구현하기 위해서는 다음과 같은 단계를 거쳐야 한다.
1. 데이터셋 구성하기: YOLO는 Pascal VOC나 COCO와 같은 대형 데이터셋을 사용하여 객체 탐지를 수행한다. 따라서, 이러한 데이터셋을 활용하여 구성한다.
2. 네트워크 구성하기: YOLO는 CNN(Convolutional Neural Network)을 기반으로 하고 있으며, 네트워크 아키텍처는 Darknet이다. 따라서, PyTorch에서 Darknet을 구현하고, YOLO 모델을 이를 기반으로 만들어야 한다.
3. 모델 학습하기: 모델을 학습하기 위해서는 데이터셋과 학습 파라미터가 필요하다. PyTorch에서는 DataLoader와 같은 유틸리티를 사용하여 데이터셋을 로드하고, loss 함수와 optimizer를 정의한다.
4. 모델 평가하기: 학습된 모델을 평가하기 위해서는 테스트 데이터셋을 사용해야 한다. 이를 위해서는 평가 지표를 정의하고, 테스트 데이터셋에서 모델을 실행하여 결과를 분석해야 한다.
5. 모델 배포하기: 최종적으로 학습된 모델을 배포하기 위해서는 PyTorch 모델을 ONNX 형식으로 변환한 후, 원하는 플랫폼에서 실행해야 한다.
Yolo 객체탐지 알고리즘의 기본 아이디어
YOLO의 기본 아이디어는 이미지를 그대로 입력으로 사용하고, 네트워크가 이미지 내에서 bounding box 좌표와 클래스를 예측하는 것이다.(레이블 구성시 클래스 네임 뿐만 아니라 좌표를 같이 구성해야함) YOLO는 이미지를 여러 그리드 셀로 나누고, 각 셀마다 bounding box를 예측한다. 이 때 예측된 bounding box 좌표는 해당 셀을 기준으로 상대적인 좌표로 예측된다. 이렇게 예측된 bounding box는 후처리 과정에서 조정되어 최종 bounding box 좌표가 결정된다.
데이터 다운로드 및 개요
kaggle에서 직접 데이터를 다운받았으며, 다음과 같은 구성을 가지고 있다.
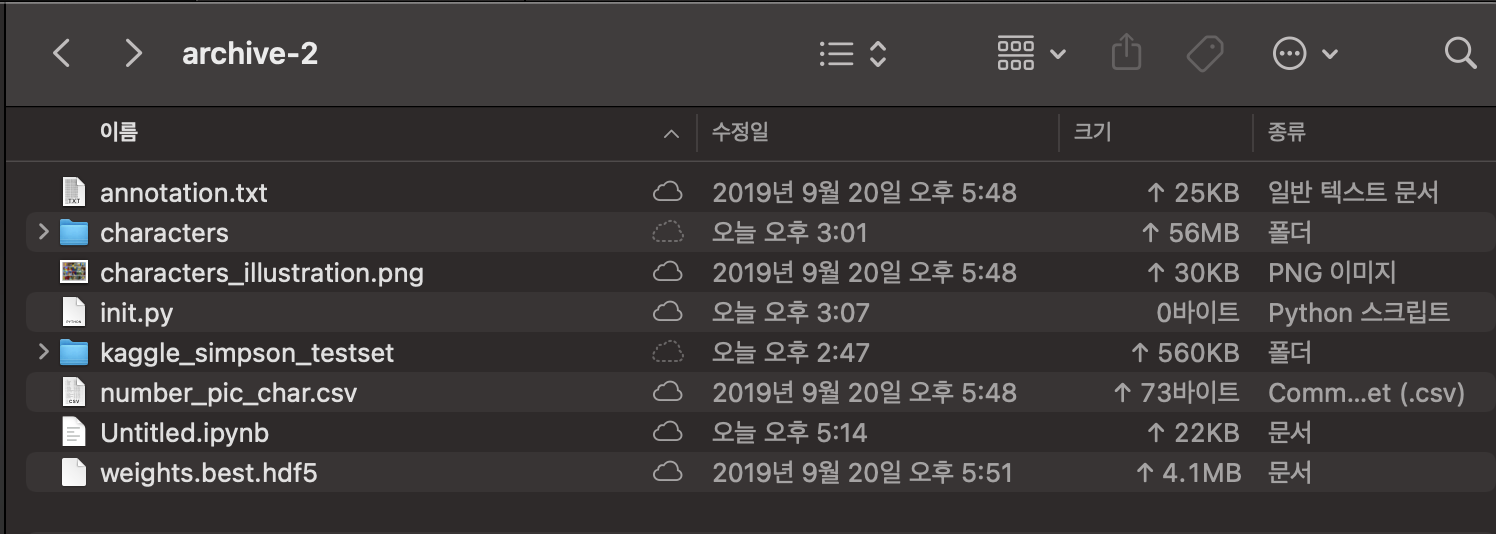 characters 디렉토리는 name을 characters로 수정하였으며(이유는 뒤에), init.py, jupyter file은 직접 생성한 파일이다. annotation.txt는 위에서 설명한 그대로이며, testset디렉토리 내의 데이터로 테스트 성능평가를 진행하면 될 것으로 보인다. characters 폴더내엔 20개의 클래스별 디렉토리가 있으며, 해당 디렉토리 안에 이미지 파일들이 존재한다.
characters 디렉토리는 name을 characters로 수정하였으며(이유는 뒤에), init.py, jupyter file은 직접 생성한 파일이다. annotation.txt는 위에서 설명한 그대로이며, testset디렉토리 내의 데이터로 테스트 성능평가를 진행하면 될 것으로 보인다. characters 폴더내엔 20개의 클래스별 디렉토리가 있으며, 해당 디렉토리 안에 이미지 파일들이 존재한다. annotation 텍스트 파일에는 다음과 같이 사진 하나하나의 경로, 좌표, 클래스네임이 적혀있으며 첫 경로의 디렉토리 이름이 characters이므로 수정을 했다.
annotation 텍스트 파일에는 다음과 같이 사진 하나하나의 경로, 좌표, 클래스네임이 적혀있으며 첫 경로의 디렉토리 이름이 characters이므로 수정을 했다.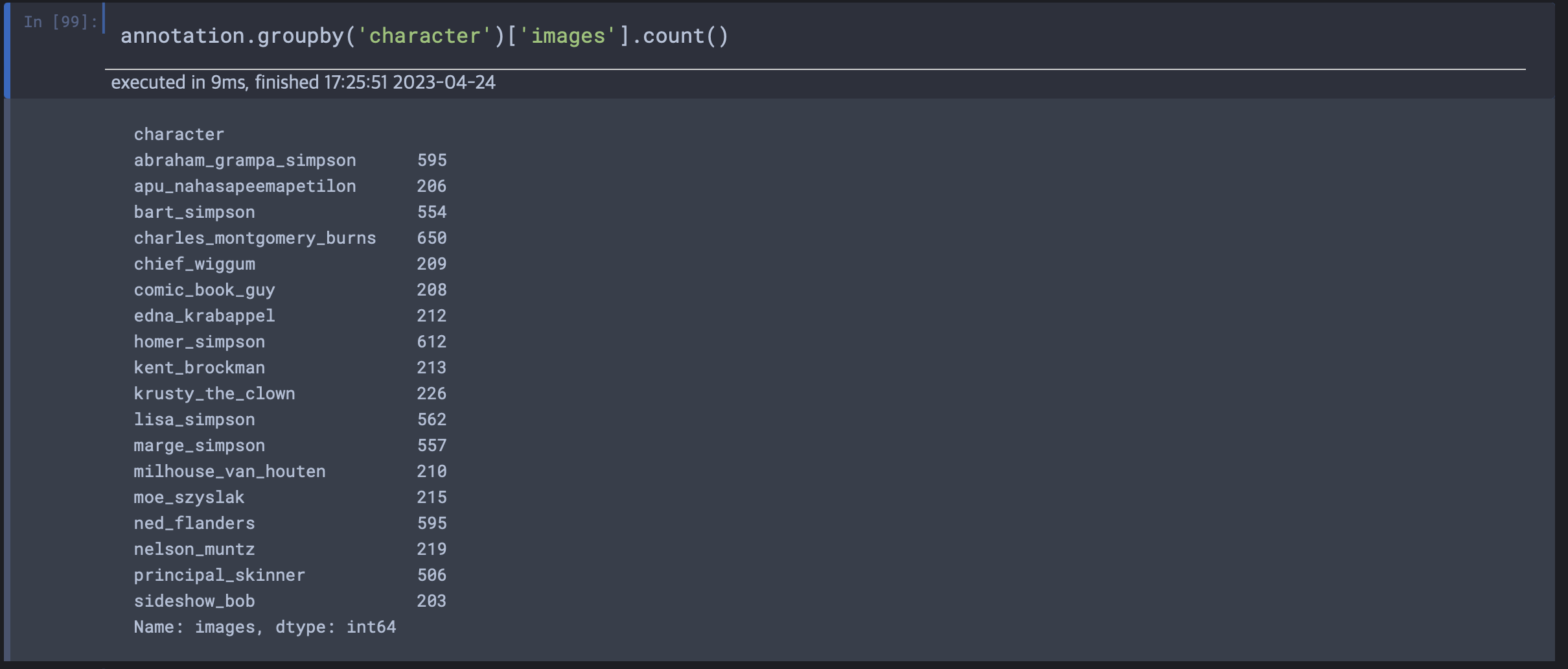 클래스 별로 데이터 수가 균등하지 않았다. 미리 파악하고 후에 augmentation할지 결정해야겠다
클래스 별로 데이터 수가 균등하지 않았다. 미리 파악하고 후에 augmentation할지 결정해야겠다
커스텀 Dataset 구성
from PIL import Image
class CustomDataset(Dataset):
def __init__(self, file_path, img_size=416):
self.data = []
self.img_size = (img_size, img_size)
with open(file_path, 'r') as f:
for line in f:
parts = line.strip().split(',')
img_path = parts[0]
x1, y1, x2, y2 = map(int, parts[1:5])
label = parts[5]
self.data.append((img_path, x1, y1, x2, y2, label))
def __len__(self):
return len(self.data)
def __getitem__(self, index):
img_path = os.path.join(self.data[index][0])
img = cv2.imread(img_path)
h, w, _ = img.shape
img_resized = cv2.resize(img, self.img_size)
#(416, 416, 3)으로.
#bounding box수정
resized_height, resized_width = self.img_size
resize_ratio = min(resized_width / w, resized_height / h)
x1 = self.data[index][1] * resize_ratio # Upper left x
y1 = self.data[index][2] * resize_ratio # Upper left y
x2 = self.data[index][3] * resize_ratio # Lower right x
y2 = self.data[index][4] * resize_ratio # Lower right y
img_input = img_resized[:, :, ::-1].transpose((2, 0, 1)).copy()
img_input = torch.from_numpy(img_input).float().div(255.0)
label = np.array([x1, y1, x2, y2, self.data[index][5]])
return img_input, label파이토치에서 제공하는 DataLoader를 이용해 미니배치 크기로 데이터를 로드하여 학습을 진행하기 위해서는 DataLoader모듈이 사용가능한 데이터셋을 구성해야한다. 이를 위해 파이토치는 Dataset모듈을 지원한다. 이를 서브클래싱하여 직접 CustomDataset을 만들어야 한다.
CustomDataset 구성 형식
파이토치에서 Dataset으로 custom dataset을 구성할 때, init, len, getitem 함수를 구현해야 한다.
-
init 함수는 Dataset 객체를 초기화하는 역할을 하며, 이 함수에서는 데이터셋의 경로, 라벨, 이미지 크기 등의 초기화를 수행한다. 즉 init에서는 annotation.txt에 적힌 데이터를 읽어 list에 순서대로 구성해야한다.
-
len 함수는 데이터셋의 총 데이터 개수를 반환한다.
-
getitem 함수는 데이터셋에서 데이터와 라벨을 가져오는 역할을 한다. 인덱스를 입력받아 해당 인덱스의 데이터와 라벨을 반환한다. 이 함수에서는 데이터와 라벨을 불러오는 방식을 지정한다. 각각의 img데이터를 텐서화하여 담아내고, 라벨과 좌표는 같이 묶는다.
이렇게 구현된 custom dataset은 DataLoader에서 사용되어 모델 학습에 활용된다.. DataLoader는 Dataset에서 데이터를 불러오는 방법과 배치 크기 등을 지정하여 학습 시에 효율적으로 데이터를 로드할 수 있도록 도와주는 역할을 한다.
init메서드 구성
self.data에 모든 데이터를 담아야 하므로 빈 데이터를 초기화하고, 데이터셋 내의 각각의 이미지는 모두 크기가 다르므로, 416x416으로 수정하기 위한 img_size=416을 초기화한다. annotation.txt파일 경로를 받아 읽어들이며, for문을 통해 모든 줄에 대해서 데이터요소를 구성하여 리스트에 주입한다.
getitem메서드 구성
getitem메서드의 경우 하나의 인덱스를 입력인자로 받아 하나의 데이터를 전처리하는 과정을 짜면 된다. img를 cv2를 활용하여 numpy형식으로 불러들여오고 416x416으로 resize한다. 이때 bounding box의 좌표또한 비례하게 수정해야한다. 기존의 shape와 resize_shape를 활용하여 비율을 구하고 각 좌표값을 수정하여 변수에 담아둔다.
img_input 즉, 최종적으로 텐서화 하기 위해 채널의 차원을 앞으로 땡겨오기 위해 transpose를 사용하여 재구성한다.
첫 코딩때는 음수문제가 발생하여 에러가 발생했었는데, img_input에 대한 np.array와 np.transpose() 메서드가 반환한 배열에 대해 일부분이 부호가 반대인 음수 스트라이드(stride)가 있어서 생긴 오류이다.
이 오류를 해결하기 위해서는, 넘파이 배열을 복사해 새로운 배열을 만든 후 사용해야 한다.(copy())
그 후 numpy배열을 torch.tensor화 하고 정규화를 위해 값들에 255.0을 나누어주고, label의 경우 좌표값 4개와 class이름을 함께 묶어 구성하여 데이터와 레이블을 함께 리턴했다.
참고자료
Yolo의 아이디어: https://machinethink.net/blog/object-detection/
