이전 글에서 셀레니움을 이용해서 원하는 사이트에 로그인하고, 필요한 화면을 캡쳐하는 기능을 만들었었다.
신나게 활용하던 중 이미지 저장에 너무 시간이 오래걸려 속도를 향상시킬 방법을 고민하게 되었다. 그래서 두 가지 부분을 수정하기로 했다.
- 멀티쓰레드를 이용하여 여러 개의 크롬 화면을 띄워서 캡쳐한다.
- 이미지를 저장하는 부분에서 시간이 오래 걸리므로 이 부분을 비동기로 처리한다.
여러 건의 웹페이지를 로그인 없이 빠르게 테스트 하기 위해서 웹툰페이지로 테스트하기로 했다. 작가님들의 저작권은 소중하니 해당 소스가 악용되는 일이 없으면 한다. 단순 공부용으로 기록한다.
우선 원시적인 멀티쓰레드 방식으로 1번 항목을 수정해봤다.
// 셀레니움을 이용해서 크롬드라이버를 새롭게 만들기. 크롬드라이버 객체가 브라우저 창 1개이다.
public static WebDriver getWebDriver(){
System.setProperty("webdriver.chrome.driver", "D:/chromedriver-win64/chromedriver.exe");
ChromeOptions options = new ChromeOptions();
options.setCapability("ignoreProtectedModeSettings", true);
options.setCapability("acceptInsecureCerts", true);
options.addArguments("--start-maximized");
return new ChromeDriver(options);
}// 수정 전
public static void main(String[] args) {
String webUrl = "https://www.google.com/";
WebDriver driver = MyUtils.getWebDriver();
driver.get(webUrl);
Webtoon webtoon = new Webtoon(driver, null);
String mainwindow = driver.getWindowHandle();
List<String> list = webtoon.loading(driver);
ImageMerge im = new ImageMerge(driver, "src/images/test/", webtoon);
// 중간에 람다식은 페이지 로딩시 대기하기 위해 실행한다. 그냥 true를 리턴해서 대기하지 않고 진행한다.
im.saveImage(mainwindow,tempDriver ->{return true;} ,list);
driver.close();
}
// 수정 후
private static void main(String[] args) {
String webUrl = "https://www.google.com/";
WebDriver driver = MyUtils.getWebDriver();
driver.get(webUrl);
Webtoon webtoon = new Webtoon(driver, null);
List<String> list = webtoon.loading(driver);
driver.close();
List<List<String>> result = new ArrayList<>();
int size = list.size();
int n = 3;
for (int i = 0; i < n-1; i++) {
result.add(list.subList(size/n * i, size/n*(i+1)));
}
List<Thread> threads = new ArrayList<>();
for (List<String> urls : result) {
Runnable r = ()->{
WebDriver innerDriver = MyUtils.getWebDriver();
drivers.add(innerDriver);
innerDriver.get("https://www.google.com/");
String innerMain = innerDriver.getWindowHandle();
ImageMerge im = new ImageMerge(innerDriver, "src/images/test/",webtoon);
im.saveImage(innerMain,tempDriver ->{return true;} ,urls );
};
Thread thread = new Thread(r);
threads.add(thread);
}
for (Thread thread : threads) {
try {
thread.start();
thread.join();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
사용하는 컴퓨터의 성능에 따라 적절한 창의 개수를 정하면 될것 같다. 너무 많은 창을 띄운다면 페이징 로딩이 오래 걸려서 오히려 성능이 저하되고 로딩 중인 화면이 캡쳐될 수도 있다.
아래는 2번 항목을 수정한 내용이다.
// 수정 전
public void saveImage(String mainWindow,Waiter waiter,List<String> list){
File[] images = null;
driver.switchTo().window(mainWindow);
// 새창에서 열기
for(int i =0; i<list.size();i++) {
String address = list.get(i);
js.executeScript(address);
if ((driver.getWindowHandles().size() - 1) % tabNumbers == 0 || i == list.size()-1) {
for (String w : driver.getWindowHandles()) {
if (w.equals(mainWindow))
continue;
driver.switchTo().window(w);
if(waiter.until(driver)){
images = imageSave(mainWindow, w);
// 변경할 구간
MergeInfo mergeInfo = concurrentHashMap.get(w);
mergeImage(images, mergeInfo);
concurrentHashMap.remove(w);
MyUtils.deleteFiles(images);
//
}
}
driver.switchTo().window(mainWindow);
MyUtils.sleep(100);
}
}
}
// 수정 후
public void asyncSaveImage(String mainWindow,Waiter waiter,List<String> list){
driver.switchTo().window(mainWindow);
// n개의 탭을 로딩하고 저장을 실행한다.
int tabNumbers = 5;
// 새탭에서 열기
for(int i =0; i<list.size();i++) {
String address = list.get(i);
js.executeScript(address);
if ((driver.getWindowHandles().size() - 1) % tabNumbers == 0 || i == list.size()-1) {
for (String w : driver.getWindowHandles()) {
if (w.equals(mainWindow)){
continue;
}
driver.switchTo().window(w);
if(waiter.until(driver)){
File[] images = imageSave(mainWindow, w);
// 저장된 이미지를 쓰레드를 이용해서 비동기로 처리한다.
new Thread(() -> {
MergeInfo mergeInfo = concurrentHashMap.get(w);
mergeImage(images, mergeInfo,0)
concurrentHashMap.remove(w);
// 윈도우 임시 저장소에 저장된 파일 삭제
MyUtils.deleteFiles(images);
}).start();
}
}
driver.switchTo().window(mainWindow);
}
}
} 이렇게 해서 원하는대로 진행되면 좋겠지만 몇가지 문제가 발생했다.
1. java.lang.OutOfMemoryError: heap space
2. Timed out receiving message from renderer: 100.000
이미지를 JVM에 로드해서 합치는데 비동기로 진행하다 보니 과부하가 발생한 것으로 추정된다. 우악스러운 방법이지만 asyncSaveImage메소드에서 멀티쓰레드 구간에서 System.gc()를 호출했지만 여전히 oom이 발생했다. 인위적으로 호출하는 것으로는 해결되지 않았다.
구글링 결과 두가지 정도 해결방법을 찾았다.
1번 항목 해결방법
jvm에서 최대 힙메모리를 늘려준다.
gc 튜닝
자바 GC에 대해 모니터링하고 튜닝해 볼 좋은 기회가 생겼다. 이번 글에서 작성하지 않고 다음 글에서 다뤄보고자 한다.
2번 항목 해결방법
크롬 실행시 화면을 띄우지 않고 실행
설정을 바꾸지 않고 소스를 바꿔서 수정할 수 있다는 점에서 화면을 띄우지 않는 쪽으로 먼저 해결하고 추후에 gc를 튜닝하기로 정했다.
public static WebDriver getWebDriver(){
System.setProperty("webdriver.chrome.driver", "D:/chromedriver-win64/chromedriver.exe");
ChromeOptions options = new ChromeOptions();
options.setCapability("ignoreProtectedModeSettings", true);
options.setCapability("acceptInsecureCerts", true);
options.addArguments("--start-maximized");
// 새로 추가한 옵션들
options.addArguments("enable-automation");
options.addArguments("--headless");
options.addArguments("--no-sandbox");
options.addArguments("--disable-dev-shm-usage");
options.addArguments("--disable-browser-side-navigation");
options.addArguments("--disable-gpu");
return new ChromeDriver(options);
}화면이 나오지 않으니 성능과 메모리 사용에서 많은 개선이 있었지만 화면이 최대크기로 변하지 않아서 스크린 캡쳐시 y축뿐만 아니라 x축도 캡쳐해서 합치도록 수정해야 했다.
x축과 y축을 모두 스크롤해서 이미지 캡쳐하기
public File[][] imageSave(String mainWindow, String windowName,By by) {
driver.switchTo().window(windowName);
webElement = driver.findElement(by);
int windowHeight = driver.manage().window().getSize().height;
int windowWidth = driver.manage().window().getSize().width;
int contentHeight = webElement.getSize().getHeight();
int contentWidth = webElement.getSize().getWidth();
String fileName = filenameSetter.setFileName(driver);
//System.out.printf("filename : %s window height : %d , window width : %d, content height : %d content width : %d\n",fileName,windowHeight,windowWidth, contentHeight, contentWidth);
File[][] srcFile = new File[contentHeight/(windowHeight/2)][contentWidth/(windowWidth/2) ];
Object ob = null;
int totalCapturedHeight = 0;
int totalCapturedWidth = 0;
int imgHeight = 0;
int imgWitdh = 0;
int y=0;
int x=0;
Object lastY = null;
Object lastX = null;
int lastScrollHeigh = 0;
int lastScrollWidth = 0;
BufferedImage temp=MyUtils.getBufferedImage(webElement.getScreenshotAs(OutputType.FILE));
imgHeight = temp.getHeight();
imgWitdh = temp.getWidth();
// 마우스로 한클릭이 40임
// y축 먼저 저장하고 x축 옳긴 다음 반복
while(totalCapturedWidth <= contentWidth + 80){
while (totalCapturedHeight <= contentHeight+80) {
srcFile[y][x] = ((TakesScreenshot) webElement).getScreenshotAs(OutputType.FILE);
js.executeScript(String.format("window.scrollTo(%d,%d)", (imgWitdh)*(x),(imgHeight)* (y + 1)));
y+=1;
totalCapturedHeight +=imgHeight;
ob = js.executeScript("return window.scrollY");
if(lastY!= null && lastY.equals(ob)) {
break;
}
lastY= ob;
// System.out.println(ob);
sleep(10);
}
totalCapturedHeight = 0; // 높이 초기화 + x축 이동
y=0;
js.executeScript(String.format("window.scrollTo(%d,%d)", (imgWitdh)*(x + 1),0));
x+=1;
totalCapturedWidth += imgWitdh;
ob = js.executeScript("return window.scrollX");
if(lastX!=null &&lastX.equals(ob)){
break;
}
lastX = ob;
// x축의 이동이 필요없는 경우
if(Integer.parseInt(lastX.toString() )<= 80){
break;
}
}
// 마지막 위치가 겹치기를 시작할 위치
lastScrollHeigh = Math.round(Float.parseFloat(String.valueOf(lastY)));
lastScrollWidth = Math.round(Float.parseFloat(String.valueOf(lastX)));
concurrentHashMap.put(windowName, new MergeInfo(fileName, contentHeight, contentWidth, lastScrollHeigh, lastScrollWidth));
driver.close();
return srcFile;
}2차원 배열로 저장했으면 이미지 합치는 곳도 이에 맞춰서 수정을 해줘야 한다.
public void mergeImage(File[][] images, MergeInfo mergeInfo) {
// 배열 크기를 여유롭게 잡았기 때문에 실제 담겨있는 파일의 길이를 확인한다.
int imagesCountY = (int)Arrays.stream(images).filter(t -> t[0]!=null).count();
int imagesCountX = (int)Arrays.stream(images[0]).filter(t -> t!=null).count();
String fileName = mergeInfo.getFileName();
int contentHeight = mergeInfo.getContentHeight();
int contentWidth = mergeInfo.getContentWidth();
// 이미지 캡쳐시 중복되는 지점의 시작
int lastScrollHeigh = mergeInfo.getLastScrollHeigh();
int lastScrollWidth = mergeInfo.getLastScrollWidth();
try {
BufferedImage[][] is = new BufferedImage[imagesCountY][imagesCountX];
FileInputStream[][] fisArr = new FileInputStream[imagesCountY][imagesCountX];
for (int i = 0; i < imagesCountY; i++) {
if(images[i]==null) continue;
for (int j = 0; j < imagesCountX; j++) {
if(images[i][j]==null) continue;
fisArr[i][j] = new FileInputStream(images[i][j]);
is[i][j] = ImageIO.read(fisArr[i][j]);
}
}
BufferedImage mergedImage = new BufferedImage(contentWidth, contentHeight, BufferedImage.TYPE_INT_RGB);
Graphics2D graphics = (Graphics2D) mergedImage.getGraphics();
graphics.setBackground(Color.WHITE);
int imageHeight = is[0][0].getHeight();
int imageWidth = is[0][0].getWidth();
int cutHeight = 0;
int cutWitdh = 0;
// x축을 합치고난 다음 y축으로 간다.
for (int y = 0; y < imagesCountY; y++) {
for (int x = 0; x < imagesCountX; x++) {
if(imagesCountY-1 == y ) {
cutHeight = lastScrollHeigh;
}
if(imagesCountX-1 == x){
cutWitdh = lastScrollWidth;
}
graphics.drawImage(is[y][x], cutWitdh, cutHeight, null);
cutWitdh +=imageWidth;
}
cutHeight += imageHeight;
cutWitdh = 0;
}
File saveFile = new File(saveDir+ fileName + ".png");
int i =0 ;
while(saveFile.exists()) {
saveFile = new File(saveDir+ fileName + "_("+i +").png");
i+=1;
}
ImageIO.write(mergedImage, "png",saveFile);
for (int j = 0; j < fisArr.length; j++) {
for (int j2 = 0; j2 < fisArr[j].length; j2++) {
if(fisArr[j][j2]!=null){
fisArr[j][j2].close();
}
}
}
mergedImage.flush();
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}실제 화면을 띄울 경우 모니터의 크기에 따라 결과물이 달라진다.
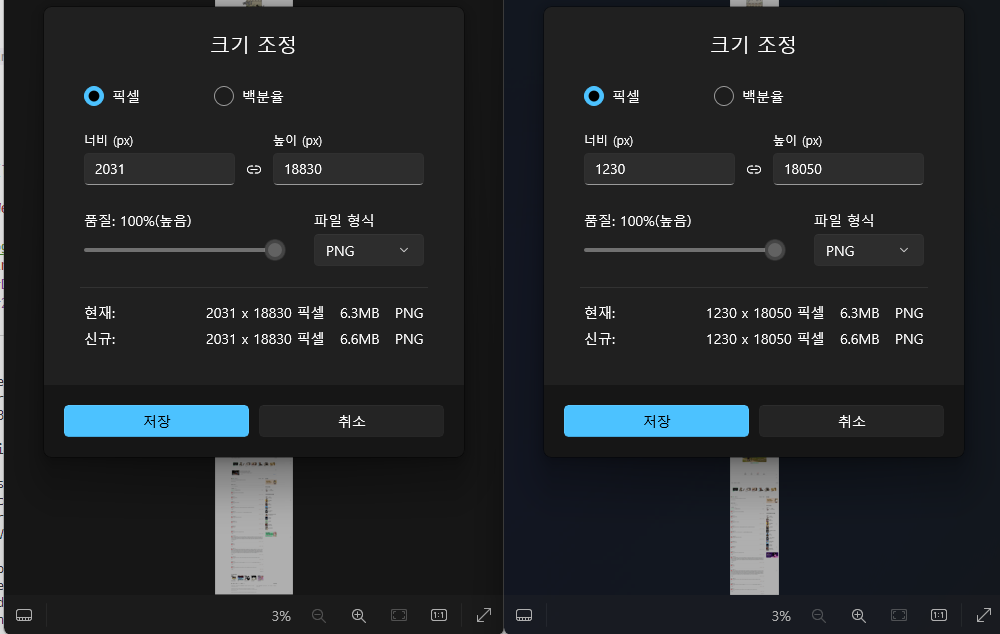
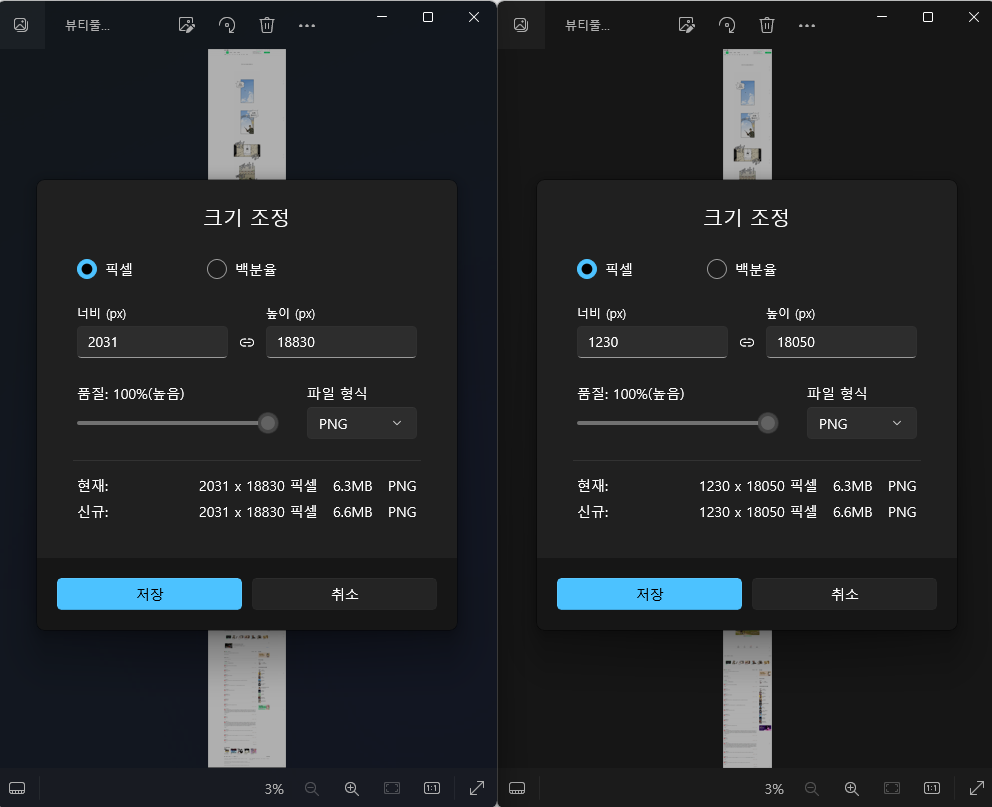
왼쪽 이미지는 QHD모니터를 사용, 화면을 띄우고 실행한 내용이다. 모니터의 해상도만큼 너비가 나왔다. 오른쪽 이미지는 화면을 띄우지 않고 실행한 내용이다. 화면을 띄우지 않을경우 600x800으로 크기가 고정되었다. 이때 너비가 1230으로 나오는 이유는 해당 사이트에서 min_width값이 1230이기 때문이다.

대략 5분 동안 25개의 페이지를 저장할 수 있었고, 저장된 총 용량은 607MB였다.
-> 아직 해결해야 하는 점들
1. 화면을 없애고 진행한 결과 전보다 OOM는 줄었지만 완전히 제거하지는 못했다. 현재 노트북의 성능으로 보아 100페이지를 저장할때 3 ~ 4건 정도가 OOM으로 저장에 실패했다. 다음 번에는 GC튜닝을 하고, 멀티스레드에서 던지는 예외를 잡아서 재처리 하도록 개선할 생각이다.
- 윈도우 환경에서 실행하는 경우, 크롬이 자동업데이트되면서 크롬 드라이버와 버전이 맞지 않아서 셀레니움에서 에러를 던지고는 했다. 이전에는 이를 해결하기 위해서 webdrivermanager 라는 오픈소스를 사용했지만 크롬 118버전 부터는 동작이 잘 안 되었다. 그 당시 webdrivermanager의 버전이 낮아서 그랬던것 같기는 하지만 도커로 컨테이너화 시켜서 개선해볼 생각이다.
추가적으로 개선할 내용
1. GC튜닝 및 JVM 모니터링
2. 멀티스레드에서 예외 잡기
3. Docker 환경에서 실행할 수 있도록 컨테이너화
관련 GIT 소스들
Webtoon.java-> main메소드가 있다.
