🛑 해당 포스팅은 패스트캠퍼스 온라인 강의 The RED : 조은의 프론트엔드 실무 가이드 강의 필기 입니다.
프론트엔드 개발자라면 결국 웹에서 발생하는 문제들에 대해 알아야 한다. 이 때 웹에서 일어나는 문제들이라고 하면 조금 추상적일 수 있다. 브라우저에서 일어나는 모든 일에 대해 알아야 한다, 고 하면 덜 추상적일까? 이 역시도 다소 막연할 수 있다.
프론트엔드 개발자의 1순위는 브라우저이고, 브라우저에서 일어나는 모든 일을 처리할 수 있어야 하는 건 알지만, 브라우저에서 일어나는 모든 일의 핵심을 꼽는다면 무얼 꼽아야 할까?
프론트엔드 개발자의 역할!?
유저가 브라우저를 통해 사이트에 접속하면 벌어지는 워크 플로우를 간단히 요약해보자!
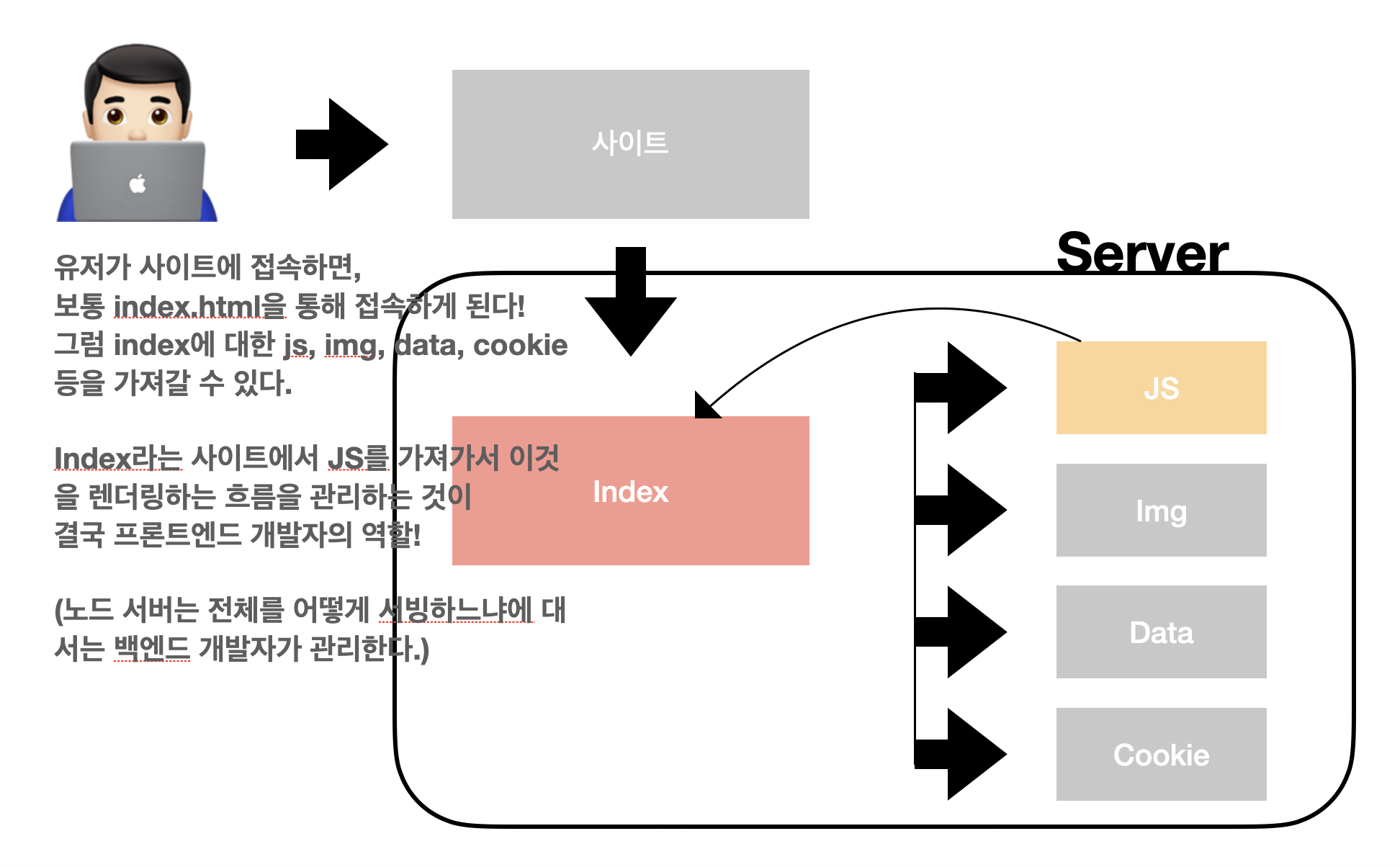
여러 유저가 동시 다발적으로 사이트에 들어온다면?
여러 유저가 동시 다발적으로 사이트에 들어온다
▶️ 트래픽이 높아진다
▶️ 우린 어떻게 대응하지?
Server란 결국 24시간 돌아가는 컴퓨터이다. 24시간 돌아가는 컴퓨터에 트래픽이 몰리면 서버의 사용량이 증가한다. 계속해서 더 많은 트래픽이 몰리다보면 서버가 죽는다. 서버가 죽게되면 결국 클라이언트에도 영향을 미치기 마련이다. 클라이언트 개발자는 서버가 왜 죽었는지, 살리려면 어떻게 해야하는지, 서버에 대해 모니터링을 해야 한다. 이걸 status check, 혹은 헬스모니터링이라고 한다.
트래픽을 감당하기 위해서는 서버를 유연하게 늘리고 줄일 수 있어야 한다. 이것을 scaling이라고 한다. 물론 유저들이 짧은 시간내에 몰리면 대기열을 만들어 유저의 접속을 막는 경우도 있다. 그러나 scaling 대응이 가능한 구조를 미리 짜놓았다면, auto-scaling이 가능하기에 대기열을 만들 필요가 없다. (사실 클라우드 서버를 사용하면 거의 자동으로 스케일링이 관리된다.)
우리는 지금부터 이 "트래픽 관리"에 집중해서 프론트엔드 개발자가 알아야 할 것들을 정리해보자.

트래픽 대응은 단순히 "서버 늘려"로 귀결되는 문제가 아니다!
AWS를 사용하거나 Vercel을 사용하면 서버의 가용성을 확인할 수가 있다. 그렇다면 서버 가용성이 100%에 도달했을 때 우리는 어떻게 해야 할까? "서버 늘려!"만 주구장창 외치면 되는 것일까? 클라이언트단, 브라우저를 가장 잘 이해하고 있는 것은 결국 프론트엔드 개발자이다. 프론트 단에서 기여할 수 있는 트래픽 대응이 분명히 존재한다.
지금까지 유저들 사이트에 접속하면 트래픽이 발생한다고 했지만, 사실 트래픽이라는 건 서버에서 응답을 내려주면서 발생하는 일에 가깝다. 클라이언트에서 유저가 리소스를 가져가면서 트래픽이 발생하는 것이다.
그렇다면 결국 트래픽을 컨트롤하기 위해서는 리소스 최적화가 무엇보다 중요하다고 할 수 있다. 예를 들어 파일 크기를 관리하거나 캐싱을 관리하는 것이 있다. 유저가 이미지 등의 리소스를 요청할 때마다 주는 것이 아니라, 캐싱을 해놓았다가 제공해줄 수도 있을 것이다. 유저의 트래픽을 결정하는 건 결국 서버에서 관리하는 전체 리소스가 얼마나 되는 용량인지, 데이터를 불러오는 레이어, DB와 얼마나 자주 통신하는지 등과도 밀접한 관련이 있다. 또, API 서버가 죽으면, API를 캐싱해두었다가, 웹페이지는 일단 띄우는 식으로 Offline 대응을 할 수도 있을 것이다. 다양한 레이어에서 트래픽을 줄이기 위해서 노력을 해야 서버가 튼튼해진다.
SSR이든 SPA이든, REACT이든 정적사이트이든, MSA를 가져가든 MFA를 가져가든 웹에서 발생하는 문제에 대한 이해도가 없이는 해당 기술들을 피상적으로 이해할 수밖에 없다! 웹에서 발생하는 트래픽 이슈를 분명하게 이해하자!
