현 컴퓨터 cpu의 기본 실행 구조
현 컴퓨터 cpu의 동작은 크게 4가지로 나누어 볼 수 있는데
1. Intruction Fetch: 실행할 명령어를 메모리에서 읽어 cpu로 가져오는 작업을 한다.
1-1. pc가 가르키는 주소를 MAR에 보낸다.
1-2. MAR에 보낸 주소를 메모리에서 읽어들여 MBR에 보낸다.
1-3. MBR에 있는 명령어를 IR에 저장
1-4. 다음 명령어를 가리키도록 pc는 주소값 증가
2. Instruction Decode: (IR에서)인출한 명령어에 포함된 데이터를 가져오고 명령어 해독
3. Instruction Execution: 명령어 실행:
MBR의 데이터와 ACC(Accumulator)의 데이터로 연산 후, ACC(Accumulator)에 저장
4. Write Back: 실행 결과를 저장
(각각의 PC,IR과 같은 용어 정리는 가장 아래쪽)
현 컴퓨터의 cpu 명령어 구조
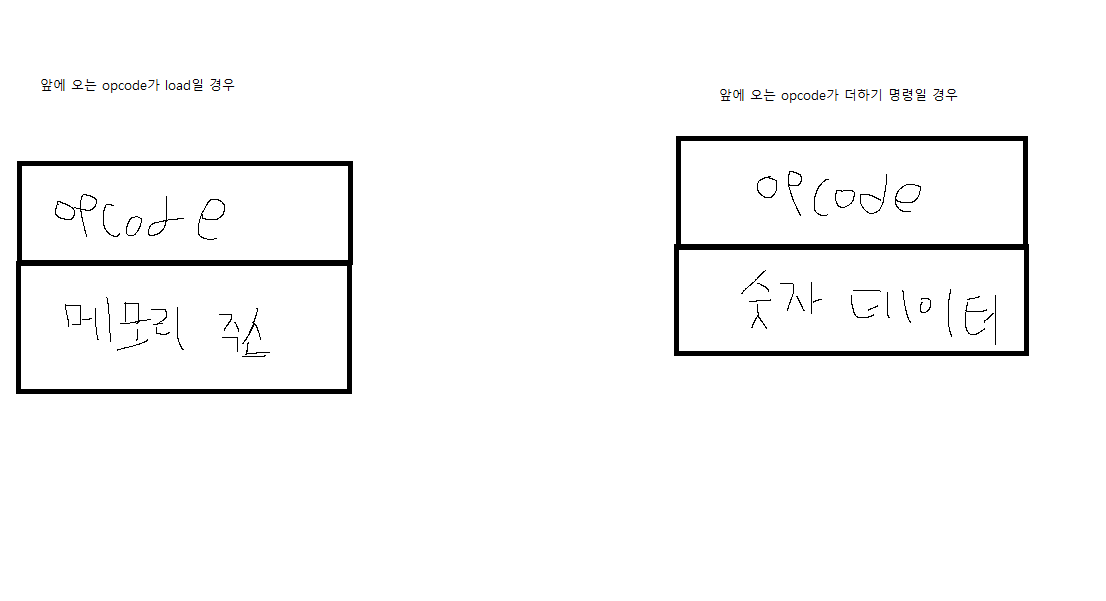
메모리에서는 opercode의 뒤에 오는 데이터인 argument(operand)가 cpu에 따라,명령어의 형태에 따라 그 데이터가 달라질 수 있지만 기본적으로는 위의 그림처럼 opercode + argument의 형태를 가지고 있다는 사실을 기억하자
cpu의 성능이 높아지는 파이프라인에대해
파이프라인이란 쉽게 말해 위에서 보았던 cpu의 4가지 과정을 좀더 세세하게 나누어서 각각 명령어를 처리 할 수 있도록 cpu를 설계하는 것이다 예를들어 위의 과정을 5단계로 나누어 아래와 같이 나누면 처리해보면
명령어 인출(IF : Instruction Fetch):메모리에서 명령어를 인출
명령어 해독(ID: Instruction Decode ):인출된 명령어 해석
오퍼랜드 인출(OF:Operand Fetch):메모리에서 데이터 인출
명령어 실행(EX:EXecute)
실행 결과 저장(SR:STore)
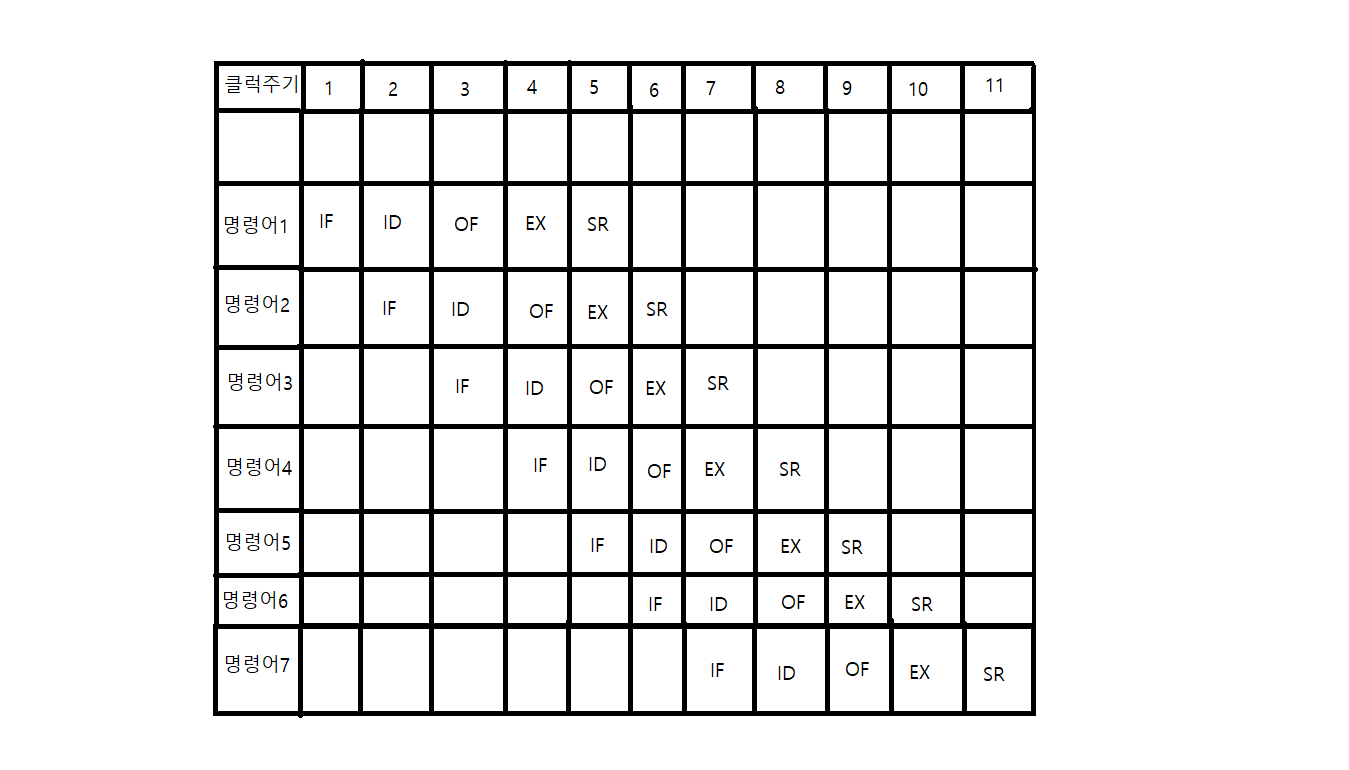
그러면 위의 그림과 같이 표현 할 수 있는데 이를 해석해보면 처음 IF 명령을 수행 하고 1클럭이 끝이난다 그 후 2클럭에서는 ID가 실행되어 1클럭의 IF 명령에 대한 ID명령을 실행하고 실행이 끝나면 IF가 또 실행되어 메모리에서 다음 명령어를 인출한다. 만약 잘 이해가 안 된다면
(필자의 개인적인 생각이지만)공장에서 물건을 생산한다 생각해보면 쉽게 이해가 되는 것 같다
하나의 물건을 만들기 위해 각 과정을 세분화해서 A팀은 어떤걸 만들고 B팀은 또 다른걸 만드는 것과 비슷한구조라고 생각된다.
파이프라인 구조를 생각하여 CYCLE단위 읽는법
CYCLE은 한 명령어가 온전히 끝나기 위한 단계이다 만약 파이프라인이 없는 구조는 1HZ = 1CYCLE/SEC 즉 한번의 클럭으로 한번의 명령어가 수행 된다. 하지만 파이프라인이 있는 CPU라면 5개의 파이프라인을 가졌다고 가정했을때 5CYCLE이 걸린다 이를 생각해 CPU의 CYCLES/SEC이 108,000이라 하였을때 이를 5CYCLE(한 명령 실행 시간)로 나누어보면 초당 21600의 명령어를 처리하는걸 알 수 있다.
레지스터의 용어정리
PC(Program Counter): 다음 실행할 명령어 주소를 가리키는 레지스터
IR(Instruction Register):가장 최근에 인출한 명령어 보관 레지스터
누산기(ACC,accumulater):데이터 일시 보관 레지스터
MAR(Memory Address Register): cpu가 메모리를 참조하기 전 MAR에 사용할 메모리 주소를 기록하고 같은 메모리 주소로 요청이 있을시 MAB의 정보를 사용하여 더욱 빠른 처리가 가능하게함
MBR(Memory Burffer Register):CPU가 메모리로부터 읽거나,저장할 데이터 자체를 보관하는 레지스터
