사내 M/L 개발자 '고강빈'님의 강의자료 입니다.
람다 아키텍처: 배치 프로세싱
1. 데이터 용어 해설
Data Lakes and hybrid Data Warehouses are certainly a wonderful tool to make the company data-driven and to bring it forward.
However, such a Data Lake must be managed and maintained, otherwise it degenerates into a Data Swamp. This often leads to the fact that information is wrong and users do not use it at all, then Data Lakes do not create any advantages but only produce costs.- What is Data Swamp? -
Data Warehouse
- 대표적인 데이터 저장소 → 대량의 데이터를 장기 보관 (보통 3개월~1년)
- 다양한 source의 데이터를 분석 가능하고 구조화된 형식으로 저장
→ 구조화된 정형 데이터를 담는 repository
→ Data-driven 의사결정을 도움 (For Analytics and Reporting)
→ 다양한 source에서 필요한 데이터를 그대로 가져오기도 하지만, 보통 ETL 과정 거침
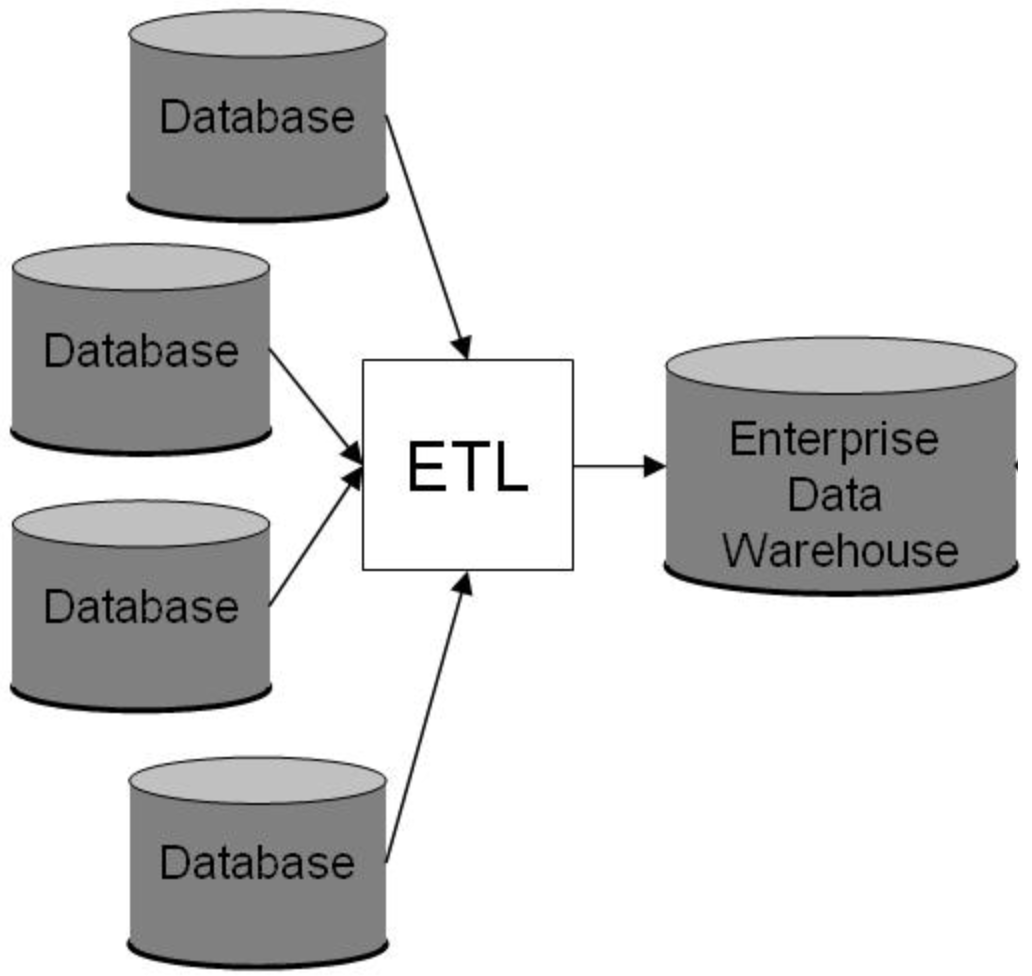
- 기본적인 RDB와 달리 주로 columnar (column-oriented) 형태로 관리됨
- 주제 지향적 (subjectoriented)
- 통합적 (integrated)
- 시계열적 (timevarient)
- 비휘발적 (nonvolatile)
Data Mart
- 특정 분야의 데이터를 정제, 집계해서 따로 담고 있는 데이터 저장소
- 팀, 부서별로 구축 및 관리
- 데이터 웨어하우스보다 최종 사용자에 근접한 데이터스토어
- 최종 사용자가 필요로 하는 속성을 갖고 있는 작은 데이터 집합
- 비교적 소량의 데이터를 가지며 전체 컬럼에 대한 조회가 잦음
→ RDB 형태를 주로 채택
- 소수의 소스로부터 or 데이터 웨어하우스로부터 ETL 프로세싱하여 구성
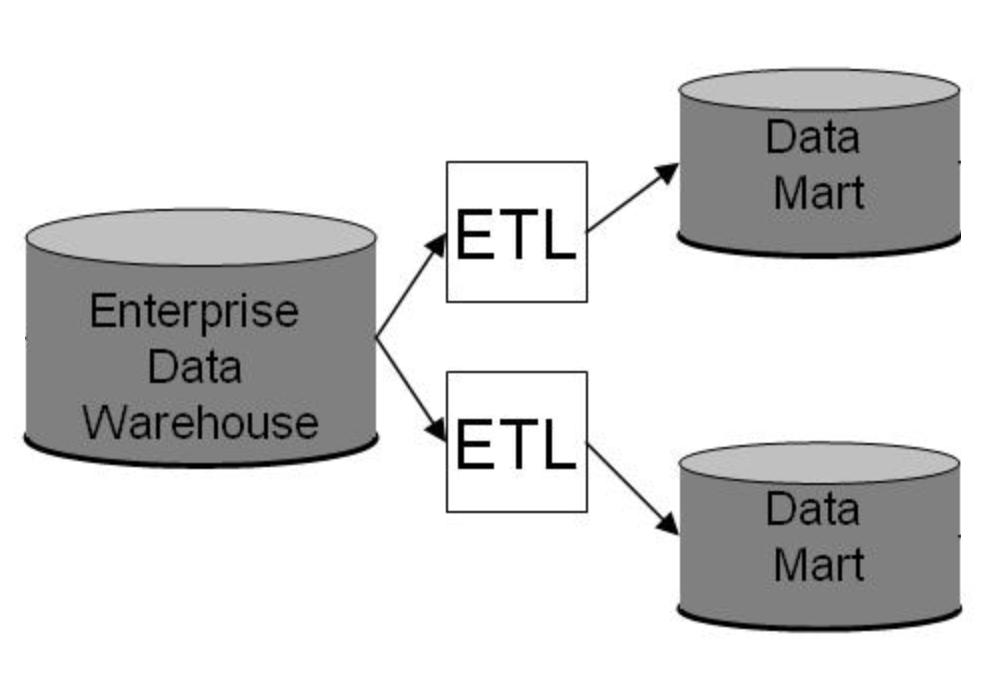
- 용도에 따라 나누어놓고 OLAP 작업 통해 BI(Business Intelligence) 실현 → 시각화 등 BI 툴을 추가하여 사용하기도 한다.
Data Lake
“일단 저장하고 필요할 때 꺼내쓴다!”
- 정형 / 비정형 데이터 모두를 저장하고 관리하는 저장소
- 최근 클라우드 및 대용량 분산처리의 등장과 함께 떠오른 기술
→ 정의된 목적이 없는, 정형화나 정규화를 하지 않고 원시 데이터를 그대로 저장- DB보다는 대용량 분산 스토리지 (S3, HDFS, …)에 가까운 형태
- not table / no schema / schema on read ⇒ 읽어들일 때 스키마를 결정
- ELT의 중간 저장소(Load) 역할
잘 관리되지 않은 데이터 레이크는 데이터 늪(Data Swamp)라고도 부른다.
OLAP
- OnLine Analysis Processing ↔ OLTP
- OnLine Transaction Processing
- 사용자가 대화형 쿼리 통해 다차원 데이터 분석을 하고 이를 의사결정에 참고하는 과정 또는 그 과정에 사용되는 DB 엔진
- 주로 대량 읽기 워크로드 담당
- 분석을 위해 만들어진 다수의 다차원 데이터(OLAP cube)를 aggregate & query
- Columnar
Row-Oriented v.s. Column-Oriented
-
Row-oriented == 일반적인 RDB(관계형 데이터베이스)
→ OLTP -
행(row)별로 데이터를 관리하고 조회
- 특정 row 검색, 삭제, 업데이트, 추가 효율적
- 트랜잭션 처리
- 적은 양의 데이터를 자주 읽고 쓴다.
-
Column-oriented(Columnar) : 열별로 데이터를 저장 ⇒ 데이터 엔지니어링 세계에선 대부분
→ OLAP -
열(column)별로 데이터를 저장하고 관리
- Delete/Update가 비효율적이거나 불가능 (Only by Batch Processing)
- 같은 형식의 데이터를 관리하기 때문에 압축이나 보관이 우세
- 특정 칼럼의 데이터만 가져오거나 대량의 데이터에 대한 쿼리, 같은 자료형의 데이터가 모여있다
- 많은 양의 데이터를 종종 읽고 쓴다.

2. Batch Processing
“Just because you have a hammer doesn’t mean that’s the right tool for every job.”
- Mark Balkenende, Director of Technical Product Marketing -
복습) Batch Processing
- 일괄 처리
- 데이터를 일정 기간동안 수집하고 나서 하나의 슬롯으로 처리하는 것
- Bounded data processing
- For large volumes of data 연산량이 많은 CPU 집약적인 작업 (ex: ML/DL)
- 중요도 : latency < throughput
배치 처리의 Pain point
- 불규칙 데이터 사이즈
→ 배치 처리의 컴퓨팅 리소스와 배치 작업 주기를 산정하기 어려움
→ 안정화가 되어 있는 경우는 뭐 괜찮지만.. 스타트업은 크리티컬 - 연산/처리 속도와 배치 주기
→ 컴퓨팅 리소스 산정
→ 비즈니스 및 DS의 요구 사항 고려> **”한 시간마다 데이터 주세요”** > - 재처리 방식
→ 재처리용 리소스를 따로 할당 or 기존 리소스를 나눠서 사용 - 태스크 스케쥴링(워크플로 스케쥴링)
→ 배치 작업을 정해진 시간에 실행하고 그 상태 / 결과를 모니터링 할 수 있어야 함
⇒ A가 끝나면 B를 수행한다. A가 실패할 경우 C를 실행한다
⇒ 뭔가 문제가 생기면 즉각 대응이 가능해야한다.
빅데이터의 왕: Hadoop

- 대표적인 빅데이터 프레임워크
→ 주로 배치 처리 담당 - HDFS, MapReduce, HBase, Spark, Presto, YARN 등 Hadoop Ecosystem
- 너무 방대한 양과 다양한 에코시스템….🥲
- 대체 가능
- Data Lake (HDFS) → AWS S3
- Hive → Amazon Athena
- Hadoop → AWS EMR
3. ETL과 ELT
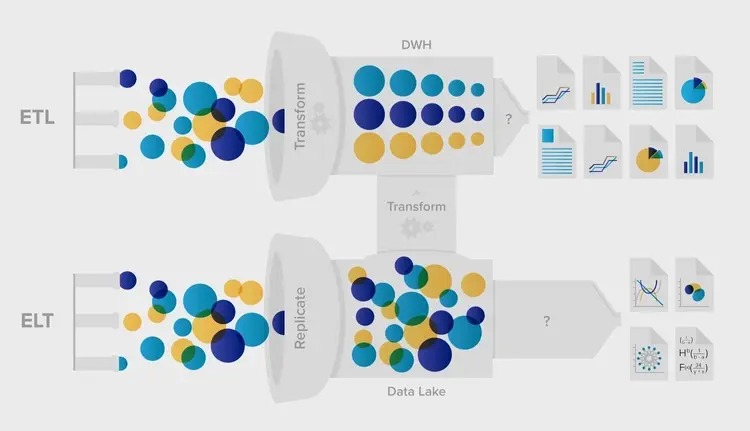
ETL
- Extract-Transform-Load
→ 비즈니스 데이터를 활용 가능한 형태로 추출(E), 변환(T), 저장(L)하여 이후 활용할 수 있도록 하는 작업, 또는 그러한 데이터 파이프라인
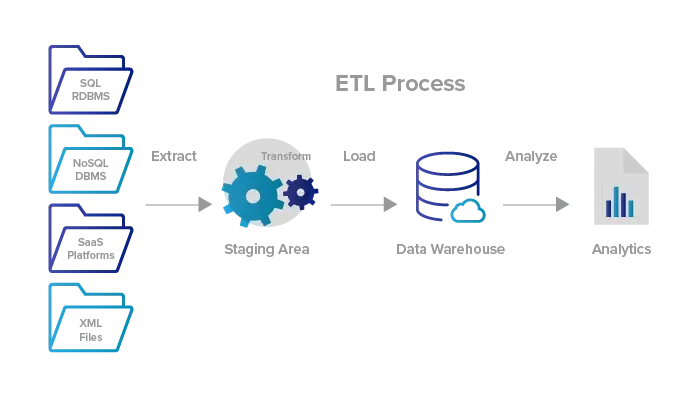
- 주로 OLTP(OnLine Transaction Processing)
→ DB를 source로 하는 ETL 파이프라인을 만들고 Data warehouse와 Data mart로 저장 - Transform (= filter, sort, aggregate, join, deduplicate, validate, missing value, etc)
- 주로 일괄 처리 방식, 주로 정형 데이터
ETL의 단점
- 추출해야 하는 데이터 스토어가 백엔드나 데이터 엔지니어링의 영역
→ 데이터 사이언티스트나 BI 담당자는 원하는 데이터를 즉각적으로 얻기가 어려움 (민첩성 결여) - 비정제, 비정형 데이터를 담아서 활용할 저장소의 부재
- 기존 DB 구조에서 크게 벗어나지 못함
- 스키마 종속적
- 제한적인 데이터 타입
- 쿼리 등의 성능 때문에 DB 모델링이 중요
데이터 필드의 변화: ELT의 등장
“원하는 데이터만 추려서 저장!” ⇒ “뭐가 필요할지 모르니까 일단 다 저장!”
- 데이터 니즈의 다양성
→ 데이터를 다루는 직군이 늘어남: 데이터 기반 의사결정
→ 데이터 소스의 다양화- 데이터 통합
- Computing resource / Storage resource 발전
- 쉽고 저렴하게 담아서 원하는 시점에 원하는 형식으로 꺼내서 사용할 수 있게 됨
- 데이터 레이크의 발전
What is ELT?
“데이터를 자주 그리고 다양하게 뽑아서 사용하겠다!”
“데이터의 목적지에서 원하는대로 변환해서 사용하겠다!”
“데이터 과학자와 분석가가 편하게, 원하는 데이터를, 원하는 방식으로
변환, 모델링, 쿼리할 수 있도록 해야겠다!”**
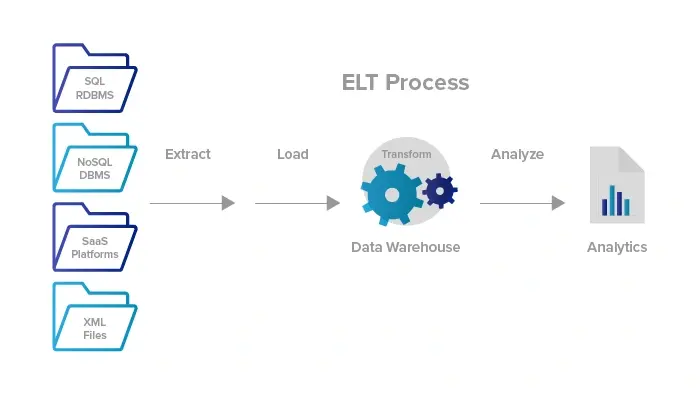
- 다양한 데이터 소스로부터 원시 데이터를 가져와서 데이터 레이크에 저장
- 구조화된 데이터 모델이 불필요 → 미리 모델링 고려할 필요 X
Is ELT silver bullet?
- 개인정보, 보안, 암호화 등의 요구 사항에선 ETL이 필요
- 데이터의 전초기지(Outpost)가 필요할 때 ETL로 데이터를 뽑아서 DW, DM 구축
- 원천 데이터가 너무 많을 경우 시스템 및 비즈니스 요구사항에 따라 좀 잘라내서 저장
⇒ ELT가 좋긴해도 ETL이 사라지진 않을 것 (여전히 배치에 의한 ETL가 70% 이상)
