사이드 프로젝트로 3월부터 시작했던 사이드 프로젝트 관리 웹 서비스 "풀(Project+Full) 케어(Care)"가 개발 막바지이다.
프로젝트가 끝나가는 이 시점에 장장 6개월동안 진행해왔던 사이드 프로젝트를 되돌아보고, 진행중 겪었던 시행착오 및 경험들을 정리해보고자 이 글을 쓴다.
팀 구성
최초에 팀을 구성했을 때는 아래와 같았다.
- 백엔드 개발자(Java/SpringBoot) 2명 -> 나는 여기에 해당
- 프론트엔드 개발자(React) 2명
- 디자인 1명
프로젝트 구성원은 나를 제외한 모두 대학교에 재학중인 학생이었다. 나만 학교안다니는 백수...읍읍
그리고 프로젝트 실개발을 진행하던 중 추가로 프론트엔드 개발자를 1명 더 모집해서, 최종적으로는
- 백엔드 개발자(Java/SpringBoot) 2명
- 프론트엔드 개발자(React) 3명
- 디자인 1명
총 6명으로 프로젝트를 진행했다.
일정
3월 ~ 4월동안에는 프로젝트 주제 선정 및 기획에 대한 회의를 진행했다. (+ 내 경우엔 하고 있던 스프링, JPA 공부도)
5월부터 실제 개발에 들어갔고, 8월말까지 대략 4개월동안 개발을 진행했다. 프로젝트 구성원 모두가 전업 개발자가 아니었기 때문에, 개발속도가 엄청 빠르지는 않았다. 또, 기획단계에서 생각했던 서비스 요구사항들이 아닌 추가적인 요구사항들이 많이 생겨나면서 개발기간이 많이 길어졌다.
실제로 개발할거라고 생각했던 API보다 2배나 많은 API를 개발했다 🫠

위의 사진이 맨 처음 호기롭게 계획했던 개발 일정인데, 전혀 지키지 못했다.

자기 반성을 해보자면... 개발 초반이었던 5월까지는 일정을 어느정도 따라갔었던 것 같은데, 6월 쯔음부터 프론트와 연동하는 작업이 시작되면서 추가적인 요구사항이 쏟아졌고, 프론트와 협업하는 프로젝트 경험이 전무했던 상황이었기 때문에 갈피를 못잡고 엄청 헤맸던 것 같다. 그러던 와중에 다른 팀원들의 학업 이슈(중간/기말고사)도 있었고, 내 스스로도 좀 루즈해졌었다. 반성하자 나 자신

프로젝트 팀원들이 대부분 학생인지라 9월에는 개강이라 프로젝트 마무리는 아무리 늦어도 8월말까지는 하자고 했었는데, 그 말이 현실이 되었다. 그래도 기획 단계부터 서비스 개발까지 중간에 포기하지않고 마무리했다는 데에 의의를 두고, 함께해준 팀원들에게 심심한 감사인사를 보내본다.
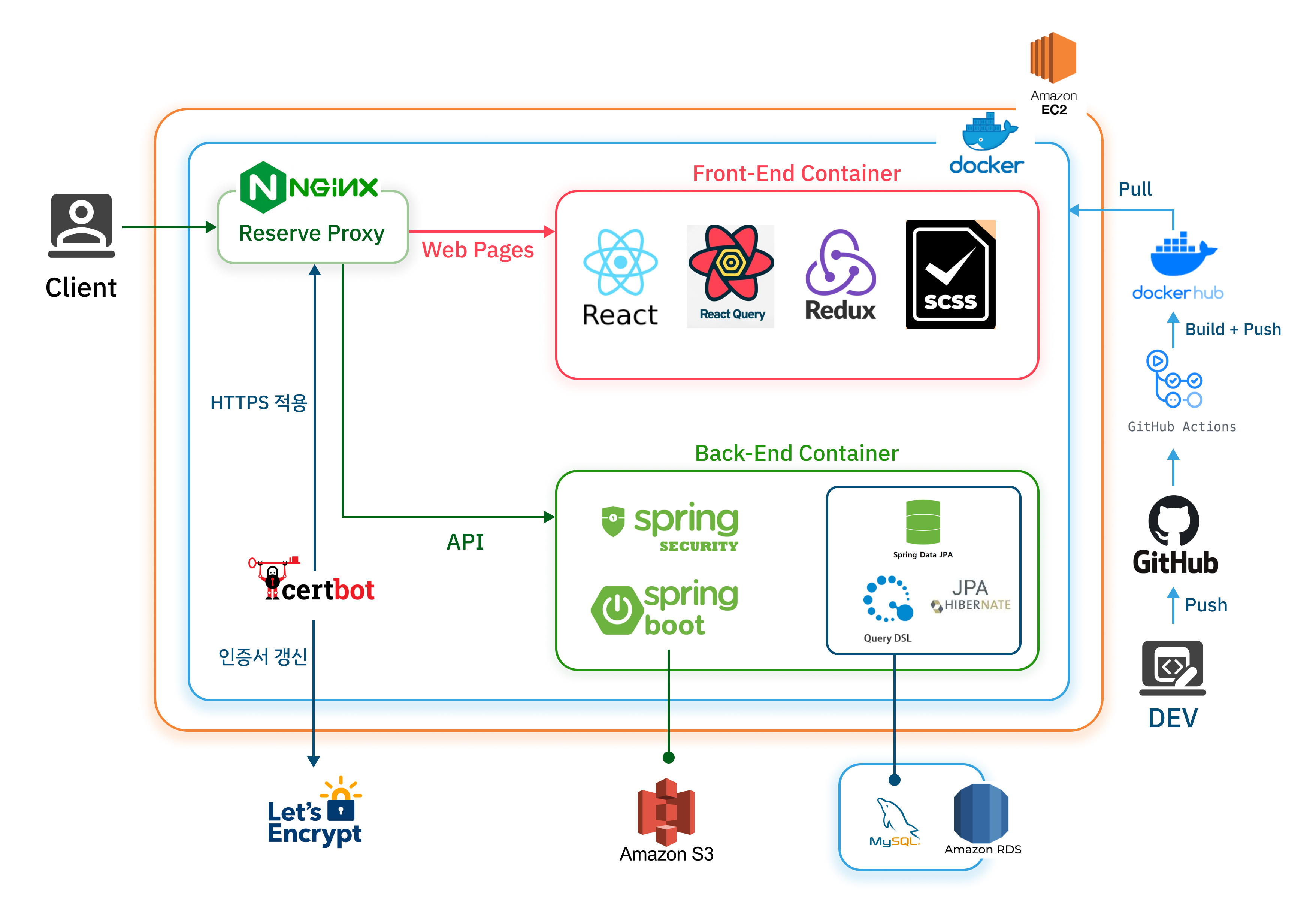
최종적으로 완료된 프로젝트의 구조는 다음 사진과 같다.
자, 이제 프로젝트를 실제로 개발하면서 노트북에 샷건을 쳤던 키보드로 교향곡을 치게 만들었던 여러 고비들에 대해 소개해보고자 한다. 아래의 설명할 이야기들은 모두 주관적인 의견들과 나만의 뇌피셜로 범벅될테니 감안하고 읽으시길.
첫번째 고비 - OAuth2, JWT, 그리고 스프링 시큐리티의 아내
르세라핌 팬 아닙니다. 전 에스파가 좋아요 ^^
진행했던 프로젝트의 경우 OAuth2와 JWT로 인증체계를 구축했는데, 이 두개를 선택한 이유는....
사실 명확한 이유는 없다.

직접 모든 아이디와 비밀번호를 데이터베이스에 저장하여 관리하는 것은 비효율적이라고 생각했고, 요 근래의 웹 서비스들은 소셜로그인만 지원하는 경우가 많기 때문에 그렇게 하기로 했다.
JWT는 세션기반의 인증과 토큰기반의 인증을 고민하던 중에 서버에 부하를 좀 더 줄이자는 생각으로 토큰기반을 선택했다.
무료로 제공되는 AWS EC2는 RAM이 2GB인가 밖에 안된다. 내 핸드폰보다 RAM이 작으면 어쩌자는거야 ㅡㅡ
그래도 아마존 좋아요 AWS 만세!
여튼, 그렇게 결정하고나서 봤더니 스프링 시큐리티에서 OAuth2와 관련된 모든 기능들을 제공하고 있었다.
스프링을 공부하고 실개발에 사용하면서 느끼는거지만 진짜.... 프레임워크 없었던 이전에는 어떻게 개발을 했었나 싶다. "이런 기능은 없을까? 만들어놓은게 있을법한데" 라고 생각이 들면 진짜 찾아보면 다있다. 거짓말이 아니라 진짜 다있음.
근데 기능이 다 있는건 있는 거고, 그걸 내가 잘 쓸 수 있다고는 안했다.

나는 스프링 코어 프레임워크, 스프링부트, 스프링 MVC, JPA, 스프링 데이터 JPA 만 공부를 했었던 상태라서 스프링 시큐리티에 대한 내용은 전혀 모르고 있었기 때문에, 독립적인 프로젝트로 관리되고 있는 방대한 양의 스프링 시큐리티를 전부 공부할 시간은 없었다.
그래서, 개념적인 부분을 스킵하고 바로 다른 프로젝트의 코드를 들여다보면서 바로 개발을 시작했다. 스프링 시큐리티의 핵심이 되는 요소와 어떤 매커니즘을 토대로 작동하는지만 개념적으로 파악하고, 그냥 맨땅에 헤딩한다는 생각으로 디버그 모드로 코드 한줄한줄씩 읽으면서 로직을 파악했다.
그 결과, 약 2~3주간의 삽질 끝에 OAuth2와 JWT를 이용한 인증관련 구현을 성공적으로 끝마쳤다.
아래의 사진은 나의 삽질의 결과다.
얼마나 힘들었는지... 봐주세요 제발
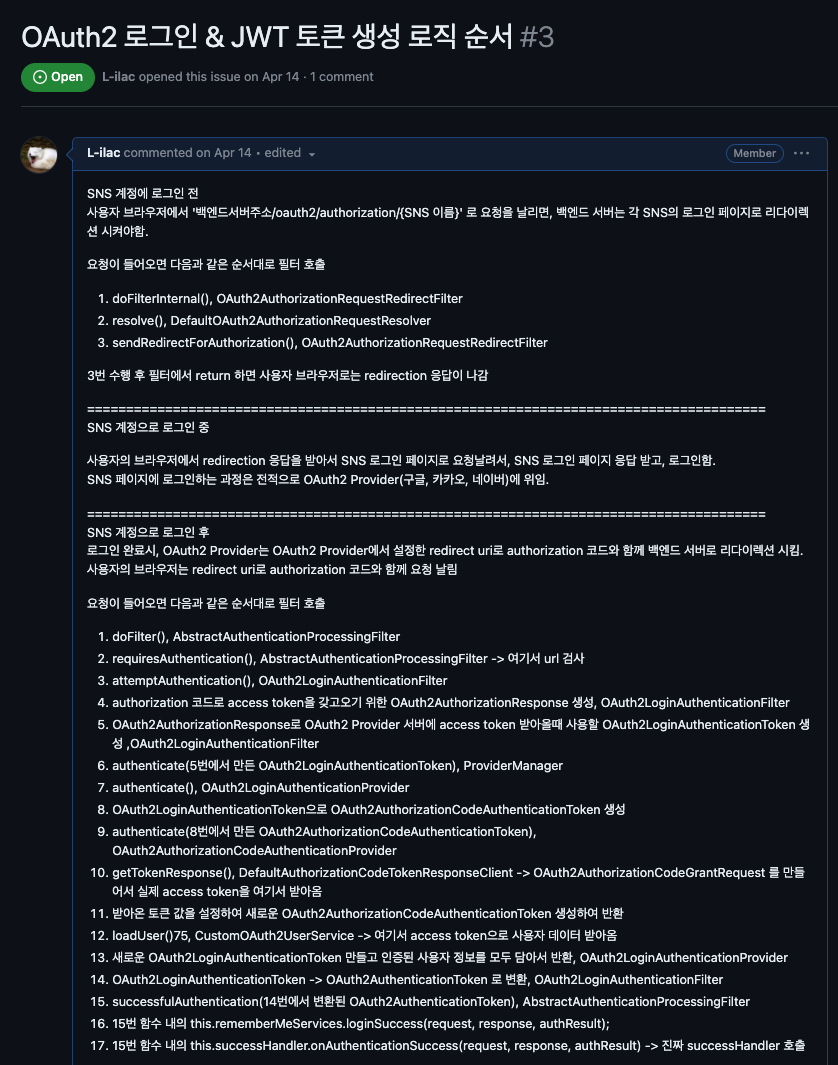
사실 위의 사진은 삽질의 한 50% 정도? 에 해당한다.
저거 말고도 삽질한게 굉장히 많은데, 제일 무식하게 삽질한게 위에 사진에 있는 거였어서 가져와봤다. 나머지는 그래도 나름 이름모를 선배 개발자들이 잘 정리해놓은 글이나 정보들이 많아서 그것들을 잘 읽어보고 이해하면서 활용했다.
인증 관련 구현을 완료한 후에 내가 느낀점으로는 다음과 같은 것들이 있다.
- 스프링 시큐리티는 매우 편리하다.
- 이미 구현되어있는 인증과 관련된 수많은 기능들을 설정 클래스 파일 하나로 입맛대로 커스텀해서 사용할 수 있다는게 정말이지 최고다.
프레임워크가 최고야 늘 새로워 짜릿해 - 하지만 그만큼 프레임워크를 사용하는 방법을 공부하는 과정은 필수불가결하다.
- 이미 구현되어있는 인증과 관련된 수많은 기능들을 설정 클래스 파일 하나로 입맛대로 커스텀해서 사용할 수 있다는게 정말이지 최고다.
- 생각보다 스프링부트는 많은 것을 자동화해놓았다.
- 의미없다고 생각했던 annotation 하나에도 스프링부트가 해놓은 자동설정이 덮여쓰여서 기능이 작동이 안되는 경우가 있었는데, 그런 부분을 보면서 사소한 코드 한줄이더라도 프레임워크에서는 엄청난 나비효과를 갖고 올 수 있겠다 라는 생각을 했다.
결론적으로는 스프링 시큐리티와 관련된 모든 경험은 이번 프로젝트를 진행하면서 내가 새롭게 얻은 성과들 중 베스트 3 안에 들지 않나 싶다. 앞으로 현업에서 스프링 시큐리티를 사용하게 되거나, 또 다른 사이드 프로젝트를 하더라도 좋은 양분으로 남아있을 것이다. 좋았~~~숴!
두번째 고비 - 성능을 위한 DB 쿼리 줄이기
누군가 나에게 웹 서비스를 개발하는데 있어서 가장 중요한 측면을 고르라고 한다면, 나는 다음 두 가지를 꼽을 것이다.
- 보안
- 성능과 안정성
보안이 중요한 이유는 내가 일일이 설명하지 않아도 될 것 같다. 비단 웹 서비스뿐만이 아니라, IT와 컴퓨터공학에서의 모든 부분에서 보안은 아무리 강조해도 지나치지 않다.
그 다음으로 고른 것은 성능과 안정성이다.
웹 서비스도 결국 "서비스"이기 때문에 서비스를 사용하는 사용자가 있어야 존재의 의미가 있는 것이고, 더 많은 사용자가 서비스를 사용하려면 성능과 안정성이 뒷받침되어야 하기 때문이다. 웹 서비스를 사용하는데 페이지가 하나 넘어갈때마다 30분이 걸린다거나 시도때도 없이 서버가 터져서 연결이 끊긴다면, 아무도 그 서비스를 사용하려고 하지 않을 것이다.
안정성의 경우, 스프링부트 서버가 내부적으로 사용하는 모듈에 의해서 보장된다. 웹 서버로 들어오는 요청을 처리하는 톰캣이 쓰레드 풀을 사용한다던가, 데이터베이스에 접근할 때 JPA에서 사용하는 HikariCP이 이에 해당한다. 물론 프로젝트의 규모나 사용자 수 등을 고려해서 튜닝을 해야할 수 도 있지만, 튜닝적인 부분까지 생각하기엔 내 실력이 너무 부족하다. 역시, 공부할게 넘쳐난다. 야호~
웹 애플리케이션에서 대부분의 성능은 데이터베이스와 관련된 작업에서 발생한다. 물론 데이터베이스 말고도 작성하는 소스코드 자체에서도 무거운 연산을 사용하거나 시간복잡도가 말도안되는 코드를 사용한다면 그 또한 성능에 영향을 미치겠지만, 그런 케이스를 제외하면 결국 문제는 데이터베이스이다. 특히 내가 진행했던 사이드 프로젝트는 복잡한 수학연산이나 인공지능 모델을 사용하는 서비스가 아니라, 요청한 데이터를 보여주거나 입력한 데이터를 저장하는 기능이 주요 기능이기 때문에 대부분의 성능이 데이터베이스와 관련된 코드에서 발생한다.그래서 그만큼 시간을 많이 쏟을 수 밖에 없었다.

프로젝트에서 사용한 데이터베이스와 관련된 작업은 모두 JPA와 Spring Data JPA를 사용했다. JPA와 Spring Data JPA 모두 ORM 기술로써 객체와 데이터베이스의 관계를 매핑해주는 도구인데, 프로그래밍 언어의 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑해준다.
보통 JPA와 Spring Data JPA를 이용해 데이터베이스 작업을 수행할 때 대부분의 성능의 척도는 읽기 연산, 즉, select 쿼리에 의해 결정되는 경우가 많다. 왜냐하면 데이터베이스의 성능을 저하시키는 가장 주된 원인이 Join 연산이기 때문이다. 여러 개의 테이블을 동시에 묶어서 데이터를 조회하는 것이 성능에 가장 큰 영향을 끼친다.
데이터베이스와 관련된 작업에서 좋은 성능을 내기 위해서는 아래의 두 가지를 잘해야한다고 생각한다.
- 도메인 엔티티 설계
- 적절한 JPA 기능 사용 -> 페치조인, 엔티티그래프 등
위의 두 가지를 위해 개발을 진행하는 내내 수도 없이 고민하고 수정했다.
개발을 시작한 5월부터 개발이 마무리된 8월말까지 매주 프로젝트 팀원 모두가 참여하는 회의를 진행해왔는데, 전체 회의를 제외하고도 다른 백엔드 개발자 한분과 매주 한번 씩 추가적인 회의를 하면서 어떻게하면 좀 더 좋은 코드를 작성할 수 있을지에 대해 토론했다. 원래도 개발과 관련된 의견을 나누고 토론하는 걸 좋아해서 그 시간이 매우 즐거웠다. 내가 보지 못했던 시각에서 다른 사람의 의견을 듣는 것도 신선했고, 나의 생각을 상대방에게 알려주는 것도 재밌었다.
 |  | 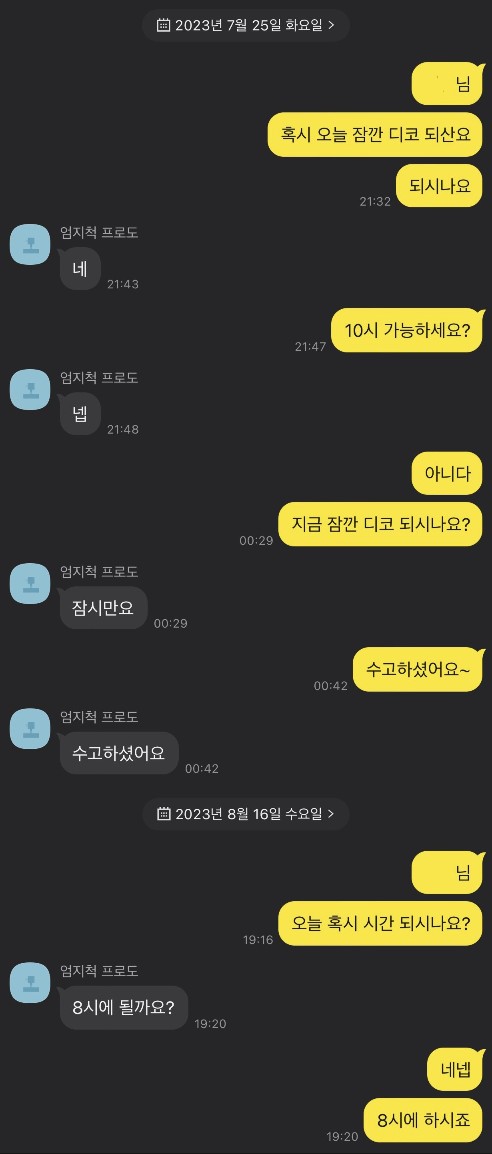 |
|---|
수많은 되시나요? 의 향연.jpg ⬆️
그렇게 머리를 쥐어짠 결과 프로젝트에서 사용되는 API 모두 API 당 DB 쿼리가 최대 4회를 넘지 않게 최적화를 할 수 있었다. 줄어드는 DB 쿼리를 보면서 희열을 느꼈던 것 같다.
아쉬웠던 점은 프로젝트의 데이터베이스로 다양한 종류의 DB를 선택하지 못했다는 점이다. 프로젝트에서 다루는 데이터의 유형이 관계형 데이터베이스에 적합했기 때문에 RDBMS를 사용했지만, 개인적으로 NoSQL을 사용하는 MongoDB나, Redis 같은 In-Memory DB도 사용해보고 싶은 생각이 있었다.
SQL 쿼리 튜닝을 통해서도 성능적 이점을 얻을 수 있지만, 상황에 따라서는 비정형데이터를 사용하거나 In-Memory DB 같이 하드웨어레벨에서 접근 속도 자체가 빠른 DB를 사용하는 것이 성능에 도움이 될 수도 있기 때문이다. 만약 또 다른 사이드 프로젝트를 하게 된다면, 그 때는 MongoDB, Redis를 둘다 써보고 싶다.
세번째 고비 - 수많은 버그와 예외의 향연
Q. 다음 중 더 위험한 말을 고르시오.
1. 어? 이게 왜 안되지?
2. 어? 이게 왜 되지?대부분의 개발자들에게 위의 질문을 묻는다면, 대부분 2번을 선택할거라고 생각한다.
1번 같은 상황은 문제라고 생각하는 지점을 디버깅을 하면 정상적으로 코드가 동작하지 않는 이유를 찾을 수 있지만, 2번 같은 상황은 문제가 있는지 없는지 조차 확신할 수 없고, 설령 심증적으로 문제가 있다고 생각해도 명확한 문제 발생 가능성이 있는 지점을 찾아내기가 어렵기 때문이다. 만약 2번 같은 상황을 제대로 확인을 하지 않고 지나간다면, 추후에 문제가 발생할 가능성이 높고 내 코드에 언제 터질지 모르는 시한폭탄을 심어놓은 것이다 다름 없다. 아래의 짤 같은 상황일 수도 있는 것이다.
다행히도 이번 프로젝트를 진행하면서는 위에서 얘기했던 2번에 해당하는 경우는 없었다. 그 대신 수많은 1번 케이스가 존재했는데...🫠 그래도 나는 디버깅을 하면서 비정상적인 로직을 찾고 그 부분을 고치는 과정을 즐기는 편이기 때문에 크게 괴롭지는 않았던 것 같다.
보통 개발중에 터지는 버그는 2종류이다.
- 사용하는 외부 라이브러리의 예외나 내가 직접 작성한 예외가 던져지면서 터지는 버그
- 잘못된 비즈니스 로직 작성으로 인해 생기는 버그
자바 개발자라면 예외는 아주 익숙한 단어이다. 소스 코드를 작성할 때 의도한 흐름이 아닌 비정상적인 흐름으로 코드가 동작되는 경우에 의도적으로 예외를 발생시켜 해당 코드의 실행을 막는 것인데, 우리가 일상생활에 사용하는 "예외" 라는 단어처럼 말 그대로 코드 상의 예외(Exception)인 셈이다.
예외는 내가 개발하는 프로그램에 맞게 직접 예외를 생성할 수도 있고, 외부의 라이브러리 또한 누군가의 창작물이기 때문에 외부의 라이브러리를 개발한 사람이 생각하는 비정상적인 동작 흐름을 막기 위해 만들어져 사용된다. 예외가 던져진다는 것은 곧 내가 작성한 코드가 비정상적인 동작을 유발했다는 말이므로, 버그로 이어질 확률이 높다. 그래도 개발단계에서 예외는 IDE의 터미널이나 콘솔 등에 예외를 일으킨 클래스가 스택형태로 전부 출력되기 때문에 비교적 추적과 수정이 쉽다.
아래와 같이 말이다.
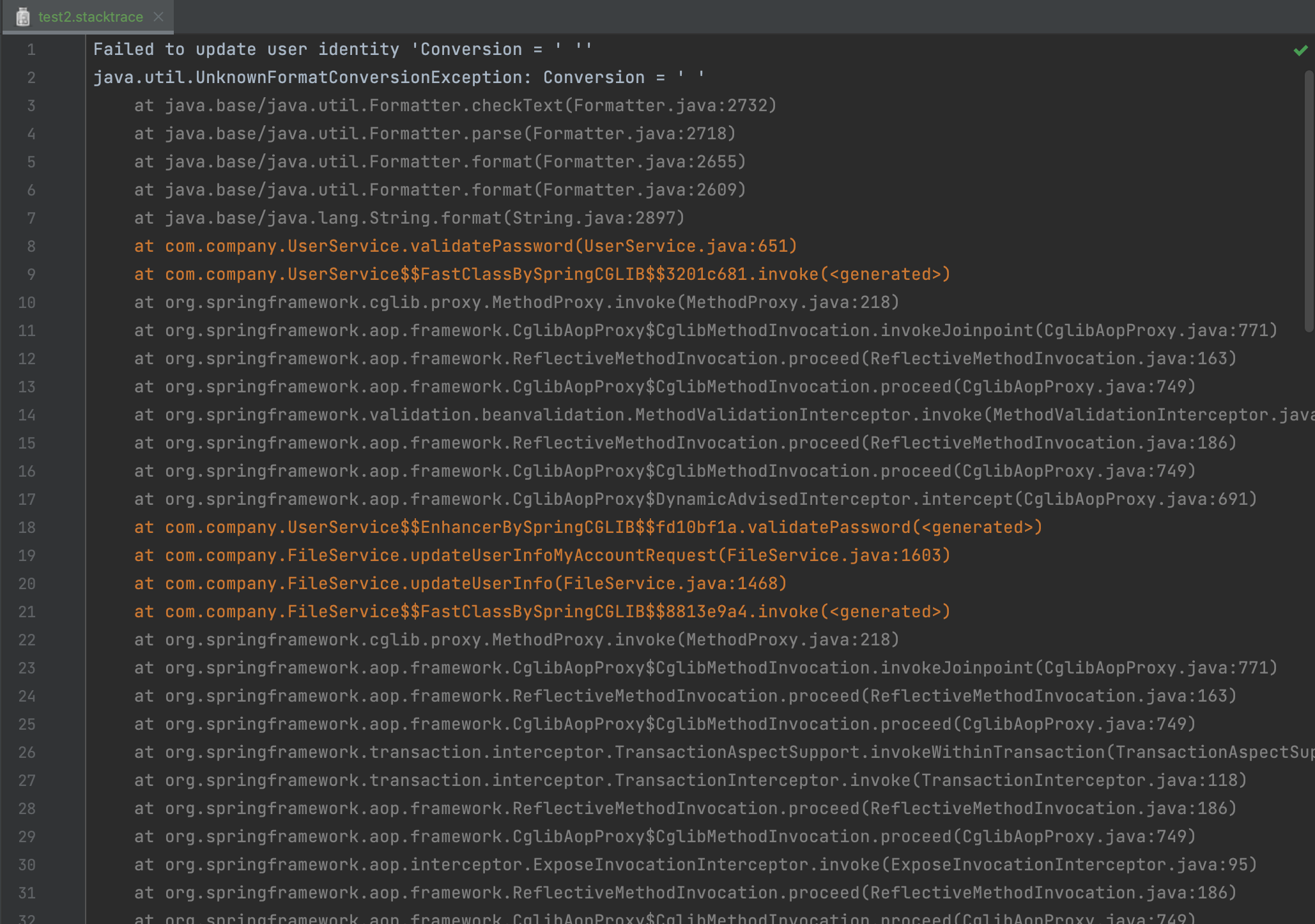
그에 반에 잘못된 비즈니스 로직으로 인해 발생하는 버그는 조금 까다롭다. 일단 우선적으로 비즈니스 로직이 잘못된 것이지 프로그래밍 언어의 문법이나 API 사용 방식이 잘못된 것이 아니기 때문에, 실제로 서버를 실행시켜서 직접 기능을 사용해야 문제를 알 수 있다. 테스트코드가 이를 위해서 존재하지만 작성하지 않은게 사실 문제다
또, 비즈니스 로직이 잘못되었다면, 비즈니스 로직 자체를 통으로 수정해야하기 때문에 좀 더 많은 고민과 시간이 필요하다. 비유를 해보자면, 어떤 물건의 사용 설명서를 만들었는데 설명서에 들어간 글의 단어가 오탈자가 있는게 아니라 사용방법 자체가 틀린 상황이라서 아예 사용방법을 통째로 고쳐야하는 것이다.
다행스럽게도 진행했던 프로젝트에는 복잡한 비즈니스 로직은 크게 없었기에 동작이 수행되어야하는 순서나, 데이터의 조회, 생성, 수정, 삭제의 권한과 관련된 처리만 신경써서 코드를 작성해주면 충분했다. 하지만, 해당 기능의 코드를 작성하면서도
테스트 코드의 필요성을 어렴풋이나마 느꼈지만 끝까지 작성하지 않은 점은 반성해야할 부분이다.
네번째 고비 - DevOps? DevOops!
DevOps를 구글링하면 다음과 같은 의미를 가진 단어라고 결과가 나온다.
데브옵스(DevOps)는 소프트웨어의 개발(Development)과 운영(Operations)의 합성어로서, 소프트웨어 개발자와 정보기술 전문가 간의 소통, 협업 및 통합을 강조하는 개발 환경이나 문화를 말한다. 데브옵스는 소프트웨어 개발조직과 운영조직간의 상호 의존적 대응이며 조직이 소프트웨어 제품과 서비스를 빠른 시간에 개발 및 배포하는 것을 목적으로 한다. - from Wikipedia
내가 생각하는 데브옵스의 목적은 결국 소프트웨어 개발을 단순히 코드를 작성해서 프로그램을 완성시키는 것으로 국한시키는 것이 아닌 배포, 운영, 유지보수 등의 개발 완료 후 실제 서비스로 제공되기까지, 더 나아가 제공된 이후에도 필요한 모든 더 넓은 범위로 확장시키는 것이다.
진행한 프로젝트에서도 AWS EC2, AWS RDS, DOCKER, GitHub Actions, 총 4개의 인프라/기술로 배포와 유지보수를 자동화하고, 서버를 운영 및 관리했다.
<프로젝트 기술 스택 구조.jpg>
나를 포함한 백엔드 개발자 2명 모두 데브옵스와 관련된 기술은 사용해본 경험이 전무해서, 구글링을 통해 여러 자료들을 참고해서 우리의 프로젝트에 적용했다. 해당 기술들을 우리 프로젝트에 적용하면서 이전까지는 직접 수작업으로 해야했던 서버 실행 환경 구성, 배포가 자동화라는 강력한 무기를 갖게 되었고, IaaS, PaaS, SaaS의 등장으로 인해서 개발자는 더욱 더 소프트웨어 개발 자체에만 선택과 집중을 할 수 있게 되었다는 점에 절실히 공감했다.
데브옵스와 관련된 기술들은 아직도 넘쳐난다. DOCKER를 효율적으로 관리할 수 있는 Kubernetes, 또 다른 CI/CD 도구인 Jenkins, 스프링부트 서버 모니터링 툴인 Actuator, Prometheus, Grafana 등등 아직 내가 이름만 들어보고 써보지 못한 도구들이 매우 많다. 더 좋은 개발자가 되기 위해서는 이런 도구들이 어떤 원리로 돌아가는지 이해하고, 적재적소에 사용할 수 있도록 많이 써봐야할 것 같다.
다섯번째 고비 - 리팩토링의 늪
좋은 코드란 무엇일까? 이번 프로젝트를 하면서 꽤나 많이 고민했던 주제이다.
코드 작성은 수학 문제처럼 명확한 답이 있는게 아니다. 하물며 명확한 답이 있는 수학문제마저도 다양한 풀이 방법이 존재하는데, 코드 작성은 정상적인 기능의 동작이라는 공통적인 목표가 있을 뿐 계산을 통해 답을 산출하는 행위가 아닌 것이다. 동일한 동작을 하는 코드는 개발자의 스타일에 따라, 만들고자하는 서비스의 특징에 따라, 때로는 소속된 개발 조직에서 정해놓은 규칙에 따라 천차만별이다. 그럼에도 불구하고, 대부분의 개발자들이 동의하는 공통적인 좋은 코드의 조건은 존재한다.
그 조건들을 모두 고려하여 내가 생각한 좋은코드는 다음과 같다.
- 읽기 쉽고 따라가기 좋은 직관적이고 간결한 코드
작성자가 아닌 타인이 보았을 때 무슨 기능을 하는 코드인지, 동작의 흐름을 직관적으로 이해할 수 있어야한다. 이로 하여금 다른 개발자들이 나의 코드를 보았을 때, '왜 코드를 이런 방식으로 구성 및 작성했지?'라는 의문이 최대한 들지 않게끔하는게 중요하다고 생각한다. 이를 위해서 나는 프로젝트 중에 코드를 작성한 후에 다른 사람의 입장에서 보는 시간을 꼭 가졌다. 또, 지속적으로 또 다른 백엔드 개발자분께 코드에 대한 피드백을 요청해서 어떤 부분이 모호했는지, 어떤 부분이 이해하기 좋았는지 의견을 받았다.
- 구조적으로 아귀가 맞아 떨어지는 코드
구조적으로 아귀가 맞아 떨어진다고하면 어떤 사람이든 '그게 뭔데?'라는 의문을 가질 것이다. 사실 나도 내 설명이 너무 추상적이라고 생각한다. 하지만, 구체적으로 잘 설명을 못하겠다. 😂
비유를 해보자면, 나는 깔끔하게 정리되어있는 공간이나 규칙적인 패턴을 보면 편안함을 느끼는데, 그거랑 비슷하게 구조적으로 깔끔한 코드가 좋다. 구조적으로 깔끔한 코드가 되려면 어떻게 코드를 적절히 분리할 것인지가 제일 중요하다고 생각한다. CQRS(Command and Query Responsibility Segregation) 패턴에서 커맨드와 쿼리를 분리하는 것처럼, 어떤 로직을 어떤 클래스의 어떤 메서드에 포함시켜야하는지, 공통적인 로직을 어디서부터 어디까지 추출해서 새로운 메서드로 정의할 것인지에 대해 고민을 시작하는 것이 좋은 코드 작성으로의 출발점일 것이다.
좋은 코드를 작성하는 과정에서의 리팩토링은 필수불가결하다. 그렇기에 프로젝트 내내 리팩토링의 늪에서 계속 허우적거리면서 코드를 수정했다. 이 회고록을 작성하고 있는 어제만해도 리팩토링만 거의 2시간...? 정도 한 것 같다. 그래도 다행인건 내 스스로가 리팩토링을 통해 코드를 어떻게 배치해야 위에서 설명하는 좋은 코드일까를 고민하는 과정을 즐겼다는 점이다.

리팩토링 전과 후.jpg ⬆️
여전히 누군가 나에게 어떻게 코드를 작성하는게 과연 좋은 코드인지 묻는다면 그 질문에 딱 떨어지는 정확한 답을 할 수 없을 것 같다. 다만 내가 생각하는 좋은 코드에 대해서 설명하고, 그게 왜 좋은 코드인지에 대해 타당한 근거를 설명할 수 있는 개발자가 되어야겠다.
프로젝트를 하면서 느낀점 총평
- 의미없는 삽질은 없다
프로젝트 초기 단계에 스프링 시큐리티를 이용해서 OAuth2/JWT 인증 시스템을 구축할 때, OAuth2와 JWT에 대해서는 알고 있었지만 스프링 시큐리티에 대해서 아는 것이 전혀 없어서 엄청 삽질을 많이했다. 스프링 시큐리티가 워낙 방대한 프로젝트라서 관련 내용이 정리된 블로그도 거의 50개 이상 봤던 것 같고, 스프링 시큐리티 공식문서도 5일 정도는 붙잡고 끙끙거리면서 읽었다. 중간중간 높은 벽에 가로막힌 기분이 들어서 많이 힘들었지만 많이 읽으면 읽을수록 감을 잡을 수 있었고, 인증 시스템 구축을 완료했을 쯤에는 초반에 읽을 때 이해하지 못했던 문서들이 어떤 의미를 갖고 있었는지 뒤늦게 이해되는 경우도 있었다. 의미없는 삽질은 없다. 단지 파고자하는 포인트를 좀 더 쉽게 팔 수 있도록 그 주변을 파고 있었던 것 뿐이었다.
- 공부할 것은 차고 넘친다. 선택과 집중을 하자.
개발자는 평생 공부해야하는 직업이라는 말이 있다. 새로운 기술의 출현은 빈번하고, 일주일이 지나면 사용하던 도구의 새로운 버전이 업데이트되어 나온다. 컴퓨터 공학의 모든 부분에 대해 전부 다 잘 알고, 현업에서 사용하는 모든 기술들을 통달할 수는 없다. 선택과 집중이 중요하다. 내가 개발을 하면서 필요한 내용들은 심도있게 공부하고, 비교적 연관성이 낮은 내용들은 개괄적인 이해정도만 하고 과감히 내려놓는게 좋다. 추후에 그 내용이 필요할 때 공부해도 늦지 않다.
- 기록의 중요성
솔직하게 말하면 나는 기록을 잘 하는 편은 아니다. 보통 뭔가를 공부할 때 핵심이 되는 원리를 이해하고, 그 원리를 기억하면 원리를 출발점으로 차근차근 다음 상황을 도출해내면서 복기를 하는 타입이다. 하지만, 사람에게 영원한 기억이란 없다. 반복적으로 내용을 확인하지 않는 한 시간이 지나면 지날수록 공부했던 내용들이 흐릿해져 기억이 희석된다. 그래서 나도 스프링 프레임워크를 공부하기 시작한 후부터 공부했던 내용들을 개인 블로그에 기록하고 있다. 또, 이번 프로젝트를 진행하는 동안 개발과 관련해서 새롭게 알게된 점이나 개발중 생기는 문제들에 대해서 GitHub에서 제공하는 Git Issue에 기록하려고 애썼다. 개발 막바지의 사소한 수정사항들은 기록하지 않은게 더 많지만 그래도 기록하려고 노력했다는데 의의를 두려고 한다. 기록도 연습이 필요하다. 꾸준한 연습을 통해 습관으로 만들어야겠다.
개선해야할 점
- Devops에 대한 나의 생각
요즘 IT분야 채용공고를 보면 Devops 엔지니어라는 직군을 따로 뽑는다. 그만큼 IT 업계에서도 Devops를 중요하게 여기고 있고, 전담으로 Devops와 관련된 업무를 하는 인력이 필요하다는 뜻이 아닐까 싶다. 개발자는 애플리케이션의 기능을 제작한다면, Devops 엔지니어는 제작 이후의 배포과정, 유지관리를 담당하는 것이다.
대학교 학부 때 소프트웨어공학개론 수업을 들었었는데, 강의에 이런 내용이 있었다.
'소프트웨어 라이프사이클에서 실제 코드 작성은 일부만을 차지할 뿐이고 사실은 그 외의 일들이 더 많은 비율을 차지한다'
이 내용을 처음 들었을 당시에는 크게 잘 와닿지 않았었는데, 이제는 그 말을 완전히 이해한다. 교수님은 도대체 몇 수 앞을....
더욱이 이번 프로젝트에서 DOCKER 나 Github Actions 같은 데브옵스 툴을 사용해서 여러 프로세스를 자동화해놓으니 자연스레 Devops 엔지니어의 필요성에 대해서도 공감하게 되었다. 더욱이, 백엔드 개발자를 지망하는 사람으로서 Devops와 관련된 지식 또는 도구들을 사용할 수 있다면 나의 강력한 무기가 될 것이라고도 생각했다.
- QueryDSL과 동적쿼리의 부재
스프링에서 동적쿼리를 사용하기 위해서는 MyBatis 같은 SQL Mapper, JPA에서 제공하는 Criteria, 외부 프로젝트인 QueryDSL을 쓴다. JPA, Spring JPA와 같은 ORM을 사용한다면 MyBatis는 자연스럽게 선택지에서 제외되고, Criteria와 QueryDSL을 사용해야 하는데, 그 중에서도 QueryDSL은 Criteria에 비해 직관적인 API를 제공하고, 사용하기도 편리해서 많이 선택된다.
하지만, 이번 프로젝트에서 내가 개발한 API 중에는 검색, 필터링 기능이 들어간 API가 없었다. 그러므로, 사용자의 입력 값에 따라 데이터베이스로 요청되어야하는 쿼리가 달라지는 동적쿼리가 없었다는 것이다. 그래서 QueryDSL에 대한 공부를 따로 하지 않았다. 다양한 종류의 쿼리를 다루지 못해 아쉽고, 추후에 꼭 학습이 필요할 것이다.
- 테스트 코드 미작성
아쉽게도 이번 프로젝트를 진행하면서 테스트 코드를 하나도 작성하지 않았다. 테스트 코드를 작성하지 않은 이유는 생각보다 간단한다. 테스트 코드 작성에 대해 아는게 너무 없었다. 테스트를 위해 사용되는 JUnit5나 Mockito같은 라이브러리에 대해 잘 알지 못했고, 어떻게 테스트 코드를 구성해야하는지에 대해서도 아는게 하나도 없었다. 실제 현업의 개발에서는 테스트 코드가 필수일텐데, 그 부분을 사이드 프로젝트 진행하면서 연습하지 못했다는 것은 개선해야할 점이다.

안녕하세요.
혹시 아키텍쳐 어떤 툴로 그리셨나요?