MNIST
고등학생과 미국 인구조사국 직원들이 손으로 쓴 70,000개의 숫자 이미지를 모은 데이터 셋

MNIST
MNIST 데이터셋 불러오기
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1, as_frame=False)
mnist.keys()
70,000개의 이미지가 있고, 각 이미지에는 784개(이미지가 28x28 픽셀이기 때문)의 특성이 있다.
개개의 특성은 0(흰색)부터 255(검은색)까지의 픽셀 강도를 나타낸다.
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
some_digit = X[0]
some_digit_image = some_digit.reshape(28, 28)
plt.imshow(some_digit_image, cmap=mpl.cm.binary)
plt.axis("off")
plt.show()샘플의 특성 벡터를 추출하여 28x28 배욜로 크기를 바꾸고 맷플롯립의 imshow() 함수를 사용해 데이터셋에서 이미지 하나를 확인한다.
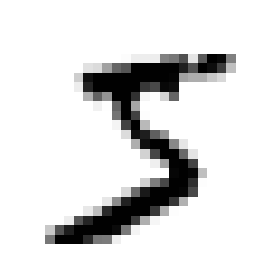
y[0]를 출력하여 위 이미지의 레이블이 문자열 '5'인 것을 알 수 있다.
레이블 y를 정수로 변환하기 위해 y = y.astype(np.uint8) 코드를 실행한다.
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]MNIST 데이터셋을 train set(앞쪽 60,000개 이미지)와 test set(뒤쪽 10,000개 이미지)으로 나눈다.
이진 분류기 훈련
binary classifier
예) MNIST에서 숫자 5를 식별하는 분류기 → '5'와 '5 아님' 두 개의 클래스를 구분한다.
y_train_5 = (y_train == 5) # 5는 Ture고, 다른 숫자는 모두 False
y_test_5 = (y_test == 5)from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(max_iter=1000, tol=1e-3, random_state=42)
sgd_clf.fit(X_train, y_train_5)분류 모델 선택 : 사이킷런의 SGDClassifier 클래스를 사용해 SGD 분류기를 사용하여 훈련시킨다.
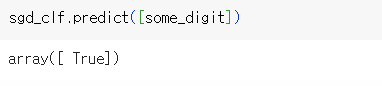
위 모델을 사용해 some_digit의 이미지를 감지한 결과, 분류기는 이 이미지가 5를 나타낸다고 추측했다(True).
성능 측정
교차 검증을 사용한 정확도 측정
사이킷런의 cross_val_score() 함수로 교차 검증을 구현할 수 있다.
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")
- train set를 k개(3개)의 폴드로 나누고, 각 폴드에 대해 예측을 만들고 평가하기 위해 나머지 폴드로 훈련시킨 모델을 사용한다.
- 실행 결과 모든 교차 검증 폴드에 대해 85% 이상의 정확도를 나타내었다.
from sklearn.base import BaseEstimator
class Never5Classifier(BaseEstimator):
def fit(self, X, y=None):
pass
def predict(self, X):
return np.zeros((len(X), 1), dtype=bool)모든 이미지를 5인지 식별하는 분류기로 비교하면
never_5_clf = Never5Classifier()
cross_val_score(never_5_clf, X_train, y_train_5, cv=3, scoring="accuracy")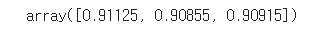
모델이 90% 이상의 정확도를 보이는 것을 알 수 있다.
( 이미지의 10% 정도만 숫자 5이기 때문에 무조건 5가 아니라고 예측한다면 정확히 맞출 확률이 90%가 된다. )
⇒ 어떤 클래스가 다른 것보다 월등히 많은 불균형한 데이터셋을 다룰 때, 정확도를 성능 측정 지표로 사용하는 것은 바람직하지 않을 수 있다.
오차 행렬
confusion matrix
오차 행렬의 기본적인 아이디어는 클래스 A의 샘플이 클래스 B로 분류된 횟수를 세는 것이다.
오차 행렬을 만들기 위해 실제 타깃과 비교할 수 있도록 예측값을 만들어야 한다. → cross_Val_predict() 함수 사용
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)cross_val_predict() 함수는 cross_val_score() 함수처럼 k-fold cross validation을 수행하지만, 평가 점수를 반환하지 않고 각 테스트 폴드에서 얻은 예측을 반환한다.
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_5, y_train_pred)confusion_matrix() 함수를 사용해 오차 행렬을 만든다.
타깃 클래스 y_train_5와 예측 클래스 y_train_pred를 넣고 함수를 호출한다.

- 오차 행렬의 행은 실제 클래스를 나타내고, 열은 예측한 클래스를 나타낸다.
- 이 행렬의 첫 번째 행은 5가 아닌 이미지(음성 클래스, negative class)에 대한 것으로, 53892개를 '5 아님'으로 정확하게 분류했고(true negative), 나머지 687개를 '5'라고 잘못 분류했다(flase positive).
- 두 번째 행은 '5' 이미지(양성 클래스, positive class)에 대한 것으로, 1891개를 '5 아님'으로 잘못 분류했고(false negative), 나머지 3530개를 정확히 '5'라고 분류했다(true positive).
y_train_perfect_predictions = y_train_5
confusion_matrix(y_train_5, y_train_perfect_predictions)
완벽한 분류기일 경우, true positive와 true negative만 가지고 있을 것이므로 오차 행렬의 주대각선만 0이 아닌 값이 된다.
오차 행렬이 많은 정보를 제공해주지만 가끔 더 요약된 지표가 필요할 수 있다. 양성 예측의 정확도를 확인할 수 있는데, 이를 분류기의 정밀도(precision)라고 한다.
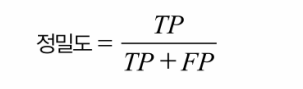
FP는 true positive의 수, FP는 false positive의 수를 의미한다.
정밀도는 재현율(recall)이라는 또 다른 지표와 같이 사용하는 것이 일반적이다.
재현율은 분류기가 정확하게 감지한 양성 샘플의 비율로, 민감도(sensitivity) 또는 true positive rate(TPR)라고도 한다.

FN은 false negative의 수를 의미한다.
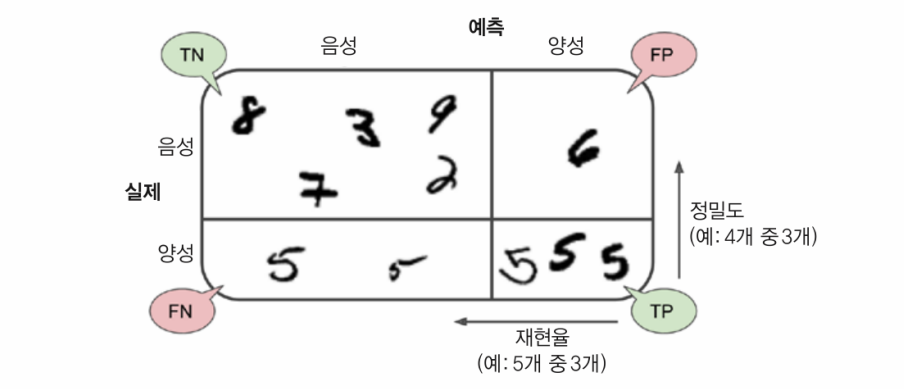
( △ 오차 행렬 참고 )
정밀도와 재현율
사이킷런은 정밀도, 재현율 등 분류기의 지표를 계산하는 여러 함수를 제공한다. → precision_score, recall_score
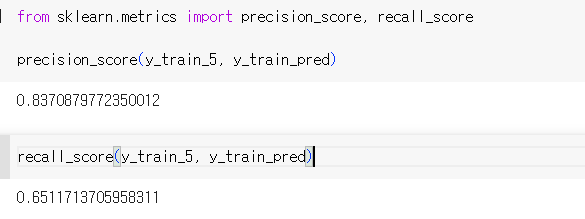
두 분류기를 비교할 때, 정밀도와 재현율을 F1 score라고 하는 하나의 숫자로 만들면 편리하다.
F1 score는 밀도와 재현율의 조화 평균을 의미한다.


f1_score() 함수를 호출하여 F1 score를 계산할 수 있다.
from sklearn.metrics import f1_score
f1_score(y_train_5, y_train_pred)
정밀도와 재현율이 비슷한 분류기에서는 F1 score가 높지만 이것이 항상 바람직한 것은 아니며, 상황에 따라 정밀도가 중요할 수도 있고 재현율이 중요할 수도 있다.
일반적으로 정밀도를 올리면 재현율이 줄고, 그 반대도 마찬가지로 나타나는데 이를 정밀도/재현율 트레이드오프라고 한다.
SGDClassifier의 경우 decision function을 사용하여 각 샘플의 점수를 계산하고 이 점수가 임곗값보다 크면 샘플을 positive class에 할당하고 그렇지 않으면 negative class에 할당한다.
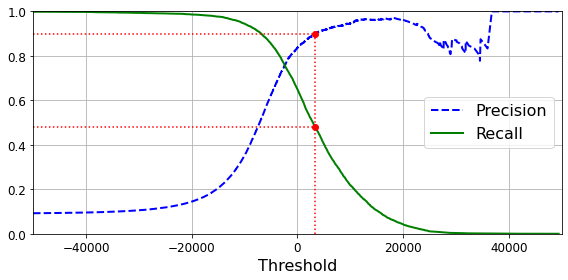
임계값을 높이면 재현율이 줄어든다.
또한 아래 그림처럼 재현율에 대한 정밀도 곡선으로 트레이드오프를 선택할 수 있다.
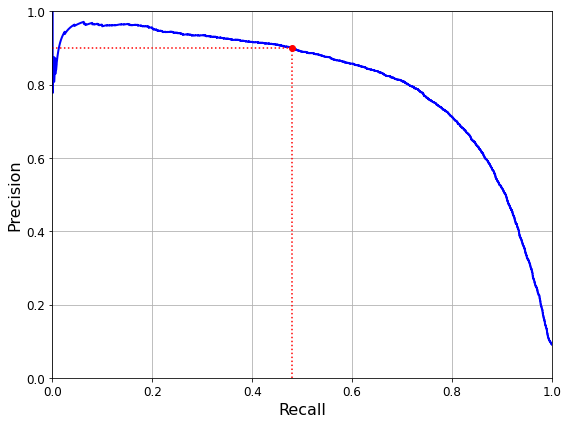
그래프에서 재현율 80% 근처에서 정밀도가 급격하게 줄어드는데, 이 하강점 직전을 정밀도/재현율 트레이트오프로 선택하는 것이 좋다.
average_precision_score() 함수를 사용하면 정밀도/재현율 곡선의 아래 면적을 계산할 수 있어 서로 다른 모델을 비교하는 데 도움이 된다.
ROC 곡선
ROC(receiver operation characteristic) 곡선도 이진 분류에서 많이 사용된다.
정밀도/재현율 곡선과 매우 비슷하지만, ROC 곡선은 FPR에 대한 TPR 곡선을 의미한다.
-
양성으로 잘못 분류된 음성 샘플의 비율이 FPR(flase positive rate)이며, 이는 1에서 음성으로 정확하게 분류한 음성 샘플의 비율인 TNR(true negative rate)을 뺀 값이다.
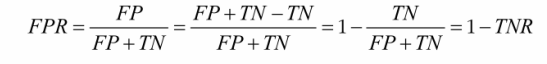
-
TNR을 특이도(specificity)라고도 한다.
⇒ ROC 곡선은 민감도(재현율)에 대한 1-특이도 그래프
ROC 곡선을 그리려면 먼저 roc_curve() 함수를 사용해 여러 임곗값에서 TPR과 FPR을 계산해야 한다.
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label)
plt.plot([0, 1], [0, 1], 'k--') # 대각 점선
plt.axis([0, 1, 0, 1]) # Not shown in the book
plt.xlabel('False Positive Rate (Fall-Out)', fontsize=16) # Not shown
plt.ylabel('True Positive Rate (Recall)', fontsize=16) # Not shown
plt.grid(True) # Not shown
plt.figure(figsize=(8, 6)) # Not shown
plot_roc_curve(fpr, tpr)
fpr_90 = fpr[np.argmax(tpr >= recall_90_precision)] # Not shown
plt.plot([fpr_90, fpr_90], [0., recall_90_precision], "r:") # Not shown
plt.plot([0.0, fpr_90], [recall_90_precision, recall_90_precision], "r:") # Not shown
plt.plot([fpr_90], [recall_90_precision], "ro") # Not shown
save_fig("roc_curve_plot") # Not shown
plt.show()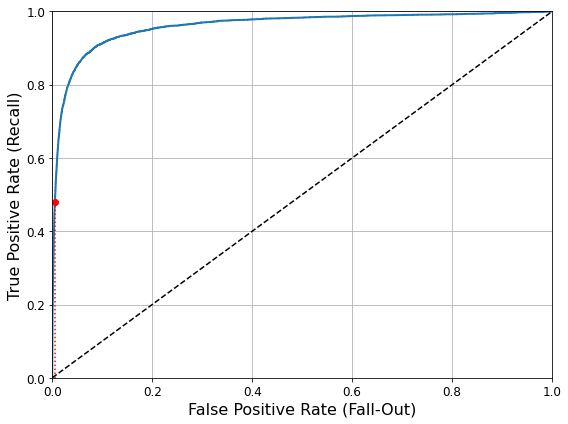
- 재현율(TPR)이 높을수록 분류기가 만드는 FPR이 늘어난다.
- 점선은 완전한 랜덤 분류기의 ROC 곡선을 뜻하며, 점선에서 왼쪽 위 모서리로 멀리 떨어져 있을 경우 좋은 분류기이다.
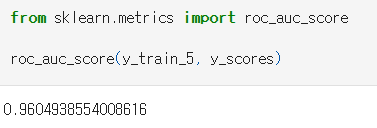
곡선 아래의 면적(area under the curve, AUC)을 측정하면 분류기들을 비교할 수 있다. 완벽한 분류기는 ROC의 AUC가 1이고, 완전한 랜덤 분류기는 0.5이다.
<RandomForestClassifier와 SGDClassifier의 ROC 곡선, ROC AUC 점수 비교하기>
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(n_estimators=100, random_state=42)
y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3,
method="predict_proba")RandomForestClassifier의 경우 decision_function() 메서드가 없어 대신 predict_proba() 메서드를 사용한다.
( predict_proba() 메서드는 샘플이 행, 클래스가 열이고 샘플이 주어진 클래스에 속할 확률을 담은 배열을 반환한다. )
y_scores_forest = y_probas_forest[:, 1] # 양성 클래스에 대한 확률을 점수로 사용한다.
fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5,y_scores_forest)recall_for_forest = tpr_forest[np.argmax(fpr_forest >= fpr_90)]
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, "b:", linewidth=2, label="SGD")
plot_roc_curve(fpr_forest, tpr_forest, "Random Forest")
plt.plot([fpr_90, fpr_90], [0., recall_90_precision], "r:")
plt.plot([0.0, fpr_90], [recall_90_precision, recall_90_precision], "r:")
plt.plot([fpr_90], [recall_90_precision], "ro")
plt.plot([fpr_90, fpr_90], [0., recall_for_forest], "r:")
plt.plot([fpr_90], [recall_for_forest], "ro")
plt.grid(True)
plt.legend(loc="lower right", fontsize=16)
save_fig("roc_curve_comparison_plot")
plt.show()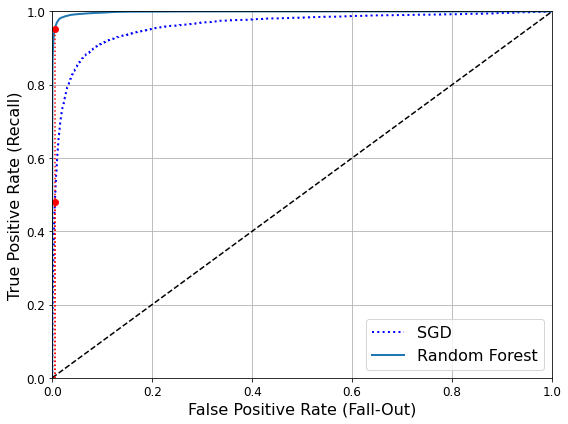
다중 분류
multiclass classifier
이진 분류가 두 개의 클래스를 구별하는 반면, 다중 분류기는 둘 이상의 클래스를 구별할 수 있다.
SGD, 랜덤 포레스트, 나이브 베이즈와 같은 일부 알고리즘은 여러 개의 클래스를 직접 처리할 수 있는 반면, 로지스틱 회귀나 서포트 벡터 머신 같은 알고리즘은 이진 분류만 가능하다. 하지만 이진 분류기 여러 개를 사용하여 다중 클래스를 분류할 수도 있다.
예를 들어 특정 숫자 하나만 구분하는 숫자별 이진 분류기 10개(0~9)를 훈련시켜 클래스가 10개인 숫자 이미지 분류 시스템을 만들 수 있다. 이미지를 분류할 때 각 분류기의 결정 점수 중 가장 높은 것을 클래스로 선택하게 된다. 이를 OvR(one-versus-rest) 또는 OvA(one-versus-all) 전략이라고 한다.
또 다른 전략은 0과 1 구별, 0과 2 구별, 1과 2 구별 등 각 숫자의 조합마다 이진 분류기를 훈련시키는 것이다. 이를 OvO(one-versus-one) 전략이라고 한다. 클래스가 N개라면 분류기는 N x (N-1) / 2개 필요하다.
(MNIST 문제에서는 45개의 분류기를 훈련시켜야 함.
이미지 하나를 45개 분류기 모두 통과시켜 가장 많이 양성으로 분류된 클래스를 선택)
서포트 벡터 머신 같은 일부 알고리즘은 train set의 크기에 민감해서 큰 train set에서 몇 개의 분류기를 훈련시키는 것보다 작은 train set에서 많은 분류기를 훈련시키는 쪽이 빠르므로 OvO를 선호한다. 하지만 대부분의 이진 분류 알고리즘에서는 OvR을 선호한다.
다중 클래스 분류 작업에 이진 분류 알고리즘을 선택하면 사이킷런이 알고리즘에 따라 자동으로 OvR 또는 OvO를 실행한다.
from sklearn.svm import SVC
svm_clf = SVC(gamma="auto", random_state=42)
svm_clf.fit(X_train[:1000], y_train[:1000]) # y_train_5이 아닌 y_train 사용
svm_clf.predict([some_digit])sklearn.svm.SVC 클래스를 사용해 서포트 벡터 머신 분류기 테스트하기
- 5를 구별한 타깃 클래스(y_train_5) 대신 0~9까지의 원래 타깃 클래스 y_train을 사용해 SVC를 훈련시킨다.
- 내부에서는 사이킷런이 OvO 전략을 사용해 45개의 이진 분류기를 훈련시키고 점수가 가장 높은 클래스를 선택한다.
some_digit_scores = svm_clf.decision_function([some_digit])
some_digit_scores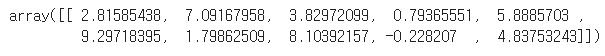
decision_function() 메서드를 호출하면 각 클래스마다 점수를 반환한다.
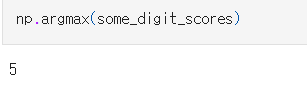
가장 높은 점수가 클래스 5에 해당하는 값이다.
