오늘 한 것
- Django 강의 수강
- 코딩테스트 풀이
- 진짜 개발자 되기위해 중요한 것에 대한 특강(정리)
문제 1. 평행(120875)

문제 이해
최초 이해: 이 문제는 4개의 점을 잇는 6개의 직선 중 평행한 것이 있는지 확인하고 있으면 1을 없으면 0을 반환하는 문제이다.
올바른 이해: 이 문제는 4개의 점중 2개씩 겹치지 않게 선택해 2개의 직선을 만들 수 있는 3가지 경우중 평행한 두 직선인 경우가 있으면 1을, 아니면 0을 반환한다.
시도 1. 최대 공약수 이용하기
직선의 기울기를 나눗셈을 통해 표현하면 부동소수점으로 인한 오차가 발생할 수 있기 때문에, 다른 방식으로 하고 싶었다.
이를 위해 x증분과 y증분을 최대공약수로 나누어 기울기를 표현하기로 하였다.
def gcd_(a,b):
if a<b:
a,b=b,a
if b==0:
return a
return gcd_(b,a%b)
def wrong_solution(dots):
lines={}
for i,dot1 in enumerate(dots):
for j,dot2 in enumerate(dots[i+1:]): # 6개의 선분 검사
line=(dot1[0]-dot2[0],dot1[1]-dot2[1])
gcd__=gcd_(abs(line[0]),abs(line[1])) # 절댓값의 최대공약수 찾아서
line=(line[0]//gcd__,line[1]//gcd__)
# 직선의 기울기를 벡터로 고유하게 표현한다
if line in lines:
return 1
else:
lines[line]=1
return 0시도 2. 직선의 양방향 고려하기
위 코드의 경우, 두 직선의 기울기가 다음과 같이 표현 되었을 때에는 평행함에도 평행하지 않은걸로 고려한다.
기울기 1: (1, 2)
기울기 2: (-1, -2)
def wrong_solution(dots):
lines={}
for i,dot1 in enumerate(dots):
for j,dot2 in enumerate(dots[i+1:]): # 6개의 선분 검사
line=(dot1[0]-dot2[0],dot1[1]-dot2[1])
gcd__=gcd_(abs(line[0]),abs(line[1])) # 절댓값의 최대공약수 찾아서
line=(line[0]//gcd__,line[1]//gcd__)
# 직선의 기울기를 벡터로 고유하게 표현한다
if line in lines:
return 1
else:
lines[line]=1
lines[(-1*line[0],-1*line[1])]=1 # 180도 반대방향도 고려하기
return 0이를 해결하기 위해 위와 같이 방향을 반전 시킨 경우도 체크 하기로 하였다.
시도 3. 문제 다시 이해하기
그럼에도 12번 테스트케이스 부터는 모두 틀린 것으로 나왔다. 이를 해결하기 위해 문제를 다시 읽어본 결과 문제를 잘못 이해하고 있었다.
이 문제는 4개의 점중 2개씩 겹치지 않게 선택해 2개의 직선을 만들 수 있는 3가지 경우중 평행한 두 직선인 경우가 있으면 1을, 아니면 0을 반환해야 한다.
따라서 for문을 위와 같이 하면 안되고 다음과 같이 해야한다.
for i,dot1 in enumerate(dots):
for j,dot2 in enumerate(dots[i+1:]):
line1=slope(dot1,dot2)
dots_=dots[::]
print(i,j)
dots_.remove(dot1)
dots_.remove(dot2)
print(dots_)
for k,dot3 in enumerate(dots_):
for dot4 in dots_[k+1:]:이렇게 하면 점의 갯수가 더 많을 때도 일반적으로 적용할 수 있다. remove 대신 접근 시간을 줄이기 위해 pop을 사용할 시 index에 영향을 주어 오류가 발생할 수 있다.
입력의 제한사항을 최대한 이용하면 다음과 같이 할 수 있다.
pairs=[(0,1,2,3),(0,2,1,3),(0,3,1,2)]
for a,b,c,d in pairs:
dot1=dots[a]
dot2=dots[b]
dot3=dots[c]
dot4=dots[d]
해결. 기울기 표현 및 비교 방식 바꾸기
바뀐 반복문 구조에 맞게 비교하는 방법을 바꾸어야 했다. 함수를 이용해 기울기의 벡터표현을 만드는 부분을 따로 뺐다. 또한 한번에 비교하기 좋게 하기 위해서 부호를 한방향으로 고정하였다.
def integer_slope(dot1, dot2):
line1 = (dot1[0]-dot2[0], dot1[1]-dot2[1])
gcd__ = gcd_(abs(line1[0]), abs(line1[1]))
if line1[0]:
sign_ = line1[0]//abs(line1[0])
else:
sign_ = line1[1]//abs(line1[1])
return (sign_*line1[0]//gcd__, sign_*line1[1]//gcd__)최종적으로 다음과 같은 코드로 통과하였다.
def solution(dots):
for i,dot1 in enumerate(dots):
for j,dot2 in enumerate(dots[i+1:]):
line1=slope(dot1,dot2)
dots_=dots[::]
dots_.remove(dot1)
dots_.remove(dot2)
for k,dot3 in enumerate(dots_):
for dot4 in dots_[k+1:]:
print(dot1,dot2,dot3,dot4)
if integer_slope(dot1,dot2) == integer_slope(dot3,dot4):
return 1
return 0혹은 다음과 같이 작성할 수 있다.
def solution(dots):
pairs=[(0,1,2,3),(0,2,1,3),(0,3,1,2)]
for a,b,c,d in pairs:
line1=integer_slope(dots[a],dots[b])
line2=integer_slope(dots[c],dots[d])
if line1==line2:
return 1
return 0위와 같이 두 직선을 만든 뒤 비교하는 방식으로 바뀔 경우, 최대공약수를 이용하지 않고 곱셉을 이용해 할 수 있다.
def solution(dots):
pairs=[(0,1,2,3),(0,2,1,3),(0,3,1,2)]
for a,b,c,d in pairs:
dots[a][0]=x1
dots[b][0]=x2
dots[c][0]=x3
dots[d][0]=x4
dots[a][1]=y1
dots[b][1]=y2
dots[c][1]=y3
dots[d][1]=y4
if (x1-x2)*(y3-y4)==(x3-x4)*(y1-y2):
return 1
return 0문제 2. return, print에서의 and/or사용
다음과 같은 코드를 발견하였다.
def solution(arr, divisor): return sorted([n for n in arr if n%divisor == 0]) or [-1]return에서 or를 사용하는 것을 어떻게 이해해야하는지 알아보기 위해 직접 코드로 테스트 해보고 구글링하여 찾아보았다.
결론:
return, print에서 and를 쓰면 다음과 같이 반환/출력한다.
참1 and 참2: 참2 출력
거짓1 and 참2: 거짓1 출력
참1 and 거짓2: 거짓2 출력
거짓1 and 거짓2: 거짓1 출력
or를 쓰면 다음과 같이 반환/출력한다.
참1 or 참2: 참1 출력
거짓1 or 참2: 참2 출력
참1 or 거짓2: 참1 출력
거짓1 or 거짓2: 거짓2 출력
이러한 특성 때문에 반환후 다른 함수에서 쓸때는 논리연산의 결과로서 True/Flase를 반환하는 것으로 보일 수 있다.
문제 3. 3진수 뒤집기(68935): int()의 진수(base) 사용
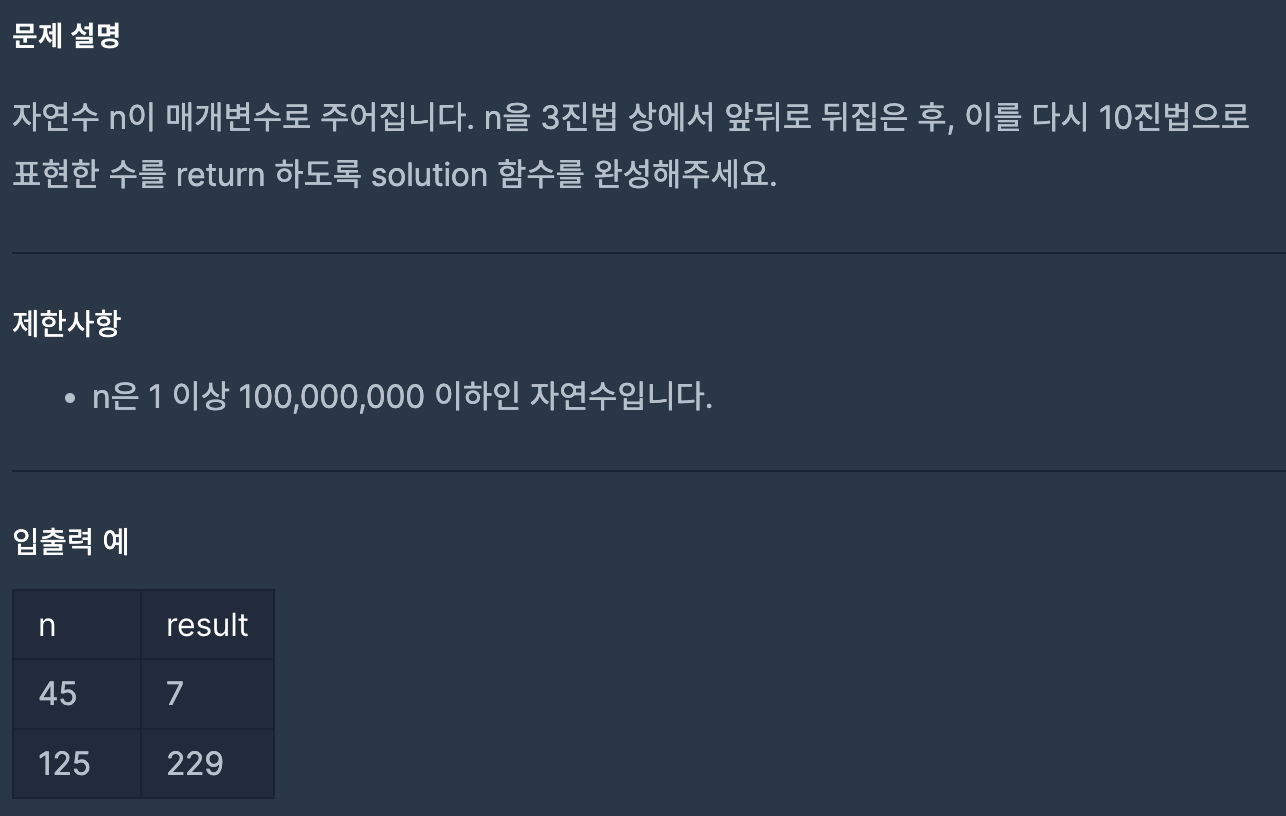
문제 이해
이 문제는 주어진 10진수를 3으로 나눈 나머지를 구하고 계속 3을 나누는 방식으로 3진수로 변환하고, 이 값들을 실제 자리와 반대의 순서로 처리해 새 10진수를 계산해내는 문제이다.
시도 & 해결. stack 이용
def solution(n):
n_=n
three=[]# 입력값을 3진법으로 표현할때 각 자리(3^i)의 계수 저장할 stack
while n_:
three.append(n_%3) # push
n_=n_//3
# 역순으로 꺼내 10진수로 변환
digit=1
num=0
while three:
num +=digit*three.pop(-1) # pop
digit*=3
return numstack을 이용해 큰 자릿수가 가장 마지막에 추가되도록 하고 ,꺼낼때는 큰 자릿수부터 나오게 해 뒤집은 3진수의 10진수 변환을 만들었다.
더 좋은 코드: int의 base 사용
int()는 숫자로 이루어진 문자열을 지정된 base(진수)의 숫자로 받아들여 10진수로 바꾸어 주는 역할을 할 수 있다.
다음과 같이 사용한다.
num=int('222',3) # 26
num=int('223',10) # 223이를 이용하여 비슷한 코드를 더 짧게 쓸 수 있다.
def solution(n):
n_=n
three=''# 입력값을 3진법으로 표현할때 각 자리(3^i)의 계수 저장할 stack
while n_:
three+=str(n%3) # 실제 자릿수와 반대로 저장됨==뒤집어짐
n_=n_//3
return int(three,3)
문제 4. 과일장수(135808)

문제 이해
최초 이해: 이 문제는 탐욕법을 통해 접근할 수 있다. 아직 박스에 들어가지 않은 사과중 최대한 점수가 높은 사과들 끼리 박스에 모아서 파는게 가장 이득이다.
시도 1. 정렬 후 반복문
#O(nlogn + n)
def solution(k, m, score):
score.sort(reverse=True)
answer=0
while len(score)>=m:
answer += m * socre[m-1]
score=score[m:]
return answer내림차순으로 정렬한 뒤, 가장 점수가 높은 과일부터 m개 씩 묶는 과정을 그대로 구현하였다.
그러나 이 방식은 퀵 정렬후 다시 순회를 해야하므로 O(nlogn + n)의 시간복잡도를 가지며, list를 계속 슬라이싱하여 저장하므로 시간초과로 오답이 되었다.
시도 2. index 이용하기
def solution(k, m, score):
score_=sorted(score,reverse=True)
answer=0
i=0
while len(score_)>m*(i+1)-1:
answer += m * score_[m*(i+1)-1]
i+=1
return answerlist를 계속 슬라이싱해서 index를 고정적으로 가져가는 대신, 정렬되어 있으니 가장 작은 점수의 과일이 박스의 가장 마지막에 옴을 고려하여 코드를 작성하면 위와같이 index를 통해 조회하는 방식으로 바꿀 수 있다.
이렇게 하면 문제는 풀리지만, 여전히 입력값 k는 사용되지 않았다.
해결
k값의 입력 제한을 보면, score의 길이와 달리 그 범위가 매우 작다. 이를 이용해 각 점수의 빈도값을 계산하면 O(n)안에 정렬을 한 것과 같은 효과를 볼 수 있다.
#리스트 쓰기
def solution(k, m, score):
count=[0]*(k+1)
for s in score: # 빈도 집계
count[s] +=1
answer=0
for i in range(k,0,-1): # k점 부터 1점 까지만(0점은 실제론 없으므로)
answer += (count[i]//m)*i*m
# (현재 점수를 가진 과일만 써서 만들 수 있는 박스 갯수)*현재점수*m
count[i-1] +=count[i]%m
# 박스에 못들어가고 남은건 1점 낮은 과일로 취급. 1점짜리 남으면 0점 처리(박스에 안들어갈만큼 남은건 버림)
return answer
#딕셔너리 쓰기
def solution(k, m, score):
count={}
for i in range(k+1):
count[i]=0
for s in score: # 빈도 집계
count[s] +=1
answer=0
for i in range(k,0,-1): # 높은 점수부터 1점 까지만(0점은 실제론 없으므로)
answer += (count[i]//m)*i*m
# (현재 점수를 가진 과일만 써서 만들 수 있는 박스 갯수)*현재점수*m
count[i-1] +=count[i]%m
# 박스에 못들어가고 남은건 1점 낮은 과일로 취급. 1점짜리 남으면 0점 처리(박스에 안들어갈만큼 남은건 버림)
return answer실제로 정렬된 리스트를 만들어(distribution count sorting) 인덱스로 조회하는 것도 좋지만, 다른 방식을 이용해본다.
점수별로 과일 갯수를 세고, 가장 높은 점수(k)부터 만들 수 있는 박스 수만큼 점수를 가산하고, 남은 과일은 1점 낮은 과일과 동급으로 친다.(어차피 같은 박스에서 가장 낮은 과일의 점수로 쳐지므로)이것을 k 번 반복하여 결과를 계산한다.
이렇게 하면 시간복잡도를 가장 아낄 수 있다.(O(n+k))
문제 5. 문자열 내맘대로 정렬(12915)

문제 이해
다음과 같은 규칙을 따르는 정렬 알고리즘을 만든다:
- n번째 문자가 알파벳 순으로 빠른 것이 앞으로 온다.
- n번째 문자가 같다면, 전체 문자열의 사전순 으로 앞선 문자열이 앞으로 온다.
시도 1. 직접 정렬알고리즘 구현
입력 크기가 그렇게 크지 않고, 비교해야할 key가 2개이상이므로 직접 간단한 정렬 알고리즘을 구현해 사용하기로 했다.
# 앞섬/뒷섬 비교 함수
def compare(str1,str2,n):
if str1[n] < str2[n]:
return True
if str1[n] > str2[n]:
return False
if str1 > str2:
return False
return True
#선택정렬
def solution(strings, n):
answer=[]
strings_=strings[:]#deep copy
for h,_ in enumerate(strings_):
min_='~'*(n+1) # 알파벳 보다 무조건 뒤로오는 문자열
min_index= -1
for i,string in enumerate(strings_[h:],h):
if not compare(min_,string,n):
min_=string # 최솟값 갱신
min_index=i # 최솟값의 위치 갱신
strings_[min_index],strings_[h]=strings_[h],strings_[min_index]#정렬되지 않은 부분의 가장 앞쪽과 swap
return strings_위와 같이 비교함수를 만들고 이를 이용해 선택 정렬을 구현하였다.
해결 1. python sort()의 특성
정답을 맞춘 뒤 다른 정답코드를 보니 이런 식으로 작성된 것이 있었다.
def solution(strings, n):
strings_=sorted(sorted(strings),key=lambda x:x[n])
return strings_이는 sort를 전제 문자열 기준으로 먼저 돌린 뒤, n번째 문자열 기준으로 다시돌린 것이다. 이것이 성립하기 위해선 새로 정렬한다고 해서 이전의 정렬 했던 것들이 뒤죽박죽이 되지 않아야한다.
이러한 특성을 stable 하다 라고 하는데, 파이썬이 제공하는 정렬 함수는 병합정렬과 삽입정렬을 이용해 만든 tim sort로, stable한 방식이다.
해결 2. key=(,)
sort(), sorted()함수의 인자를 정할 때, key를 list나 튜플로 지정하여 우선순위가 낮은 key를 추가할 수 있다.
def solution(strings, n):
return sorted(strings, key=lambda str: (str[n], str))해결 3. str 특성 이용해 key 변경
str 끼리 비교할 때는 기본적으로 사전순으로 비교한다. 따라서 가장 먼저 비교할 n번째 문자 뒤에 전체 문자열을 갖다 붙인 새로운 문자열을 만들어 key로 설정하면 바로 원하는 대로 정렬이 가능하다.
def solution(strings, n):
return sorted(strings, key=lambda str_: str_[n]+str[:])배운점
- int()는 base지정 가능하다. n진법 문자열->10진법
- 수학을 이용해 표현을 간단하게 바꿀 수 있다.
- return, print에서의 or, and 사용법을 알았다.
- 입력 크기에 비해 값의 범위가 매우 작을 때는 distribution count sorting이 매우 효과적이다. (O(n))
- python sort, sorted는 팀 정렬을 이용한 stable한 정렬이다.
- key값은 단순히 item의 일부가 아니라 어떤 연산의 결과 일 수 있다.
