23.03.27~31 WIL
이번주 한 것
- 알고리즘 강의 1주차 완료
- 파이선 개인, 팀과제 진행 및 피드백 세션 참여
- 코딩테스트 기초 문제
- 알고리즘 특강 세션 수강
1. 알고리즘과 자료구조
알고리즘이란 문제 해결을 위한 명확한 명령문의 연속을 통칭하는 말이다. 구체적으로, 알고리즘은 유효한 입력으로부터 유한한 시간 내에 요구되는 출력을 만들어 내야 한다.
문법에 맞는 코드보다 중요한 것은 성능/용량/비용 면에서 좋은 코드이며, 알고리즘과 자료구조에 대한 이해가 있어야 이것이 가능하다.
알고리즘의 요구사항
- 유한성(Finiteness)
- 명확성(Definiteness): 알고리즘을 구성하는 단계별 동작들은 반드시 명확하다.
- 명확하게 특정된 입력: 알고리즘이 동작하기 위한 입력값의 범위는 신중하게 정해진다.
- 명확하게 특정된 출력
- 효율성(Effectiveness)
이러한 조건을 만족하는 알고리즘은 같은 알고리즘이라도 여러 형식으로 표현될 수 있고, 같은 문제를 풀기위한 여러가지 알고리즘이 존재할 수 있고, 서로 다른 아이디어에 기반할 수 있다. 서로 다른 알고리즘들은 속도가 크게 다를 수 있다.
알고리즘을 이용한 문제풀이의 순서
- 문제를 이해한다.
- 어떤 방식으로 문제를 풀지 결정한다: 연산 방식, 정확한 해(exact solving) 찾기 vs 근사해 찾기(approximate solving), 알고리즘 설계 기술 선택...
- 알고리즘, 자료구조 설계
- 알고리즘의 정확성 확인/증명 -> 실패시 2,3으로 회귀
- 알고리즘 분석 -> 부적절 할시 -> 2,3 으로 회귀
- 알고리즘을 실제로 코딩한다.
몇가지 중요한 알고리즘 문제들
- 정렬(sorting): 다른 종류의 문제해결에 필요한 경우가 많다. 정렬기준이 되는 값(key)의 비교횟수를 복잡도를 비교하는 기준으로 삼는다.
- 탐색(searching): 정렬을 전제로 한다. 원하는 값을 찾는다. 순차적 탐색, 이진탐색등이 있다.
- 문자열 처리(string processing): 일치하는 패턴, sub-string 찾기 등의 문제가 있다.
- 그래프(graph problem): 순회(traversal: 모든 노드 방문), 최단경로, 위상정렬 등의 문제
- 조합(combinatorial problem): 나열, 조합, 부분집합등을 찾는 문제. (ex:행상인 문제). 이론적으로도 실제 구현에 있어서도 매우 어렵다.
- 기하 문제(geometric): 가장 가까운 한 쌍 찾기, 볼록껍질 찾기 등
- 수치적 문제(numerical): 실수를 다뤄야하므로 근사치를 찾는 해법이 주가 되는 영역. 잘못하면 round-off error가 발생하여 출력이 왜곡될 수 있다.(예: 0.1+0.2 != 0.3)
시간 복잡도
시간복잡도는 알고리즘이 입력값의 크기에 따른 동작 시간이 얼마나 걸리는지 나타낸다.
실행 시간의 측정방법

실행시간을 실제 시간으로 측정하면 실행환경마다 다를 수 있으므로 적절하지 못하다. 따라서 입력값에 따른 basic operation이 실행된 횟수로 시간복잡도를 표현해 실행시간을 표현한다.
basic operation은 알고리즘의 가장 안쪽 loop에서 가장 시간이 많이 소모되는 연산으로 선정된다. 예를들어 정렬 알고리즘에선 키 비교, 수학적 문제에서는 사칙연산등이 해당된다.
입력 상태에 의한 시간복잡도 변화
예를 들어 요소가 n개인 list에서 어떤 값을 찾기 위해 순차적으로 조회할 때
worst case: 찾는 값이 가장 뒤에 있다면, Cworst(n)=n이다.
best case: 찾는 값이 가장 앞에 있다면, Cbest(n)=1이다.
average case: 찾는 값이 평범하게 중간 어딘가에 임의로 위치하고 있는 경우를 말한다. 위 두 케이스에 비해 정확히 측정하기 어렵다.
Order of growth, 점근표기법
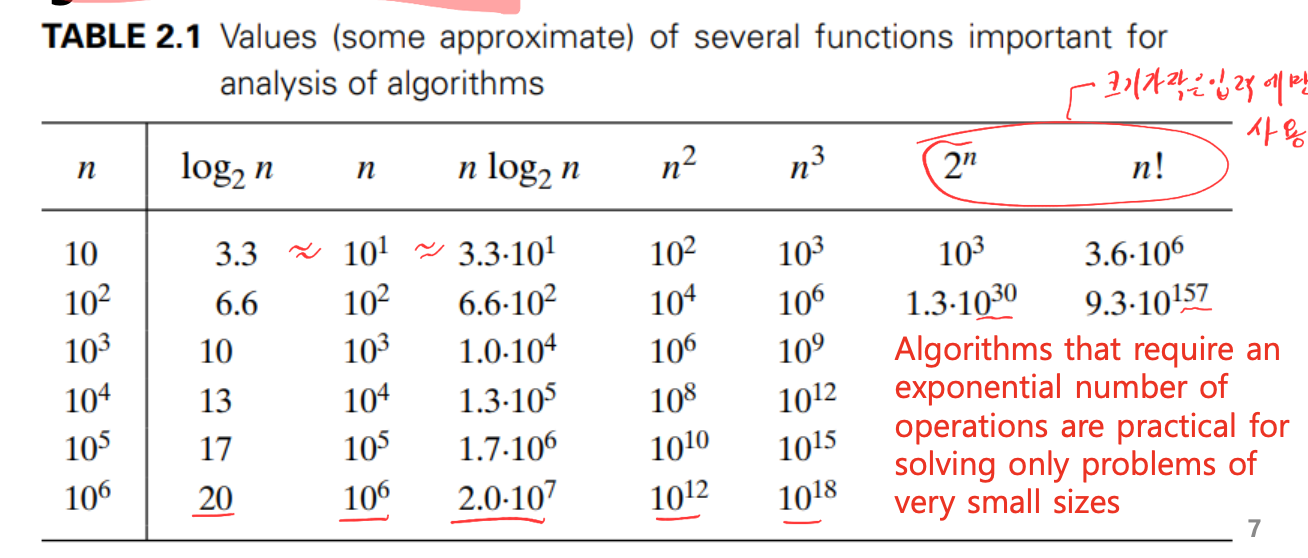
시간복잡도를 비교할때에는 차수가 중요하며 상수, 계수는 무시된다. 이러한 접근을 점근 표기법이라고 한다.
세가지 표기법이 존재한다.
1. big-O: 𝚶(g(n)): worst case
2.big-Omega: 𝛀(g(n)): best case
3. 𝚯(g(n)): average case
시간복잡도의 비교와 계산(비 재귀/재귀)
비교
극한(lim)을 이용한다.
계산-비 재귀
- 입력 크기를 나타내는 지표를 정한다.
- 알고리즘의 basic operation을 정한다.
- 입력크기가 n일 때 worst, best, average case에 해당하는 입력상태를 정한다.
- basic operation의 실행횟수를 나타내는 합산식(∑)을 작성한다.
- 합산식을 간단하게 n을 매개변수로 가지는 함수형태로 표현한다.
계산-재귀
점화식을 이용하여 계산한다.
1. Inital condition(재귀가 멈추는 조건에 해당하는 지점)에서 basic operation이 몇번 실행되는지 확인한다. M(0)=x
2. 재귀 호출 전후로 몇번의 basic operation이 발생하는지, 몇번의 재귀호출을 하는지 확인한다. M(k+1)=i*M(k)+y
3. 후진 대입법(backward-substitution)을 이용해 간단하게 n을 매개변수로 가지는 함수형태로 표현한다.
자료구조와 알고리즘
자료구조는 데이터를 효율적으로 관리하는 방법론을 의미한다. 데이터는 변수, 상수, 파일 등 모든 자료를 의미한다.
자료구조: 연결리스트
연결리스트는 자신의 값과 다음 노드의 포인터로 이루어진 노드들로 이루어진다.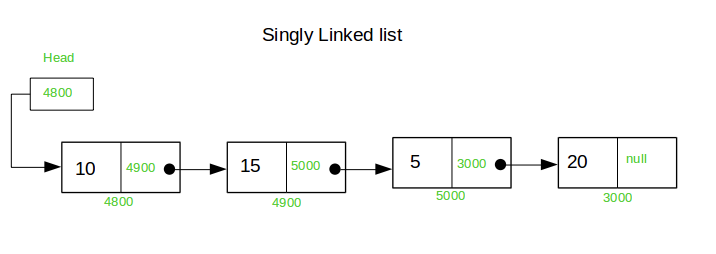
이 자료구조는 배열(실제 메모리상에 연속된 공간에 요소들을 저장, 인덱스를 통한 랜덤 엑세스 가능)에 비해 조회 할때의 시간복잡도가 O(n)으로 느린편이나, 배열과 다르게 중간 요소의 삭제, 삽입시 속도가 빠르다(O(1)).
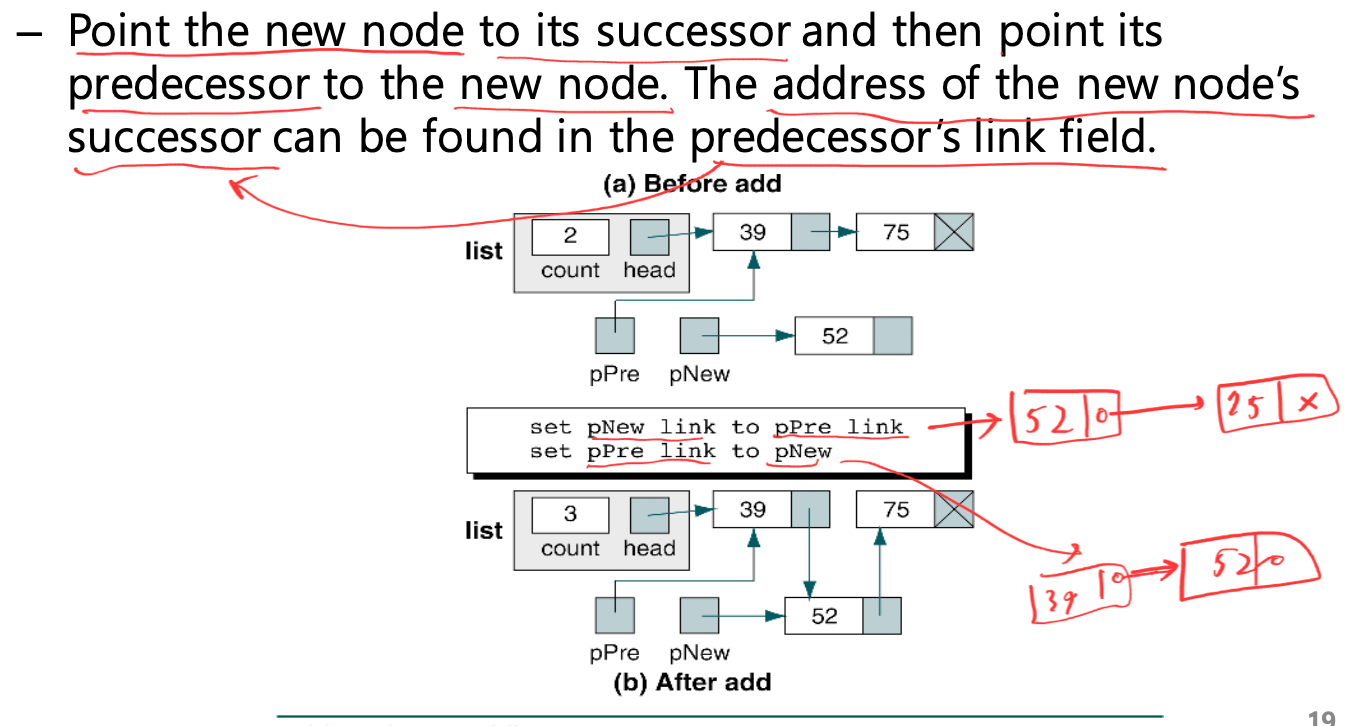 삽입시에는 그림과 같이 삽입할 위치를 찾고 포인터만 바꿔주면 된다.
삽입시에는 그림과 같이 삽입할 위치를 찾고 포인터만 바꿔주면 된다.
삽입할 위치의 이전 노드에 저장된 포인터를 꺼내 새로운 노드의 포인터에 대입하고, 이전 노드의 포인터는 새로운 노드의 주소로 바꾼다.
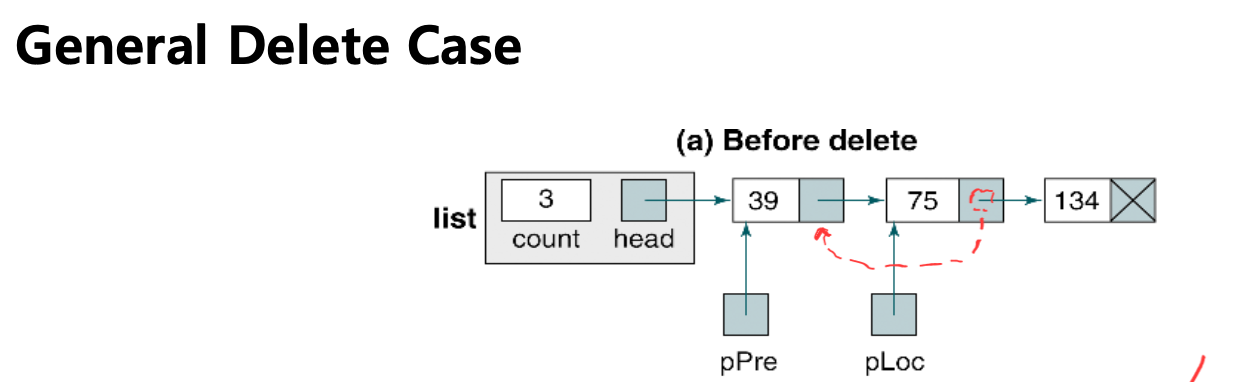
삭제시에는 그림과 같이 삭제할 노드의 포인터를 이전 노드의 포인터에 대입하고, 삭제할 노드는 메모리에서 free(혹은 del)한다.
배열은 삭제/삽입 시 각 요소들을 밀고 당겨야하므로 훨씬 느리다.
Stack
Stack은 삽입과 삭제를 한쪽 끝(top)에서만 할 수 있도록 제한된 선형 자료구조이다. 자료를 넣으면(push), 꺼낼 때(pop)는 반대의 순서로 나오게 된다. (후입선출, LIFO)
stack의 활용
stack은 다음과 같을 때 주로 사용된다.
1. '최근에 임시저장한' 데이터를 가장 먼저 활용:
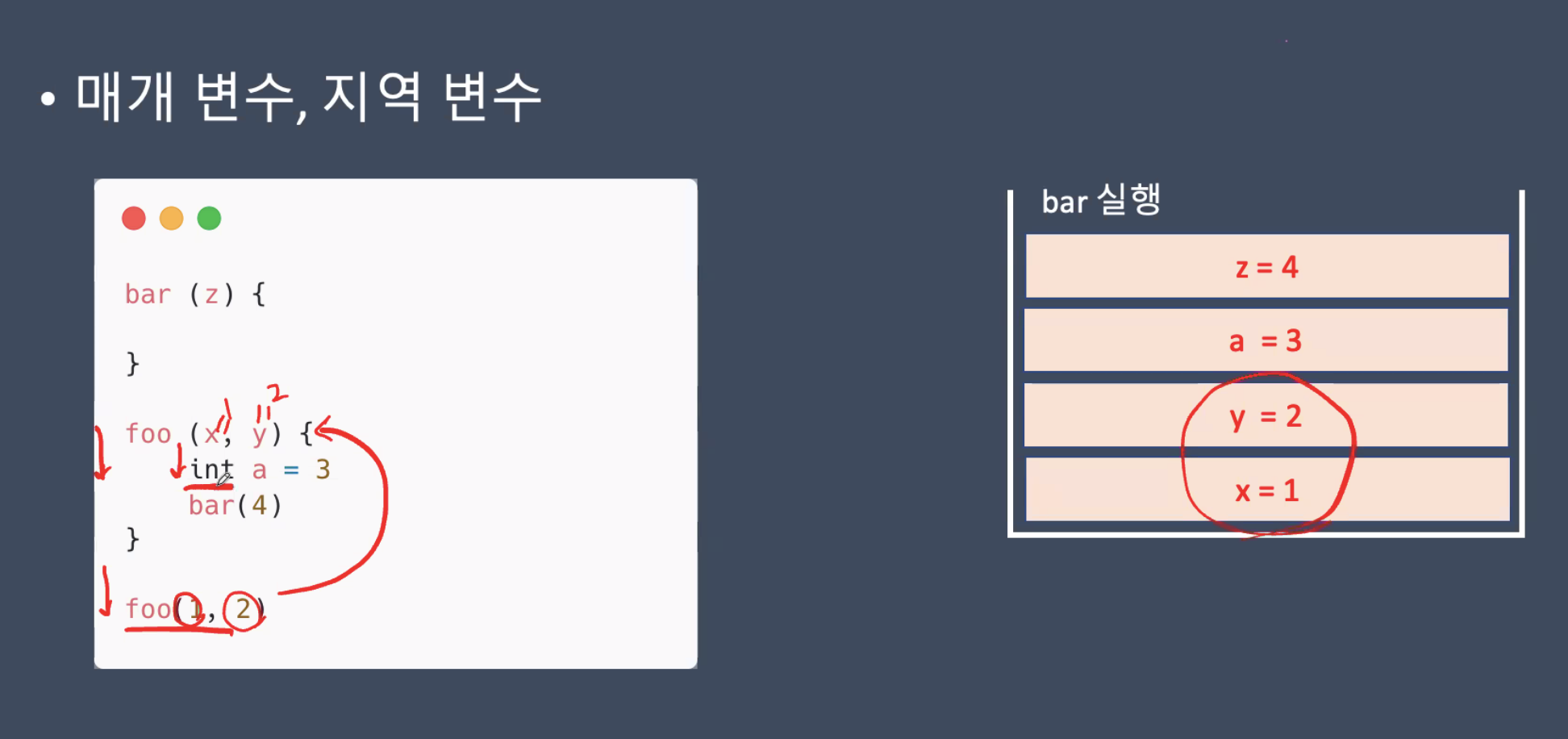
함수의 안에서 선언되는 매개변수,지역변수들은 스택에 저장된다.
함수가 끝나면 메모리에서 변수가 사라져야한다. 스택에 저장했으므로 바로 최근에 저장된 것들을 팝 하면 된다.
2. 쌍을 맞추기:
문자열에 주어진 괄호가 쌍이 맞는지 검사
'(':push
')':pop
문자열이 끝나고 stack에 남은 것이 있거나 빈 stack에서 pop하는 경우에는 쌍이 맞지 않는다는 것이다.
3. 뒤로 가기 기능:
웹페이지, 컨트롤제트, 그래프탐색에서 뒤로가기 등에 활용
Queue
삽입과 삭제를 정해진 반대쪽 양끝에서만 할 수 있도록 제한된 선형 자료구조이다. 자료를 넣으면(enqueue), 꺼낼 때(dequeue)는 넣은 순서로 나오게 된다. (선입선출, FIFO)
Queue 활용
큐는 대기열, 버퍼등을 구현하는데 사용된다. 또한 스케쥴링 알고리즘을 만들 때 쓰인다.
정렬 알고리즘
정렬 알고리즘은 요소들을 기준 값에 따라 오름차순, 혹은 내림차순으로 순서대로 줄을 세우는 것이다.
기본 메서드를 제공하지만, 정렬 알고리즘의 원리를 묻는 문제가 나오기 때문에 그 원리를 알아야 한다.
삽입정렬 (O(N^2))
- 0부터 N까지 요소를 순차적으로 선택한다.(i)
- i보다 앞에 있는 요소들을 역순으로 i와 비교해서 i보다 크면, 한칸 뒤(큰 쪽)로 보낸다.
i 보다 작거나 같은 값을 만나면, 뒤로 보내지 않고 그 값 뒤에 i를 넣는다.
결론:
첫번째 for는 정방향, 두번째 for는 역방향, 앞쪽부터 정렬이 완료된다.
버블정렬 (O(N^2))
가장 큰(뒤로가야할)요소가 거품처럼 쭈루룩 올라가는 모습이 이름의 유래다.
1. 앞에서 부터 순회(i)
2. 인접한것끼리 잘 정렬되어있는지 확인하고 바꿔치기(i,i+1)를 반복한다.
3. 정렬될 때까지 1, 2 를 반복한다. 가장 뒤는 제 위치이므로 반복이 돌 때마다 뒤에서 하나씩 빼고 비교 가능하다. (뒷쪽부터 정렬완료)
선택 정렬 (O(N^2))
- 정렬 안된 부분(최초: 전체 배열)에서 최솟값을 찾고 제일 앞과 치환한다.
- 정렬 안된 부분이 한 사이클당 한칸씩 줄어든다. 1을 다 정렬될때까지 반복한다.
퀵 정렬 (O(nlogn))
분할 정복의 개념을 이용한다. 분할정복은 큰 문제를 작은 문제로 분리해 해답을 찾아 종합하여 큰 문제의 답을 구하는 방법론이다.
- 피벗: 임의로 고른 기준점을 정한한다.
- 피벗보다 큰 것은 피벗 뒤로, 작은 것은 앞으로 넘긴다.
- 앞과 뒤의 sub-array에 대해 1,2를 재귀적으로 실행한다.
- sub-array길이가 1, 0 일때는 그냥 반환한다.
개인 과제 및 팀 과제
1. 직업별 특수스킬 지정
Player 클래스의 서브 클래스들에 특수스킬에 해당하는 스킬을 새로 정의해주면 된다. 그러나 기능의 유사한 부분으로 인해 코드 중복이 발생할 수 있다.
이를 해결하기 위해 super() 사용하였다. 부모 클래스에서 각 특수 스킬의 공통된 기능을 메서드로 정의해주고 자식 클래스에서 super().<매서드명>으로 불러오면 된다.
def mag_attack(self, other):
if self.sp == 0:
print("공격실패: SP가 부족합니다")
return
super().mag_attack(other)
dice = rd.randint(1, 20)
...
2. 선택 - 일반공격 / 특수공격
동기분중 한분이 몬스터가 랜덤하게 플레이어에게 일반공격과 특수 공격 중 한가지 공격을 가하는 코드를 짜고 싶었다고한다.
def attack_or_skill(self, other):
select = random.choice(self.attack(other), self.skill(other))
return select위와 같은 코드를 작성하였더니, 일반 공격과 특수공격을 동시에 하거나, 인자의 갯수를 초과하였다는 오류가 발생하였다.
해결하기 위해 random.choice 함수의 인자 갯수를 맞추어 보고 print()로 어디서 어떤 문제가 발생하는지 알아보았다.
해결: 함수를 실행하지 않고 이름(주소)으로 가져오기
위 코드에서 두 공격 메서드들은 호출된 상태이므로 해당 줄이 번역되자마자 실행되어 공격이 진행되었다.
이를 막기위해 다음과 같이 함수이름을 이용해 함수의 주소를 받아온뒤, 필요할 때 인자를 주고 호출하여 실행시키는 방식으로 해결하였다.
def attack_or_skill(self, other):
select = random.choice([self.attack, self.skill])
select(other)이를 이용하여 임의 순서로 함수를 호출하는 동작도 구현할 수 있었다.
# 플레이어가 더 빠를 때
if p_s-e_s > 0:
first = p_move
second = enemy.attack
first_arg = enemy
second_arg = player_entity
# 플레이어가 더 느릴 때
else:
first = enemy.attack
second = p_move
first_arg = player_entity
second_arg = enemy
first(first_arg)
# 속도차이로 인한 공격불능 체크
if (p_s-e_s)**2 <= rd.randint(1, 25):
second(second_arg)3. 화면전환: os.system
터미널에서 출력이 줄줄이 쌓이지 않고 화면이 전환되는 효과를 만들고 싶었다.
이를 위해 os 모듈의 system 함수를 사용하였다. 이것은 파이썬 코드내에서 CLI에 명령어를 입력하도록 한다.
이를 이용해 화면 전체를 지우는 명령을 내리려고 하였다. OS마다 해당하는 명령어가 다르므로 다음과 같이 try-except문을 이용하려고 했다.
try:
os.system('cls')
except:
os.system('clear')그러나 다음과 같은 오류가 발생하였다.
sh: cls: command not found원인을 찾아본 결과 이 에러를 예외처리 구문으로 해결하지 못하는 이유는 에러가 파이선에서 발생한 것이 아니라 bash에서 발생하였기 때문이다.
해결:
에러를 발생시키지 않고 각 os에 맞게 작동하는 코드를 geeks for geeks에서 발견하였다.
if os.name == 'nt':
os.system('cls')
else:
os.system('clear')os.name을 통해 현재 pyyhon이 어떤 os상에서 실행중인지 알 수 있다. nt는 윈도우 운영체제, posix는 리눅스, 맥os등의 name이다.
4. CSV를 이용한 몬스터 자동생성
다양한 몬스터 종류를 간편하게 저장된 목록상에서 뽑아 랜덤하게 생성하고 싶었다. 이를 위해 클래스를 여러개 만들거나, list of dictionary를 만들어 보았으나, CSV에 각 몬스터의 수치정보(클래스 생성자 메서드에 필요한 인자들)을 저장해두고 딕셔너리 형태로 불러와 입력하였다.
팀과제 컨벤션 정하기
원활한 협업을 위해 대략적인 규칙에 따라 코딩 스타일을 정하기로 하였다.
- 생성된 객체를 담는 변수에는 'entity'라는 단어를 쓴다.
- 어떤 클래스의 메소드는 다음 두가지 조건중 하나라도 해당하는 경우가 아니면 클래스 이름을 제일 앞에 붙인다.
1. 부모로부터 상속하는 메서드를 이용해 작성된다.
2. 오버라이딩 하려고 한다.예시) Character 클래스를 상속받는 Hero 클래스에는 부모와 전혀 상관없는 magic_attack 메서드를 넣어야한다.
이 때는 hero_magic_attack으로 이름을 지어 어디에 위치하는지 알기 쉽게 한다.
팀과제 파일 분리
팀원들과 상의한 끝에 다음과 같이 파일을 분리하여 만들기로 하였다.
이는 협업시 중복 수정 및 충돌의 가능성을 낮추기 위해서 이다.
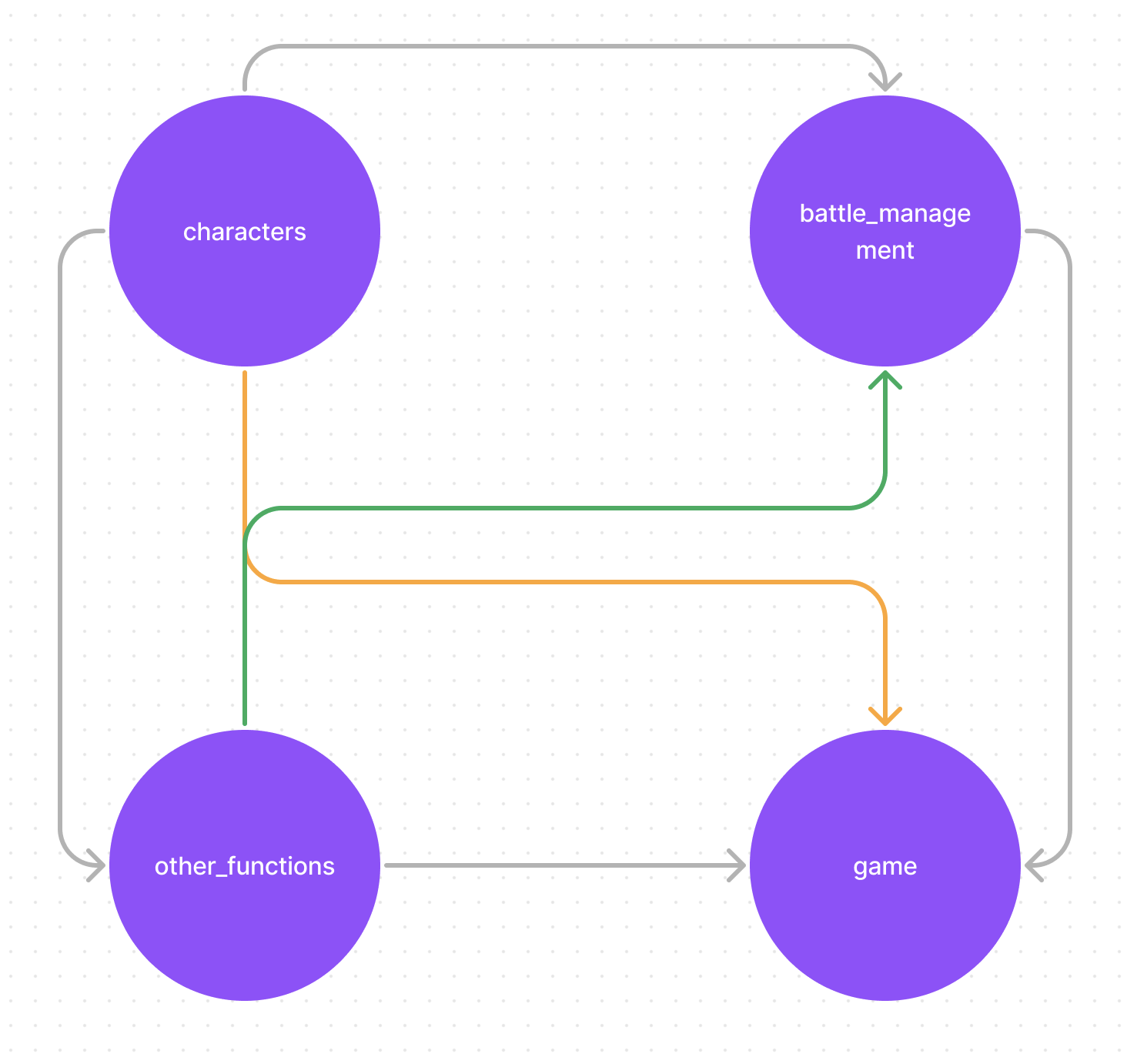
- game.py: 핵심적인 게임의 흐름을 통제한다.
- characters.py: 플레이어블 캐릭터나 적 캐릭터의 클래스를 만들어 두는 파일이다.
- battle_management.py: 한번의 전투 내에서의 흐름을 통제하는 코드들을 모아둔다.
- other_functions.py: 화면 표시, 플레이어 선택에 따른 객체 생성, 랜덤이름 생성등 기타 부가 기능들을 위한 코드들을 모아둔다.
dependancy관계는 다음과 같이한다.
팀과제 역할 분배
역할 분배는 파일을 나눈 목적 대로 파일별로 진행하기로 하였다.
2명씩 묶어서 남은 한명은 플레이어블 캐릭터와 몬스터 캐릭터의 클래스를 만들고, 한 쌍은 game.py 와 battle_management.py를 담당하고(나+한명), 나머지 한 쌍이 oter_functions.py를 담당하기로 하였다.
팀과제 협업 방식
협업은 처음에는 github을 이용하기로 하였으나, 현재 팀원들 간 구현 역량의 편차가 큼을 고려하여, 하나의 live share서버에서 같은 역할을 맡은 인원끼리 협업하고 담당이 아닌 파일은 최대한 직접 수정하는 것을 피하며 계속 변경사항에 대해 소통하기로 하였다.
팀과제 전체 구조 설계 - 주석과 스켈레톤 코드
실제 코드가 실행될 때 구체적으로 실행될 내용들을 생략 하고, 주석 위주로 동작의 절차를 기술하고, 서로 파일, 객체 외부에서 호출하게될 함수들의 이름과 매개변수들을 명확히 정하기 위해 함수 이름만 선언해 두는 스켈레톤 코드를 작성하였다.

팀과제 클래스 딕셔너리 만들기
플레이어의 입력에 따른 직업을 선택하는 기능을, 플레이어의 입력을 키로 삼아 딕셔너리의 값(클래스)를 불러오는 식으로 만들려고 하였다.
class_dict={}
for class_ in list(Hero.subclasses()):
key_=str(class_)[:]# 봐서 적당히 슬라이싱해 클래스명 추출
class_dict[key_]=class_처음에는 부모가 되는 클래스의 __subclasses__() 메서드를 쓰면, 자식 클래스들을 가져오는 것을 이용해 위와 같이 작성했다.
그러나 이는 형변환과 슬라이싱을 이용해야해서 변거롭다.
아예 클래스 안에 적당해 키가 될만한 이름(혹은 입력을 편하게 하기 위해 줄임말)을 지정해두는 것은 사용자가 이미 만들어둔 클래스마다 데이터를 일일히 추가해줘야하는 번거로움이 있었다.
해결: class.__name__
이 속성은 해당 클래스명을 string으로 저장하고 있다.
class_dict={}
for class_ in list(Hero.subclasses()):
key_=class_.__name__[0]
class_dict[key_]=class_따라서 위의 두 시도에서의 문제를 모두 해결할 수 있다.
만약 자식이 아닌 객체 자기 자신의 클래스 명을 알고 싶다면 다음과 같이 하면 된다.
me.__class__.__name__
이런 것들을 내장 변수라고 부르고 메서드인 경우 매직 메서드라고도 부른다.
팀과제 테이블 이쁘게 출력하기
터미널에서 테이블을 출력하고 싶을 때, 문자열의 길이에 따라 테이블이 예쁘게 나오지 않고 깨질 수 있다. 이를 해결하고 싶었다.
문자열 길이를 8 이하로 제한하고 탭문자(\t)을 이용해보려 했으나 잘 되지 않았다. 결국 딱 8 글자일 때는 정렬이 깨진다. 그러나 7 글자까지 제한하고 싶지는 않았다.
TAB='\t'
NOTAB=''
f"\t\t{hero_name}\t\t{TAB if len(hero_name)<8 else NOTAB}{monster_list.get(str(i)).monster_class_name}"위와같이 길이에 따라 탭문자 횟수를 변경하면 탭 문자의 횟수를 길이에 따라 유동적으로 변경시켜서 테이블을 깨지지 않게 할 수 있었다. 그러나 너무 길어져서 더 나은 방법이 있을 것이라 생각하고 찾아보았다.
해결: formatting
f-string은 변수를 출력할 때 최대 몇 칸을 차지하게 출력하고 그 몇 칸 안에서 오른쪽/왼쪽/중앙 정렬중 어떤걸 선택할지 정할 수 있다.
s1 = '1234'
result1 = f'|{s1:<10}|'
print(result1)
# |1234 | 왼쪽
result2 = f'|{s1:^10}|'
print(result2)
# | 1234 | 중앙
result3 = f'|{s1:>10}|'
print(result3)
# | 1234| 오른쪽공백 채우기, 소수점 표시도 지원한다.
f'{"12":=^10}' # 가운데 정렬하고 '=' 문자로 공백 채우기
#'====12===='y = 3.42134234
f'{y:10.4f}' # 소수점 4자리까지 표현하고 총 자리수를 10으로 맞춤
' 3.4213'과제 피드백 정리
1. 딕셔너리의 활용
| method | description |
|---|---|
| dict.keys() | return list of keys |
| dict.values() | return list of Values |
| dict.items() | return list of key-value pairs |
기존 if문을 사용했던 코드를 딕셔너리를 활용해 if문을 사용한 코드보다 간편한 동시에 휴먼에러를 방지하는, 더 안전한 코드로 개선할 수 있다. 조건문을 통해 분기하는 코드는 쓸데없이 길고 보기힘들고 추후 수정하기 번거로울 수 있다.
class_dict={'A':Archer(...),'B':Babarian(...),'C':Cleric(...)}
while True:
print("choose: [A]rcher, [B]arbarian, [C]leric")
choice=input("your choice: ")
if choice in class_dict.keys():
player_entity=class_dict[choice]
break
print('invalid input. re enter.')이렇게 객체를 딕셔너리에 직접 지정하여 조건문 분기를 쓰지 않고 선택지를 만들 수 있다.
클래스의 추가로 인한 코드의 수정이 필요한 경우에도 쉽게 자동으로 반영되게 할 수 있다.
2. 하나의 함수엔 하나의 기능만 넣는다.
2-1. if문 대신 각각의 함수(메서드)를 만들자: 메서드 자체를 나누어 하나의 함수가 오직 하나의 기능을 하게 만들면 깔끔하게 코드를 작성하는데 도움이 된다.
2-2. 함수 실행을 위한 검증(validation)은 분리: 함수가 호출 되면 오직 본연의 기능만 수행하면 되도록 만들어 줘야 구조가 깔끔해지고 디버깅이 용이해진다.
3. VScode 단축키 기능:
변수 선택 후 F2: 해당 변수와 같은 변수가 쓰인부분을 모두 선택하여 수정할 수 있다.
변수 선택 후 ctrl(command)+F2: 선택한 부분과 같은 문자열을 코드 전체에서 모두 선택하여 수정할 수 있다.
둘을 사용방법에 따라 구분하여 쓰면 편리하게 이용할 수 있다.
option+방향키로 커서 갯수를 늘릴 수 있다.
4. import * 지양
해당 모듈의 모든 변수와 함수를 import 하기 때문에, 의도하지 않은 충돌이 발생할 수 있다. 꼭 필요한 요소만 import하도록 하자.
from characters import Character, Hero, Monster, BossMonster, hero_status_wikipedia5. 더 간편한 행동 선택 구현
클래스의 메서드들 중 하나를 선택해서 실행하게 할때, 클래스 자신이 선택대상이 되는 함수들의 이름을 저장하고 있는 딕셔너리 하나를 가지고 있게 하면 더 간단하게 코드를 짤 수 있다.
class Character:
"""
모든 캐릭터의 모체가 되는 클래스
"""
def __init__(self, name, hp, power, magic_power, agility):
self.behaviors={
'1':{'vervose':'일반공격', 'action':self.attack},
'2':{'vervose':'특수공격', 'action':self.magic_attack}
}
... 6. kwargs 활용하기(packing,unpacking)
함수(메서드)가 많은 수의 인자를 받을 때에는 kwargs와 언패킹을 이용해 한번에 딕셔너리로 주고받는 것이 편리하다. 또한 휴먼 에러를 줄일 수 있다.
더 안전한 코드는 사람 코더의 실수에 영향이 적은 코드이다.
class Hero:
def __init__(self, **kwargs): # packing
super().__init__(**kwargs) # unpacking
self.max_mama=kwargs.get('mana')
self.mana=self.max_mana
...
hero_stat={'name':'asdf','hp':10,...}
palyer_character=Hero(**hero_stat) # unpacking
7. doc string과 type hint
협업을 위한 중요한 기능이다.
함수나 클래스 아래에 복수줄 주석(''')을 달아주면 doc string이 된다. 이걸 적어놓으면 해당 함수에 대한 설명을 함수에 마우스를 올려 읽을 수 있다.
매개변수 뒤에 :type을 적으면 어떤 타입의 인자를 받기위한 함수인지알 수 있다. 괄호 뒤에 -> type을 적으면 어떤 반환형을 가지는지 알 수 있다.
def func(num_a: int, num_b: int) -> int:
'''
a+b 반환하는 함수
'''
return num_a + num_b
print(func(10, 11))8. mutable, deep copy
파이선의 자료형은 mutable, immutable로 나뉜다. 리스트와 딕셔너리는 mutable에 속하며, 이들은 다음과 같이 다른 변수에 복사하여 저장하거나 함수에 인자로 넣을 때나 실제로는 같은 메모리 공간을 참조하므로 한쪽에 변경사항이 있으면 둘다 변한다. (shallow copy)
list_1=[1,2,3]
list_2=list_1
list_2[0]=0
print(list_1) # [0,2,3]
dict_1={1:1,2:2}
dict_2=dict_1
dict_2[1]=0
print(dict_1) # {1:0,2:2}따라서 실제로 값을 모두 복사하기 위해서는 deep copy를 해야한다. (.copy() 혹은 [::])
이를 이용하면 다음과 같이 오류가 있는 코드를 간단하게 오류없게 바꿀수 있다.
a = {'a': [[1, 2,3], [2, 3,4], [3, 4,5]]}
for i, j in a.items():
for x in j:
j.remove(x)
print(a)
# {'a':[[2],[3],[4]]}a = {'a': [[1, 2,3], [2, 3,4], [3, 4,5]]}
for i, j in a.items():
for x in j[::]: # deepcopy한 다른 객체
j.remove(x)
print(a)
# {'a':[[],[],[]]}만약 뮤테이블한 객체 안의 뮤테이블한 요소가 또 있는 경우 그것까지 복사해야한다면 copy모듈을 임포트해 deepcopy()함수를 써야한다.
import copy
a = [[1, 2], [3, 4]]
b = copy.deepcopy(a)9. setattr, getattr
setattr()는 객체에 문자열에 주어진 이름의 데이터(변수)나 메서드가 있으면 그 값을 변경하고 없으면 새로 추가해준다.
getattr()는 객체가 가지고 있는 이터(변수)나 메서드를 문자열로 접근하여 가져온다.
문자열로 접근하고, 객체에 없으면 None을 반환한다는 특성이 있어 특정상황에서 유용하게 사용할 수 있다. 예를들어 다음과 같이 동적으로 접근할 수 있다.
attr_list=['foo','bar']
for attr in attr_list:
getattr(x, attr)유무 확인만 하는 hasattr(), 삭제하는 delattr() 도 있다.
기타
reduce
reduce는 함수를 이용해 반복가능한 요소(list 등)의 요소들을 하나의 값으로 연산하게 하는 함수이다.
에를 들어 [1, 2, 3, 4, 5]와 같은 리스트가 있을 때 reduce를 이용해 합계를 구할 수 있다.
import functools
result=functools.reduce(lambda x,y:x+y,[1,2,3,4,5])
# 1+2=3
# 3+3=6
# 6+4=10
# 10+5=15반복문 없이 누적되는 연산을 할 수 있다.
:=, 대입표현식
파이썬 3.8 에서 추가된 기능이다. 바다코끼리 연산자라고 불린다. 변수 대입(초기화)를 하는 동시에 조건문 등에서 사용가능하다.
list_=[1,2,3,4,5]
if (n:=len(list_))>2:
print(f'리스트 길이가 {n}. 2보다 큽니다.')이외에도 리스트안에서도 쓸 수 있는 등 활용법이 다양하다고 한다.
x=5
y=x
a=[y,y**2,y**3]
x=5
b=[(y:=x),y**2,y**3]
#a와 b는 같다차주 목표
- 알고리즘/자료구조 강의와 장고 강의 완강
- 매일 1개 이상 프로그래머스 2단계 이상 수준의 문제 풀이
- 알고리즘 문제 시트에 주어진 기초 알고리즘 문제들 모두 풀어보기
금주 반성
- 알고리즘/자료구조 강의 완강 실패: 개인과제에 시간을 너무 많이 썼고, 팀과제 조율 및 팀원/동기분들을 도우느라 강의를 모두 듣는것은 실패하였다. 다음주에도 시간을 조금 할애하여 모두 완강해야겠다.
- 개인과제와 팀 과제를 git을 이용해 성공적으로 마무리하기: 안타깝지만 마감기한에 맞추지 못할 것 같아 라이브쉐어를 이용해 협업을 진행하였다.
- 코딩 테스트 1일 1개 이상 풀고 TIL에 체계적으로 정리하기: 코딩테스트를 꾸준히 풀긴하였으나 대부분 0~1레벨 문제들이어서 특별히 남길만한 내용이 없었다.
- 좀더 체계적으로 TIL 작성하기,생각의 흐름을 최대한 많이 기록: 오늘 내가 한 것을 실시간으로 작성해두고 그중에 추려서 TIL을 작성해두니 뭔가 시간은 많이 썼는데 쓸건 없었던 이전에 비해 좀더 내용이 생기고 체게가 잡힌것 같아 만족한다.
