
들어가기 앞서
통계
수량적 비교를 통해 다양한 사실을 관찰하는 방법
단순히 쌓여있는 raw data만으로는 의미있는 정보를 찾아내기 어렵다. 20세 남성/여성 평균 신장 데이터가 주어진다고 해도 180-남, 168-남, 171-여, ... 와 같이 나열된 숫자-문자열 뭉치일 뿐이다. 우리는 raw data로 부터 의미있는 정보(평균값, 중앙값 등)를 얻기 위해 통계적 방법론을 이용해야한다.
이를 위해 데이터를 field값에 따라 범주로 묶거나 정렬하여 한번의 query로 각 범주의 통계값을 비교하기 위해 쓰이는 'Group by'와 'Order by'에 대해 배운다.
1. SQL syntax - Group by & Order by
1-1. Group by
동일한 범주를 갖는 데이터를 하나로 묶어서, 범주별 통계를 내주는 기능이다. group by 뒤에 지정된 field 값이 같은 record끼리 하나의 그룹으로 묶고 각 그룹의 record 수(count), 어떤 field값의 평균(avg)/최대(max)/최소(min)등을 구할 수 있다.
Group by를 이용해 여러 통계값 알아보기
Ⅰ. 테이블 훑어보기
select문과 limit문을 통해 개략적인 형태를 살펴본다.
select * from checkins limit 10
Ⅱ. record 들을 원하는 field로 묶기
select * from [table] group by [범주로 쓸 field]실행 순서에 맞춰 어떤 범주로 묶을지 먼저 정하여 group by 부터 작성해두고 다음 단계를 진행하는 습관을 들이는 것이 좋다.

Ⅲ. 범주 내 record 개수: Count
각 범주별 총 record 갯수를 출력하기위한 query는 다음과 같다.
select [범주로 쓸 field],count(*) from [table]
group by [범주로 쓸 field][범주로 쓸 field] 부분은 필수는 아니나 출력의 가독성을 높이기 위한 용도이다.
예시:
입력
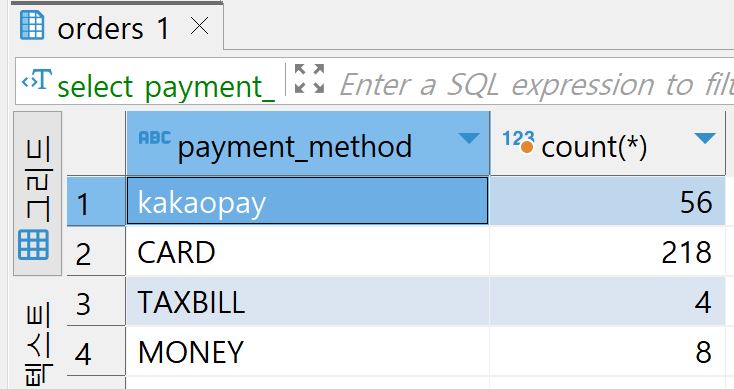
select week,count(*) from checkins group by week
출력
지불방식에 따라 record를 그룹으로 묶고, 각 그룹의 week값과 각 그룹의 record갯수를 출력했다.
Ⅳ. 범주 내 record의 특정 field 최소/최대/평균/합계
원하는 field로 범주별로 묶고, 다른 feild의 각 범주별 통곗값을 출력하기위한 query는 다음과 같다.
select [범주로 쓸 field], [min/max/avg/sum]([원하는 field]) from [table]
group by [범주로 쓸 field]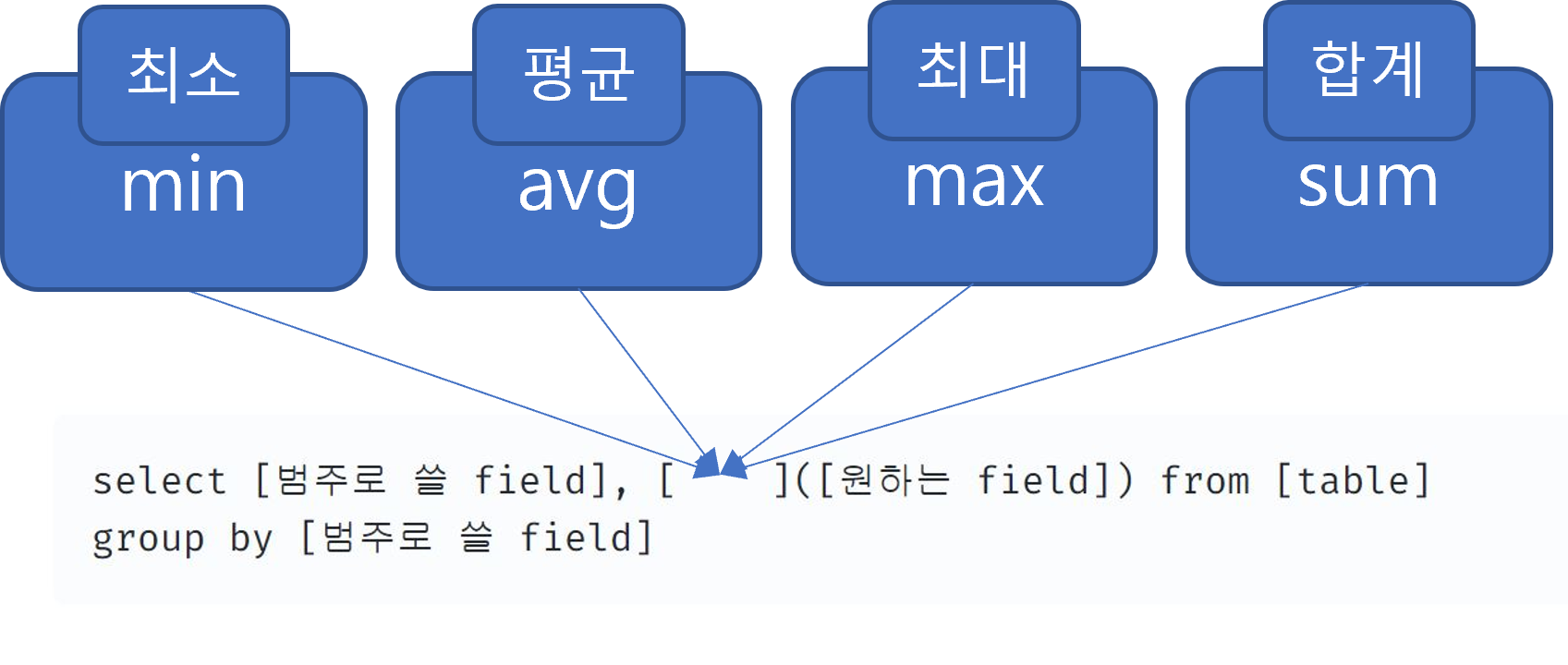
예시1: 최소-min
입력
select week,min(likes) from checkins group by week각 그룹별 likes의 최솟값을 출력한다.
출력

예시2: 최대-max
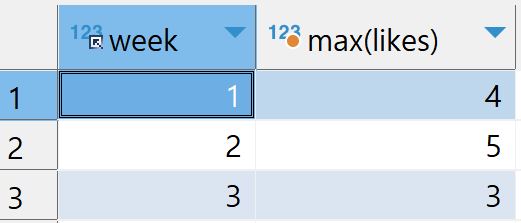
입력
select week,max(likes) from checkins group by week각 그룹별 likes의 최댓값을 출력한다
출력
예시3: 평균-avg
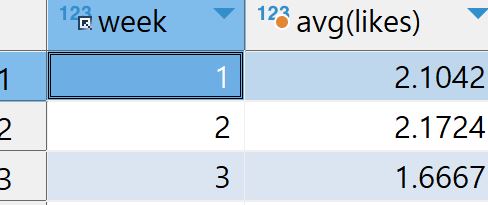
입력
select week,avg(likes) from checkins group by week각 그룹별 likes의 평균값을 출력한다.
출력
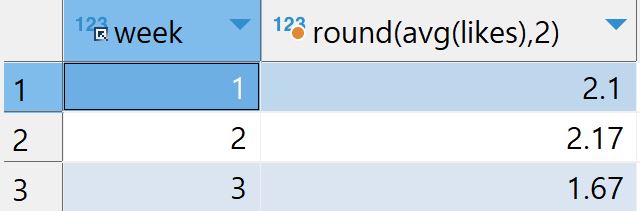
예시3-1: 소숫점 반올림-round
round함수를 사용하는 법은 다음과 같다.
round([반올림할 대상],n)n은 표시할 소숫점 아래 자릿수이다. 즉 n 자리에 1을 입력할 경우 최대 소숫점 아래 한자리 까지 표시되도록 반올림한다.
입력
select week,round(avg(likes),2) from checkins group by week각 그룹별 likes의 평균값을 그대로 출력하지 않고, round함수를 통해 소숫점 아래 2자리로 반올림하여 출력한다.
출력
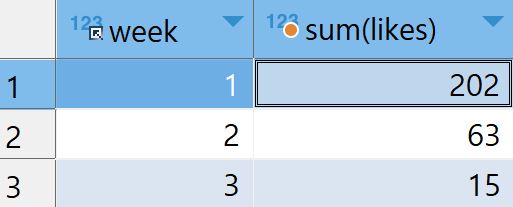
예시4: 총합-sum
입력
select week,sum(likes) from checkins group by week각 그룹별 likes의 총 합을 출력한다.
출력
예시5: '*'
입력
select * from checkins group by week이와같이 입력할 경우 각 범주당 하나의 record를 보여준다.
출력

1-2. Order by
order by는 모든 query에 적용될 수 있는 기능으로 뒤에 오는 field를 기준으로 하여 출력할 record들을 오름차순/내림차순으로 정렬한다.
현재 까지 배운 것 중 가장 마지막에 실행되는 구문으로, query문의 최하단에 작성한다.
select * from [table 명]
order by [정렬 기준이 될 field 명]내림차순의 경우 다음과 같이 하면 된다.
select * from [table 명]
order by [정렬 기준이 될 field 명] desc기본이 오름차순 정렬이므로 오름차순으로 정렬하고 싶다면 desc를 입력하지 않거나 asc로 바꿔 작성한다.
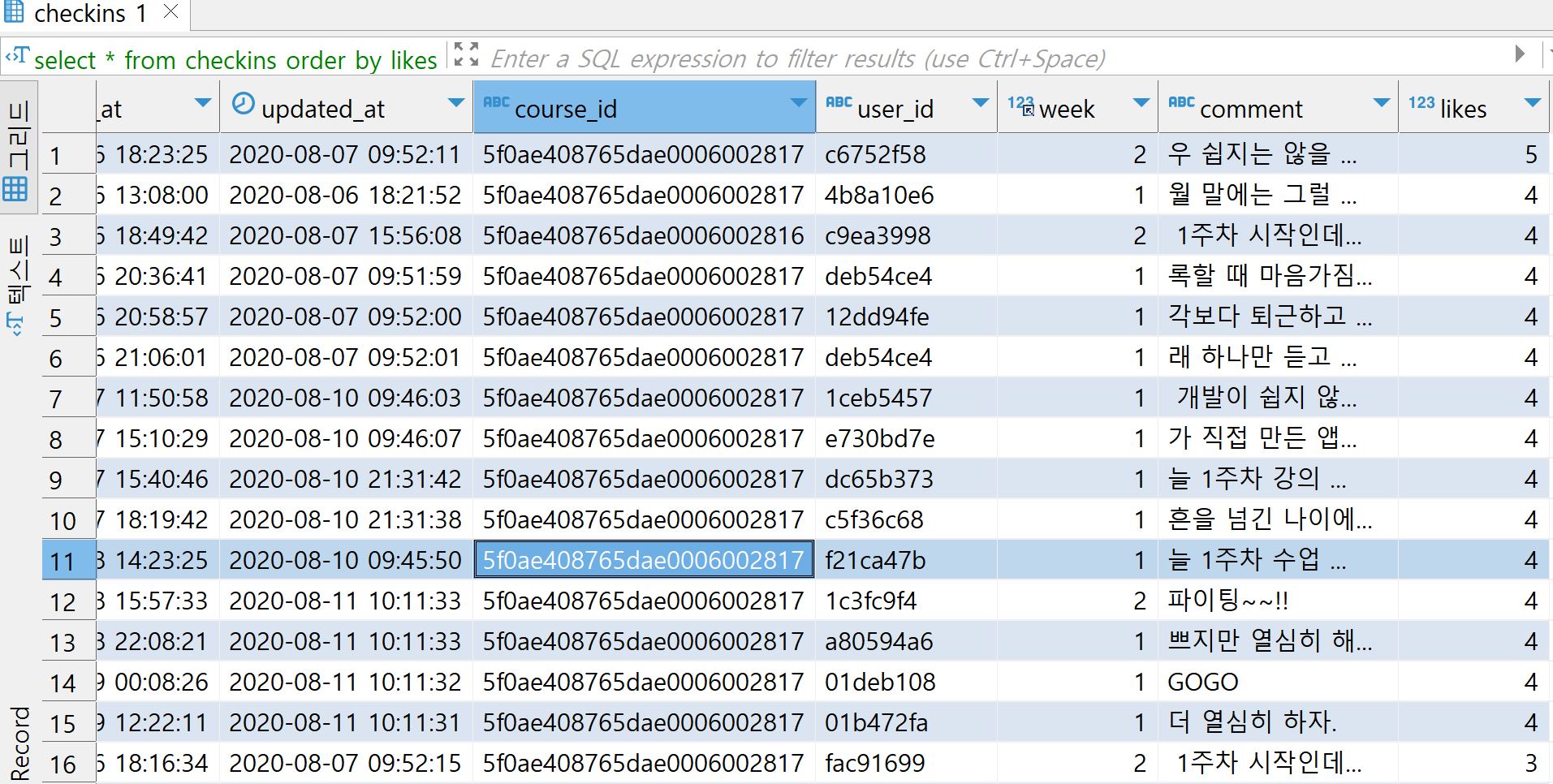
예시 1: 단독 사용
입력
select * from checkins order by likes desc전체 record를 likes 값 크기 내림차순으로 정렬해 출력한다.
출력
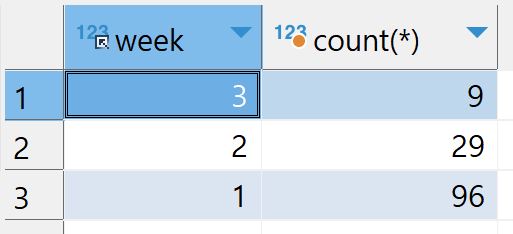
예시 2: group by와 함께 사용
입력
select week, count(*) from checkins group by week order by count(*)전체 record를 week 별로 묶은 뒤, 각 그룹의 총 record 갯수를 구하고 그 갯수에 따라 오름차순으로 정렬한다.
출력
1-3. Where와 Group by / Order by 동시 사용
group by와 order by 모두 where보다 하단에 존재하여야 한다. 실행은 where문에 의해 먼저 조건이 추가되고 그 이후 group by, 그 이후 order by가 실행된다.
예시
입력
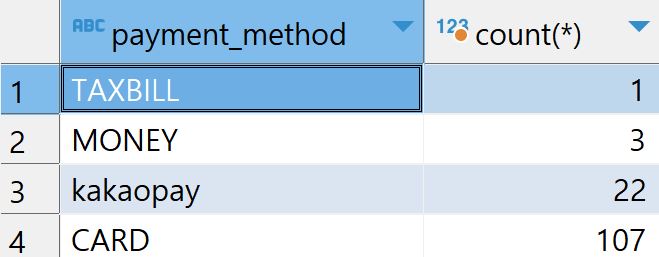
select payment_method, count(*) from orders where course_title = "웹개발 종합반" group by payment_method order by count(*)course_title이 웹개발 종합반인 record만 선택된다. 이후 payment_method로 정렬되고 count()가 계산된다. 이후 count()에 따라 오름차순으로 정렬한다.
출력
1-4. 실행 순서
query문의 각 부분이 어떠한 순서로 실행되는지 이해하면 작성에 도움이 될 것이다. 1. from [table 명]부분이 가장 먼저 실행되어 table의 전체 데이터를 불러온다.
2. 이후 where 문이 실행되어 조건에 따라 record 들이 선별된다.
3. 이후 group by가 실행되어 각 레이블이 범주로 묶인다.
5. 이후 select 문의 앞부분이 실행되어 출력할 field들이 결정된다.
6. 마지막으로 order by가 지정된 field로 결과물을 정렬한다.

번외 1. SQL syntax - Alias
별칭을 붙이는 기능이다.
쿼리를 작성하다보면 어떤 table의 field인지 헷갈리거나 출력 결과물의 field명이 지저분한 것이 마음에 안들 때 쓸 수 있다.
- table의 별칭: from [table 명] 뒤에 알파벳 1~2글자 정도로 붙인다. field가 어떤 table의 field인지 지칭할 때 다음과 같이 사용가능하다.
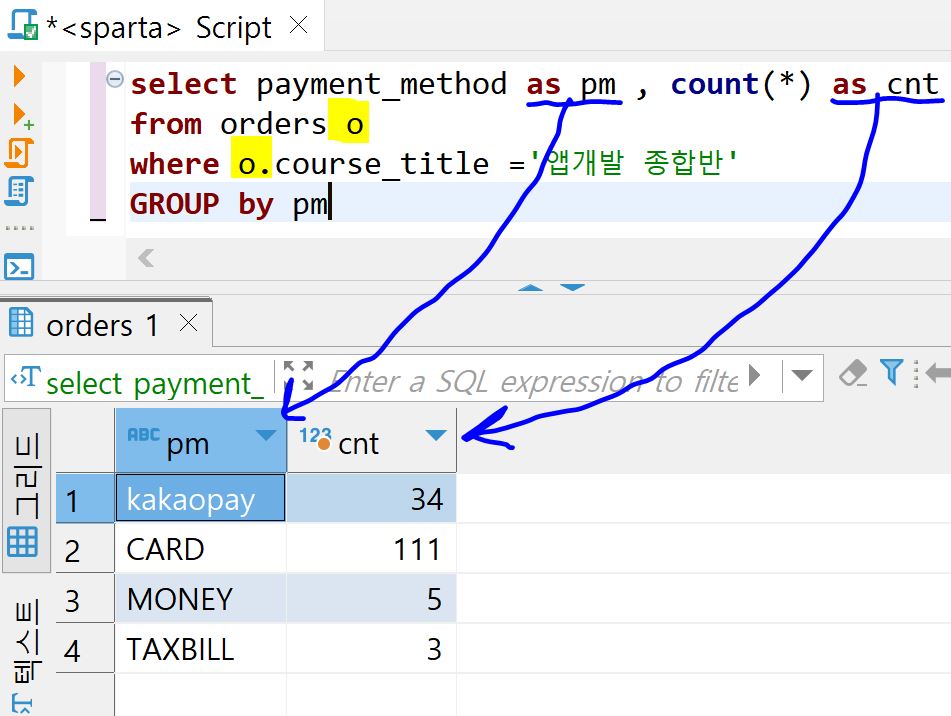
select payment_method as pm , count(*) as cnt
from orders o
where o.course_title ='앱개발 종합반'- 출력 field의 별칭: [field 명] as [별칭]
예시:
select payment_method as pm , count(*) as cnt
from orders o
where o.course_title ='앱개발 종합반'
GROUP by pm위와같이 입력시 출력:
번외 2. Query 작성 하기 절차
- show tables로 어떤 테이블이 있는지 확인
- select * from [원하는 정보가 있을 것 같은 테이블 명] limit 10
- 범주를 나눠서 보고싶은 필드를 찾기
- 범주별로 통계를 보고싶은 필드를 찾기
- SQL 쿼리 작성
