오늘 한 것
- 스파르타 코딩클럽 알고리즘/자료구조 1강 내용+전공강의 내용 정리(링크)
- 프로그래머스 - 뒤에 있는 큰 수 문제(154539) 풀이
- 개인 과제 (설명) 팀원들 코드 리뷰
- 개인과제 피드백 정리
프로그래머스 - 뒤에 있는 큰 수
시도 1. 이중 for문을 이용한 exhaustive search.
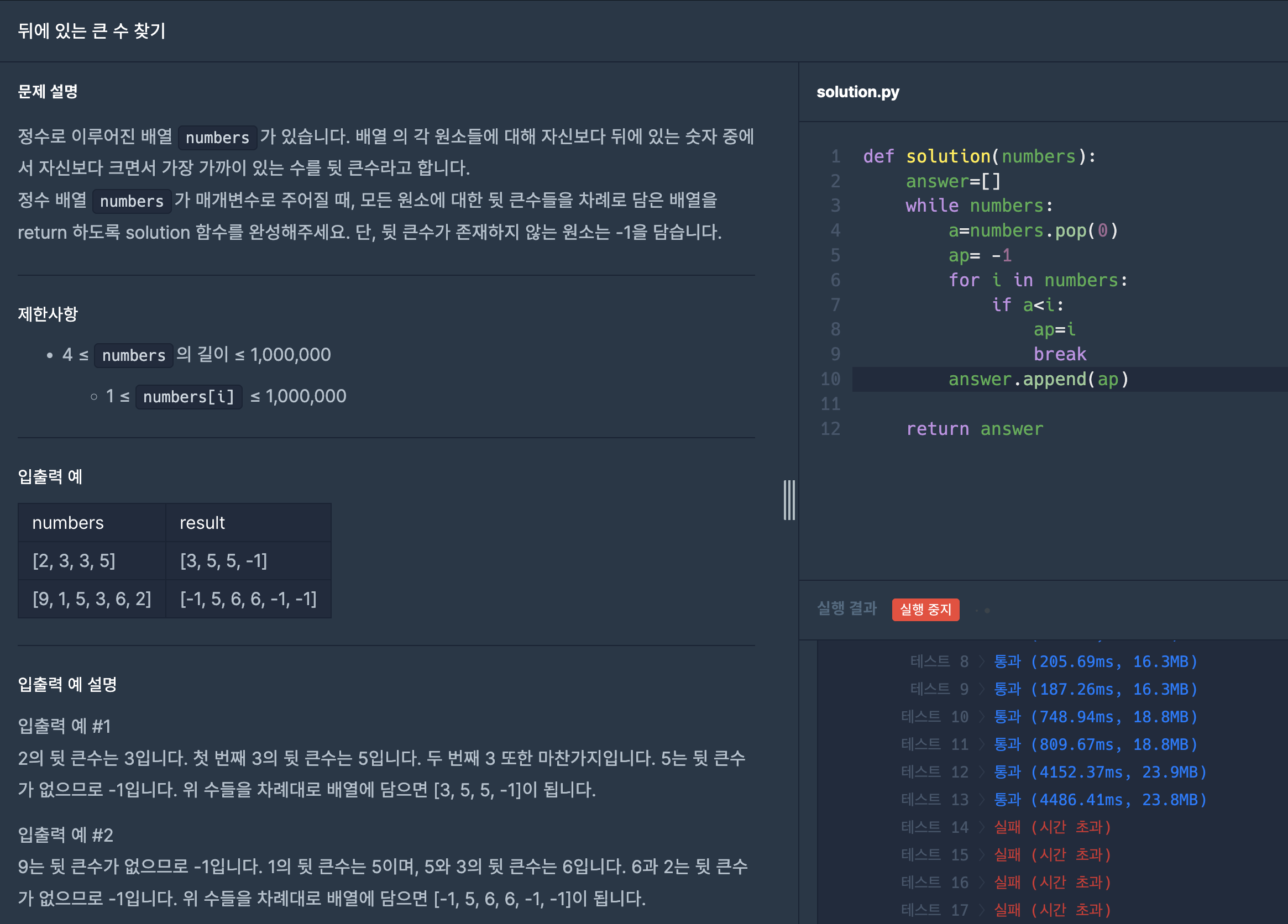
def solution(answer):
answer=[]
while numbers:
poped=numbers.pop(0)
close= -1
for i in numbers:
if a<i:
close=i
break
answer.append(close)
return answerlist의 요소를 앞에서 부터 pop해 남은 요소(뒤에 있는 요소)들과 순차적으로 비교해 가장 먼저 나온 뒤에 있는 큰 수를 정답 리스트에 append하였다.
그러나 이는 O(n^2)의 시간복잡도를 가지고 있어 입력 리스트의 길이가 길면 시간초과로 인해 오답처리되었다.
시도 2. 거꾸로 조회하기
앞에서 부터 조회하는 것을 매 요소마다 반복하는 것은 2중 반복문으로 인해 시간복잡도가 커진다. 따라서 이번에는 뒤에서부터 조회하기로 하였다.
def solution(numbers):
# 가장 뒤는 제외 (어차피 -1)
old=numbers[-1]
answer=[-1]
# 뒤에서 두번째 부터 처음 까지
for number in numbers[-2::-1]:
# 이전값이 현재 값보다 크면 이전값을 정답에 붙임
if old > number:
answer.append(old)
# 아니면 이전값을 현재값으로 갱신하고 -1 붙임
else:
old=number
answer.append(-1)
return answer[::-1] # 역순으로 조회하였으므로 뒤집어서 출력그러나 이 코드는 이전에 조회한 값중 가장 큰 값만을 기억하는 코드가 되었으므로 정답에 부합하지 않았다.
해결1: stack이용하기
문제를 해결하기 위해서는 거꾸로 조회하면서 이전에 조회했던 값들을 최근 것 부터 순차적으로 꺼내보다가 자신보다 큰 것 중 가장 최근에 조회한 값을 얻어야 한다.
이는 정확히 stack의 저장/꺼내기 순서와 일치한다.
따라서 다음과 같은 코드를 작성할 수 있다.
def solution(numbers):
# 가장 뒤 제외 (어차피 -1)
answer=[-1]
last=numbers[-1]
# 스택으로 쓸 리스트 선언
stack=[last]
# 뒤에서 두번째 부터 처음 까지
for i in numbers[-2::-1]:
# 스택이 비거나 현재 조회중인 값보다 큰 값 발견할때까지 stack 에서 꺼내온다
while stack and stack[-1]<=i:
stack.pop(-1)
# stack에 무언가 남았다면 가장 마지막에 추가된 것이 가장 가까운 뒤에 있는 큰수
if stack:
answer.append(stack[-1])
# 아니라면 뒤에 있는 큰수가 없다는 것이다.
else:
answer.append(-1)
# 조회한 값을 stack에 넣는다
stack.append(i)
return answer[::-1] # 역순으로 조회하였으므로 뒤집어서 출력그 결과, 다음과 같이 통과할 수 있었다.
해결 2. stack에 넣을 값 거르기
그러나 위의 코드는 다음과 같은 경우 쓸데 없이 넣었다 뺏다만 많이 한다.
solution([2, 2, 2, 6, 6, 6, 6, 6, 6, 6, 6, 6, 8]) # case1
solution([2, 1, 3, 2, 4, 3, 5, 2, 9]) # case2case1, case2 모두 이후(index상 앞쪽)요소의 결과에 영향을 주지 않는 요소들(case1: 2, 6 | case2: index 1,3,5,7)을 stack에 넣고 빼므로 시간낭비가 존재한다.
이를 해소 하기 위해 몇가지 로직을 추가하였다.
def solution2(numbers):
answer=[-1]
old=numbers[-1]
stack=[]
for i in numbers[-2::-1]:
if old>i:
answer.append(old)
stack.append(old)
else:
while stack and stack[-1]<=i:
stack.pop(-1)
if stack:
answer.append(stack[-1])
else:
answer.append(-1)
old=i
return answer[::-1]old는 조회하고 있는 값 이전(인덱스 상 뒤)값을 말한다. 현재 조회중인 값과 비교하여 이전값이 크면 stack에 추가한다. 이렇게 되면 stack에는 '현재까지 자신 이후에 자신보다 크거나 같은 값이 나오지 않은 값만' 추가된다.
이렇게 하자 입력값이 큰 테스트 중 대다수가 이전보다 속도가 빨랐다.
개인과제 피드백 내용 정리
오늘은 개인과제의 제출 마감일이었다. 제출 이후 이창호 튜터님이 정답 코드를 공개하고, 일부 인원들의 코드를 직접 보며 개선사항등의 피드백을 제공하였다. 이곳에는 피드백들의 내용중 내가 수용해야할 것들을 위주로 정리하였다.
1. 딕셔너리의 활용
| method | description |
|---|---|
| dict.keys() | return list of keys |
| dict.values() | return list of Values |
| dict.items() | return list of key-value pairs |
기존 if문을 사용했던 코드를 딕셔너리를 활용해 간편한 동시에 휴먼에러를 방지하는 코드로 개선할 수 있다.
while True:
choice=input("choose: [A]rcher, [B]arbarian, [C]leric : ")
if choice not in ('A','B','C'):
countinue
if choice =='A':
player_entity=Archer(...)
elif choice =='B':
player_entity=Babarian(...)
else:
player_entity=Cleric(...)이렇게 조건문을 통해 분기하는 코드는 쓸데없이 길고 보기힘들고 추후 수정하기 번거롭다.
class_dict={'A':Archer(...),'B':Babarian(...),'C':Cleric(...)}
while True:
print("choose: [A]rcher, [B]arbarian, [C]leric")
choice=input("your choice: ")
if choice in class_dict.keys():
player_entity=class_dict[choice]
break
print('invalid input. re enter.')이렇게 객체를 딕셔너리에 직접 지정하여 조건문 분기를 쓰지 않고 선택지를 만들 수 있다.
클래스의 추가로 인한 코드의 수정이 필요한 경우에도 쉽게 자동으로 반영되게 할 수 있다.
class_dict={'A':Archer(...),'B':Babarian(...),'C':Cleric(...)}
while True:
print("choose: ",end='')
for i in class_dict.keys():
print(f"[{i}]{class_dict[i].class_name} ")
# choose: [A]Archer [B]Barbarian [C]Cleric
choice=input("your choice: ")
if choice in class_dict.keys():
player_entity=class_dict[choice]
break
print('invalid input. re enter.')2. 하나의 함수엔 하나의 기능만
2-1. if문 대신 각각의 함수(메서드)를 만들자: 하나의 메서드가 입력값에 따라 여러 기능을 하게 만들기 보다는, 메서드 자체를 나누어 하나의 함수가 오직 하나의 기능을 하게 만들면 깔끔하게 코드를 작성하는데 도움이 된다.
2-2. 함수 실행을 위한 검증(validation)은 분리: 함수가 호출 되면 오직 본연의 기능만 수행하면 되도록 만들어 줘야 구조가 깔끔해지고 디버깅이 용이해진다.
3. VScode 단축키 기능:
변수 선택 후 F2: 해당 변수와 같은 변수가 쓰인부분을 모두 선택하여 수정할 수 있다.
변수 선택 후 ctrl(command)+F2: 선택한 부분과 같은 문자열을 코드 전체에서 모두 선택하여 수정할 수 있다.
둘을 사용방법에 따라 구분하여 쓰면 편리하게 이용할 수 있다.
오늘 배운점
- 문제해결에 필요한 자료구조를 적절히 선택하여 문제를 쉽게 해결 할 수 있다는 것을 실제 사례를 통해 느꼈다.
- 딕셔너리는 매우 강력한 자료구조이다. 이러한 자료구조를 적재 적소에 활용할 줄 알아야한다.
- 함수(메서드)는 하나의 기능만 담당하도록 설계하는 것이 좋다.
