🙌🏻 해당 글은 김시훈님의 mongoDB 기초부터 실무까까지의 강의 노트입니다.
데이터가 많아지면서 느려지는 탐색시간
지금까지는 호출 빈도를 줄이는 것에 초점을 맞추었다. 그러나 어떻게 호출 빈도를 줄이든 모든 API에서 탐색 과정이 계속해서 발생한다. Delete를 할 때도 일단 먼저 탐색을 한다. (결국 탐색이 늦어지면 모든 오퍼레이션이 다 느려진다.) 이번 세션에서 다룰 것은 탐색 자체를 빠르게 하는 법이다. 데이터가 너무 많이 쌓이면 find라는 오퍼레이션 자체가 오래 걸리게 된다. 그것을 해결할 수 있는 것이 바로 Index이다.
Index 원리 이해하기
콜렉션에 여러 가지 age와 타입이 담긴 여러 개의 문서가 있다고 생각하자. Model.find({age: 53})이 주어지면 무조건 N번 연산해야 한다. 때문에 데이터 양에 비례해 탐색 속도가 느려진다. 우리가 사전에서 단어를 빠르게 찾을 수 있는 이유는, 사전에 들어 있는 단어들이 정렬되어 있기 때문이다.
우리도 데이터베이스에 담긴 데이터들을 정렬해줄 것이다. 물론 하드디스크에는 그대로 저장된다. 대신 데이터들의 주소들에 인덱싱을 하는 거다. 몽고디비가 이 역할을 해준다. 인덱스에 각각의 문서 주소가 저장되도록 하는 것이다. 이러면 아까와 같은 상황에서 logN의 복잡도가 나올 수 있다.
탐색 성능 테스트를 위한 데이터 생성
await generateFakeData(100000, 5, 20);일단 십만 명의 유저를 만들어주자!
Index 성능 테스트하기

몽고디비 compass를 이용해 위 사진과 같이 index를 조회해줄 수 있다.
_id가 아닌 username에는 왜 인덱스가 걸려있을까? 이는 중복되는 유저네임이 없도록 방지해주는 것이다. 유니크인지 아닌지를 판단해주는 것! 새로 작성하는 유저네임이 기존 유저네임 중에 있는지 없는지를 빠르게 판단해주는 역할을 한다!
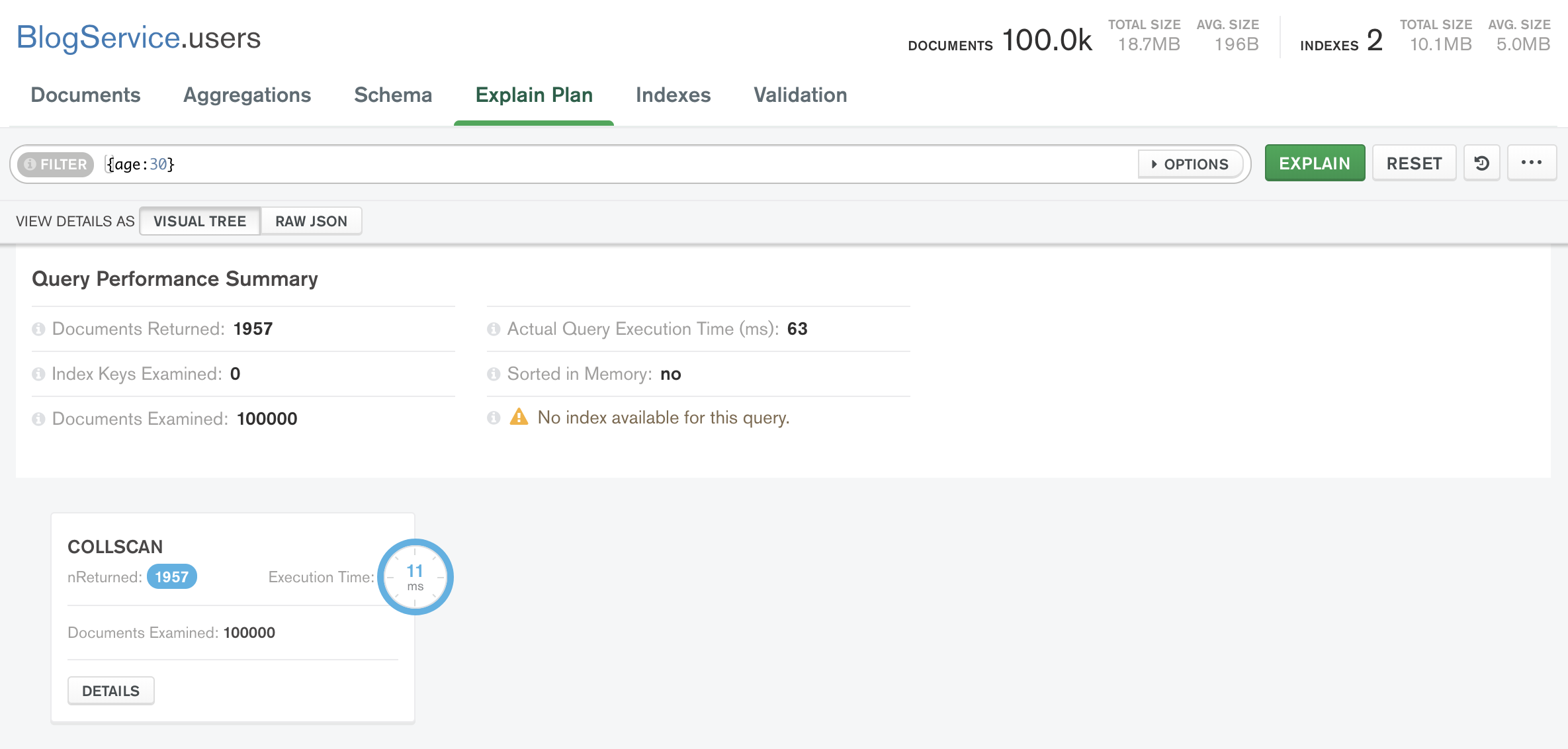
explain plan에서 조회하면 검색 성능을 분석해준다.

age에 해당하는 인덱스를 생성해주고나서 다시 성능을 분석해보면!

개선된 속도를 확인할 수 있다!
아까는 콜렉션 전체를 스캔하는 COLLSCAN 이었는데 이제는 인덱스를 기준으로 스캔하는 IXSCAN으로 바뀌었다!
좀 더 성능차이가 있는 상황을 가정해보자!
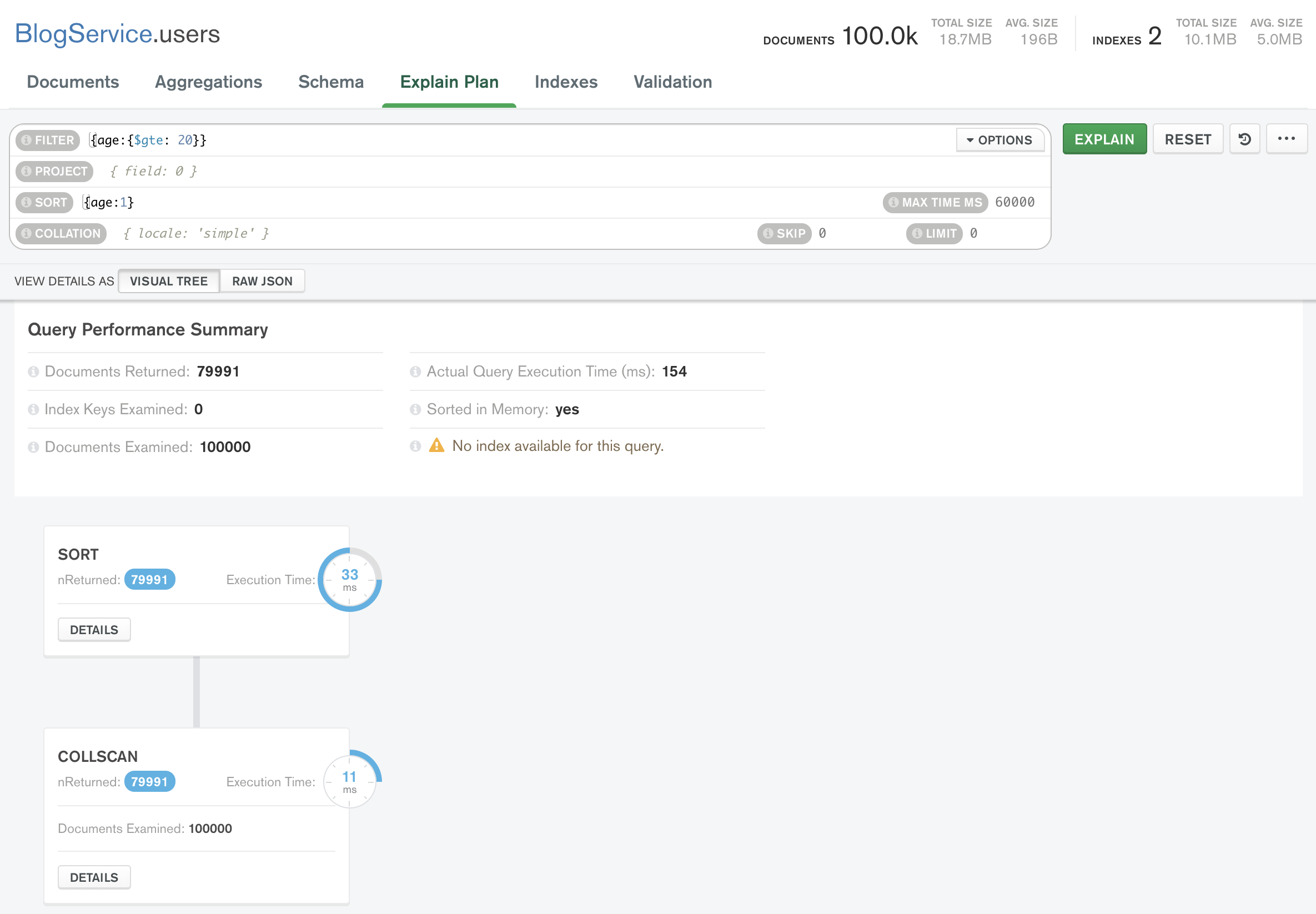
이건 정렬까지 해주는 경우이다. 확실히 아까보단 시간이 더 걸리는 걸 확인할 수 있다!
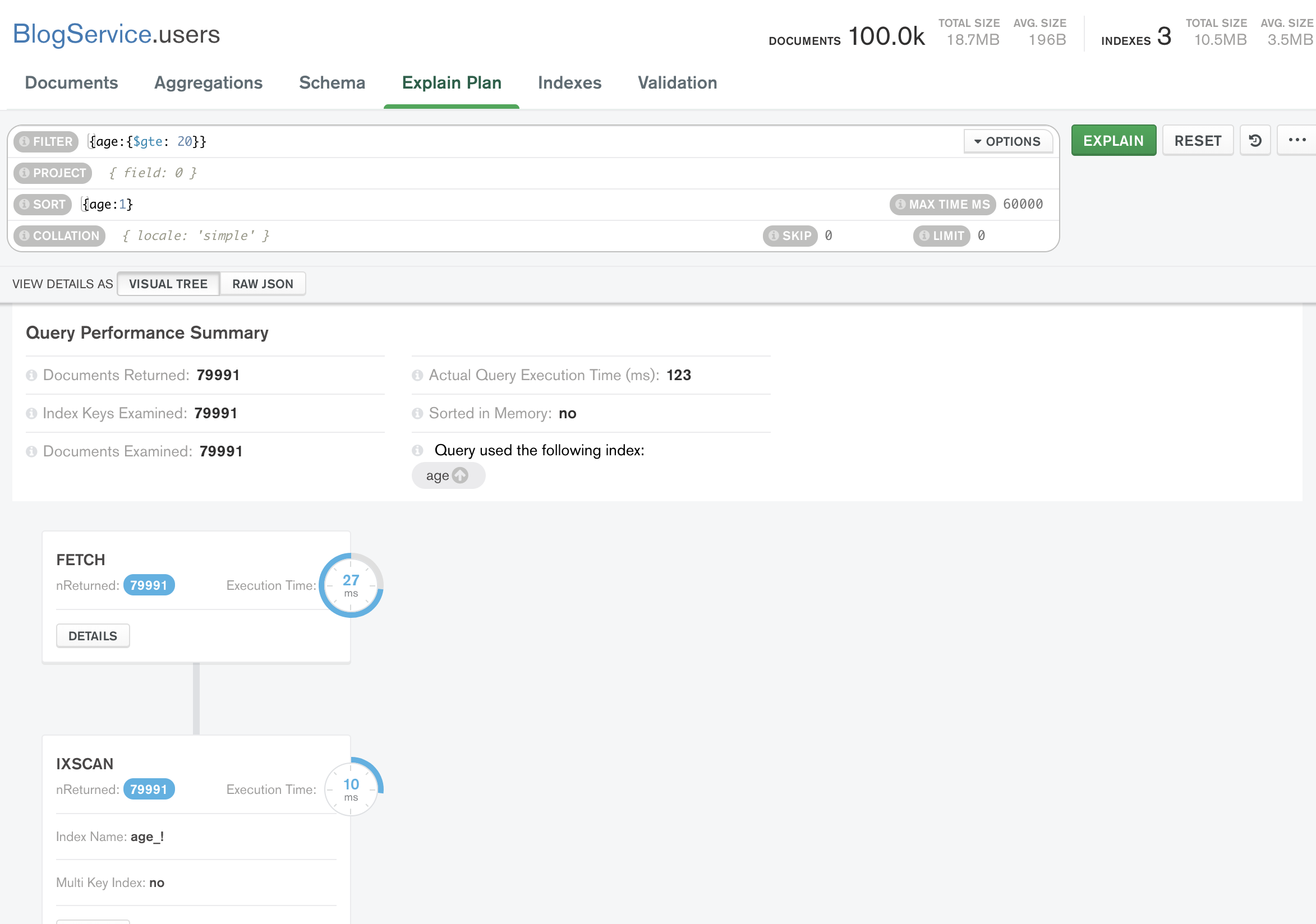
이걸 인덱스를 추가해주고나면 이렇게 조금은 시간이 개선된것을 확인할 수 있다!
이게 단일키라면 내림차순 오름차순에 성능차이가 없다는 것도 알아두자.
(대칭이니까!)
Pagination 원리
트래픽이 많을 때는 빨르게 대응하는 것이 중요하다. 그런데, 트래픽이 많더라도 한 화면에 많은 데이터를 전부 동시에 보여줄 필요는 없다. 유저가 원하는 특정한 정렬로 정리를 해주고 부분 부분 불러와 보여주면 된다. 그게 바로 pagination의 접근법이다.
<인덱스 없이 Pagination하기>
- step1: 인덱스가 없는 문서들이 있다
- step2: 컬렉션 스캔으로 원하는 문서들을 골라낸다.
- step3: 정렬한다.
- step4: pagination!
인덱스를 걸면 우선 step2에서 인덱스스캔을 해주기 때문에 속도가 빨라지고,
step3의 정렬과정이 생략된다.
압도적으로 빠르다.
0초걸림....!
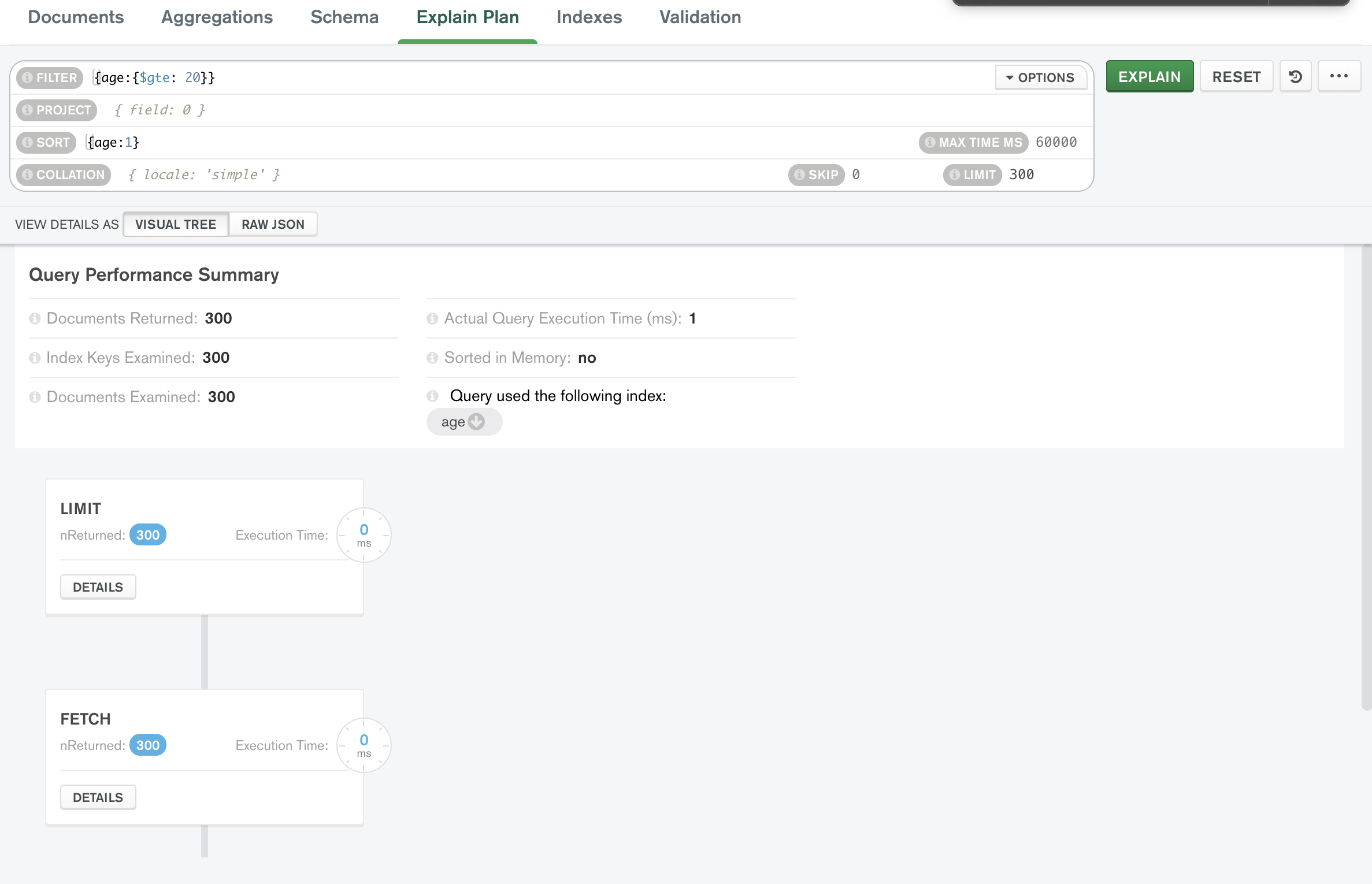
페이지네이션을 잘 쓰면 데이터가 많아도 빠르게 불러올 수 있다!
근데 눈여겨 볼만한 점이 스캔할 때는 일단 문서들을 다 불러온다.
때문에 마지막 부분을 페이지네이션으로 가져오면 시간이 좀 더 걸리긴함
(마지막 부분은 사실 정렬을 뒤집어주면 빠르게 할 수 있다.)
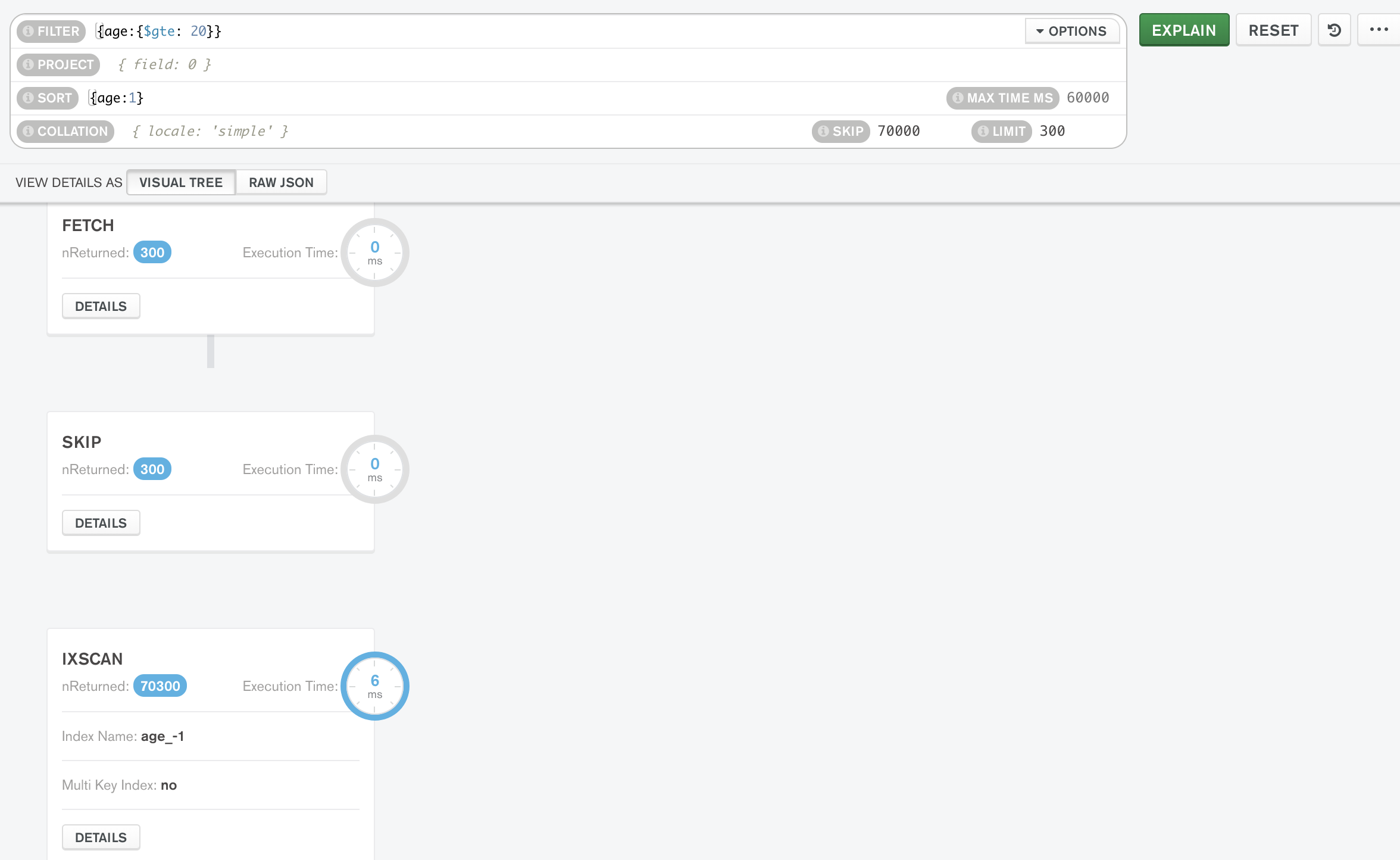
보통 상용서비스에서 1, 2, 3, ... , 98, 99 100 이렇게 페이지 설정된 이유가 다 있다!
양 끝을 시작점으로 생각하면 결국 중간 부분으로의 바로 진입은 어렵다는 걸 알 수 있다.
GET /blog API에 Pagination 적용
보통 pagination은 API를 따로 만드는 것이 아니라, 변수로 page에 대한 정보를 넘겨준다.
?page=0&sort=1 이런 문법으로 보낸다.

변수들을 보내면, 그것들을 이용해 pagination을 적용해준다.
let { page } = req.query;
page = parseInt(page);
let blogs = await Blog.find({})
.sort({ updatedAt: -1 })
.skip(page * 3)
.limit(3);
// .populate([
// { path: "user" },
// { path: "comments", populate: { path: "user" } },
// ]);
return res.send({ blogs });
이렇게 pagination이 적용되어, 3개 씩만 조회되는 것을 볼 수 있다.
Compound Key(복합키)
여러 개의 key를 통해 정렬하고 싶을 때 복합키를 사용한다.

복합키 설정할 때는 순서에 유의해야 한다.
예를 들어 age_username으로 적용한 경우 age로 먼저 정렬한 것을 username으로 정렬하는 것이다.
때문에 막연하게 뒤집어서 사용할 수도 없다.
(대칭일 때만 똑같은 키 적용 가능하다.)
복합키는 원하는 만큼 더 깊게 갈 수도 있다!
Selectivity - 분포도를 고려해서 효율적으로 인덱스 생성
만약 필터조건, 적용가능한 인덱스가 여러 개라면, 몽고디비는 일단 여러개 모두를 이용해 조금만 탐색을 해본다. 그리고 나서 가장 효율적일 것 같은 인덱스를 키로 사용해 탐색을 한다. 그렇게 선택된 경우가 아래 이미지의 winningPlan이고, 제외된 경우가 rejectedPlans이다.
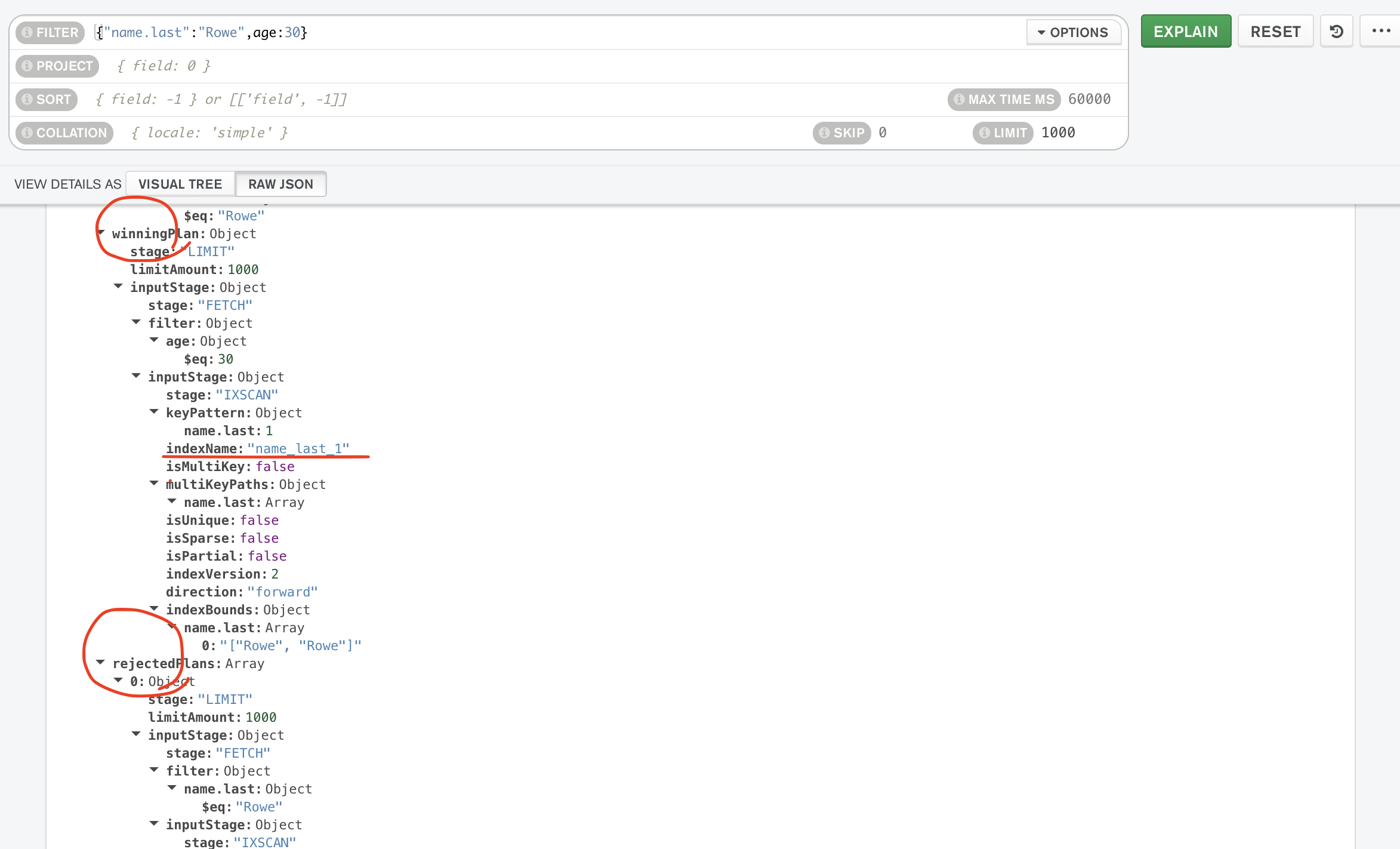
rejectedPlans에는 여러 플랜이 배열로 담겨서 온다.

좋은 인덱싱이란 무엇일까?
그렇다면 좋은 인덱싱은 무엇일까? 바로 분포가 잘 된 문서들을 대상으로 적용된 인덱스!
우리는 분포가 잘 안 된 경우를 셀렉티비티가 떨어진다고 한다. 좋은 인덱싱이란 셀렉티비티가 뛰어난 인덱싱이다. 우리가 언급하지 않은 것은 사실 인덱스도 데이터 공간을 차지한다. 원래 인덱스를 생성하면 하드에 인덱스가 저장되긴 하지만, 서버를 키면 이것을 몽땅 메모리에 올려놓는다. 때문에 인덱스를 남발하는 것은 절대 바람직한 선택이 아니다.
(사실 분포가 넓지 않으면 인덱스 스캔을 해도 효과가 별로 없다. 스캔한 애들을 상대로 또 COLLSCAN해야 하니까. 그냥 메모리만 많이 차지하게 된다.)
특히 CRUD에서 인덱스가 생성되면 R은 빨라질지 몰라도, CUD는 느려진다. 저장 할 때도 위치에 맞춰서 저장을 해주어야 하니까.
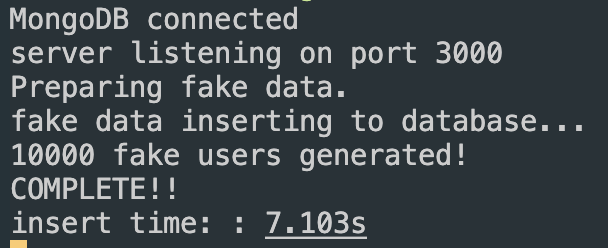
그럼 인덱스 있을 때와 없을 때 데이터 생성 시간을 체크해보자!
app.listen(3000, async () => {
console.log("server listening on port 3000");
console.time("insert time: ");
await generateFakeData(10000, 5, 20);
console.timeEnd("insert time: ");
});
인덱스를 다 지우면!

초반에는 사실 인덱스 없어도 별 성능에 차이 없다!
무작정 추가하는 게 아니라, 진짜 데이터가 많아지고 난 후에 트래픽 보고 자주 쓰이는 쿼리들에 대해 인덱스를 생성해주는 게 좋다.
Mongoose로 Index 생성하기
이제 코드 상으로 Mongoose를 통해 Index를 생성해줄 것이다.
분석할 때는 물론 Atlas를 이용한다. 코드에서는 스키마를 보고 바로 바로 적용해줄 수 있다는 장점이 있다.
물론 어디서 적용하든 크게 상관이 없다.
블로그 스키마에 Index 적용
const BlogSchema = new Schema(
{
title: { type: String, required: true },
content: { type: String, required: true },
islive: { type: Boolean, required: true, default: false },
user: {
_id: { type: Types.ObjectId, required: true, ref: "user" },
username: { type: String, required: true },
name: {
first: { type: String, required: true },
last: { type: String, required: true },
},
},
comments: [CommentSchema],
},
{ timestamps: true }
);
// BlogSchema.index({ "user._id": 1, updatedAt: 1 }, { unique: true });
BlogSchema.index({ "user._id": 1, updatedAt: 1 });코멘트 스키마에 Index 적용
const CommentSchema = new Schema(
{
content: { type: String, required: true },
user: { type: Types.ObjectId, required: true, ref: "user", index: true },
userFullName: { type: String, required: true },
blog: { type: Types.ObjectId, required: true, ref: "blog" },
},
{ timestamps: true }
);유저 스키마에 Index 적용
const UserSchema = new Schema(
{
username: { type: String, required: true, unique: true },
name: {
first: { type: String, required: true },
last: { type: String, required: true },
},
age: { type: Number, index: true },
email: String,
},
{ timestamps: true }
);text index 생성하기
이번 레슨에서는 text index에 대해서 다룬다.
BlogSchema.index({ title: "text", content: "text" });
// 텍스트키는 하나만 만들 수 있음, 두 개 하고 싶으면 복합키 만들어야 함!물론 몽고디비에 내장된 더 좋은 검색엔진도 있다고 한다.
해당 부분은 직접 서치하는 것으로...