TODO
DataServer에서 매번 토큰을 체크하고 인증하는 middleware방식 대신, 한번 Authorization된 클라이언트라면 절차를 생략하고 허용된 시간동안 imgae, json을 upload할 수 있는 권한을 부여할 수 있는 방법을 고민하게 되었다.
- 이미지와 json파일을 요청할 때마다 uuid를 서버에 보내는 방식은 비효율적이다.
- 이미지가 100, 1000, 10000개 등 증가할 때마다, 매번 uuid_token검증을 위해 데이터베이스를 매 요청마다 조회하는 것은 비효율적이다.
- 특히 요청의 수가 많아질수록 데이터베이스에 대한 부하가 증가하고, 전체적인 응답 시간도 길어지게 될 것이다.
- 서버 입장: 매 작업마다 데이터베이스를 조회하고, 인증 과정을 거치는 것도 비효율적임
- 클라이언트 입장: 클라이언트에 민감한 데이터 정보가 그대로 저장되어 있기 때문에 보안에 token을 탈취 당했을 경우, 데이터가 유출되거나 탈취된 토큰을 이용하여 시스템 자원을 남용할 수 있음
- 대안으로 생각할 수 있는 것: Redis, Memcached같은 인메모리 데이터 스토어를 사용해 볼 수 있다.
1. HTTP 비연결성과 비상태성
1.1 HTTP 비연결성
- HTTP는 요청과 응답을 한번 주고 받으면 바로 연결을 끊어버리는 특성을 가지고 있다.
- 그리고 다음 요청을 하기 위해 다시 연결을 맺어야 한다.
- 이를 HTTP의 비연결성이라고 한다.
1.2 HTTP 비상태성
- HTTP 프로토콜은 요청과 응답을 교환하는 동안 상태를 저장하지 않는다.
- 따라서, HTTP레벨에서는 이전에 보냈던 request, response를 기억하지 못한다.
- 요청은 직전의 요청과 전혀 관련이 없다. 이를 HTTP의 비상태성이라고 한다.
- HTTP 비상태성의 장점?
- 연결을 맺을 때 발생하는 오버헤드가 줄어든다.
- 데이터를 빠르고 확실하게 처리할 수 있다.
- 요청간의 상태를 공유하지 않으므로 확장성을 갖는다.
- 이런 특징이 생겨난 이유는 처음 HTTP가 등장할 때 단순히 HTML문서만을 주고 받는것이 목적의 전부였기 때문에, 최대한 단순하게 설계되었기 때문이다.
- HTTP 비상태성의 한계
- 하지만 웹이 발전하면서 요청과 요청간의 상태가 유지되어야 할 필요가 있어졌다. 상태가 유지되지 않으면 사용자는 페이지를 이동할 때마다 새롭게 로그인을 해줘야 할 것이다.
- 이렇게 상태가 유지될 수 있는 이유는 바로 Cookie라는 개념이 등장했기 때문이다.
2. 쿠키 (Cookie)
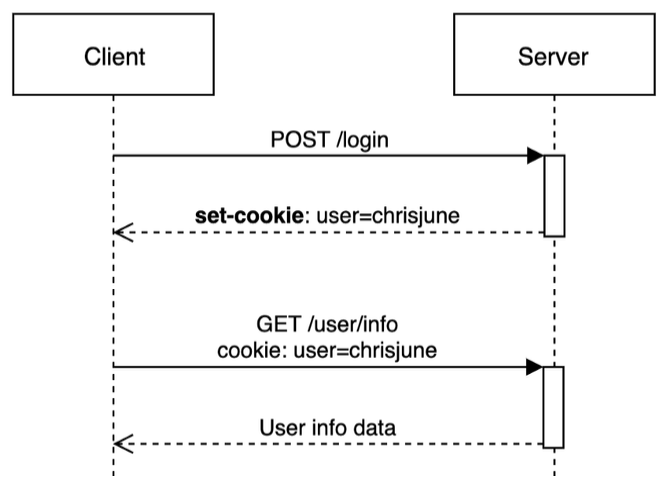
- HTTP의 비상태성을 보완하기 위해 쿠키라는 개념이 등장했다.
- 쿠키는 HTTP요청과 응답에 함께 실려 전송된다. 쿠키는 클라이언트, 즉 브라우저에 저장된다.
- 웹 서버가 클라이언트로 보내는 응답의 헤더 중 set-Cookie라는 헤더에 키와 값을 함께 실어 보내면 그 응답을 받은 브라우저는 해당 쿠키를 저장하고, 그 다음 요청부터 자동으로 쿠키를 헤더에 넣어 송신한다.
- 성능이슈: 쿠키는 한번 생성되면 매 요청마다 헤더에 실려 서버로 전송된다. 만약 쿠키에 저장된 정보가 너무 많다면, 매번 요청마다 큰 오버헤드가 발생할 것이다. 이러한 이유로 일반적인 쿠키의 데이터는 4kb로 제한이 되어있다. (사이트당 쿠키의 갯수 제한: 20개)
- 보안이슈: 쿠키는 클라이언트 측에 저장된다. 만료시각을 명시하지 않으면 쿠키는 메모리에 저장되어 브라우저를 종료하면 휘발되지만, 만료시각을 명시하면 파일로 저장되어 브라우저가 종료되더라도 휘발되지 않는다.
3. 세션 (Session)
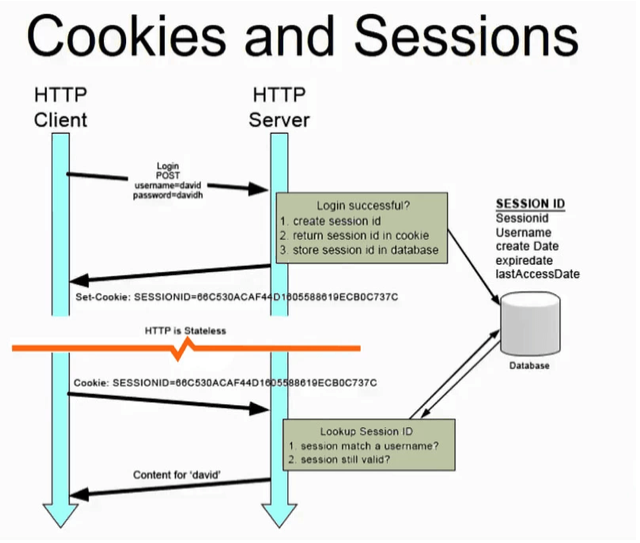
- 쿠키는 클라이언트에 민감한 정보를 헤더에 저장하는 방식으로 보안이슈와 성능이슈가 발생했다면 이를 보완하고자 한 것이 session이다.
- 세션은 쿠키와 다르게 정보를 서버측에 저장하는 방식이다.
- 브라우저로 웹 서버에 접속한 시점부터 브라우저를 종료하여 연결을 끝내는 시점 까지의 일련의 요청을 하나의 상태로 간주하고, 그 상태를 일정하게 유지하는 기술이다.
3.1 세션 생성 과정
- 클라이언트가 body에 인증 정보를 실어 서버로 보낸다. (ex. id, password 등)
- 서버에서는 해당 인증정보가 유효하면 사용자와 데이터를 식별하는 sessionID를 생성한다.
- 생성된 sessionId는 set-Cookie로 생성된 세션아이디를 header에 담아 클라이언트에게 전송한다.
- 클라이언트는 해당 세션 아이디를 쿠키에 저장하고, 매 요청마다 세션 아이디를 cookie header에 서버에 전송한다.
- 서버는 세션 아이디를 통해 해당 요청의 송신자가 누구인지 식별할 수 있다.
4. Redis, JWT(Json Web Tokens)
✨ 대안: 캐싱 사용
- 캐싱은 데이터를 자주, 빠르게 접근할 수 있는 저장소에 임시로 저장하는 기술이다.
- uuid_token검증 정보를 캐싱하여 데이터베이스 조회를 최소화할 수 있다.
- 구현 방법
- Redis나 Memcached와 같은 인메모리 데이터베이스를 사용하여 캐시 시스템을 구축한다.
- 서버가 uuid_token을 검증할 때, 먼저 캐시에서 해당 토큰을 조회한다.
- 캐시에 토큰이 존재하면, 데이터베이스 조회 없이 바로 검증 절차를 진행한다.
- 캐시에 토큰이 없는 경우에만 데이터베이스에서 토큰을 조회하고, 검증 후 캐시에 저장한다.
- 캐시된 데이터는 일정 시간 후에 만료되도록 설정할 수 있다.
- 장점
- 데이터베이스 부하를 크게 줄일 수 있다.
- 응답 시간을 단축하여 애플리케이션의 성능을 향상시킬 수 있다.
- 고려할 점
- 캐시 서버에 문제가 발생할 경우를 대비하여, 캐시 미스 시 데이터베이스에서 정보를 가져올 수 있는 백업 로직이 필요함
- redis 설치 및 실행
- redis 설치 https://github.com/microsoftarchive/redis
- redis 실행
-
The server is now ready to accept connections on port 6379 에서 실행이 기본임
redis-server.exe
-
- redis 설치 https://github.com/microsoftarchive/redis

- Key 값 설정 규칙
- Key의 최대 길이는 512MB이다. (value도 마찬가지)
- 매우 긴 키는 좋지 않다. 예컨데 1MB 길이의 키는 메모리 관리 측면 뿐만 아니라 키를 조회할 때 고비용의 키 비교 로직을 실행해야 할 수 있기 때문에 나쁜 생각이다. 키 값이 너무 길다면 차라리 SHA-1 등으로 해싱하라.
- redis를 쓰는 주요한 목적이 빠른 응답속도를 보장받고자 함임을 생각해보면 성능을 악화시킬 수 있는 요소는 최대한 배제하는 게 좋다고 생각.
- 매우 짧은 키 또한 좋은 생각이 아니다.
user:1000:followers대신u1000flw로 사용하는 것은, 메모리상 이득은 작고 가독성은 해치는 것이다. (key가 차지하는 공간은 value에 비해 작기 때문에) 비록 작은 메모리상 이득은 있지만, 가독성과 메모리 효율사이의 적당한 균형을 찾아야 한다. - 고정된 스키마를 활용해라. object-type:id 형식은 좋은 생각이다. ex) user:1000 만약 여러 단어를 조합해야 할 일이 있으면,
.이나-가 주로 활용된다.
ex)comment:4321:reply.to,comment:4321:reply-to
- 매우 긴 키는 좋지 않다. 예컨데 1MB 길이의 키는 메모리 관리 측면 뿐만 아니라 키를 조회할 때 고비용의 키 비교 로직을 실행해야 할 수 있기 때문에 나쁜 생각이다. 키 값이 너무 길다면 차라리 SHA-1 등으로 해싱하라.
- Value: String type 등
🪄 적용: Redis에서 [Key] Device_Owner_ID : [Value] 사용자의 uuid_token
-
🚨 앞서 이야기한 것처럼, 캐시 서버에 문제가 발생할 경우를 대비하여, 캐시 미스 시 데이터베이스에서 정보를 가져올 수 있는 백업 로직이 필요하다.
-
캐싱 로직 추가:
- 미들웨어에서 요청을 처리하기 전, Redis 캐시를 조회
- 캐시 서버에 uuid_token이 존재한다면, 다음 미들웨어로 넘어감
- 캐시 서버에 uuid_token이 존재하지 않는다면, 데이터베이스에서 조회한 후 조회된 uuid_token을 redis에 저장
-
캐싱 기간 설정
- Redis에 데이터를 저장할 때는 적절한 만료 시간(TTL, Time-To-Live)을 설정하는 것이 중요하다. → 데이터 신선도 유지
-
에러 처리
- Redis작업 중 발생할 수 있는 예외를 처리 해야한다. Redis서버가 다운되었을 경우 애플리케이션은 계속적으로 정상 동작해야 하기 때문이다.
-
코드 예시
const redis = require('redis');
const client = redis.createClient(); // Redis 클라이언트 설정
module.exports = function setupUploadMiddleware(dbConnection) {
return async (req, res, next) => {
const token = req.headers.token;
const cacheKey = `auth:${token}`; // Redis에 저장될 키
// Redis에서 캐시된 값을 조회
client.get(cacheKey, async (err, cachedData) => {
if (err) {
// Redis 에러 처리
console.error('Redis error', err);
return res.status(500).send('Internal Server Error');
}
if (cachedData) {
// 캐시된 데이터가 있다면, 바로 다음 미들웨어로
return next();
} else {
// 캐시된 데이터가 없다면, DB에서 조회
try {
const result = await deviceRepository.findDeviceNameByOwnerId(req.headers.device_owner, req.headers.device_name, dbConnection);
if (result.length > 0 && result[0].http_token == token) {
// DB 조회 결과를 Redis에 저장
client.setex(cacheKey, 3600, JSON.stringify(result[0])); // 3600초 동안 캐시 유지
return next();
} else {
return res.status(401).send('HTTP auth (token) error');
}
} catch (error) {
console.error('DB error', error);
return res.status(500).send('Internal Server Error');
}
}
});
};
};
const client = redis.createClient(); // Redis 클라이언트 설정
-
node.js 애플리케이션이 Redis 서버의 클라이언트가 되어 서버와 통신할 수 있는 연결을 생성하고, 이 연결을 관리하는 Redis클라이언트 객체를 반환함.
-
즉, node.js는 redis모듈을 사용해 Redis 서버와의 통신을 담당한다. node가 redis.createClient()를 호출하면 Redis 서버에 연결하기 위한 클라이언트 객체를 생성한다. 이제 Redis 서버에 데이터를 쓰거나, 데이터를 읽는 등 작업을 수행할 수 있다.

기억을 위한 기록 :>