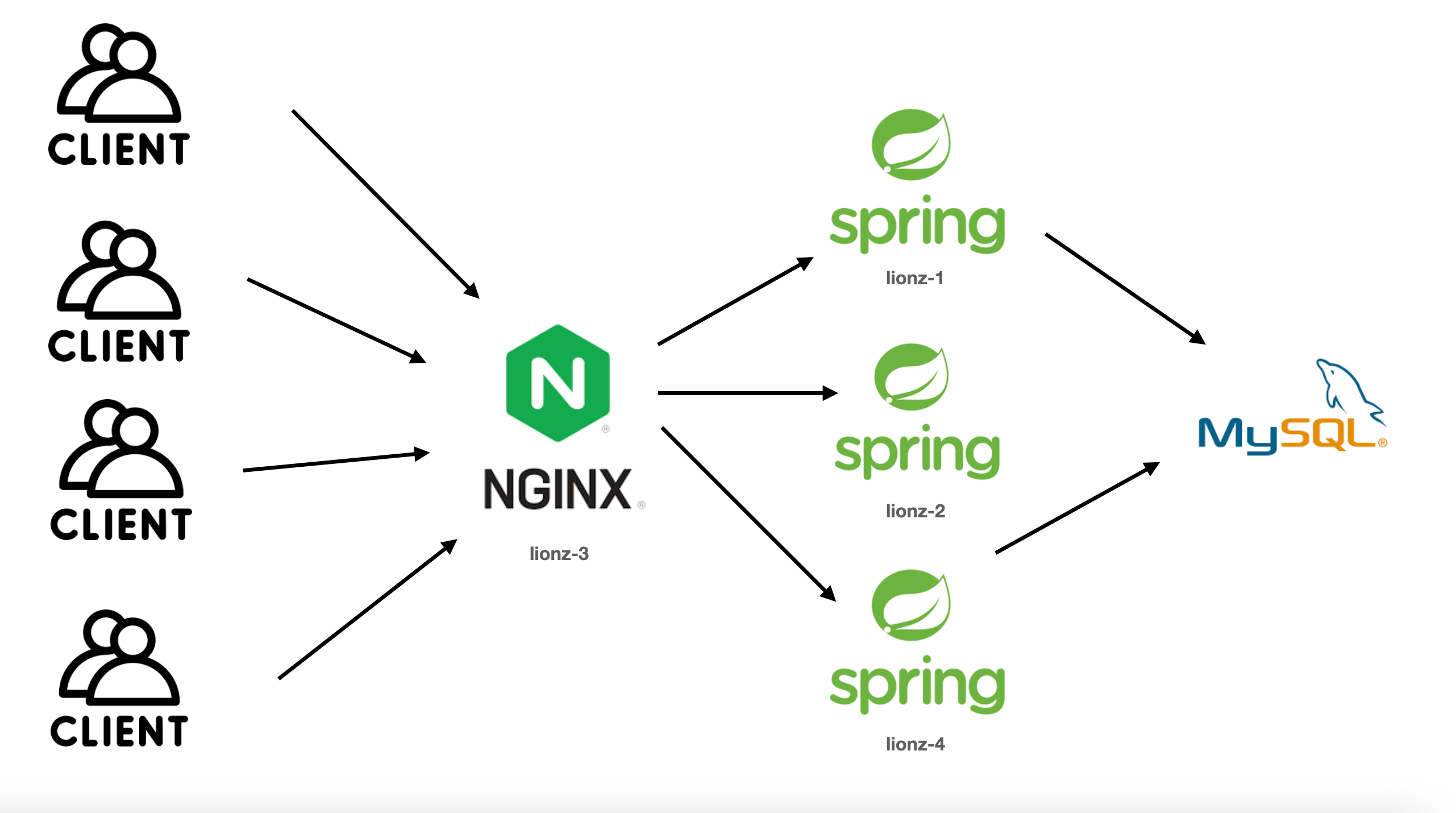
로드밸런서 스펙 :vCPU 4EA, Memory 16GB, [SSD]Disk 50GB
WAS 스펙 : vCPU 2EA, Memory 8GB, [SSD]Disk 50GB
RDS 스펙 : 8vCPU, 32GB Memory
들어가기 전에
과거 Nginx를 이용한 로드밸런싱 테스트에서 로드밸런싱을 적용해 1,000명의 동시 사용자를 받을 수 있도록 세팅한 적이 있었습니다.
이번엔 LB서버와 RDS서버 scale-up을 진행하고 Tomcat 스레드 튜닝 등을 진행보려고 합니다.
목표
목표는 평균 0.1초가 걸리는 api에 2,000명의 동시 사용자가 부하를 주어도 감당할 수 있도록 로드밸런싱을 적용하는 것입니다.
서버 한 대만 우선 튜닝해보자
기존에 아무 설정도 건드리지 않았을 때는 vus가 200~250만 되어도 서버가 다운됐었습니다.
톰캣의 max-threads를 500으로 늘려보겠습니다. (default: 200)
server:
tomcat:
accept-count: 100
max-connections: 8192
threads:
max: 500캡쳐하지 못했지만 vus가 600이 넘어가면 부하테스트 초기에 `connection reset by peer` 나 `request failed`에러가 났었습니다. 초기에만 발생하고 일정 시간이 지나면 에러가 나지 않는 것을 보고 한 가지 추측을 할 수 있었습니다.
처음부터 max-threads만큼의 스레드가 존재하는 것이 아니다.
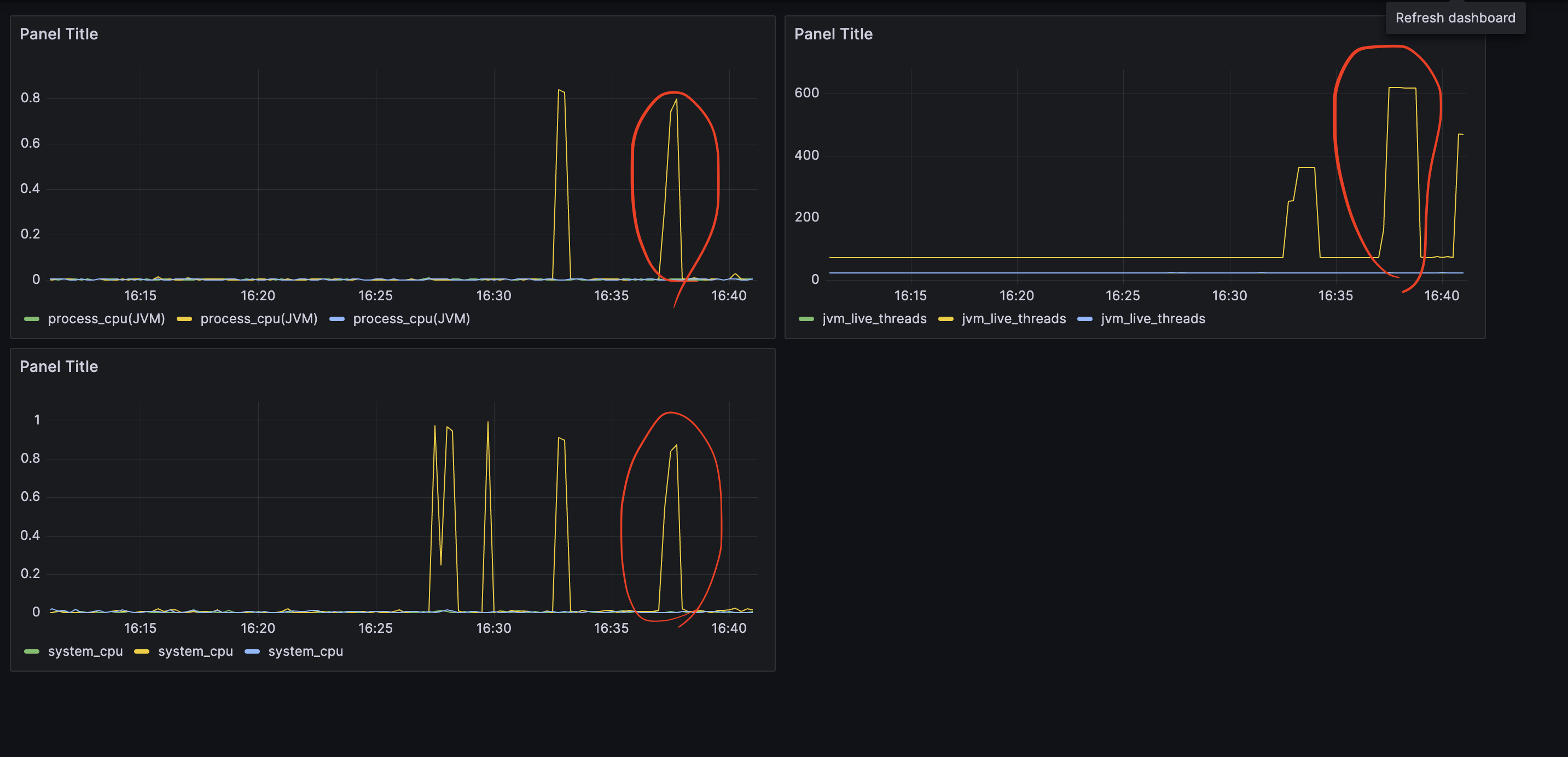
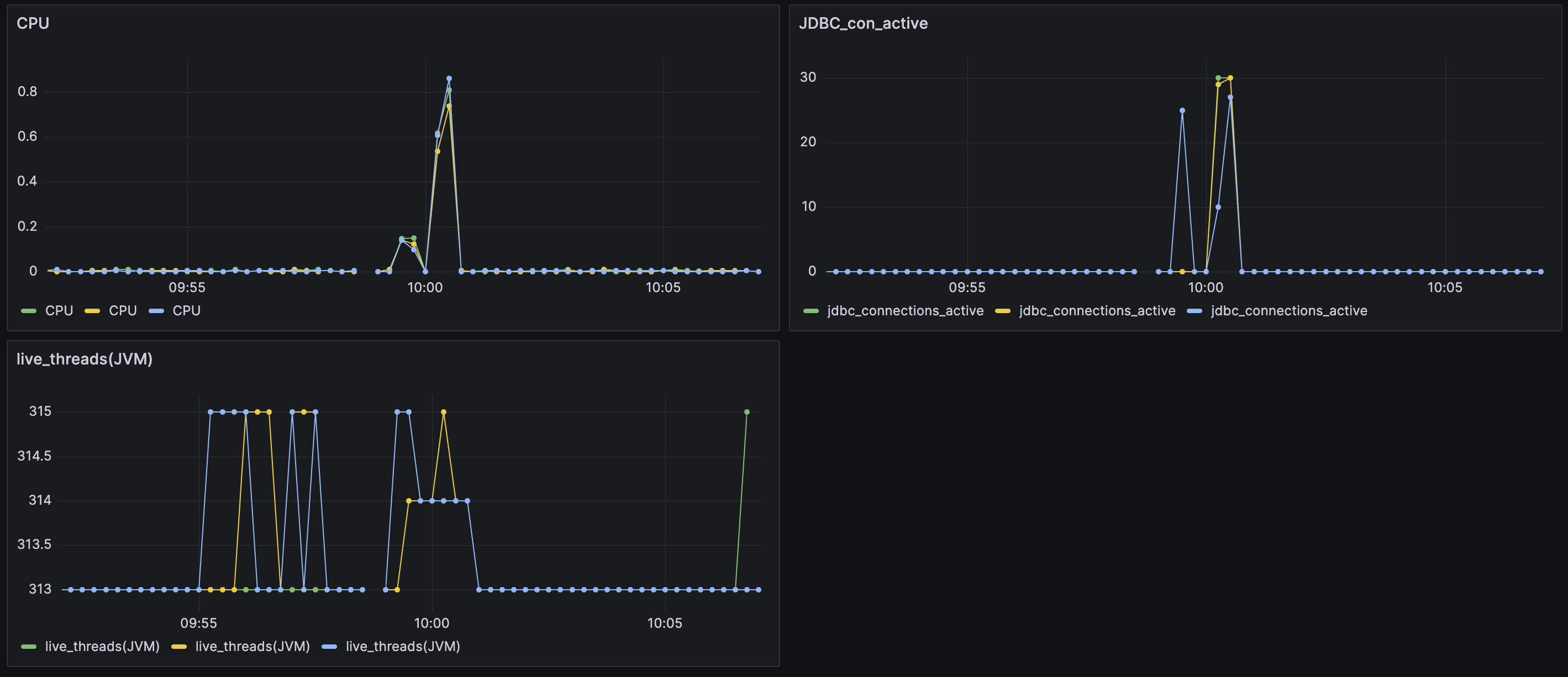
우측의 그래프는 jvm의 실시간 스레드 수 그래프입니다.
그래프를 보면 처음에는 고정적으로 적은 스레드를 가지고 있다가 요청이 많아지면 그제서야 스레드가 증가하는 모습입니다.
따라서, 부하 초기에 발생하는 에러를 해결하기 위해서는 초기에 존재하는 idle threads가 현재보다 높아야 한다고 판단했습니다.
따라서, 톰캣의 min-spare를 300으로 설정했습니다.
server:
tomcat:
accept-count: 100
max-connections: 8192
threads:
max: 500
min-spare: 300 (default : 10)DB Connection 튜닝
추가적으로 DB와의 연결을 위해 hikari maximum-pool-size도 30으로 늘려주었습니다. (default : 10)
spring:
datasource:
hikari:
maximum-pool-size: 30기존에는 평균적으로 응답에 0.1초가 걸리는 API에
600TPS를 감당하기위해 DB의 connection pool을 60으로 늘리려고 했는데
이번 실험의 목적이 WAS서버의 스펙은 고정시키고 LB와 RDS서버 스펙만을 올려서 비용적으로 이득을 보려고 했기 때문에 60보다 작게 진행하려고 노력했습니다.
또한, 적은 것이 오히려 좋다 라는 글을 보고 30으로 진행하기로 결정했습니다.
결과
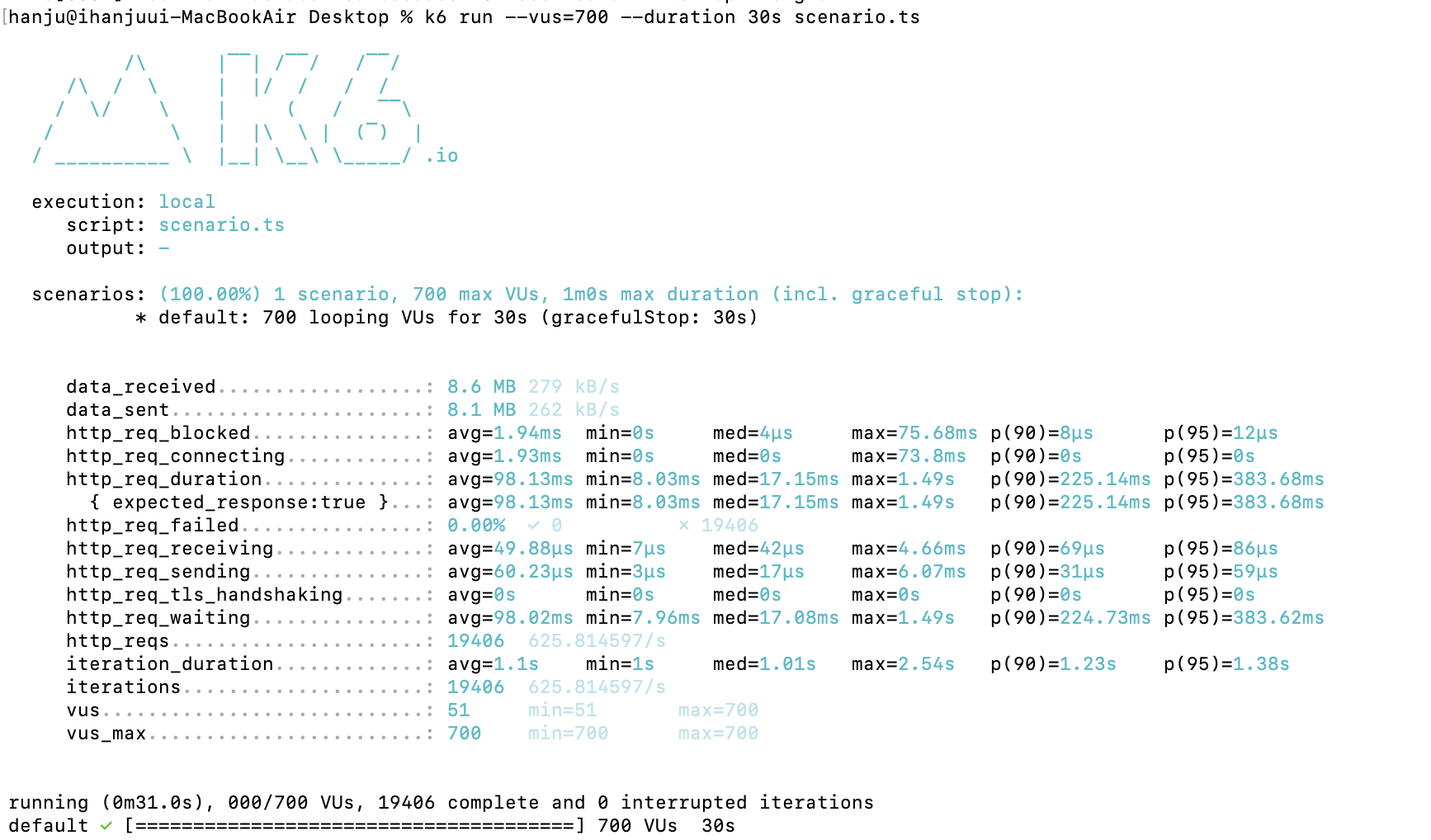
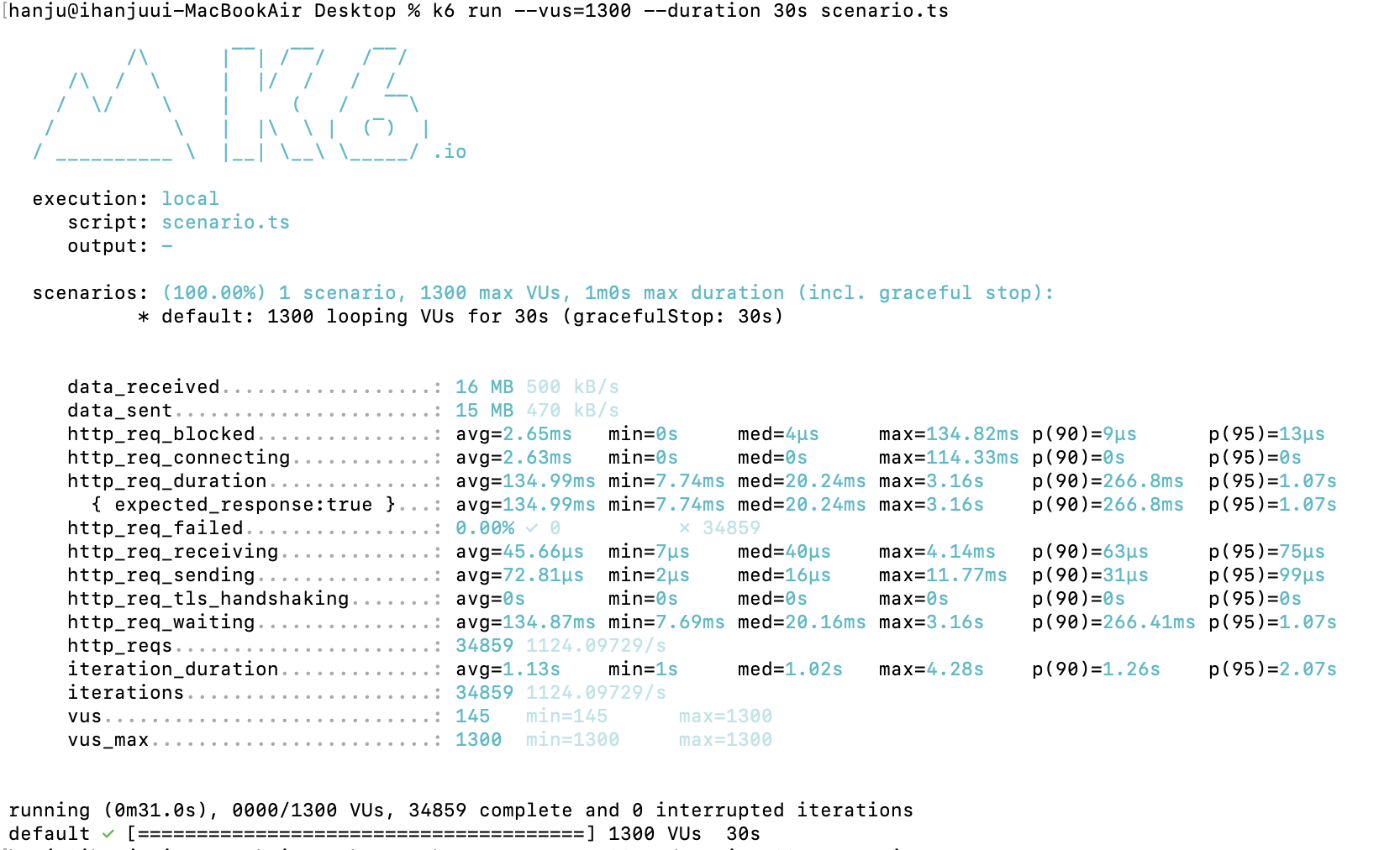
600명 O

700 O
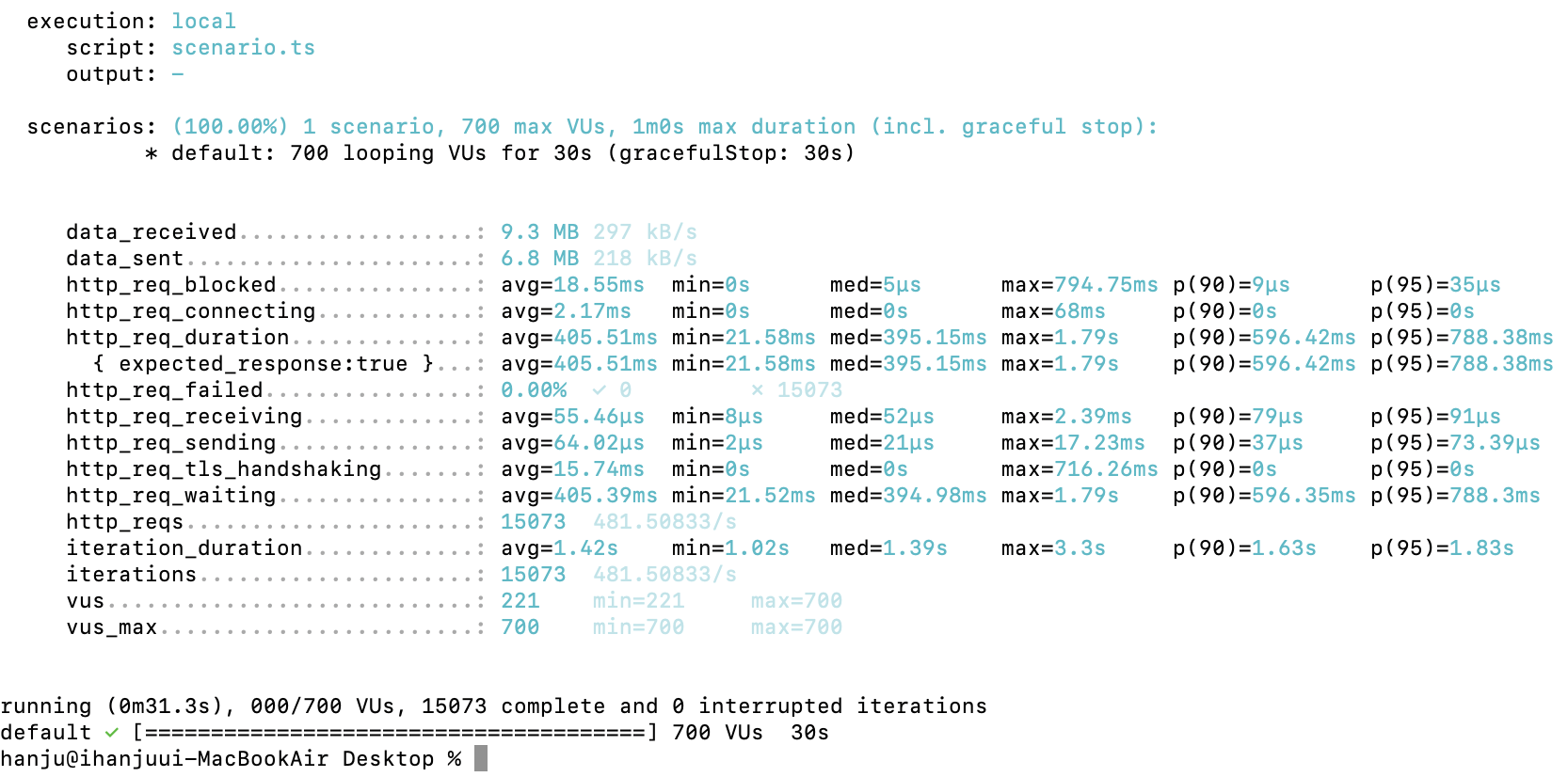
부하테스트 해보니 600~700명의 동시사용자의 요청에도 에러없이 수행하는 모습을 확인할 수 있었습니다.
사실 hikari:maximum-pool-size를 10으로 해도 됐었습니다.
connections = ((core_count * 2) + effective_spindle_count)
PostgreSQL - 데이터베이스 커넥션 개수 공식
위의 공식을 보니 default인 10으로 그냥 진행해도 되겠다는 판단을 했고 실제로 해보니 에러 없이 그대로 수행하는 모습을 보였습니다.
(시간을 비교했어야 했는데 못하고 실험을 끝내버린..)
결과적으로 WAS서버 스펙을 올리지 않는 이상 hikari:maximum-pool-size은 건드리지 않는 것이 가장 빠른 응답속도를 보이는 것이 맞는 것 같습니다.
로드밸런싱 적용
DB서버 스펙을 올려보자
로드밸런싱을 적용했을 때 앞단에서 부하를 분산해도 어차피 DB로 오는 길목에 병목이 생길 것이라고 판단하여 기존의 RDS보다 3배정도 scale-up을 진행했습니다.
기존 RDS스펙 : 2vCPU, 8GB memory
New RDS 스펙 : 8vCPU, 32GB Memory
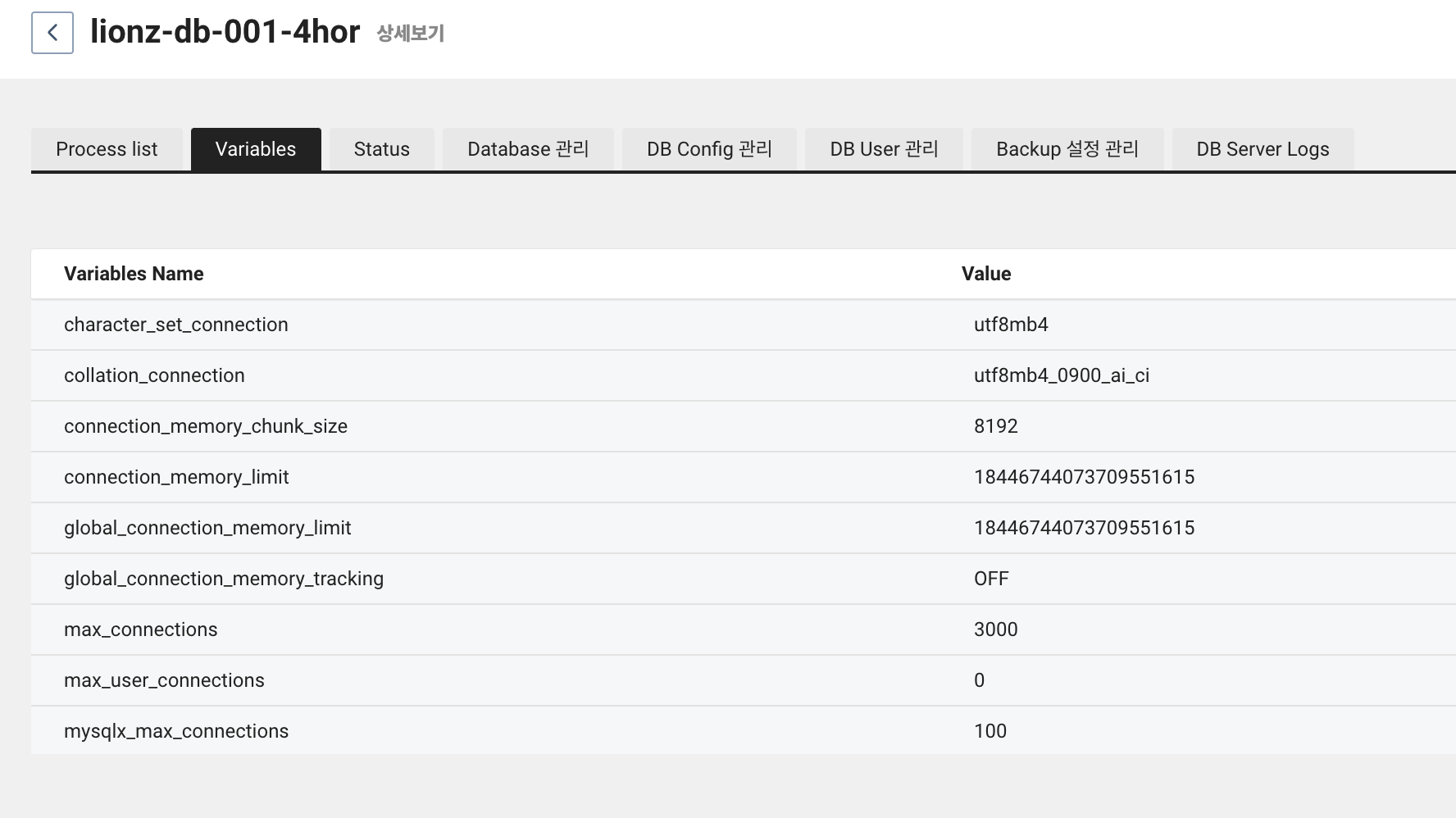
위와 같이 max_connections가 넉넉히 3,000으로 늘었습니다.
(추가) WAS서버의 DB커넥션 수는 WAS서버의 CPU의 수와 비슷해야 효율적이라고 합니다. HDD에서 SDD 로 바뀌면서 I/O 접근에 들어가는 시간이 줄어들게 되었고 스레드가 I/O 에 대한 waiting 하는 시간보다 오히려 context switching 을 하는 경우에 대한 비용 값이 더 커지면서 커넥션 풀의 적절한 크기는 오히려 코어 수에 맞추는 정도가 적절하고, 늘리더라도 코어 수의 2배이상을 넘기지 않는 것이 좋다고 합니다.
scale-up 하기전 DB서버의 max_connections수도 300언저리로 충분했던 것 같은데 그럼 DB서버 스펙 업은 더 빠른 Disk I/O를 위한 것이라고 보는 것이 맞는 것 같습니다.
로드밸런서 튜닝
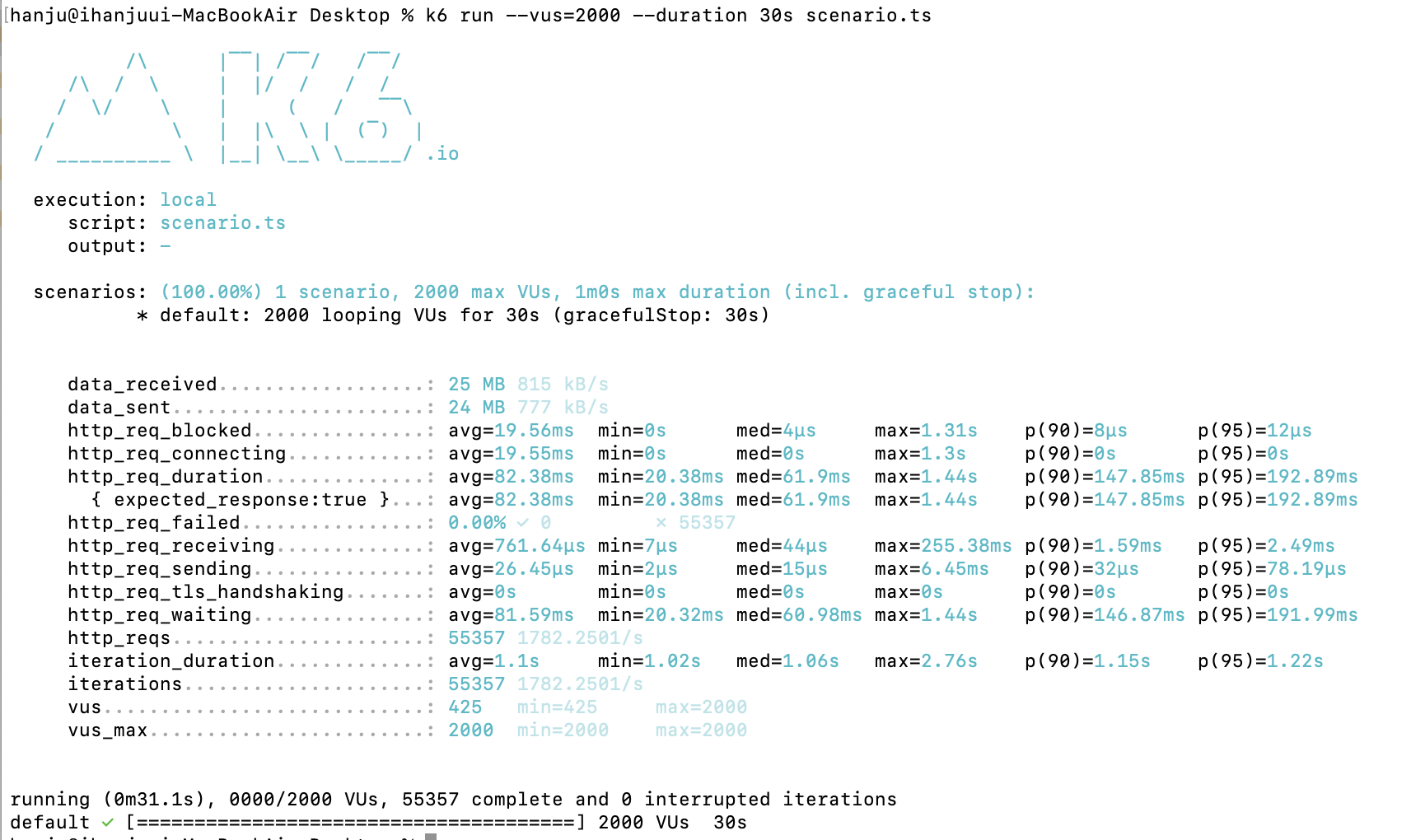
3대의 WAS로 부하를 분산한다고 해도 앞에 있는 LB에 부하가 한 번에 몰릴 것이기 때문에 LB서버 스펙도 올려야 한다고 판단했습니다.
기존 로드밸런서 스펙 :vCPU 2EA, Memory 8GB, [SSD]Disk 50GB
NEW 로드밸런서 스펙 :vCPU 4EA, Memory 16GB, [SSD]Disk 50GB
단순히 scale-up으로는 부하를 성공적으로 견디지 못하는 모습을 보여서
현재 로드밸런서 역할을 해주는 Nginx도 튜닝을 진행했습니다.
worker_connections
Nginx는 worker process * worker connection 만큼의 request를 동시에 처리할 수 있습니다.
worker process는 auto로 설정해두어 서버 cpu에 맞게 자동 세팅이 되게 했고 기존에 512였던 worker connection값을 2048로 증가시켜주었습니다.
추가
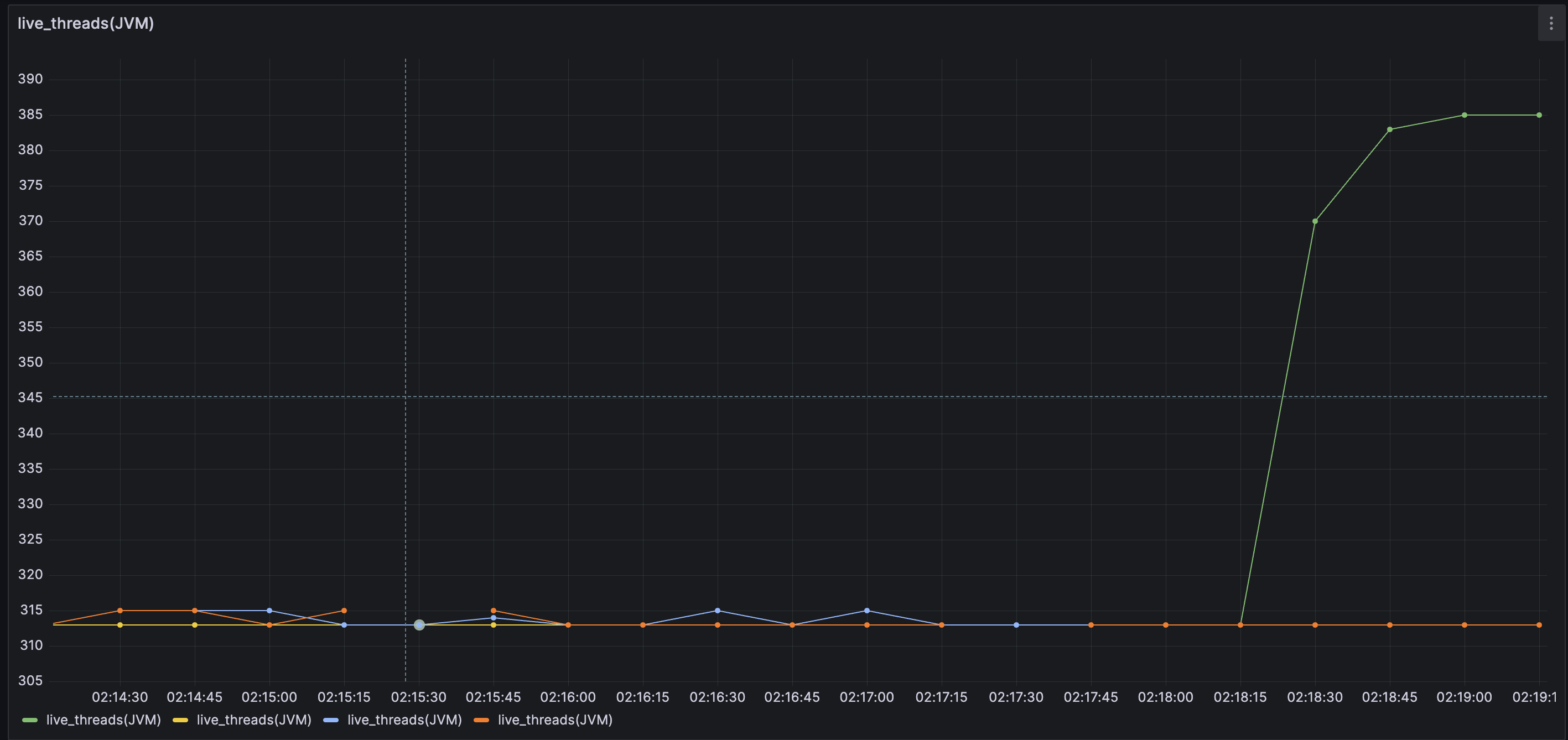
이상한 점이 있었는데 max-threads를 500으로 했을 때 실시간 스레드가 최대 315까지만 생성되었다
max threads를 700으로 늘리니까 스레드가 385까지는 올라간다..
또한, 제 노트북에서 서비스 서버로 k6를 통해 부하테스트를 하는 상황에서 저의 네트워크 상태도 중요할 수 있다는 생각을 했습니다.
인터넷 속도가 느리거나 핫스팟을 사용했을 때는 부하테스트 중 http_req_failed 가 몇 건 발생했었는데 네트워크 상태가 양호했을 때는 거의 나오지 않았습니다.
네트워크 상태가 양호하지 않으면 패킷이 손실될 수 있기 때문에 request fail이 충분히 발생할 수 있다고 생각했습니다.
출처
https://minholee93.tistory.com/entry/Nginx-Worker-Process
https://hodolman.com/m/16?category=326617
https://nginxstore.com/blog/nginx/nginx-%EC%95%A0%ED%94%8C%EB%A6%AC%EC%BC%80%EC%9D%B4%EC%85%98-%EC%84%B1%EB%8A%A5-%ED%96%A5%EC%83%81%EC%9D%84-%EC%9C%84%ED%95%9C-10%EA%B0%80%EC%A7%80-%ED%8C%81/


굉장히 어려운 걸 공부하시는 군요..! 응원합니다 👍