
쿠키 (Cookie)
HTTP는 기본적으로 과거의 행적(history)을 기억하지 않는 stateless한 특성을 가지고 있는데
쿠키(Cookie)가 stateful 하게끔 해준다
- 원래는 HTTP가 이전에 어떤 요청메시지를 보냈는지 이런 것을 신경쓰지 않아요. 그냥 잊어버리죠. 근데 특정 사용자를 제한하거나 사용자에 맞춰 콘텐츠를 제공해야할 수도 있잖아요? 근데 이
쿠키가 사용자를 추척해서 그것을 가능하게 해줍니다!
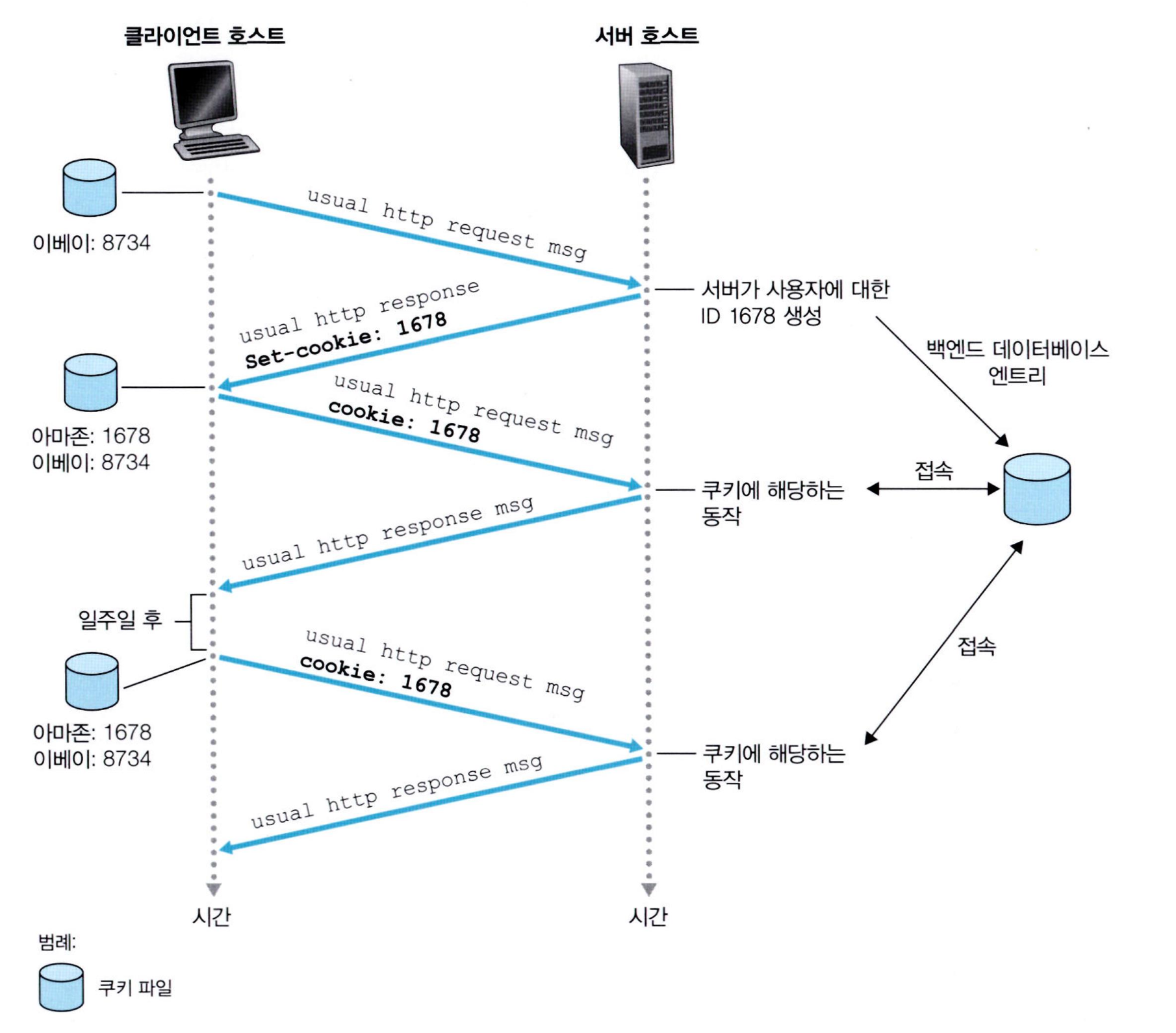
- 현재 클라이언트는 과거에 이베이에 들어갔던 적이 있는 상황
- 그래서 헤더에
이베이 쿠키 : 식별번호가 저렇게 있는 것임- 지금은 아마존에 들어가는 상황!
- 아마존에 접속하면 접속한 사용자에게 위와 같이 유일한 식별번호를 만들고 헤더에
Set-cookie:식별번호를 넣어서 응답을 함- 사용자는 이제부터 헤더에 그 부여된 cookie를 헤더에 넣어서 서버에 보내면 서버가 알아차리고 기억함
웹 캐싱
웹 캐시 (Web caches)혹은프록시 서버(proxy server)는 기점 웹 서버, 즉 Origin Web Server를 대신해서 HTTP요구를 충족시키는 네트워크 개체입니다.
웹 캐시는 자체의 저장 디스크를 가지고 있어서 최근 호출된 객체의 사본을 저장하고 있습니다.- 서버와 클라이언트의 거리가 굉장히 멀면 그 중간에 서버를 하나 더 두는것이 합리적입니다. 그 중간 서버가 바로 웹 캐시입니다.
- 자주 사용하는 objects는 proxy server에 두고 가끔 사용하는 objects는 original server에 가서 가져오도록 합니다.
상황으로 설명
- 한 사용자가 http://www.someschool.edu/campus.gif 라는 객체를 요구한다고 생각해봅시다.
- 그럼 먼저 브라우저와
웹 캐시가 TCP연결을 맺고웹 캐시에 객체에 대한 HTTP요청을 보냅니다. 웹 캐시는 그 객체 사본이 본인한테 저장되어 있는지 확인합니다.- 저장되어 있으면 HTTP응답 메시지+객체를 클라이언트 브라우저에 보냅니다
- 저장되어 있지 않다면
웹 캐시는기점 서버 (Origin Server)인 www.someschool.edu로 TCP연결을 맺고 그 객체에 대한 HTTP요청을 보냅니다 - 그래서
기점 서버 (Origin Server)로부터 객체를 수신하면 그 객체를웹 캐시의 저장장치에 복사하고 클라이언트 브라우저에 HTTP응답과 그 객체의 사본을 보냅니다.
-> 따라서웹 캐시는 서버이기도 하고 클라이언트이기도 합니다.
장점
- 클라이언트의 요구에 대한 응답 시간을 줄여줄 수 있습니다.
- 한 기관(회사나 학교)으로 접속하는 링크상의 웹 트래픽을 대량으로 줄일 수 있습니다. 따라서 기관들은 대역폭을 자주 개선할 필요가 없어서 비용이 절감됩니다.
-> 결과적으로 인터넷 전체의 웹 트래픽을 줄여주어 모든 애플리케이션의 성능이 개선됩니다.
조건부 GET
웹 캐싱이 응답시간을 줄일 수 있기는 한데 문제가 하나 있습니다.
캐시 내부에 있는 객체가 최신의 것이 아닐 때 입니다
캐싱된 후에 기점 서버에서는 갱신이 이루어진 상황인거죠
다행히도 HTTP는 클라이언트가 브라우저로 전달되는 모든 객체가 최신인지 확인하면서도 캐싱을 해주는 방식을 갖고있습니다.
이러한 방식을 조건부 GET이라고 합니다
(1) GET방식을 사용하고 (2) If-Modified-Since: 헤더라인을포함하고있다면, 그것이 조건부 GET 메시지입니다.
웹 캐시는 기점 서버(Origin Server)에 이렇게 말을 합니다.
"Last-Modified에 있는 날짜가 If-Modified-Since에 있는 날짜보다 최신이면 객체를 보내줘라"
- (의문점)근데 지금 보면 어쨋든
웹 캐시와기점 서버(Origin Server)끼리 HTTP메시지를 주고 받는 것 아닌가요?웹 캐시쓰는게 도움이 되는지..? - (답) ->
기점 서버(Origin Server)에서 객체가 갱신이 안되었다면웹 캐시에게 객체를 새로 줄 필요가 없죠? 그러면 그냥 HTTP응답 메시지의 개체 몸체 부분을 빈 상태로 보낼 수 있고 그것 자체가 대역폭을 낭비하지 않는 셈입니다!
DNS
우리들은 어떤 사람을 부를 때 주민번호로 부르지 않고 "홍길동"이라는 이름으로 부르잖아요? 그것이 더 쉽고 편리하기 때문입니다.
인터넷 호스트도 마찬가지입니다. IP주소로도 부를 수 있지만 www.google.com 같은 호스트 이름으로 되어있는 것이 우리들이 보기에 편합니다.
사람들은 이렇게 호스트 이름 으로 부르는 것을 선호하지만 실제 네트워크에서 라우터는 고정 길이의 계층 구조를 가진 IP주소를 좋아합니다.
이러한 선호 차이를 절충하기 위해
호스트 이름을IP주소로 변환해주는 디렉터리 서비스가 필요합니다.
이것이 인터넷 DNS (domain name system)의 주요 임무입니다.
간단한 DNS
DNS는 하나의 애플리케이션계층 프로토콜 입니다.
DNS를 가장 간단하게 구현하는 방법은 전 세계 통틀어하나의 네임 서버를 두는 것 입니다.
그러면 전 세계의 모든 클라이언트들은 이 하나의 네임 서버에 DNS질의를 하겠죠? 이 DNS질의라는 것은 IP주소에 맞는 호스트네임을 받기 위해 물어보는 느낌입니다.
근데 이렇게 단 하나의 네임 서버를 두면 문제점이 있습니다.
- 서버 고장 : 만약에 이 네임 서버가 고장나면 전체 인터넷이 작동되지 않습니다.
- 트래픽양 : 단일 DNS서버가 모든 DNS질의를 처리해야 합니다.
- 먼 거리의 중앙 집중 데이터베이스 : 서버가 만약 뉴욕에 한 대있으면 우리나라에서는 굉장히 멀겠죠??
- 유지관리 : 하나의 서버가 모든 데이터들을 기록해놓고 있어야하고 새로운 호스트들도 반영을 해야합니다.. 힘들죠
따라서 이런 중앙 집중 데이터베이스 형태는 확장성이 없습니다
분산 계층 DNS 서버
사실 우리는 결과적으로 DNS는 분산되도록 설계해서 사용중입니다!
위와 같이 계층이 나누어져 세 유형의 DNS서버가 있습니다.
- 루트 DNS 서버
- 최상위 레벨 도메인(TLD-top level domain) 서버
- 책임 DNS 서버
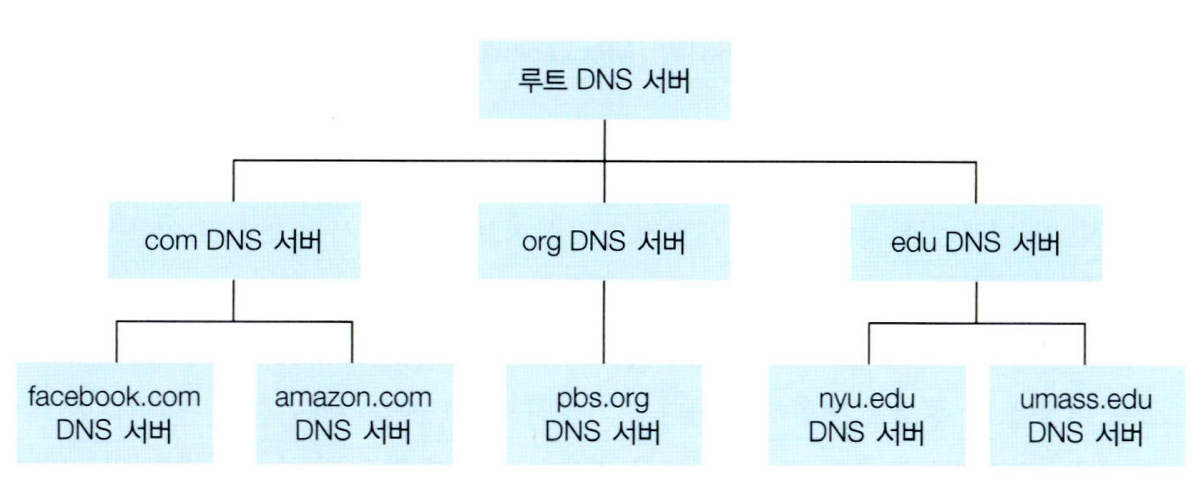
이 세 유형의 DNS서버가 어떻게 상호 작용 하는지 보기위해 어떤 DNS클라이언트가 www.amazon.com의 호스트 네임을 얻기 원한다고 가정합니다.
- 먼저 이 클라이언트는 루트 서버 중 하나에 접속합니다.
- 루트 서버는 최상위 레벨 도메인 com을 갖는 TLD 서버 IP 주소를 보냅니다.
- 그 다음 클라이언트는 이 TLD 서버 중 하나에 접속하고, 서버는 도메인 amazon.com을 가진 책임 서버의 IP 주소를 보냅니다.
- 클라이언트는 amazon.com의 책임 서버 중에서 하나로 접속합니다.
- 서버는 호스트 네임 www.amazon.com의 IP주소를 보냅니다.
로컬 DNS서버
그리고 추가적으로 로컬 DNS서버라는 것이 있습니다.
얘는 위와 같은 계층에 엄격하게 속하지는 않는데 DNS구조의 중심에 있습니다.
예시를 통해 보겠습니다.
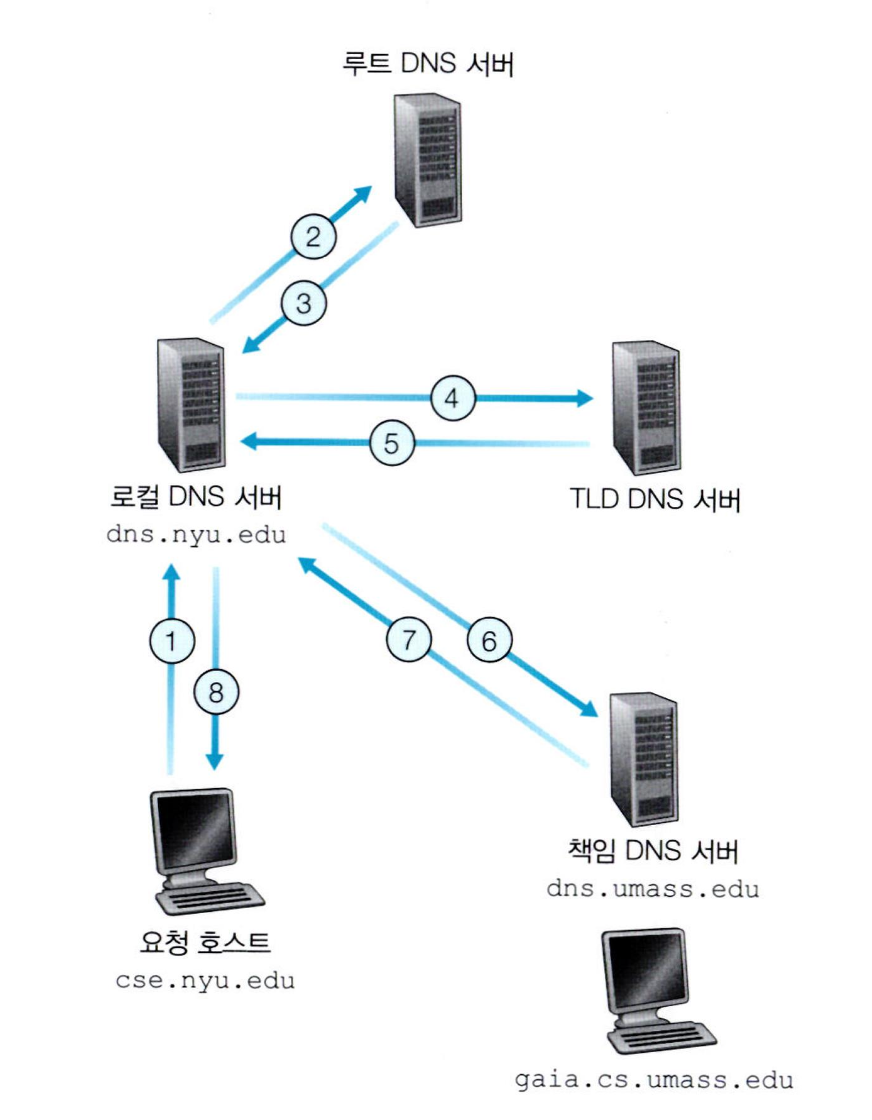
cse.nyu.edu라는 호스트가 gaia.cs.umass.edu의 IP주소를 얻기를 원한다고 가정합니다.
또 cse.nyu.edu의 NYU의로컬 DNS서버는 저기 왼쪽 가운데에 있는 dns.nyu.edu라고 가정합니다.
- 먼저 호스트 cse.nyu.edu가 자신의 로컬DNS서버로 DNS질의를 보냅니다.
변환을 해야하는 놈인 gaia.cs.umass.edu를 포함해서요- 로컬 DNS서버는 루트 DNS서버에 DNS질의 메시지를 보냅니다.
- 루트 서버는
edu를 인식하고edu에 대한 책임을 가진, 즉edu에 대해 알고있는TLD서버의 IP주소를 로컬DNS 서버로 보냅니다. TLD한테 물어보라고 TLD서버의 IP주소를 알려준거죠!- 그러면 이제 TLD 서버에 물어보고 TLD서버는
umass.edu를 인식하고 이것에 대해 알고있는dns.umass.edu즉 책임 DNS서버의 IP주소를 알려줍니다.- 그럼 이제 최종적으로 책임 DNS서버에게 물어보면 되겠죠?
{kind=link}
이렇게 계층적으로 이것에 대해 더 잘 아는 놈을 소개시켜줄게 방법을 통해 총 8번의 DNS질의가 오가게 됩니다.
DNS 캐싱
위의 예시에서는 뭘 더 아는 놈한테 가서 물어봐라 식으로 계속 DNS질의가 이루어졌죠?
로컬 DNS서버에서 호스트 이름과 IP주소쌍을 저장할 수 있고, TLD IP주소도 저장할 수 있습니다.
이게 왜 좋냐면 만약 저런 과정이 한 번 이루어지고 다음에 또 뭐시기.umass.edu라는 것의 IP주소를 알고싶어서 로컬 DNS서버에게 물어본다면 로컬 DNS서버는 저렇게 물어물어서 원하는 정보를 알아낼 필요가 없죠!
바로 TLD DNS서버로 가서 물어보면 되는 것이고
만약 똑같은 호스트 이름이면 더 이득이죠! 이미 저장해 둔 IP주소를 그냥 주면 되는거니까요!
로컬 DNS서버가 호스트 이름-IP주소 쌍을 저장해 두거나
TLD IP주소등을 저장해두면 질의를 저렇게 많이할 필요가 없어진다!
