
주제: 군집자료형
-
단일(single): numeric(int, float, complex), bool
-
군집(container): list, tuple, dictinary, set
-> 임의의 자료형의 원소를 여러 개의 담을 수 있는 자료형들
1. 리스트
1.1 특징
- 여러 데이터를 한꺼번에 보관 / 컨테이너 자료형
- 원소는 어떤 자료형도 수용가능
- 원소의 순서가 중요 / 순서 접근 순서
- 원소의 개수와 내용은 수시로 바꿀 수 있음 / 가변형
1.2 슬라이싱
(1) 구간 추출
✍입력
L = [1,9,3,2]
L[1:2+1:1]💻 출력
[9, 3](2) 부분 교체
✍입력
L = [1,9,3,2]
L[1:3] = [99, 101]💻 출력
[1, 99, 101, 2](3) 부분 삭제
✍입력
L = [1,9,3,2]
L[1:3] = []
L💻 출력
[1, 2](4) 여러 가지 슬라이싱 방법

1.3 리스트의 메서드
(1) 원소 추가(append,extend,insert)

(2) 원소 제거(remove,pop,clear)
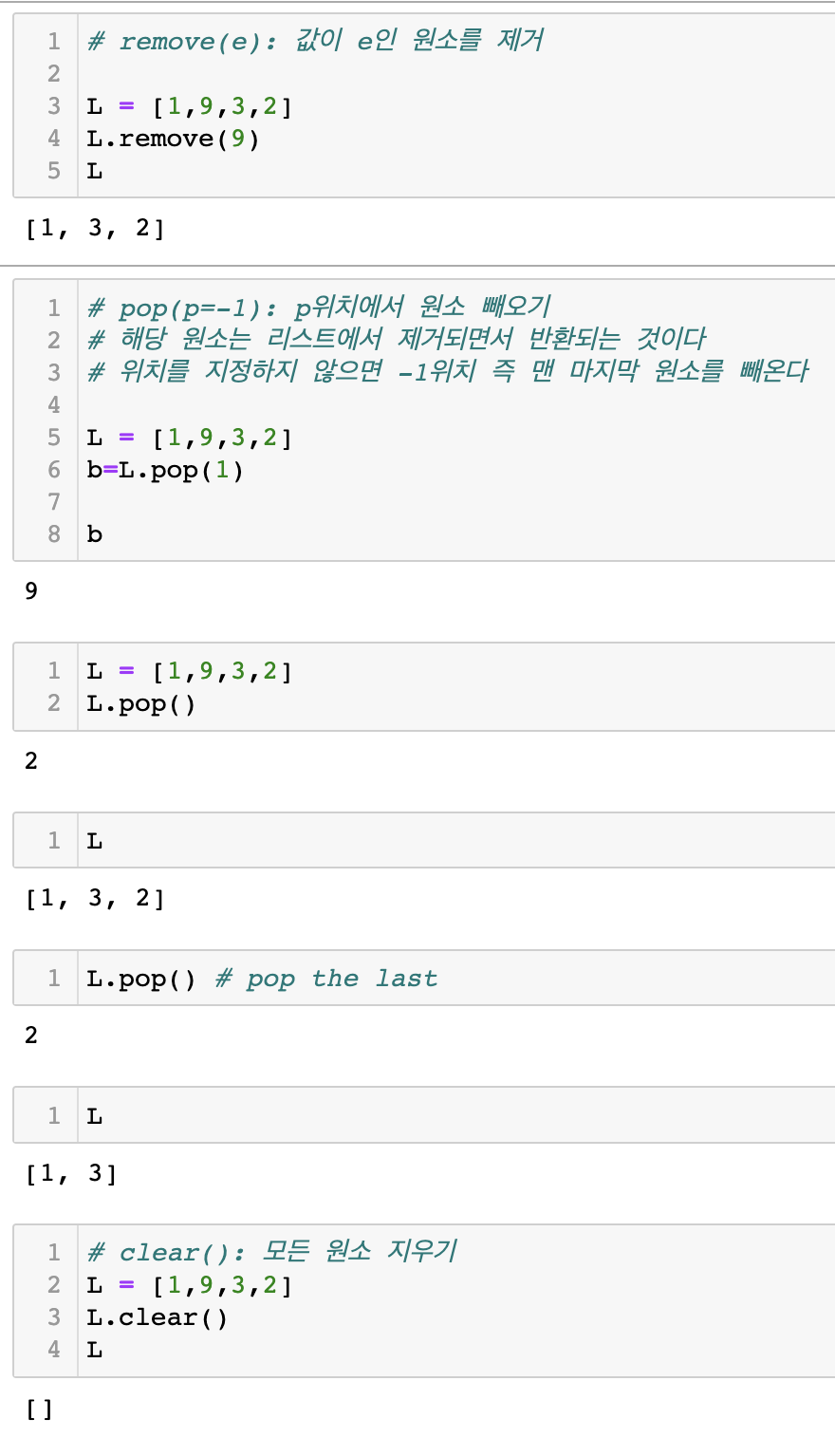
연습문제 1
- [1,3,4,4,3,2,7,4,1,7,4]에서 4와 7인 원소를 모두 제거하는 프로그램을 작성하라.
✍입력
L = [1,3,4,4,3,2,7,4,1,7,4]
del_list = [4,7]
for x in del_list:
while x in L:
L.remove(x)
print(L)💻 출력
[1, 3, 3, 2, 1](3) 원소 순서 재배치(reverse,sort,sorted)

(4) 원소 정보 확인(count,index)
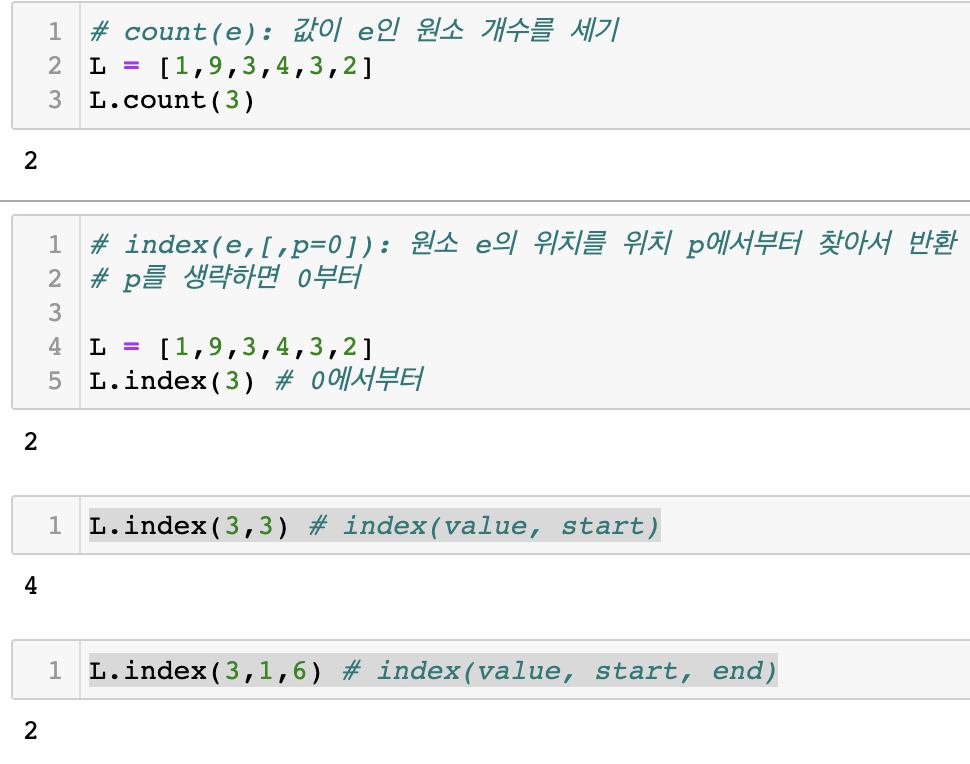
연습문제 2
- [-3.2, 5.5, 4.1, 1.1, -1.3, 2.7, 0.5]에서 최상위 3개만을 제외한 리스트를 구하라. 단, 원래 순서는 그대로 유지한다.
✍입력
a = [-3.2, 5.5, 4.1, 1.1, -1.3, 2.7, 0.5]
temp = a.copy()
temp.sort(reverse=True) # 내림차순 정렬
print(f'sorted={temp}')
for x in temp[:3]:
while x in a:
a.remove(x)
print(f'removed={a}')💻 출력
sorted=[5.5, 4.1, 2.7, 1.1, 0.5, -1.3, -3.2]
removed=[-3.2, 1.1, -1.3, 0.5]cf. mutable자료의 복사
-> 리스트의 copy 메서드나 슬라이싱 b=a[:]를 사용하면 새로운 객체를 생성한다.
✍입력
c=[1,2,3]
d=c.copy()
d[0]=100
d
id(c)💻 출력
140673228259392✍입력
id(d) # 새로운 객체를 생성한다💻 출력
1406732282405762. 튜플
2.1 특징
- 튜플(tuple): 여러 원소를 가질 수 있는 자료형
- 원소를 ()내에 ,로 구분
- 튜플은 불가변이라 리스트에 비하여 기능이 단순하고 속도가 빠르다
- 여러 데이터를 한꺼번에 보관 / 군집 (container)
- 원소의 개수와 내용은 바꿀 수 없다 (불가변)
2.2 활용
✍입력
tuple('abcd') # 문자열에서 튜플로
tuple([1,2,3]) # list에서 튜플로
a,b,c = 1,2,3 # 튜플의 언패킹
a💻 출력
('a', 'b', 'c', 'd')
(1, 2, 3)
13. 문자열
3.1 특징
- 문자열(string): 여러 문자들의 1차원 결합
- 여러 데이터를 한꺼번에 보관 / 군집
- 원소의 순서가 중요
- 원소의 개수와 내용은 바꿀 수 없다
3.2 문자열의 메서드
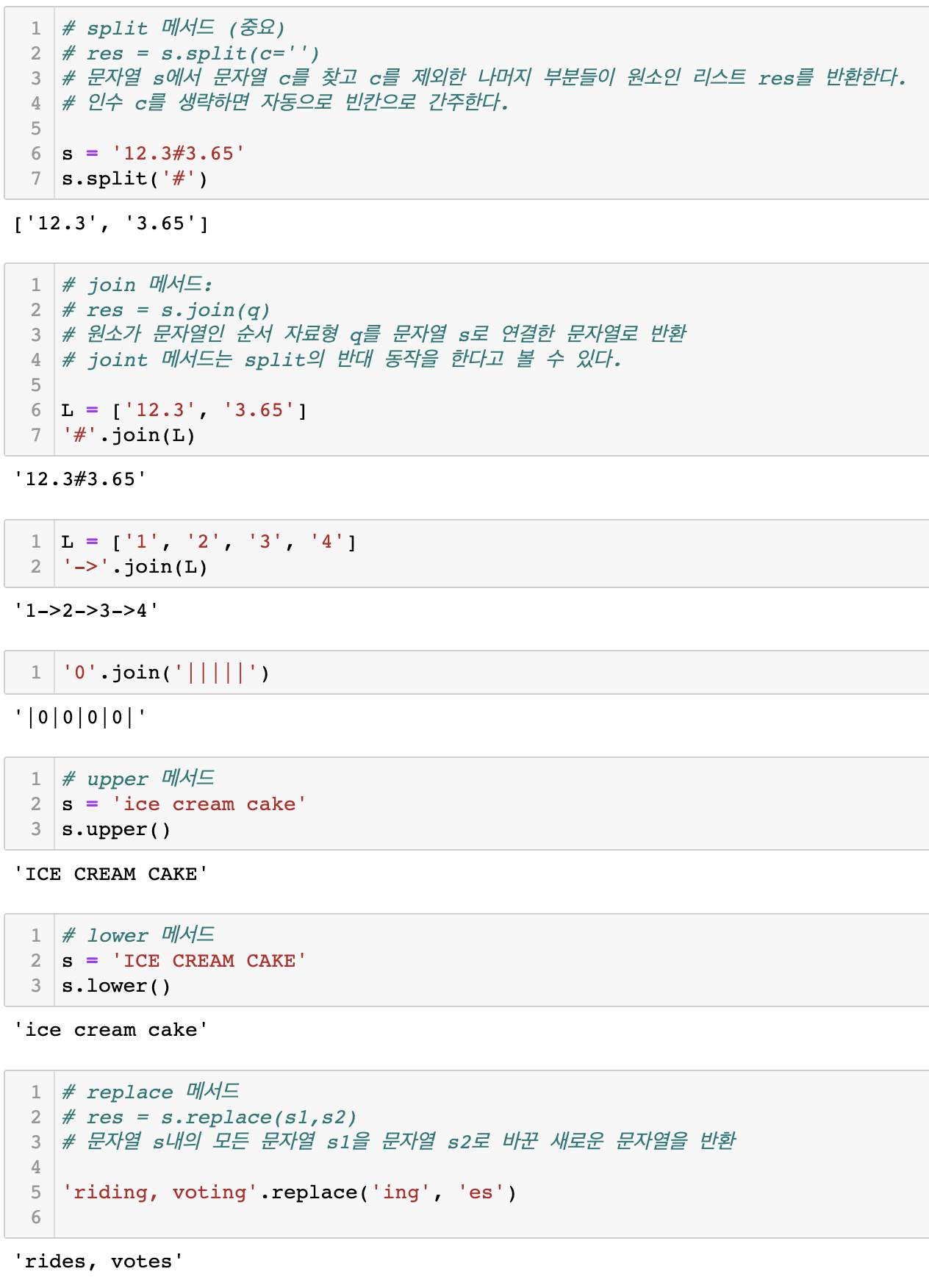
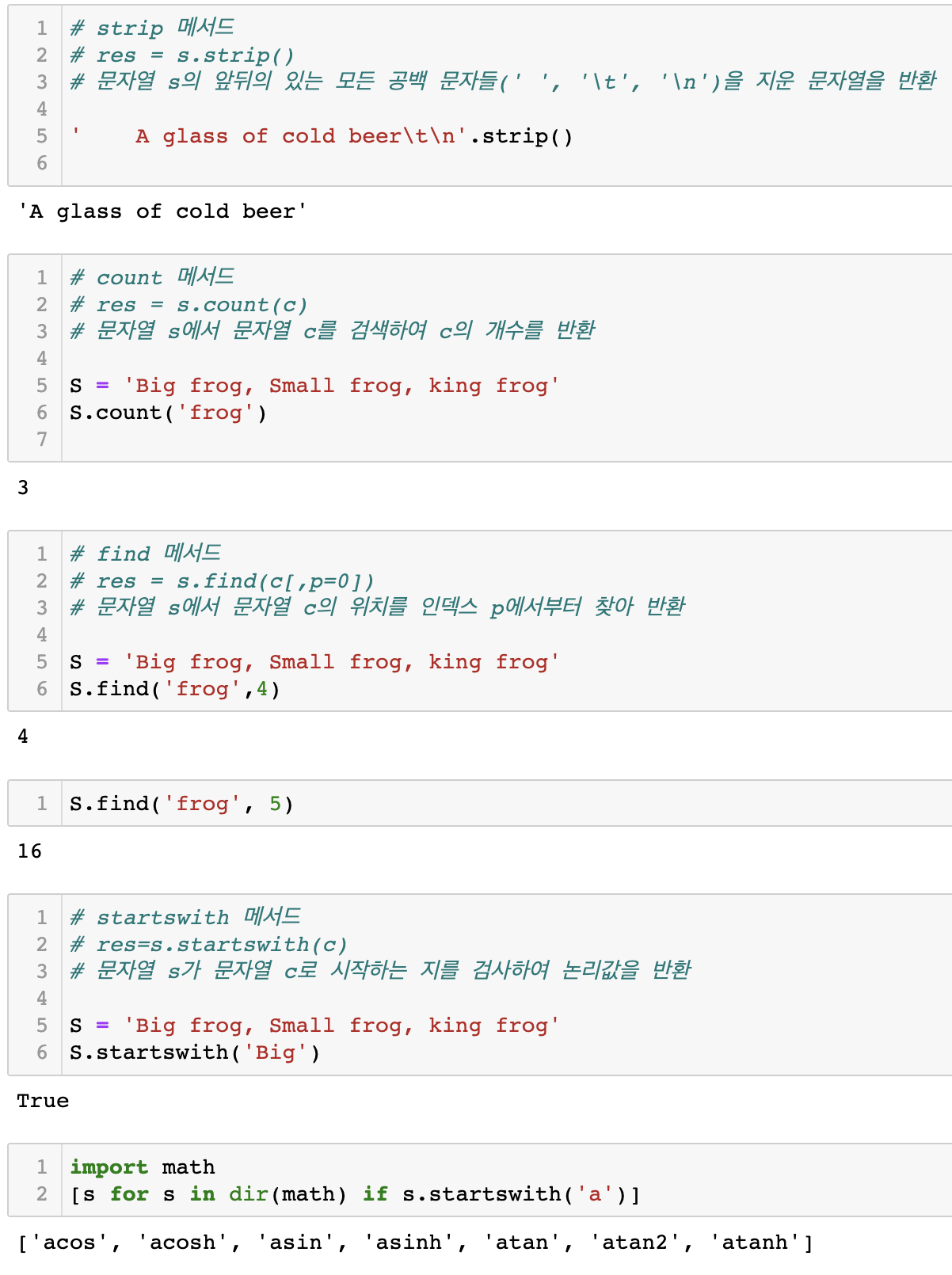

4. 딕셔너리
4.1 특징
- 원소는 key와 value로 구성
- 여러 데이터를 한꺼번에 보관 / 군집 또는 컨테이너
- key는 불변 자료형만 가능(중복은 불가)
- value: 아무 자료나
- key로 매핑 접근 key -> value
- 원소의 개수와 내용은 바꿀 수 있다 (가변적)
4.2 활용
✍zip함수/ 원소 수정 및 추가
# zip함수를 이용하여 사전으로 변환
k = [0,1,2]
v = ['zero', 'one', 'two']
d = dict(zip(k,v))
d
# 원소 수정 (가변적)
f = {0:'zero', 1:'one', 2:'two'}
f[0] = 'null'
f
# 원소 추가
e = {0:'zero', 1:'one', 2:'two'}
e[3] = 'three'
e💻 출력
{0: 'zero', 1: 'one', 2: 'two'} # zip
{0: 'null', 1: 'one', 2: 'two'} # 원소 수정
{0: 'zero', 1: 'one', 2: 'two', 3: 'three'} # 원소 추가✍중첩사전
# 중첩 사전
# 중첩(nested) 사전은 사전의 키에 대한 값이 또다른 하위 사전인 경우를 말한다
# D={key1:{sk1:sv1, sk2:sv2...}, key2:}
score = {'재롱': {'국어':50,'수학':78,'과학':46},
'또치':{'국어':80,'수학':100,'과학':78},
'또롱':{'국어':15,'수학':90,'과학':78}}
score['재롱']['과학']💻 출력
46✍keys, values, items
d = {0:'zero', 1:'one', 2:'two'}
d.keys()
e = {0:'zero', 1:'one', 2:'two'}
e.values()
f = {0:'zero', 1:'one', 2:'two'}
f.items()
for k,v in d.items():
print(k,v)💻 출력
dict_keys([0, 1, 2]) # keys
dict_values(['zero', 'one', 'two']) # vaues
dict_items([(0, 'zero'), (1, 'one'), (2, 'two')]) # items
# for문
0 zero
1 one
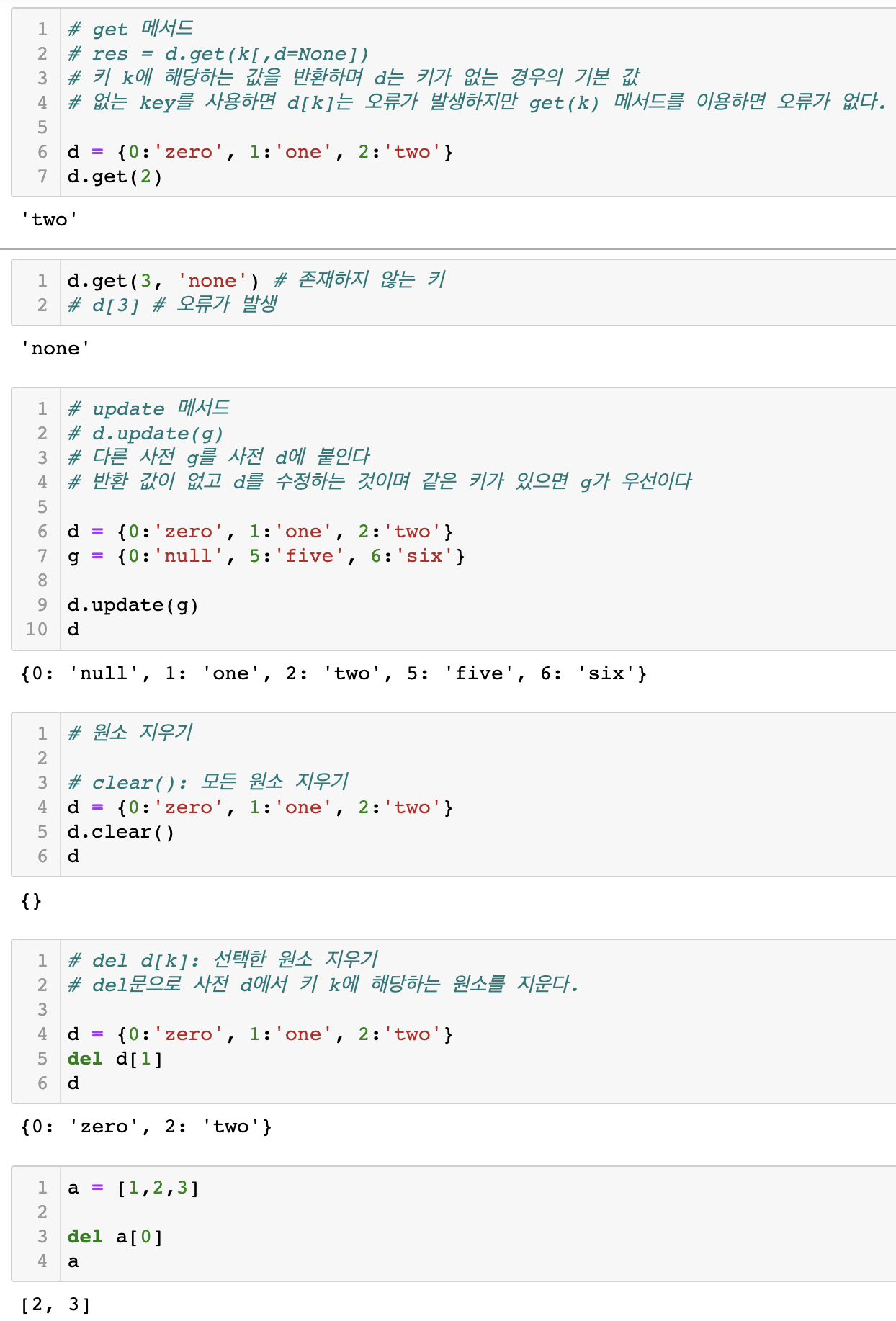
2 two4.3 딕셔너리의 메서드
5. 집합
5.1 특징
- 원소 중복 불가
- 여러 데이터를 한꺼번에 보관 / 군집 자료형
- 원소의 순서 무관하여 인덱스가 없다
- 원소의 개수와 내용은 바꿀 수 있다 (가변적)
5.2 활용
✍union, intersection, difference, in
a = {1,2,3}
b = {2,3,4,5}
a.union(b)
a.intersection(b)
a.difference(b)
5 in a💻 출력
{1, 2, 3, 4, 5} # union
{2, 3} # intersection
{1} # difference
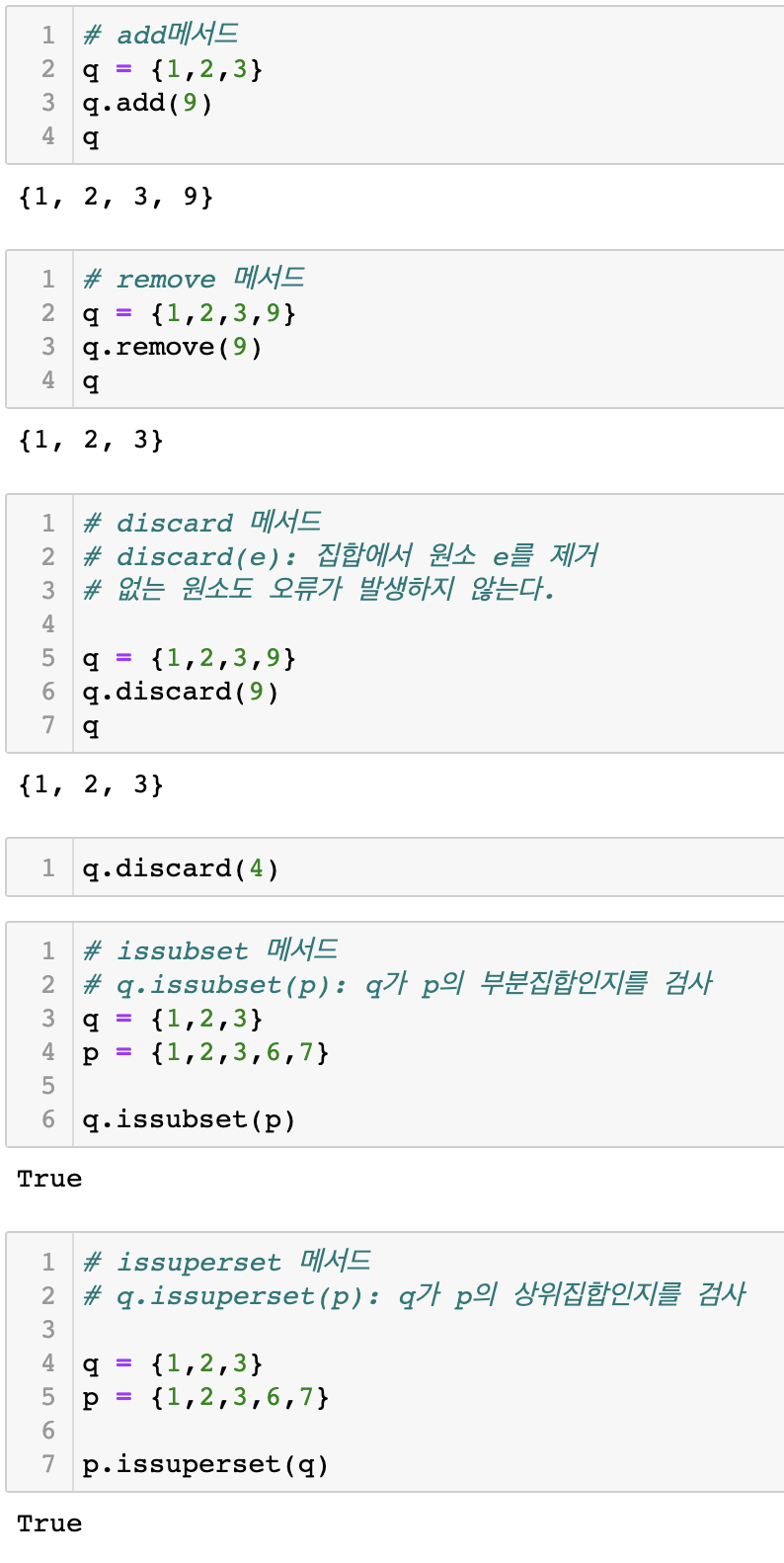
False # in5.3 집합의 메서드
6. Comprehension
✍ for문
inch = [1,2,3,4]
cm = []
for x in inch:
cm.append(2.54*x)
cm이 코드를 어떻게 하면 간략화 할 수 있을까?
함축을 이용하면 된다
✍ comprehension
inch = [1,2,3,4]
cm = [2.54*x for x in inch]
cm💻 출력
[2.54, 5.08, 7.62, 10.16]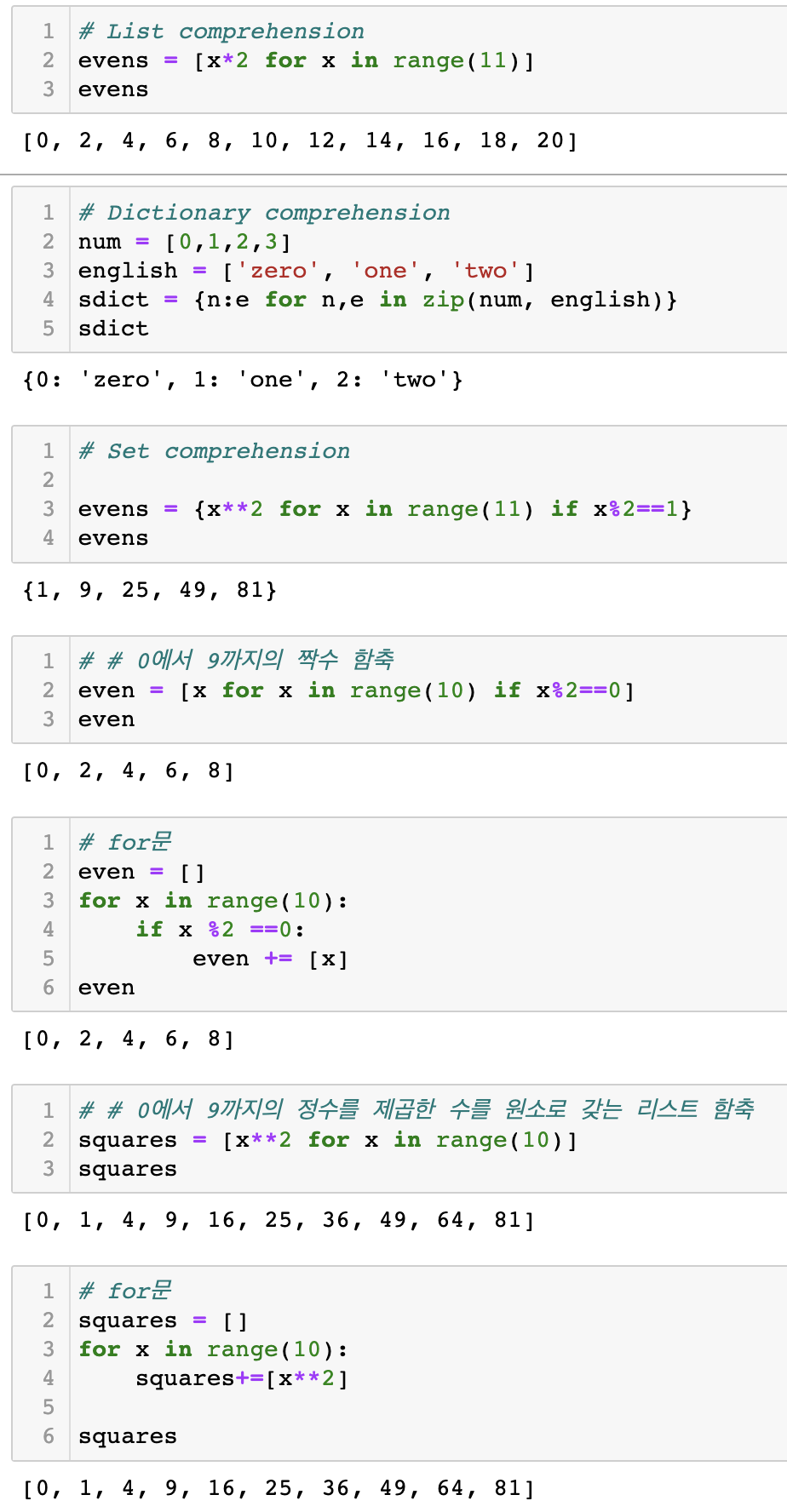
📚 참고자료:
위키독스, 점푸 투 파이썬, 'https://wikidocs.net/15', (2023.03.22)

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊