Title
- End-to-End Object Detection with Transformers
- DETR

0. 논문 읽기 전에 알면 좋을 것들
Anchor

- Anchor의 사전적 의미는 "닻"으로, 비교적 큰 배나 항구가 일정한 곳에 머물 때 그 자리에 멈추어 있도록 하고 배가 어느 위치에 있는지 확인하는 기준이 될 수 있음.
-> 입력 영상에 대해서 객체가 있을 법한 곳에 설정한 box
- 가로, 세로, ratio가 정해진 Bounding Box를 의미함.
->단점: 미리 정해진 ratio의 box만 생성 가능하기 때문에 input image에 맞춰서 Bounding Box를 생성하기는 어려움.
NMS

- Non-Maximum Suppression으로 객체 탐지 알고리즘의 후처리 단계에서 중복되거나 겹치는 Bounding Boxes를 제거하고 가장 확실한 객체 위치를 결정하는 기술
-> 위의 사진과 같이 여러개의 Bounding Boxes가 생기는 문제를 막기 위해 사용됨.
- 말 그대로 최대값을 제외한 값들을 억제하는 알고리즘임.
Transformer + ViT

- image를 여러 patch로 나누어 embedding을 수행함. 그 이후 각 patch를 하나의 token으로 이용해 transforemr 구조에 입력함.
- class token을 추가 학습하여 뒷단의 MLP Layer에 태워 image의 class를 예측함.
- Inductive Bias를 크게 줄여 모델의 자유도를 얻음.
Hungarian Algorithm

- 두 집합 사이의 일대일 대응 시 가장 비용이 적게 드는 이분매칭(bipartite matching)을 찾는 알고리즘
- 어떠한 집합 와 matching 대상인 집합 가 있으며, 를 에 매칭하는데 드는 비용을 라고 할 때 로의 일대일 대응 중에서 가장 적은 cost가 드는 매칭에 대한 permutation 를 찾는 것.
permutation: 매칭 시 최적의 순서에 대한 label를 의미
predicted bounding box: 행렬의 행
ground truth: 행렬의 열
- 위의 왼쪽 그림(일자 형태 매칭, cost 32)은 matching score가 높은 permutation
- 오른쪽 그림([일자 형태 매칭X, cost12])은 matching score가 낮은 permutation
🤜 cost에 대한 행렬을 입력 받아서 cost가 최소인 Permutation을 출력함.
Bounding box Loss
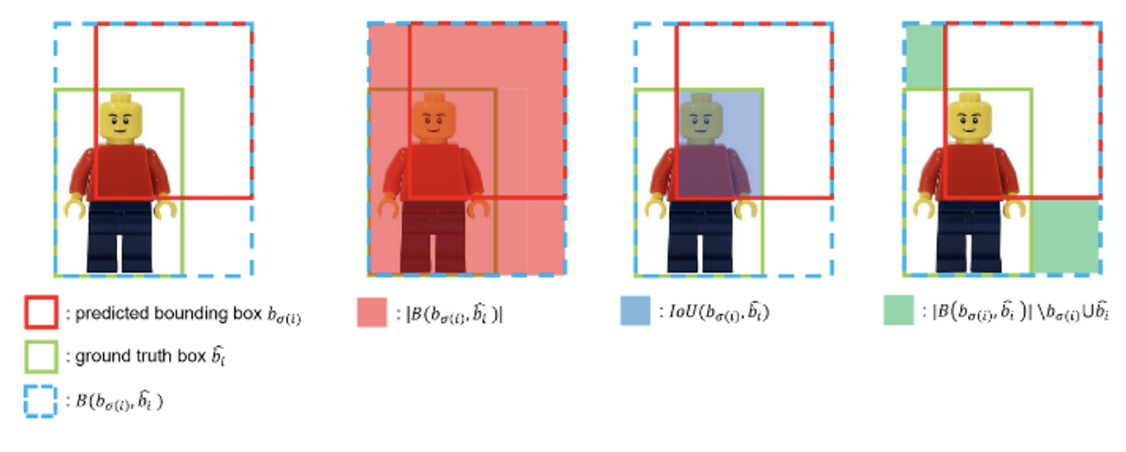
- 이는 Hungarian algorithm 연산과 Loss 계산 시 사용됨.
| 기존 | DETR |
|---|---|
| anchor 기반으로 하기 때문에 bounding box의 범위가 크게 벗어나지 않음. | inital guess 없이 예측하므로 예측값의 범주가 크게 벗어남. |
🤜 절대적인 거리를 측정하는 L1 loss만 사용할 경우, 큰 box는 큰 loss를, 작은 box는 작은 loss를 가지게 될 것임.
🤜 본 논문에서는 L1 lose와 generalized IoU(GIoU) Loss를 함께 사용함.
GloU
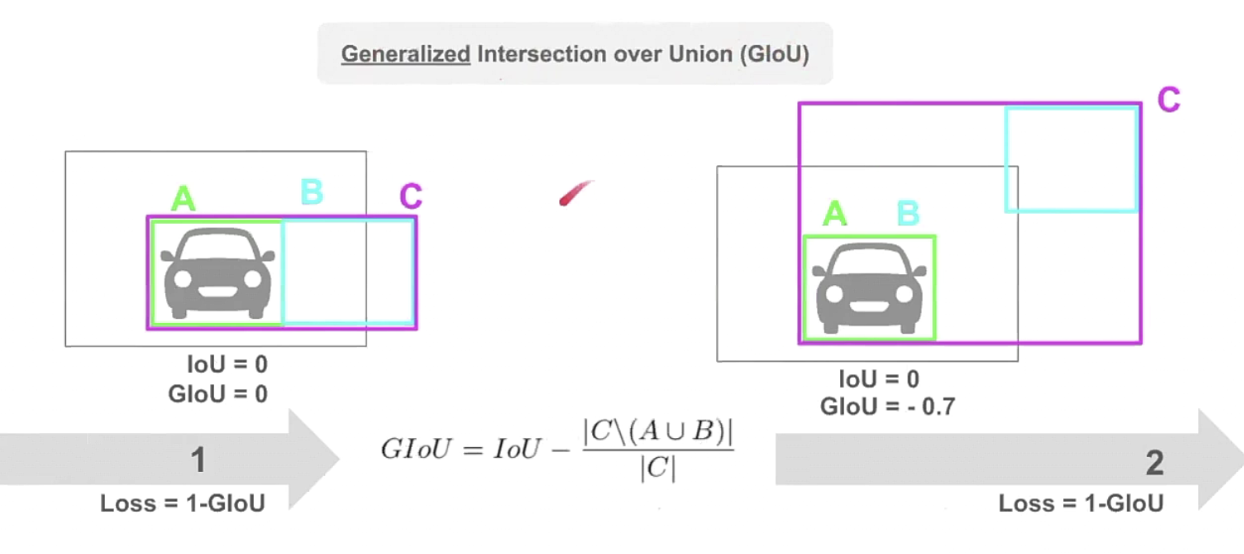
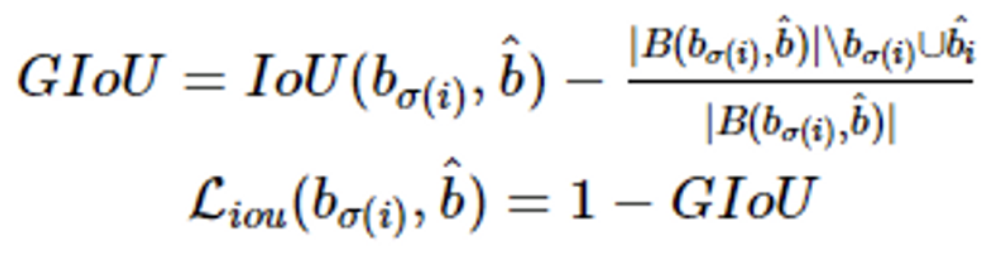
- generalized IoU(GIoU)로 두 box 사이의 IoU 값을 활용한 Loss로 scale-invariant 특징.
- GIoU는 ~1에서 1사이의 값을 가짐
- Loss로 사용할 때는 1-GIoU 형태로 Loss의 최대값은 2, 최소값은 0임.
Abstract
- Facebook AI팀은 DEtection Transformer 모델을 제안함.
-> Object Detection을 set prediction problem의 문제로 접근하며, end-to-end 모델로서 geometric prior가 필요하지 않음.
-> RPN, NMS와 같은 수작업 enginerring이 필요 X
- 기존 Object Detection방법들은 너무 복잡하였고 다양한 라이브러리를 활용하였음. 하지만 DETR은 특별한 라이브러리가 필요하지 않음.
- 구조적으로 매우 간결하고 다른 Task에 확장성이 높음.
-> Attention mechanism에 의해 전역적 정보를 이용함에 따라 성능 Good!!
- object query를 고정해놓고, obect 간 관계와 prediction을 병렬적으로 추론 가능함.
- 당시 SOTA baseline 모델이었던 Faster R-CNN과 동등한 정확도 및 실행 시간 성능을 보임.
- segmentation Task에서도 일반화될 수 있음.
기존의 Object Detection 기술과 비교했을 때 매우 간단하며 경쟁력 있는 성능
DETR 핵심
(1) 이분매칭 (partite matching)
(2) Transformer
1. Introduction
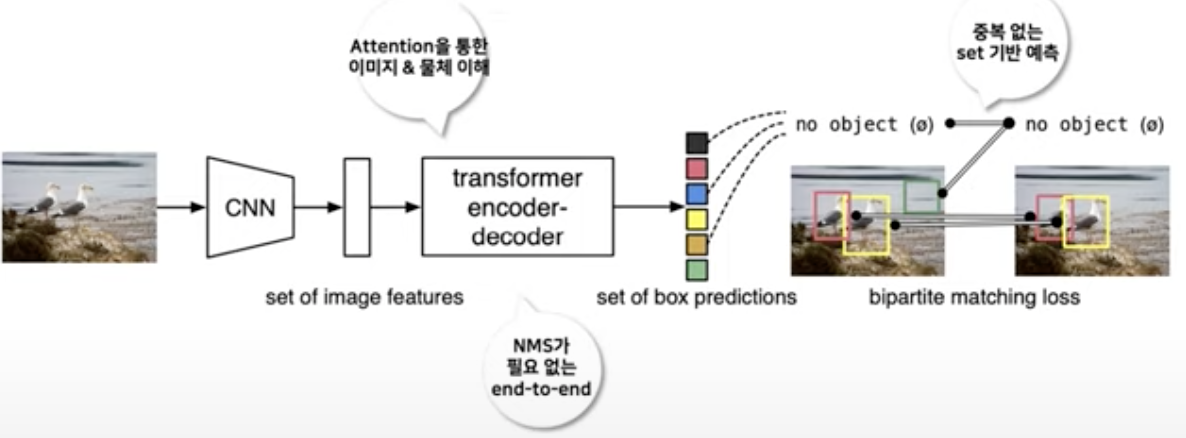
- 기존 Object Detection은 anchor, window centers 등 해당 집합들을 예측하기 위한 indirect한 방법을 사용
-> 중복 예측을 피하기 위해서 직접 anchor sets을 설정한 뒤 target box를 정하는 후처리가 필수적임.
- DETR은 direct set prediction을 제안하였고, 별도의 수작업 과정이 필요없어짐.
-> 중복 예측 제거 기능 수행
-> 순서에 영향을 받지 않음
- Transformer 기반의 encoder-decoder 구조를 통해 전반적인 instance간의 상호작용을 파악할 수 있고, 각 pixel별 self-attention mechanism 활용 가능
정리
- DETR은 이분매칭(partite matching)과 병렬처리가 가능한 Transformer구조
- 순서에 영향을 받지 않는 set prediction에 적합하고 Faster R-CNN보다 더 좋은 성능을 보임.
2. Related work
2.1. Set Prediction
- 본 논문에서는 Hungarian algorithm을 통해 Loss function을 구성하고, ground-truth와 prediction에 대한 이분매칭이 가능
- 정리하면, set prediction관점에서 이분매칭을 통해 예측의 순서와 상관 없이 loss function을 최소화 + transformer 통한 병렬학습 가능
2.2. Transformers and Parallel Decoding
- Transformer가 어떻게 활용되었을까?
- Attention은 전체적인 Input sequence에서의 정보를 활용함.
- Transformer는 Long sequence의 정보를 처리하는 데 용이할 뿐더러 병렬적인 학습이 가능하여 computing resource를 줄일수 있기에 활용함.
2.3. Object Detection
- 기존 방식들(2-stage-detectors, single-stage methods)은 처음 guess를 어떻게 설정하냐에 따라 성능이 크게 좌우됨.
- 손수 작업해야 하는 anchor를 대체하여 absolute box prediction으로 직접적으로 설정 가능
🏔️ Recurrent Detectors
- 본 논문과 매우 비슷한 방법론을 사용함
(End-to-End Set Predictions & Instance Segmentation 등)
- RNN 기반의 autoregressive model들이 많이 제안됐지만, modern baseline보다는 성능이 안좋기 때문에 병렬적인 학습이 가능한 transformers를 활용함.
3. The DETR model

- DETR에서 direct set prediction이 가능하도록 하기 위해서는 아래 2가지가 필요함.
1️⃣ Predicted된 box와 Ground truth box 간의 유니크한 매칭을 위한 set prediction loss 활용
2️⃣ Set of Objects 예측한 뒤 그 관계를 modeling하는 아키텍처 활용
3.1. Object Detection set prediction loss
1️⃣번을 만족하기 위한 Loss 계산 과정은 2단계로 구분됨.
(1) predicted bounding box와 ground truth box 사이의 unique한 matching을 수행하는 과정
(2) matching된 결과를 기반으로 hungarian loss 연산
이분매칭 (Bipartite matching)
Direct set prediction에서 중요한 두 가지 요소는?
- 예측과 GT 사이에 중복이 없는 일대일 매칭이 되야함.
- 한 번의 추론에서 object set을 예측하고 그들의 관계를 모델링할 수 있어야 함.
- object detector를 학습시키기 위해 DETR은 Hungarian Algorithm을 활용해 이분 매칭을 통해 Loss를 정의함.
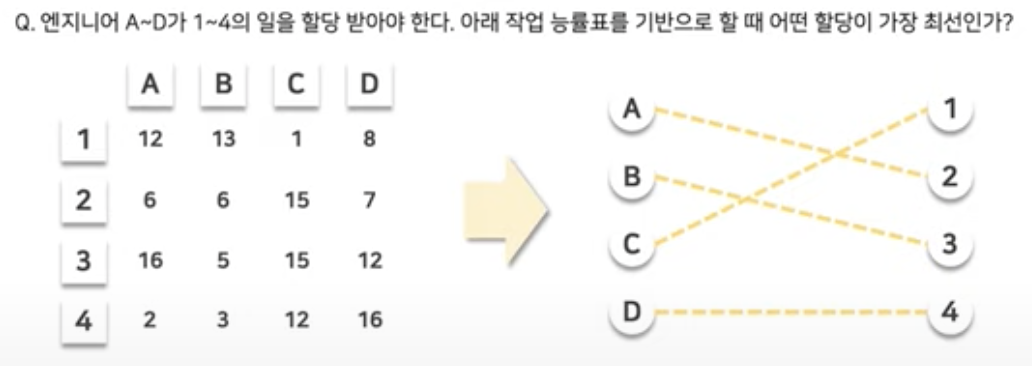
- 서로 다른 두 그룹이 있을 때, 각각의 그룹 안에서는 matching이 없고, 서로 다른 그룹끼리로의 연결만 존재하는 matching 방법
-
DETR학습을 위해 FFN까지 거치고 나온 output에 이를 적용해야함.
-
loss를 걸어주기 전에 output과 gt를 서로 matching 시켜 pair 집합을 만들어 주는 과정이 필요한데 이를 이분 매칭이라고 함.
-
Object query마다 예측된 결과물(class유무, 박스 좌표)과 ground truth set 간 Hungarian algorithm 기반 매칭 수행
-> _match를 최소화하는 최적의 순열을 찾는다!- DETR은 set prediction과 ground truth 간 일대일 매칭 수행하여 중복 배제
<-> anchor는 ground truth와의 중복 예측을 허용함
- DETR은 set prediction과 ground truth 간 일대일 매칭 수행하여 중복 배제
-
matching cost가 가장 작아지는 방향으로 이루어짐.
-> 수식은 아래를 참고하면 됨.
3.1.1. Find optimal matching
- 고정된 크기의 N개의 prediction만을 수행하고, anchor를 생성하는 과정을 우회함.
- N의 경우 이미지 내 존재하는 객체의 수보다 헐씬 더 큰수로 지정 (최대 N개)
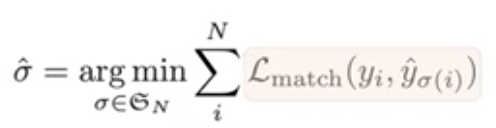
- : 실제값 집합
- _hat: 예측값 집합
- : 매칭된 결과
- 매칭된 loss 값: pair-wise한 matching cost
🤜 매칭 Loss 값의 합을 가장 작게 만들어주는 를 찾기!
🤜 matching 알고리즘을 통해 Loss가 최대한 작아지도록 prediction을 정렬함.
🤜 를 찾는 최적 할당 문제로, 가중 이분 매칭이라고 표현함

- class 예측 cost
: 순열 의 i번째 요소가 해당하는 GT의 클래스를 예측한 확률
- box 좌표 예측 cost
: 순열 의 i번째 요소의 예측 박스 좌표에 해당하는 GT의 박스 좌표 간 Loss
- _match: 위의 식은 ground truth와 matching cost는 class prediction과 predicted bounding box와 ground truth box 사이의 유사도를 모두 고려하는 식임.
- 모델이 예측한 class가 gt class와 같을 확률이 높을수록, 모델이 예측한 bounding box와 gt의 bounding box간 loss가 작을수록 matching cost가 작아지는 것을 알 수 있음.
3.1.2. Compute Hungarian Loss
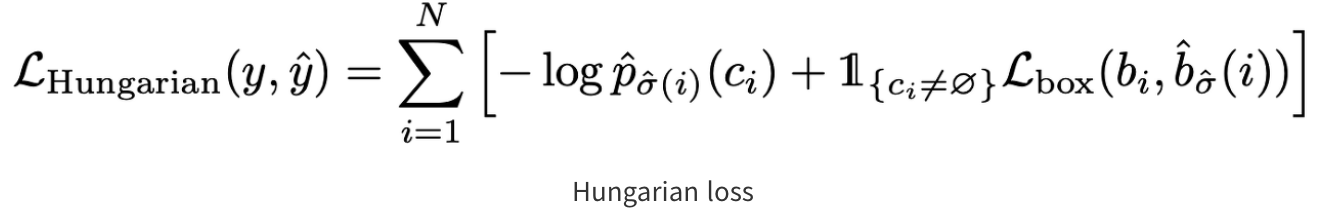
📚 Hungarian loss를 통해 최적의 매칭 값을 찾아줌.
- 위의 수식은 매칭된 Hungarian Loss값의 수식
- Loss: Class Loss와 Box Loss로 구성
- Class Loss: prediction에 대한 negative log-likelihood를 계산
- bounding box loss: 박스의 좌표 값 자체로 계산하는 L1 loss와 generalized IoU Loss를 결합하여 사용
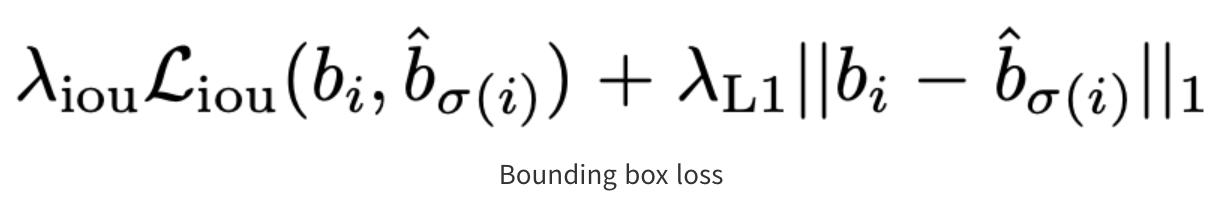
- Bounding box에 대한 Loss 수식
- L1에 대한 Loss 값: 두 개의 bounding box가 유사해지도록 하는 역할 수행 / 크기에 영향을 받음
3.2. Transformer vs DETR Transformer
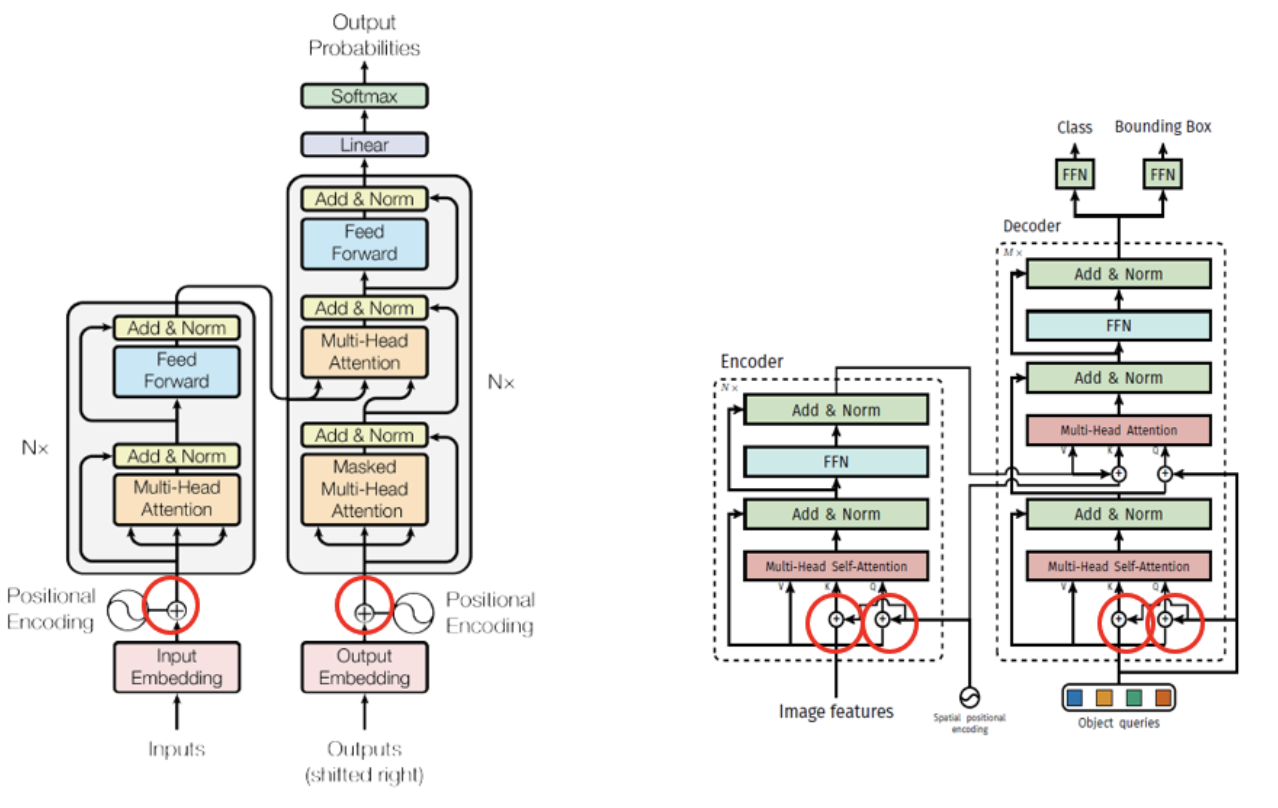
- 비슷한 모양을 하고 있지만 두가지 차이점이 존재함.
(1) Positional Encoding 위치가 다름
- Transformer
: transformer module(encoder, decoder)에 한 번만 encoding을 진행함.
- DETR
: 모든 encoder, decoder module에서 positional encoding을 진행함.
(2) Auto-regression vs Parallel 방식
Auto-Regression?
: 현재 tick에서의 값을 예측하기 위해 지금까지 예측한 값들을 이용해서 예측하는 방식으로, 시계열 데이터에서 많이 사용하는 방식
- Transformer
: 예측할 때 모든 entity를 한 번에 Output하지 않고 매 tick마다 하나의 entity씩 예측함.

- DETR
: 한 번에 모든 entity들을 output함.

정리
- computational cost는 parallel 방식이 더 적다는 장점이 있음.
- 하지만 auto-regression보다는 정확도가 떨어질수 있음.
- DETR의 output는 object query임
- 이 object들은 NLP Task처럼 서로가 밀접한 관련이 있는 task가 아니므로 parallel하게 output하는 방식이 적절함!
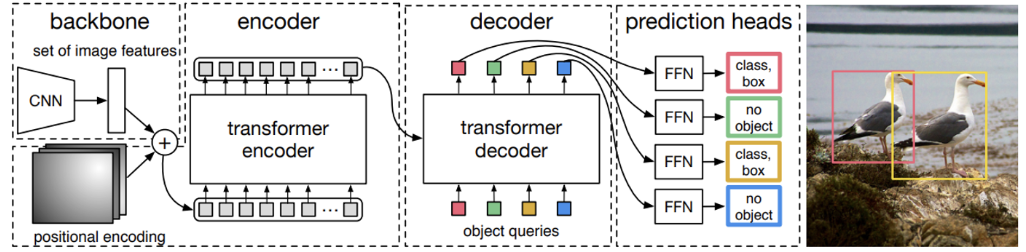
3.3. DETR Architecture
- 위의 그림은 DETR 전체 시스템 구조임.
- Backbone + Transformer + MLP 구조

- 고려대학교 DSBA (소규성) , Tistory 자료를 참고하였습니다.
- 좀 더 자세하게 아키텍처를 살펴보겠다!
3.3.1. Transformer Encoder

- attention mechanism을 기반으로 feature map의 pixel과 pixel 간의 관계를 학습
- CNN(Locality 중심)와 달리 global한 정보를 학습함으로써 이미지를 이해함.
- object detection task에 맞게 이미지 내 object의 위치, 관계를 학습함.
(1) 이미지를 Transformer 입력형태로 변환

1.1. Backbone인 ResNet50에 Image를 태워 feature map를 얻음.
1.2. 얻은 feature map을 1x1 Conv Layer에 태워, 미리 설정한 token embedding 차원(d=256)으로 축소
1.3. 최종적으로 d x HW로 flatten하여 transformer에 입력으로 사용할 수 있는 sequence를 얻음.
(2) Positional Encoding
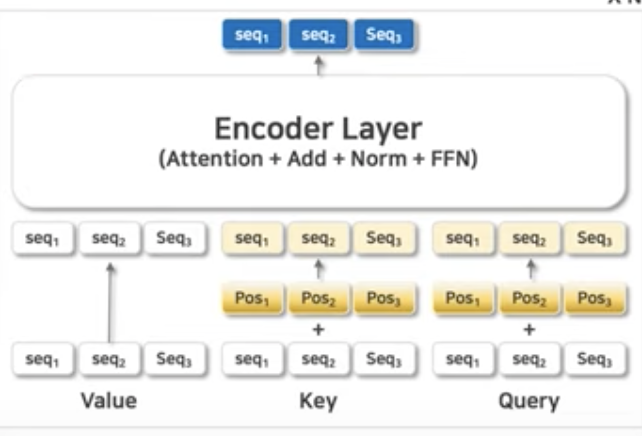
- Transformer 아키텍처와 동일하게 positional encoding을 더하고 학습
- DETR에서는 2D fixed sine positional encoding을 사용 (ViT 논문에서는 1D와 2D 성능 차이는 유의미하지 않음)
-> x와 y를 따로 구해준 다음에, 뒤에 concat을 사용하는 구조로 활용
- 모든 encoder layer마다 positional encoding을 query, key에 더하여 입력으로 사용함.
-> 이렇게 했을 때 더 성능이 좋았음.
(3) Self-Attention
-> 입력된 각 pixel들 간 어떠한 관계가 있는지를 global하게 학습
(4) FFN
-> output에 대한 normalization & 학습 보조
3.3.2. Transformer Decoder
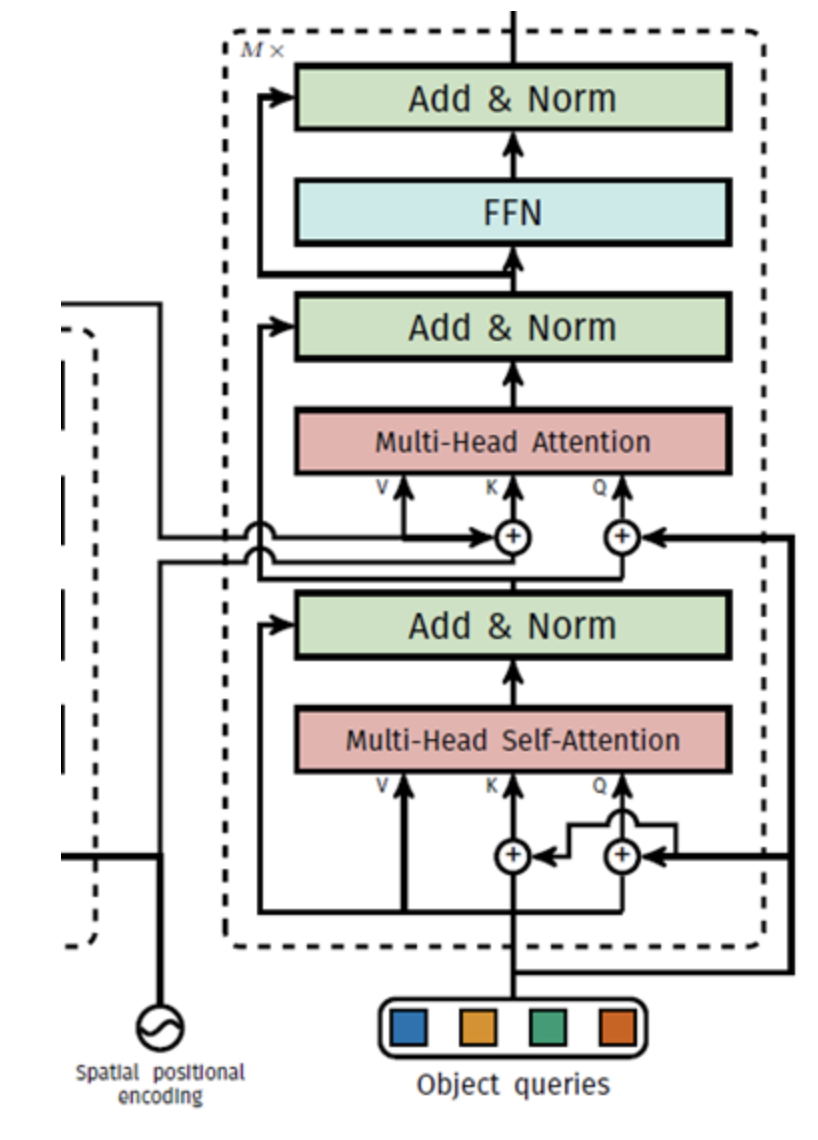
- Decoder의 역할은 어떠한 입력값을 받아 이미지 내에 존재하는 object의 클래스 및 위치를 출력하는 것.
- Permutation invariant한 transformer의 특성으로 인해 입력값이 서로 달라야 서로 다른 출력값을 출력할 수 있으므로 학습이 가능한 positional encoding (object query)를 random하게 초기화하여 입력값으로 사용함.
(단, Github 저자들은 decoder는 모든 것이 set이므로, "positional embedding"라는 의미가 없음.)
(1) Object query 입력
- 정보를 담기 위한 그릇(slot)으로 생각할 수 있음.
- "It turns out experimentally that it will tend to reuse a given slot to predict objects in a given area of the image"
-> 실험적으로 이미지 특정 부분에는 특정 object query를 재사용한다.
-
class 정보를 학습하는 것이 아닌, special & specific한 정보를 학습하는 것이 object query의 역할임을 실험적으로 찾아냄.
-
Decoder의
(1.1) Encoder-decoder attetion을 통해 이미지의 어느 부분을 위주로 봐야할지 학습 (물체가 어느 위치에 있을 확률이 높은지)
(1.2) Self-Attention을 통해 자신의 역할을 어떻게 분배하여 최적의 일대일 매칭을 수행할 수 있을지를 학습
(2) Decoder Self-Attention
- Self Attention을 통해 query slot 간 관계 학습
(첫번째 self attention은 의미가 없으므로 제거해도 성능 차이 X)
-> 하지만 코드의 간결함을 위해 남겨둠.
(3) Encoder-Decoder Attention
- Encoder의 결과물과 query slot 간 attention을 통해 어느 query가 어떤 위치에서 object를 찾을 수 있을 지 학습
(4) FFN
- Output에 대한 normalization & 학습 보조

- Decoder의 slot은 이미지/물체에 대한 이해와 더불어 각자의 관계를 학습하여 slot 개수(N)만큼의 embedding 값을 출력함
-> 전체 이미지를 하나의 context로 이용
- 각 embedding 값을 FFN에 태운 뒤 특정 slot이 예측한 물체의 유무 + 물체의 위치를 출력함
- 순차적인 관계(NLP)가 아니므로 set-prediction 수행함.
3.4. Overall training procedure
(1) Extract feature map by CNN backbone
- BackBone(ResNet50)을 입력해서 feature map 추출
(2) Add Positional Encoding
- Feature map을 1x1 conv 입력해서 flatten한 feature map에 대한 positional encoding 더함
- Transformer Encoder 통과
(3) Generate Object queries
- Object query 생성
(4) Output encoder memory by Transformer encoder
- output: Encoder memory
(5) Output output embedding by Transformer decoder
-
Attention 지나서 나온 output을 Decoder에 multi-head attention layer에 전달
-
Transformer Decoder 통과
- FFN를 타고 output embedding 출력
(6) Class prediction by Class head
- class prediction head를 통한 class 예측
(7) Bounding box prediction by Bounding box head
- bounding box head를 통한 예
(8) Match prediction with ground truth by Hungarian Matcher
- Hungarian Matcher을 통한 최적의 (i) 탐색
(9) Compute losses
- Loss 구하기
- Hungarian matcher를 통해 구한 permutation σ(i)으로 matching된 prediction과 ground truth 사이의 loss를 구함
4. Experiments
4.1. Comparison with Faster R-CNN
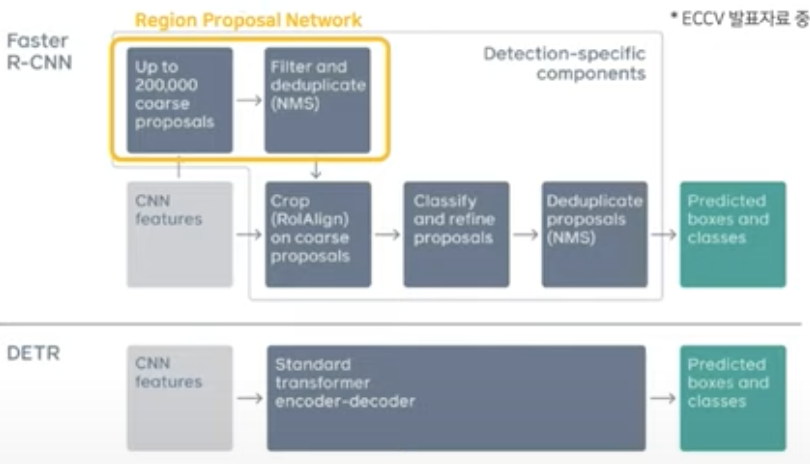
- Faster R-CNN
: RPN과 NMS을 거치고 최종적인 후보 위치를 예측한 후, 해당 지역들에 대해 다시 한번 Detection을 수행하는 복잡한 pipeline
- DETR
: 직접적이고 절대적인 방식으로 box set을 예측함으로써 NMS와 같은 수작업 과정을 사용하지 않기 때문에 end-to-end 구조를 구축할 수 있음.

- 크기가 큰 물체에 대해서는 Faster R-CNN 대비 높은 성능을 달성함.
- 하지만 크기가 작은 물체에 대해서는 낮은 성능을 달성함.
4.2. Ablations
4.2.1. Encoder
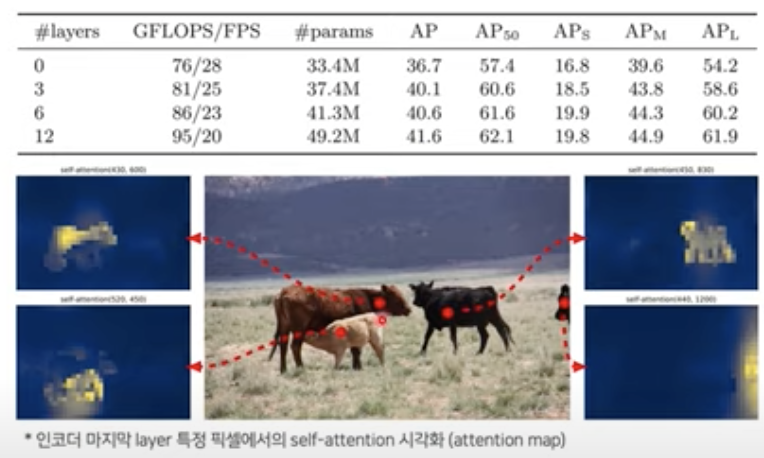
- 위의 사진은 encoder의 MHSA 내용을 시각화한 것.
- 사진에 찍힌 빨간 점을 query라고 할 때 그 query에 대해 활성화 되는 attention map을 시각화함.
- DETR의 attention mechanism이 image 내 물체를 분리하는 데 굉장히 중요함.
여기서 알 수 있는 점은 Encoder에서부터 이미 물체를 구분할 수 있다는 점이다!
-> 덕분에 Decoder에서는 simple한 작업만을 수행 가능함
4.2.2. Decoder
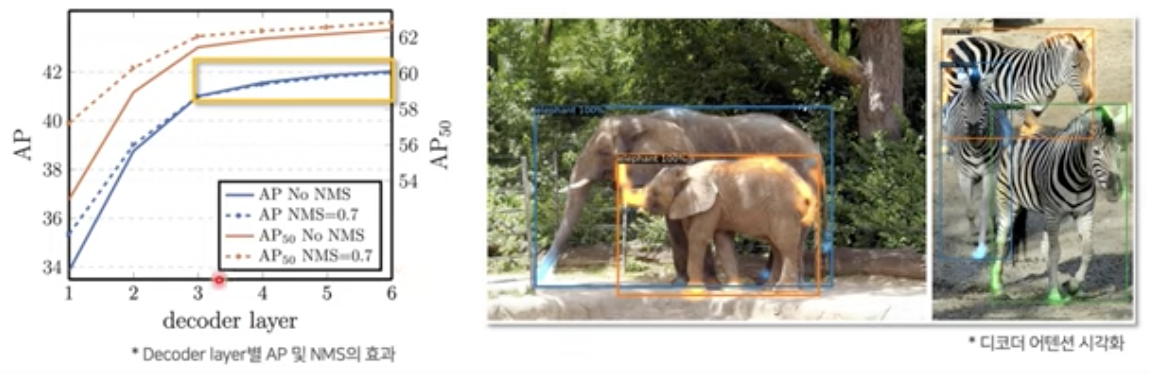
- Decoder Layer가 깊어질수록 예측 정확도가 높아지고, NMS을 추가하여도 효과 X
- Decoder에서는 object의 extremities(말단)에 attetion을 주도록 학습
- class 및 물체의 바운더리를 잘 추출하도록 attention을 줌.
5. Conclusion
- Object Detection -> dire set prediction 관점
- Transformer + End-to-End의 간결한 pipline
[geometric Prior(RPN, NMS)]
- 확장성 very good + 높은 잠재성
한계점
: 학습 시간 많이 필요함 + 작은 물체에 대한 정확도 약함
장점
- 기존 object detection의 복잡한 과정을 dire prediction으로 단순하게 만듬.
- CNN 이후 Transformer를 사용하면 되는 구조로 매우 단순함.
단점
- Transformer의 특성상 학습하는데 많은 시간이 필요함.
- small object detection이 약함.
🎯 Summary
- 저자가 뭘 해내고 싶어 했는가?
- Transformer를 Object Detection에 최초로 적용
- 기존의 model들과 다르게 DETR모델은 객체 위치와 크기를 직접 예측 할 수 있기 때문에 별도의 수작업 과정이 필요 없음.
- 이 연구의 접근 방식에서 중요한 요소는 무엇인가?
- 이분 매칭(bipartite matching)
-> set prediction probelm을 직접적으로 해결해줌.
-> 학습과정에서 이분 매칭을 수행함으로써 instance가 중복되지 않도록 유도.
- Transformer
- 어느 프로젝트에 적용할 수 있는가
- Object Detection
- Segmentation
- 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- Transformer
- ViT
- Faster R-CNN
- Hungarian Algorithm
- 느낀점은?
- Hungarian Algorithm에서 막히고 수식에서 막히고 총체적 난국이었음. 아직도 이해가 안됨...(동공지진) 다시 공부해서 보완해야겠음!
- Transformer를 object detection 분야에 end-to-end모델로 확장한점이 신선했음.
- Transformer을 기반으로 한 발전은 끝이 없음......
- Transformer를 활용한 project에 대한 소망을 품은채 오늘의 리뷰는 여기서 마무리하겠습니다!!!!!!!!!!
📚 References
유튜브
- https://www.youtube.com/watch?v=q1wSykClIMk, 고려대학교 dsba (소규성)
블로그
