
알고리즘 준비
-
백준 단계별 알고리즘 풀이
유형과 난이도 모두가 중요하다. -
카카오 : 난이도가 높은데 실제 문제와 관련된 코테가 나온다. ex) 택시의 경로에 따른 최소비용, 문자열 핸들링.
-
삼성 : 실제 구현을 많이 해봤어야 하는 문제들. ex) 큐브 - 오른쪽 몇 번, 위 몇 번 돌렸을 때 어떤 면이 나올 것인가. 돌리는 것을 어떻게 구현할 것인가.
-
기업마다 선호하는 기출 유형이 달라서 기출을 어떻게든 풀어보는 것이 좋다.
-
알고리즘은 수학과 비슷하다. 시간이 오래 걸린다. 꾸준히 공부해야하는 영역이라 사실상 지금도 시간이 된다면 적어도 하루에 한 문제 정도는 어떻게든 try 해보면 좋다.
백준이 좋은 점이 답을 사람들이 많이 풀어놓았기 때문에 답지를 많이 참고할 수 있다. 문제 한 30분 보고 고민하고 모르겠다 싶으면 답지 보고, 안보고 다시 풀이해보고, 이후에 또 풀어보고 유형을 풀이하고 또 난이도를 높여서 풀어보아야 한다. -
보통 수학 잘하는 애들이 잘한다. 수학을 못한다고 생각한다면 무조건 열심히 해야한다.
-
언어 같은 경우 굳이 파이썬이 아닌 자바를 사용해도 된다. 문자열 핸들링 같은 것들에 대한 내용. 개인적으로 자바를 많이 사용해서 자바. 그런데 확실히 파이썬이 짧고 쉽긴해서 좋다. 여러분의 선택이긴한데 어떤 걸 해도 상관 없을 것 같다.
api 호출을 여러 번 나눠서 하는 것이 좋을지, 한 번에 많은 데이터를 조회하는 것이 좋은지?
-
우리의 결론: 클라이언트-서버 간 요청을 나눠서 보내면 그만큼 비용이 소요되니까 << 여러번 api를 나눠서 보내는 것보다 << 한 번 api를 보내는 것이 나을 것이라 생각한다. 그렇다면 한 번에 응답하는 데이터 양은 어디까지 허용되는 것이 좋은가?
-
기존 서비스들을 참고하면 된다. (URI 복잡도 등도 인프런에서 해당 내용을 확인할 수 있다.)
-
인프런의 수강평을 예시로 들어보자.
만약 3000개인데 3k를 다 가져오면 서버의 메모리를 잡아먹고 시간을 소요하게 되는 것이다. 텍스트는 그 정도 보내도 크게 영향이 없지만, 프론트 처리 등의 문제가 있다. 그래서 '수강평 더 보기'를 클릭해서 서버에 추가 페이지를 요청해서 보내는 형태로 되어 있다. -
한 번에 호출할 때 얼마나 많은 데이터를 주는가. 는 사실 그렇게 영향이 없다. 향상된 컴퓨팅파워와 네트워크 덕분에 우리가 진짜 많이 보낸다고 생각해도 그렇게 느리지도 않고 크게 악영향이 없다. (특히 텍스트의 경우)
단, 프런트 측면의 관점을 생각해야한다. 데이터의 양을 얼마나 주는 것이 맞을지는 기획적으로 풀이하는 것이 좋다. -
일반적인 관점에서는 한 번에 많은 데이터를 보내주는 것이 좋다.
대신, 여러 번에 걸쳐서 나눠보내야하는 경우도 있다. 예를 들면 호출하는 자원이 여러 계층으로 나눠져 있는 경우가 있다.
community/rank/post?date=2023-09...
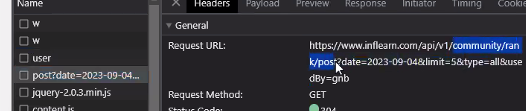
재활용성이 있는 것은 나눴을 때 더 좋을 수 있다.
그리고 기획적인 측면을 고려해야 한다.
ex)더보기api를 어떻게 만들지 -> 인프런에서 힌트를 볼 수 있다.
우리도 이렇게 다 보여주지는 못하고 '더보기'를 눌렀을 때 프론트가 api를 찌를 것은 만들어주긴 해야한다는 것이다. -
항상 대규모 서비스를 고민해서 이야기할 것을 생각해야 한다.
ex) 우리는 그냥 한페이지로 다 보여줬는데용? (x)
ex) 우리는 대규모 서비스 처리를 고려하기 위해 '더보기' 기능 등으로 무한 스크롤 데이터를 나누어 처리하는 방법을 고안하여 구현했습니다. (o) -
설계에 대한 고민이 있을 때는 다른 서비스를 찾아보는 것도 좋은 경험이다.
yml에서 숨겨야할 정보는 어디까지인가? 예를 들어, RDS 엔드포인트는 숨겨야 하는가?
-
현업에서는 엔드포인트까지 숨기지 않는다. 왜냐하면 private git을 사용하므로.
어차피 두 번째로는 방화벽으로 막아놓기도 한다. -
그래도 당연히 계정같은 정보나 로그인, 유저 등의 정보는 당연히 보호해야한다.
그래서 어떻게 사용하냐면 -> application.local.yml , application.dev.yml, application.prod.yml
profile 기능을 사용 한다.
로컬에서 돌렸을 때랑, 개발 환경에서 돌렸을 때랑, 기타 등등을 구분해서
중요한 정보들을 차등적으로 제외해가며 관리한다.
실제 서버 aws ec2 안에 username과 pwd 실제 값을 같이 넣어둔다. 실제 서버는 탈취될 염려가 없으니까? (멘토님께서 이렇게 말씀하셨음..) -
실제 중요하지 않은 것들만 git에 올려두고 실제 서버에 중요 값을 담아 둔다.
-
프로필 기능 살펴보기 / dev, stg, prd 환경에 대해 생각해보기,
git에 중요한 정보를 올리지 않는 방법과 환경별로 중요한 환경변수를 따로 관리하는 것 (서버에서 직접 파일 관리)
URI 구성이 복잡해졌을 때
-
URI 구성이 복잡해져도 괜찮나? (PatchMapping)
plantObj/1/leaf/1->body()로 변경될만한 값을 주는 것이 좋다. => plantObj 1번에 엮여있는 leaf 1번에 대한 값을 requestDto로 변경하기.- 설계 자체는 맞는 부분이다.
어떤 키워드로 찾아보아야 하는가?Restful API
- 설계 자체는 맞는 부분이다.
-
책을 하나 추천하겠다.
HTTP 완벽 가이드
기회가 되면 반드시 읽어보는 것이 좋을 것이다.
내용이 좋다.
URI 조작 대비
- 당연히 검증해야한다. 클라이언트가 보낸 변수값을 서버에서 검증하는 것이 맞다.
단, 반드시 SecurityContextHolder에서 처리해야만 하는 것은 아니다.
컨트롤러단에서도 Validation의 Exception처리에서 할 수 있다.
굳이 서비스단까지 갈 이유가 없다.
Entity에 setter를 사용하는 것
-
호불호다. 근데 호불호가 아니라 위험할 수도 있다. 특히 lombok의 @Setter => 모든 필드에 대해서 setter 메서드를 다 만들어 주기 때문이다.
데이터를 바꿀 수 있다는 것이 위험하다. 막 바꿀 수 있기 때문에 어디서 누가 setter를 사용해서 값을 변경했는지 파악하기 어렵다.- createdAt, modifiedAt, password 아무거나 아무거나 바꿀 수 있다는 '가능성'이 있기 때문에 어렵다.
-
핵심은 무분별하게 setter를 사용하는 것은 위험하다.
바꿔야할 데이터에만 해당 수정 메서드를 작성해서 사용해야한다.
네이밍은 update를 할 수 있는데, 바꿀 것만 setter를 지정해서 쓸 수 있다.
바꾸면 오히려 이상할 때는 정석적인setter로 쓰기도 한다.
테이블 개수가 많아지는 것?
-
~~Image 테이블을 너무 많이 만드는것이 안좋다?
그냥 테이블 자체가 많아서 생길 수 있는 문제와 동일할 것이다.
관리하기 어렵다는 그렇게 큰 문제가 될 수는 없다.
한 눈에 보기 힘들고 찾아다녀야하고 한 번 필드를 정의해놓으면 수정하기가 어렵다?
묶는 것은 상관없는데 -
상속관계를 만들어서 관리하는 것은 당연히 좋다.
상속 관계 주고 테이블 나눈 것은 그대로 유지하면 ok- 너무 좋다. 예를 들어 이미지 클래스 안의 이미지url, 원본파일이름 등의 공통 속성을 상속시키는 방향으로 ...
인터페이스와 클래스를 사용하는 기준
-
이게 참 어려운 것 같다. 대답하기 어렵다.
-
인터페이스는 약간 행동성이 강하다.
클래스의 '마린' implementation '하늘 공격' -> 마린은 하늘 공격이 가능하다. (단, 오버라이드 해야한다. (마린 -> 하늘 공격 데미지 5, 고스트 -> 하늘 공격 데미지 10) -
클래스, 추상 클래스는 진짜 추상화의 개념이다.
예를 들어 '사람' -> 마린, 고스트
인터페이스와 달리 필드도 존재한다는 의미가 있다. 특히 클래스는 오버라이드 할 필요도 없다.
-
현업에서는 거의 인터페이스를 사용하고 클래스, 추상 클래스를 상속하는 경우는 거의 없다.
딱 맞아 떨어지는 케이스가 거의 없어서.
파일upload를S3로 할 것인지EC2로 할 것인지 implementation 인터페이스하여 추상 메서드를 구현할 때 다른 방식으로 구현. -
class Board_image extens Image implementation 업로드- 업로드에 대한 추상 메서드 구현. -> EC2로 보낼 것인지, S3 보낼 것인지
좋아요 -> 주변에서 어떻게 하는지 참고 (인프런)
-
Q. 좋아요 선택 / 취소와 같은 경우에서 현재는 api 하나에 좋아요 실행/ 취소가 다 이루어지는 데 이걸 api 2개로 분리를 하는 것이 좋은지?.(현업에서 어떤 식으로 하는 지?)
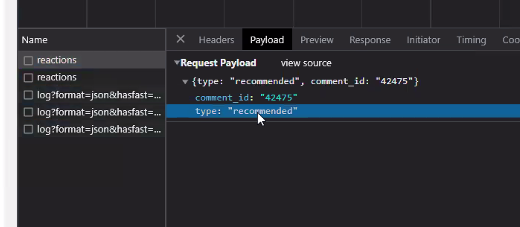
Type이 recommend로 들어가면 좋아요 , null로 들어가면 취소!
요청을 보낼 때 하나의 url로 요청을 하는구나.
(인스타그램도 똑같다.) -
⭐ 현업에서 어떻게 하는지 궁금할 때는 주변의 참고사항이 많다. 개발자도구를 켜고 api 요청 보내고 Payload 등 살펴보기
-
만약 두 개로 나눈다면 관리하기 더 어려울 수 있다. 예를 들어, 엔드포인트 등을 변경해야 할 때?

accountId를 받는 상황에 대한 고찰.
-
Q. 클라이언트에서 accountId를 받을 수 있는 상황에서 accountId를 받는 것이 좋을지, 혹은 받을 필요 없이 Spring Context Holder에서 사용자 로그인 정보를 꺼내오는 방식으로 하면 될지 궁금합니다. (성능상 차이가 있을까요?)
-
ThreadLocal 활용하기 . 검색해보자.
-
이미 로그인이 되었다면 사실 거의 accountId를 보내지 않는 경우가 많죠.
Mapstruct 사용?
-
Q. Mapstruct를 사용했을 때의 장단점이 궁금합니다. 매퍼 클래스를 별도로 분리하는 것이 좋을까요? 혹은 toEntity() 와 같은 형변환 메서드를 만드는 것이 좋을까요?
-
우리 같은 경우에는 굳이 매퍼클래스를 만들어서 하는 이점보다
toEntity를 사용하고 있다. 어차피 형변환 메서드를 구현하는 것은 똑같으므로.
(특수사항: 멘토님 회사에서는 RDB를 사용하는데도 관계가 모두 꺼져있어서 맵스트럭트를 더 쓸 일이 없었다.)
코딩 스타일이다.
이것도 팀에 가서 팀 스타일로 맞춰보는 것이 좋다.
EC2 호출 - RDS 호출 트레이드 오프
-
EC2 트래픽 량을 적게하는 설계가 좋을까요, RDS 호출을 적게 하는 것이 일반적으로 괜찮을까요?(JWT관점)
- jwt 토큰 내부의 payload에 accountId 같은 정보를 담아도 된다. 개인 정보를 너무 많이 담지만 마라.
-
케바케. EC2 jwt에 정보량을 증가시켰더니 헤더 길이가 너무 길어져서 트래픽 양이 많아졌다.RDS 호출 조금 하더라도 EC2 jwt 정보량을 빼자. 라는 식으로 트레이드 오프를 할 수 잇는 것이다.
- 부하테스트를 진행해서 진짜 트래픽량이 많이 걸리는지 실제 테스트를 해보는 자세가 중요.
이런 게 궁금하다. 헤더에 많은 정보를 담아보자. -> 근데 부하 테스트에서 실제로 테스트를 진행해봤더니 별반 차이 없더라. or 차이 있더라. 그래서 프로젝트 이렇게 개선했다. 이런게 키 포인트가 될 수 있다.
- 부하테스트를 진행해서 진짜 트래픽량이 많이 걸리는지 실제 테스트를 해보는 자세가 중요.
DBMS - DB 레코드 비어 있으면 안되는가?
Q.
id
1
2
3
을 지웠더니 다음 행에서는 다시 1이 나올 줄 알았더니 id가 4가 나온다.
null이 아닌가?
- 멘토님 : 별로 안될 게 없어 보인다.
신경 쓰인다면 id를 채번하는 테이블을 초기화 하는 방식으로 새롭게 채번을 할 수 있다.
다만 이렇게 하지 않더라도 null 값으로 할당되는 것이 아니라 단순히 증가된 id를 채번시켜주는 것 뿐이다.
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=hanajava&logNo=220554545738
게시판 공유 서비스 구현
-
Q. 게시판과 식물 카드 일지 설계 시에 일지를 작성할 때 게시글로도 등록하게끔 설계를 했는데, 구현상의 어려움이 있습니다. 동일한 레코드가 각각 다른 테이블로서 존재하는 것이 맞을지, 혹은 애초부터 다른 테이블로 설계하는 것이 맞는지 궁금합니다. (게시물 공유)

Board가 더 넓은 개념이고 journal이 더 작은 개념인데
type을 사용해서 구분하여 Board에서 표현할 때는 다 보여주고
journal을 사용할 때는 해당 타입만 보여준다. -
동일한 데이터를 두 번 저장하는 것은 비교적 좋은 방법이 아님 -> 동기화 이슈
MSA 상황에서 특정 서버에서 성공하고 특정 서버는 실패했다. 그럼 데이터 무결성 측면에서 한 서버의 DB는 업데이트 되고, 다른 서버의 DB는 업데이트 되지 않는다.
Garden 보류? 추가?
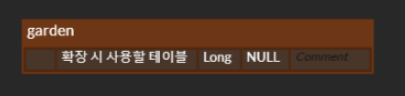
- Garden 현재 필요없는 테이블이지만 미래에 필요할 수도 있는 테이블.
(맵 형태를 변경하거나, Garden 개수를 다양하게 가지던가.)
그런 경우에 유지보수의 어려움이 있을지, 미래를 예측하는 설계와 고민을 하는 것이 분명 도움이 된다.
RDB의 관계를 끊어놓고 사용하는 것?
-
멘토님이 RDB의 관계를 끊어놓고 사용한다는 말의 의미?
-
팀원 모두의 JPA에 대한 이해 수준이 높지 않아서.
양방향 매핑 관계에서 정보업데이트 메서드를 다음과 같이 적용했을 때 성능상의 문제가 있을까?
-
stream은 비동기 병렬처리로 발생해서 속도 측면에서 큰 이슈는 없을 것 같다.

