
주제: 파이썬에서 정규표현식 활용하기
1. Pattern 객체의 메소드
1) 정규표현식을 사용하기 위한 모듈
import re 2) 정규표현식 사용 예시
import re
data = \
"""Geon 010-1111-2222
Ha 010-3333-5555"""
pattern = re.compile("(\d{3})[-](\d{4})[-](\d{4})")
print(pattern.sub("\g<1>-****-\g<3>", data))3) Pattern 생성
p = re.compile('ab*') # a로 시작하며 그 뒤에 b가 0개 이상 붙어있는 패턴4) Pattern 객체의 메소드
- match()
- search()
- findall()
- finditer()
- sub()
1.1 match()
-
1) 문자열의 처음부터 패턴과 매칭되는지 확인한다.

-
2) match()로 생성되는 결과물은 Match라는 Class의 객체다.

match()로 생성된 객체에서도 별도의 메소드들을 사용할 수 있다.
-
4) Match Class에서 유용한 메소들은 다음과 같다.

-group(): 매칭된 문자열을 반환한다.
-start(): 매칭된 문자열의 시작 위치를 반환한다.
-end(): 매칭된 문자열의 끝 위치를 반환한다.
-span(): 매칭된 문자열의 시작위치, 끝위치에 해당하는 튜플을 반환한다.
1.2 search()
- 문자열 전체를 탐색하여 정규식과 매칭되는지 확인한다.
- 그렇다면 match와 search의 차이점은 무엇일까?
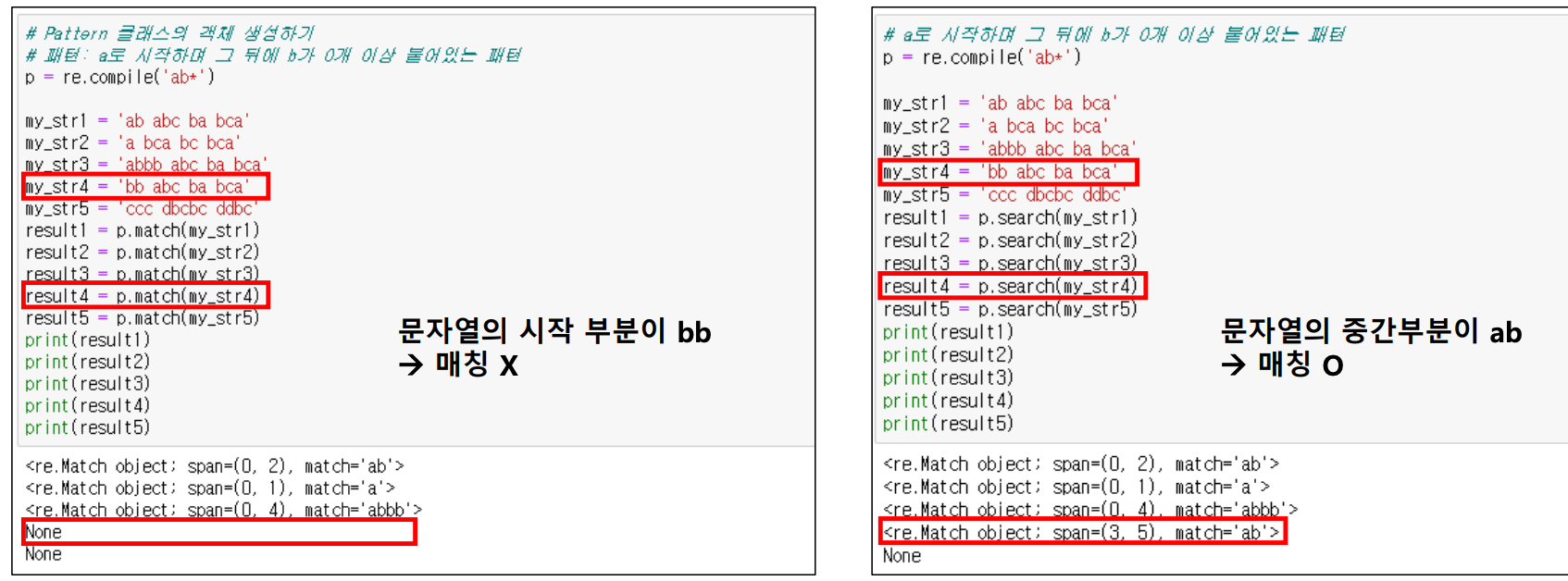
my_str4와 비교하면서 봤을 때, 차이점이 존재한다.
- match: 문자열의 시작부분이 bb이기 때문에 매칭이 되지 않는다. 즉, match는 문자열의 처음부터 끝까지 매칭되는 것을 찾는다.
- search: 문자열 전체를 탐색하는 것이기 때문에 문자열의 중간부분에 ab가 오더라도 매칭된다.
1.3 findall()
- 정규식과 매칭되는 모든 문자열을 반환한다.

cf) 순서 상관 없이 bca, ba가 오더라도 a만 추출하여 반환한다.
- my_str5 같은 경우, a로 시작하는 문자열이 없기에 빈 리스트가 출력되었다.
1.4 finditer()
- 정규식과 매칭되는 모든 문자열을 반복가능한 객체(iterator)형태로 반환한다.

✍ 입력
type(result1)💻 출력
callable_iterator✍ 입력
for my_str in result1:
print(my_str)💻 출력
<re.Match object; span=(0, 2), match='ab'>
<re.Match object; span=(3, 5), match='ab'>
<re.Match object; span=(8, 9), match='a'>
<re.Match object; span=(12, 13), match='a'>
- result1에 해당하는 a로 시작하며 그 뒤가 b가 0개 이상 반복되는 패턴은 총 4개가 있다. finditer 메소드는 패턴과 맞는 문자열을 4가지 iterator 형태로 반환해준다. 그 후 for문을 활용하여 span(시작위치, 끝 위치) 형태로 튜플을 반환해준다.
cf) iterator는 한 번 다 순환하면 다시 사용할 수 없다. 만약 다시 사용 하려면 재선언해서 돌려야 한다.
1.5 sub()
- 정규식과 매칭되는 모든 문자열을 다른 문자열로 수정한다.

- my_str5는 a로 시작하며 b로 끝나는 문자열 조건이 없기 때문에 그대로 출력하는 것을 확인할 수 있다. 그 외에는 패턴 조건에 맞춰서 'xx'형태로 수정된 것을 볼 수 있다.
2. Pattern 생성
- 패턴 생성시 옵션 사용하기 (re.compile()의 option)
2.1 re.DOTALL (re.S)
-
메타문자 .s는 줄바꿈 문자(\n)을 제외한 모든 문자와 매칭된다.
-
\n도 포함하여 매칭하고 싶을 때 사용한다.

my_str1을 보면, 줄바꿈문자(\n)가 포함 되어 있다. 이를 re.DOTALL을 활용하여 span=(0,3), match=''a\nb' 형태로 나타난 것을 확인할 수 있다.
2.2 re.IGNORECASE (re.I)
- 대소문자 구별 없이 매칭할 때 사용된다.

2.3 re.MULTILINE (re.M)
- 패턴을 문자열의 각 Line마다 적용해주는 것을 의미한다.
✍ 입력
data = """python one
life is too short
pythontwo
you need python three
python three"""
data💻 출력
'python one\nlife is too short\npythontwo\nyou need python three\npython three'
- re.M을 사용하지 않았기 때문에 'python one'만 출력이 되었다. 즉, 첫번째 line만 매칭되어서 나타냈다. 그러나 위의 조건에 맞는 'python three'는 출력이 되지 않았다는 것을 알 수 있다.

- 하지만 아래에는 re.M을 사용했기 때문에 문자열의 각 line마다 매칭할 수 있다. 그렇기 때문에 조건에 맞는 2개의 output이 출력되었다.

2.4 re.VERBOSE
- 문자열에 사용된 whitespace를 컴파일할 때 제거된다.
- 복잡한 정규식에 주석을 달 때 많이 사용한다.
✍ 입력1
charref = re.compile(r'&[#](0[0-7]+|[0-9]+|x[0-9a-fA-F]+);')✍ 입력2
charref = re.compile(r"""
&[#] # Start of a numeric entity reference
(
0[0-7]+ # Octal form
| [0-9]+ # Decimal form
| x[0-9a-fA-F]+ # Hexadecimal form
)
; # Trailing semicolon
""", re.VERBOSE)3. 다양한 정규표현식 사용 예제_python
앞의 regexr 정규표현식과 내용이 겹치기에 간단하게 정리하고 넘어가겠습니다.
- 대괄호 ([])
-[xyz]: xyz 문자 중 하나와 매칭된다.
- 중괄호 ({})
-{m,n}: m개 이상 n개 이하. m이 0이면, nro dlgk(0도 포함)이고, n이 0이면, m개 이상으로 매칭된다.
- 소괄호 (())
-(xyz), (?xyz): xyz와 매칭된다.- OR (|)
- SRARTSWITH(^)
-첫번째 줄의 시작
cf) 대괄호 안에 ^를 사용하면, '문자를 제외하고'의 뜻이다.
-> 여기서 my_str은 방탄소년단, Permission to Dance(2021.07.09.) 가사를 의미한다.
✍ 입력
p = re.compile('^[aA]nd [a-zA-Z]+', re.MULTILINE)
results = p.finditer(my_str)
for result in results:
print(result)💻 출력
<re.Match object; span=(170, 176), match='And to'>
<re.Match object; span=(245, 252), match='And the'>
<re.Match object; span=(482, 490), match='And live'>
<re.Match object; span=(514, 522), match='And roll'>
<re.Match object; span=(1021, 1029), match='And stay'>
<re.Match object; span=(1058, 1064), match='And we'>
<re.Match object; span=(1178, 1186), match='And live'>
<re.Match object; span=(1210, 1218), match='And roll'>
<re.Match object; span=(1790, 1798), match='And live'>
<re.Match object; span=(1822, 1830), match='And roll'>
- ENDSWITH($)
-마지막 줄의 끝
✍ 입력
p = re.compile('[a-zA-Z]+ [yY]eah$', re.MULTILINE)
results = p.finditer(my_str)
for result in results:
print(result,f", 추출 문자열: {result.group()}")💻 출력
<re.Match object; span=(450, 459), match='move yeah'> , 추출 문자열: move yeah
<re.Match object; span=(845, 854), match='vibe yeah'> , 추출 문자열: vibe yeah
<re.Match object; span=(935, 944), match='lock yeah'> , 추출 문자열: lock yeah
<re.Match object; span=(1146, 1155), match='move yeah'> , 추출 문자열: move yeah
<re.Match object; span=(1758, 1767), match='move yeah'> , 추출 문자열: move yeah4. optional
4.1 긍정형 전방탐색
- 사용: (?=문자)
- 조건: 등호(=) 두의 문자와 일치하는 텍스트를 전방에서 탐색한다.
- 결과: 문자는 검색 조건으로 사용되나, 결과에는 포함되지 않는다.
4.2 부정형 전방탐색
- 사용: (?!문자)
- 조건: not equal(!) 뒤의 문자와 일치하지 않는 텍스트를 전방에서 탐색한다.
- 결과: 문자는 검색 조건으로 사용되고, 해당 문자가 들어있지 않는 텍스트를 탐색한다.
4.3 긍정형 후방탐색
- 사용: (?<=문자)
- 조건: <=뒤의 문자와 일치하는 텍스트를 후방에서 탐색한다.
- 결과: 문자는 검색 조건으로 사용되나, 결과에는 포함되지 않는다.
4.4 부정형 후방탐색
- 사용: (?<!문자)
- 조건: <! 뒤의 문자와 일치하지 않는 텍스트를 후방에서 탐색한다.
- 결과: 문자는 검색 조건으로 사용되고, 해당 문자가 들어있지 않는 텍스트를 탐색한다.
점프 투 파이썬 8장 '정규표현식' 참고해서 내용 작성하였습니다.
🎯 Summary
정규방정식을 공부하면 할수록 공부할 것이 더 쌓이는 기분이 들었다. 다 외울 수는 없겠지만, 데이터 전처리를 할 때 유용하게 사용할 수 있을 것 같다. 그리고 전방탐색과 후방탐색의 식이 다소 복잡해서 구현하는 데 에러가 많이 떴었다. 이 두 개의 식도 열심히 공부해봐야겠다.
📚 References
- 점프 투 파이썬(https://wikidocs.net/4309)
