GPU 환경에서의 네트워크 최적화: Cilium + SR-IOV + Multus
GPU 워크로드는 대규모 연산과 빠른 데이터 전송을 동시에 요구한다.
특히 분산 학습이나 대규모 데이터셋을 다루는 환경에서는 네트워크 지연(latency)과 대역폭(bandwidth)이 성능의 핵심 요소가 된다.
Kubernetes 환경에서 이러한 요구를 충족하기 위해서는 SR-IOV, Multus, Cilium을 함께 사용하는 구성이 효과적이다.
이번 글에서는 각 기술에 대한 소개와 구성 실습을 진행한다.
SR-IOV
GPU 환경에서 네트워크 성능을 최적화하기 위해서는 RDMA(Remote Direct Memory Access) 기술을 활용하는 것이 중요하다.
RDMA란 CPU 개입 없이 네트워크를 통해 직접 메모리에 접근할 수 있도록 하는 기술로, 지연을 최소화하고 대역폭 활용을 극대화할 수 있다.
SR-IOV는 이러한 RDMA 기술을 Pod 단위에서 활용할 수 있도록, 물리 NIC의 가상 함수(VF)를 Pod에 직접 할당한다.
이 때 RDMA 통신은 일반적으로 RoCE 프로토콜을 통해 이루어진다.
RoCE (RDMA over Converged Ethernet)
RoCE는 이더넷 기반 네트워크 상에서 RDMA를 지원하는 기술이다.
기존 RDMA가 InfiniBand와 같은 특수 네트워크에서만 가능했던 것과 달리, RoCE를 활용하면 표준 이더넷 환경에서도 RDMA 성능을 활용할 수 있다.
RoCE는 두 가지 버전이 존재한다.
1.RoCE v1
특징
- Ethernet Layer 2에서 동작한다.
- 동일 브로드캐스트 도메인 내에서만 통신이 가능하다.
- L2 프레임 기반이므로 라우팅이 불가능하다.
장점: 간단한 구성으로 낮은 지연을 제공한다.
제약: 대규모 클러스터 또는 다른 네트워크 세그먼트를 넘는 통신에는 부적합하다.
2.RoCE v2
특징
- UDP/IP 위에서 동작하는 RDMA 프로토콜이다.
- L3 라우팅이 가능하여, 서로 다른 네트워크 서브넷 간에도 RDMA 통신을 지원한다.
- QoS 및 Congestion Control 메커니즘과 결합하여 대규모 클러스터 환경에 적합하다.
장점: 대규모 데이터센터 환경에서 확장성이 뛰어나다.
제약: RoCE v1보다 상대적으로 복잡하며, 네트워크 설정(QoS, PFC 등)이 필요하다.
정리를 하자면 RoCE v1은 동일 노드 또는 동일 네트워크 세그먼트에서 GPU 간 저지연 통신이 필요한 경우 적합하다.
RoCE v2는 대규모 GPU 클러스터에서 서로 다른 노드 간 학습 데이터를 주고받을 때 사용한다.
SR-IOV를 통해 Pod에 VF를 할당하고, 해당 VF를 RoCE 지원 네트워크 인터페이스로 구성하면 Kubernetes GPU 워크로드에서도 RDMA 성능을 활용할 수 있다.
Multus
Kubernetes는 기본적으로 Pod에 하나의 네트워크 인터페이스만을 제공하며, CNI 플러그인(Cilium, Calico 등)에 의해 관리된다. 해당 인터페이스는 주로 Kubernetes 서비스 트래픽과 Pod 간 기본 통신에 사용된다.
그러나 GPU 환경에서는 단일 네트워크인터페이스 만으로는 서비스 트래픽과 고속 데이터 전송을 동시에 처리하기 어렵기 때문에 멀티 네트워크 인터페이스를 통해 트래픽을 분리하고 최적화해야 한다.
Multus CNI는 Kubernetes에서 Pod에 다중 네트워크 인터페이스를 부여할 수 있도록 해주는 메타 플러그인이다.
즉, 하나의 Pod가 여러 CNI 플러그인을 동시에 사용할 수 있도록 한다.
Multus 역할
1.데이터 경로와 제어 경로의 분리
eth0은 Kubernetes 서비스 및 관리 트래픽을 담당한다.
net1 같은 추가 인터페이스는 SR-IOV 기반 고성능 RDMA/RoCE 트래픽을 담당한다.
이를 통해 서비스 안정성과 데이터 성능을 동시에 보장한다.
2.특화된 네트워크 할당
GPU 학습 워크로드는 고성능 RDMA 네트워크가 필요하다.
Multus를 통해 특정 Pod에만 SR-IOV NIC의 VF를 붙여주어, 필요할 때만 성능 최적화 네트워크를 사용할 수 있다.
Multus CNI Plugin
Multus CNI는 다른 CNI를 호출하여 Pod에 여러 네트워크를 붙여주는 메타 플러그인으로 Multus CNI 자체가 네트워크를 직접 구성하지는 않는다.
Multus를 통해 여러 네트워크를 추가할 때는 아래와 같은 CNI 플러그인들을 조합할 수 있다.
| 플러그인 종류 | 설명 | 활용 사례 |
|---|---|---|
| SR-IOV CNI | 물리 NIC의 SR-IOV 기능을 이용해 Pod에 가상 함수(VF)를 직접 할당한다. | GPU/HPC 환경에서 RoCE·RDMA 전용 네트워크 제공 |
| macvlan CNI | Pod에 별도 MAC 주소를 부여하여 물리 네트워크에 직접 연결한다. | Pod이 외부 네트워크와 직접 통신해야 할 때 |
| ipvlan CNI | 호스트 NIC의 MAC을 공유하며 Pod에 IP만 부여한다. | MAC 주소 제한이 있는 대규모 Pod 환경 |
| bridge CNI | Pod 인터페이스를 호스트 브리지에 연결한다. | 테스트/개발 환경에서 간단히 브리지 네트워크 활용 |
| vlan CNI | Pod 트래픽에 VLAN 태그를 붙여 네트워크를 분리한다. | 멀티 테넌트 환경에서 네트워크 격리 |
| host-device CNI | 노드의 물리 NIC을 Pod에 직접 할당한다. | 특정 Pod에 물리 NIC 리소스를 100% 전담시킬 때 |
| loopback CNI | Pod 내부 lo 인터페이스를 생성한다. | 모든 Pod에 기본 제공, 내부 통신용 |
IPAM Plugin
IPAM(IP Address Management) 플러그인은 각 네트워크 인터페이스에 IP 주소를 어떻게 할당할지를 결정한다.
CNI 플러그인이 인터페이스를 생성하면, IPAM 플러그인이 호출되어 해당 인터페이스에 붙을 IP, Gateway, Route 등을 결정한다.
즉, “네트워크 인터페이스 생성”과 “IP 할당”을 분리하여 관리할 수 있다.
IPAM Plugin 종류는 다음과 같다.
- host-local: 노드 로컬에 IPAM 상태를 저장하고 IP를 순차적으로 할당한다.
- static: 설정 파일에 미리 정의한 IP를 할당한다.
- dhcp: 외부 DHCP 서버에서 IP를 받아온다.
실습
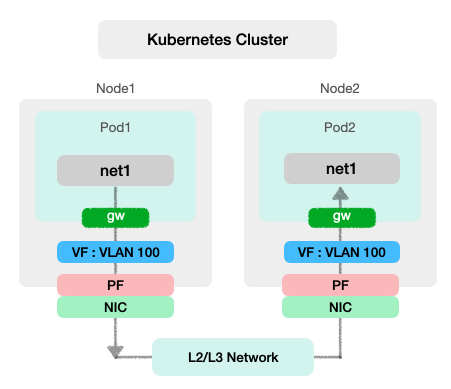
*현재 통신 이슈를 확인하는 단계로 통신 이슈 해결 시 업데이트 예정이다.
구성 설명
SR-IOV
각 노드의 NIC에서 VLAN100을 Pod의 net1으로 직접 할당
Pod가 NIC VF를 통해 RoCE v2 트래픽을 바로 전송 가능
Multus
Pod에 net1 인터페이스를 붙여줌
RoCE v2
net1을 통해 UDP/IP 기반 RDMA 통신 수행
서로 다른 노드의 Pod 간 라우팅으로 데이터 전송
Pod 통신
ping 및 RDMA 테스트 시, net1(VLAN100) 사용
사전 확인
클러스터 생성
클러스터 생성 시 Cilium CNI와 Multus CNI를 배포한다.
정상적으로 배포되었다면 multus daemonset이 배포되며 노드에서도 cni 정보를 확인할 수 있다.
~# ls /opt/cni/bin/multus
/opt/cni/bin/multus
~# tree /etc/cni/net.d/ | grep multus
├── 00-multus.conf
├── multus.d
│ └── multus.kubeconfigPF(Physical Funciton) 할당 확인
물리 NIC를 나누어 Pod에 가상 NIC조각을 붙이기 위해서는 현재 어떠한 물리 NIC가 매핑되어 있는 지 확인해야 한다.
여기서 물리 NIC를 PF(Physical Function), 가상 NIC를 VF(Virtual Funciton)이라 부른다.
RDMA 스택에서 어떠한 물리 NIC이 연결되어있는지, 커널 단에서 어떠한 명의 네트워크 인터페이스를 사용하는지를 확인해본다.
# RDMA를 지원하는 NIC이름(HCA-Host Channel Adapter) 확인
~# rdma link show
...
link mlx5_8/1 state ACTIVE physical_state LINK_UP netdev enp157s0np0
# 지원 RDMA 종류 확인
~# cat /sys/class/infiniband/mlx5_8/ports/1/gid_attrs/types/1
RoCE v2
# 커널에서 해당 NIC을 식별하는 주소 (PCI) 확인
~# readlink /sys/class/infiniband/mlx5_8/device
../../../0000:9d:00.0
# PF 확인
~# ls /sys/bus/pci/devices/0000:9d:00.0/net
enp157s0np0GPU WorkerNode SR-IOV 지원 여부 및 IOMMU 가상화 확인
네트워크를 통해 직접 메모리에 접근하기 위해서는 SR-IOV지원 및 IOMMU(nput-Output Memory Management Unit) 가상화를 확인해야 한다.
~# ls /sys/class/net/enp157s0np0/device | grep sriov
...
sriov_totalvfs
~# cat /proc/cmdline | grep iommu
BOOT_IMAGE=/boot/vmlinuz-5.15.0-91-generic root=UUID=de68bbf0-de79-441c-8e44-57c29618114e ro intel_iommu=on iommu=pt pci=pcie_bus_perf pcie_acs_override=downstream,multifunction console=tty1 console=ttyS0Nvidia Network Operator 배포
Nvidia Network Operator란 NVIDIA GPU 서버 환경에서 RDMA 기반 고속 네트워크설정과 관리를 자동화하는 Kubernetes Operator이다.
RDMA-capable 장치를 Pod, Node, NIC 수준에서 구성 및 모니터링, 자동화가 가능하기 때문에 Kubernetes 환경에서 많이 사용된다.
helm install network-operator nvidia/network-operator \
--namespace network-operator \
--create-namespace \
--set deployCR=true \
--set nfd.enabled=true \
--set sriovNetworkOperator.enabled=true \
--set rdmaSharedDevicePlugin.enabled=true \
--set secondaryNetwork.enabled=trueNvidia Network Operator helm Chart를 배포하면 아래와 같은 리소스들이 배포된다.
| 리소스 | 역할 |
|---|---|
| DaemonSet: nvidia-network-operator | 클러스터 모든 GPU 노드에 배포되어 RoCE, SR-IOV, VF 설정 및 관리 |
| ConfigMap: nvidia-network-config | NNO 설정 값 저장 (SR-IOV, RDMA VF, QoS, VLAN 등) |
| DaemonSet: node-feature-discovery (NFD) | 노드의 SR-IOV, RDMA, GPU 등의 하드웨어 특성 레이블링 |
| DaemonSet: sriov-network-operator | SR-IOV 네트워크 CRD를 감시하고, PF/VF 생성 및 관리, Pod에 VF 할당 |
| DaemonSet: sriov-network-config-daemon | 노드의 SR-IOV PF/VF, VLAN, QoS 등 L2/L3 네트워크 설정 수행 |
| NetworkAttachmentDefinition (NAD) | Multus CNI에서 Pod에 추가 네트워크 인터페이스를 연결하기 위한 정의 |
| SriovNetworkNodePolicy (SR-IOV NNP) | 노드별 SR-IOV 네트워크 정책을 정의하는 CRD. sriov-network-operator가 이를 기반으로 PF/VF 생성 및 관리 |
SriovNetwork관련 생성
Node1, Node2 각각 SriovNetworkNodePolicy를 생성한다. 각 노드에서 어떤 NIC를 사용할지, 몇개의 VF를 사용할지에 대한 정보이다.
sriov-network-operator가 해당 리소스를 기준으로 VF생성 및 VLAN 할당을 진행한다.
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: rocebgr1
namespace: network-operator
spec:
deviceType: netdevice
isRdma: true
linkType: eth
mtu: 9000
nicSelector:
pfNames:
- enp157s0np0
nodeSelector:
kubernetes.io/hostname: node1
numVfs: 8
priority: 99
resourceName: rocebgr1
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: rocebgr2
namespace: network-operator
spec:
deviceType: netdevice
isRdma: true
linkType: eth
mtu: 9000
nicSelector:
pfNames:
- enp157s0np0
nodeSelector:
kubernetes.io/hostname: node2
numVfs: 8
priority: 99
resourceName: rocebgr2Node와 SriovNetwork가 잘 연결되었는지는 SriovNetworkNodeState CR을 통해 확인할 수 있다.
> kubectl get sriovnetworknodestate -A
NAMESPACE NAME SYNC STATUS DESIRED SYNC STATE CURRENT SYNC STATE AGE
network-operator node1 Succeeded Idle Idle 38h
network-operator node2 Succeeded Idle Idle 38h실제로 VF가 생성되었는지 확인해본다.
> kubectl describe node | grep -A10 "Allocatable" | grep 'nvidia.com/roce'
nvidia.com/rocebgr1: 8
nvidia.com/rocebgr2: 8
~# lspci | grep 9d
9d:00.0 Ethernet controller: Mellanox Technologies MT2910 Family [ConnectX-7]
9d:00.1 Ethernet controller: Mellanox Technologies ConnectX Family mlx5Gen Virtual Function
9d:00.2 Ethernet controller: Mellanox Technologies ConnectX Family mlx5Gen Virtual Function
9d:00.3 Ethernet controller: Mellanox Technologies ConnectX Family mlx5Gen Virtual Function
9d:00.4 Ethernet controller: Mellanox Technologies ConnectX Family mlx5Gen Virtual Function
9d:00.5 Ethernet controller: Mellanox Technologies ConnectX Family mlx5Gen Virtual Function
9d:00.6 Ethernet controller: Mellanox Technologies ConnectX Family mlx5Gen Virtual Function
9d:00.7 Ethernet controller: Mellanox Technologies ConnectX Family mlx5Gen Virtual Function
9d:01.0 Ethernet controller: Mellanox Technologies ConnectX Family mlx5Gen Virtual Function각 노드 별로 Policy를 생성했다면 SriovNetwork를 생성한다. 컨테이너에서 연결할 VF를 정의하기 위한 리소스이다.
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetwork
metadata:
name: rocebgr1
namespace: network-operator
spec:
ipam: |
{
"type": "host-local",
"subnet": "10.255.0.0/30",
"rangeStart": "10.255.0.1",
"rangeEnd": "10.255.0.1",
"gateway": "10.255.0.2",
"routes": [
{ "dst": "0.0.0.0/0", "gw": "10.255.0.2" }
]
}
linkState: enable
logLevel: info
networkNamespace: default
resourceName: rocebgr1
spoofChk: 'off'
trust: 'on'
vlan: 100
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetwork
metadata:
name: roce2-bgr
namespace: network-operator
spec:
ipam: |
{
"type": "host-local",
"subnet": "10.255.0.4/30",
"rangeStart": "10.255.0.5",
"rangeEnd": "10.255.0.5",
"gateway": "10.255.0.6",
"routes": [
{ "dst": "0.0.0.0/0", "gw": "10.255.0.6" }
]
}
linkState: enable
logLevel: info
networkNamespace: default
resourceName: rocebgr2
spoofChk: 'off'
trust: 'on'
vlan: 100SriovNetwork를 생성하면 자동으로 SriovNetwork기반 NetworkAttachmentDefinitions 리소스가 생성된다.
Deployment 생성 및 상태 확인
위에서 생성한 SriovNetwork를 가지고 각 Node에 Pod가 뜨도록 리소스를 배포한다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: rocebgr1
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: roce-test
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
annotations:
k8s.v1.cni.cncf.io/networks: |
[
{ "name": "rocebgr1" }
]
labels:
app: roce-test
spec:
containers:
- command:
- sleep
- infinity
image: >-
registry.hcloud.hmc.co.kr/library/nvidia/cuda:12.2.0-base-ubuntu22.04-roce
imagePullPolicy: IfNotPresent
name: test
resources:
limits:
nvidia.com/rocebgr1: '1'
requests:
nvidia.com/rocebgr1: '1'
securityContext:
capabilities:
add:
- IPC_LOCK
- SYS_RAWIO
- NET_ADMIN
privileged: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: rocebgr2
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: roce-test
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
annotations:
k8s.v1.cni.cncf.io/networks: |
[
{ "name": "rocebgr2" }
]
labels:
app: roce-test
spec:
containers:
- command:
- sleep
- infinity
image: >-
registry.hcloud.hmc.co.kr/library/nvidia/cuda:12.2.0-base-ubuntu22.04-roce
imagePullPolicy: IfNotPresent
name: test
resources:
limits:
nvidia.com/rocebgr2: '1'
requests:
nvidia.com/rocebgr2: '1'
securityContext:
capabilities:
add:
- IPC_LOCK
- SYS_RAWIO
- NET_ADMIN
privileged: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File생성된 Pod에 들어가보면 lo, eth0외에 net1 인터페이스가 신규로 생성된 것을 확인할 수 있다.
/# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
85: net1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP group default qlen 1000
link/ether 1a:16:7a:56:dc:60 brd ff:ff:ff:ff:ff:ff
altname enp157s0v6
inet 10.255.0.1/30 brd 10.255.0.3 scope global net1
valid_lft forever preferred_lft forever
inet6 fe80::1816:7aff:fe56:dc60/64 scope link
valid_lft forever preferred_lft forever
171: eth0@if172: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether a2:39:a1:e4:2b:5c brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.42.4.24/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::a039:a1ff:fee4:2b5c/64 scope link
valid_lft forever preferred_lft forever노드에서 확인해보면 VF 중 하나가 vlan100으로 할당된 것을 알 수 있다.
~# ip link show enp157s0np0
9: enp157s0np0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether c4:70:bd:e8:3f:b6 brd ff:ff:ff:ff:ff:ff
vf 0 link/ether 32:16:09:43:16:22 brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state auto, trust off, query_rss off
vf 1 link/ether 36:8c:40:53:d5:84 brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state auto, trust off, query_rss off
vf 2 link/ether d6:b1:6e:c3:78:f7 brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state auto, trust off, query_rss off
vf 3 link/ether 2a:6f:cd:d6:3f:e8 brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state auto, trust off, query_rss off
vf 4 link/ether 06:6a:5b:cf:67:10 brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state auto, trust off, query_rss off
vf 5 link/ether a2:35:0e:45:65:14 brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state auto, trust off, query_rss off
vf 6 link/ether 1a:16:7a:56:dc:60 brd ff:ff:ff:ff:ff:ff, vlan 100, spoof checking off, link-state enable, trust on, query_rss off
vf 7 link/ether d2:ff:ba:3d:b7:10 brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state auto, trust off, query_rss offPod 통신 테스트
동일 노드 위 pod간 net1 ping 통신은 성공하지만
서로 다른 노드 간 Pod에서 ping통신을 하면 패킷들이 모두 실패한다.
Node Routing 설정
*여러 라우팅 조건을 넣어 테스트 중이나 현재는 통신이 실패하는 상태이다. 추후 해결 시 업데이트 예정이다.
서로 다른 노드 간 Pod ping 통신 실패 원인
Pod net1은 Pod 내부에만 존재하는 가상 인터페이스이며, 노드에는 대응하는 net1 인터페이스가 없다.
노드 라우팅 테이블에는 Pod 서브넷으로 향하는 경로가 존재하지 않기 때문에 다른 노드에 있는 Pod IP로 ping을 보내도, 노드는 어디로 패킷을 보내야 할지 몰라 전송이 실패한다.
또한 VF에 VLAN 태그가 붙어있더라도, 노드에서 L3 경로가 없으면 ARP 요청이 전달되지 않아 통신이 불가하다.
라우팅 추가
노드에서 Pod 서브넷으로 가는 L3 경로를 명시적으로 추가해야 한다.
예시1) PF에 VLAN 인터페이스 생성
ip link add link name .100 type vlan id 100
ip addr add <GW_IP>/24 dev pf.100
ip link set dev pf.100 up
예시2) 노드 라우팅 테이블에 Pod 서브넷 경로 추가
ip route add <POD_SUBNET_CIDR> via <GW_IP> dev

혹시 서로 다른 node간 ping test 는 성공 하셨나요? 어떻게 해결하셨는지 궁금합니다!