1. Python 기초 문법
python은 직관적인 문법, 다양한 라이브러리(특히 ai관련), 광대한 커뮤니티 등을 강점으로 가진 '인터프리터 언어' 이다. 앞으로 python의 Django 웹 프레임워크를 이용해 웹 서비스를 구축하기 위해 기본적인 파이선 문법들에 대한 지식을 배운다.
python 설치란
python을 설치한다는 것은 python문법으로 작성된 .py파일을 한줄 한줄 읽고, 기계어로 번역하여 컴퓨터가 실행하게 만드는 '번역 도구(interpretor)'를 설치한다는 것이다.
C등의 compiler 언어는 컴파일(기계어로 번역)과 실행이 분리되어있다.
따라서 python은 비교적 실행속도가 느리지만 수정이 간편하다.
1-1. 변수 선언 & 자료형
a = 'hi' #string
b = 100 #int
c = True #boolean변수 선언: 새로운 변수명 뒤에 =를 붙여 초기화 함으로 성립된다. 변수는 Memory상의 어떤 위치(주소)에 값이 저장되어있는지 지정하여 변수명을 통해 해당 위치에 접속가능하게 한다.
자료형: 변수에 저장된 값이 어떤 형태인지 나타낸다. type(<변수>)함수를 통해 변수가 어떤 자료형을 띄는지 알 수 있다. 아래 목록을 포함해 다양한 자료형이 존재한다.
| 이름 | 설명 |
|---|---|
| NoneType | - |
| bool | True/False |
| int | 정수 |
| float | 실수(부동소수점) |
| str | 문자열 |
| tuple | 불변하는 요소 묶음 |
| list | 순서있는 요소 묶음 |
| dict | 순서없는 key-value 묶음 |
| function | 함수 |
boolean
참/거짓을 나타내는 자료형으로, 조건문, 비교연산자의 결과로 나타나기 위해 자주 쓰인다.
not, and, or 등의 논리연산자를 이용할 수 있다.
if문에서 빈 문자열, 빈 list, 0, None등의 값은 boolean False로 인식한다.
string
"" 혹은 ''로 둘러 싸인 문자의 연속. 문자열 간의 +연산이 가능하다. 단, 문자열과 숫자 자료형(int, float)을 더하려하면 오류가 발생한다. 또한 문자열의 길이를 len()함수를 이용해 얻을 수 있다.
+
a='I am'
b='a boy'
print(a+b) // I am a boy 출력
print(len(a)) // 4 출력
print(a+10) // errorpython에서 자료형은 class와 같으며 따라서 다양한 내된 메소드(method)를 사용할 수 있다.
string.upper(): 소문자를 대문자로
string.lower(): 대문자를 소문자로
string.split("문자"): 특정 문자를 기준으로 문자열 나누고 list형태로 반환
string.replace("문자1","문자2"): 문자1을 문자2로 바꾸기
string은 list와 유사한 성질을 지녀 index를 통해 안의 요소를 지정(indexing)하고 부분을 추려낼 수 있다. (slicing)
string.join(list of string):string을 사이에 두고 연결되는 문자열을 만든다.
a='abcde'
a[0] # a
a[-1] # e
a[:3] # abc (처음~a[3-1])
a[2:4] # cd (a[2]~a[4-1])
a[2:] # cde (a[2]~끝)
a[:] # abcde (전체)f-string: 문자열에 간편하게 변수 넣기
a = 10
b = 'Smith'
c = b+' is '+str(a)+' years old.'
d = f'{b} is {a} years old.'
print(c) # Smith is 10 years old.
print(d) # Smith is 10 years old.r-string: escape문자 안쓰고 backslash(\)그대로 출력
list
순서 있는 요소들의 묶음. 요소들의 자료형은 다를 수 있다.
a=[1, 'hi', [1, 2, 3], (1,2), {'name':'smith'}] # int, str, tuple, dict
a[1] # 'hi'
a[3] # (1,2)
len(a) # 5 #list 요소 갯수 반환순서가 있는 자료형이므로 indexing과 slicing가능.
list 끼리 +연산을 할 경우 뒤의 list요소들이 앞의 list 뒤쪽에 추가된다.
내장 메서드로 .sort(), .append() 등이 사용가능하다.
in 문법을 통해 요소가 리스트에 있는지 알 수 있다.
a=[1, 2, 4]
3 in a # False
4 in a # True.sort() Vs. sorted(list)
.sort()는 자기 자신을 정렬하여 저장한다. sorted()는 정렬된 리스트를 새로 만들어 반환한다.
dict
key-value 쌍으로 이루어진 순서 없는 자료구조. value는 어떤 자료형이든 가능.
#선언
a={'name':'smith', 'age':20}
a=dict()
#,update, 새 key-value쌍 넣기
a['mbti']='INTJ'in을 통해 특정 key가 dictionary에 있는지 확인가능하다.
me={'name':'smith', family='choi'}
'name' in me # True
'age' in me # Falsetuple
리스트와 비슷하지만 한번 선언되면 내용이 바뀌지 않는다.
a=(10, 9)
a[0]=100 # errorset
요소간의 중복이 제거되는 '집합'을 구현한다.
a=[1, 2, 3, 3]
a_set=set(a) # {1, 2, 3}다음과 같은 연산이 가능하다.
a = [1, 2, 3, 3]
b = [2, 3, 4 ,4]
a_set=set(a)
b_set=set(b)
a_set | b_set #합집합
a_set & b_set #교집합
a_set - b_set #차집합
a_set ^ b_set #합집합과 교집합의 차집합(XOR)1-2. 조건문
조건이 참(True) 일때만 특정 코드를 실행하도록 하는 문법이다. 들여쓰기로 어디까지 if문에 포함인지 결정된다.
a=10
if a>=20: # False
print('bigger then 20') # 미실행
elif a<=10: # True
print('smaller then 10')# 실행
else: #모든 조건 불만족시 실행
print('10<a<=20') # 미실행다음과 같이 한줄 짜리 코드에 사용하기도 한다.
a=10
b= 1 if a<20 else -1
print(b) # 1
a=30
b= 1 if a<20 else -1
print(b) # -1
논리연산자 and, or, not을 이용해 2개 이상의 조건을 복합적으로 사용하고 다양한 로직을 정의할 수 있다.
비어있는 string, 비어있는 list, 숫자 0, None 등은 False로 판별되며, 어떤 값이 True로 판별되는지 아닌지는 bool()함수를 통해 알 수 있다.
bool(0) #false
bool([])#false
bool(-1)#Trueany() / all()
list나 tuple을 입력받아 여러 값들에 대한 True/False를 판단할 때 쓰인다.
print(bool(any([0, False, None]))) # list
print(bool(any((0, '', True)))) # tuple
print(bool(all([1, True, None])))
print(bool(all([1, True, 'abc'])))출력:
False
True
True
False
1-3. 반복문
for문은 다음과 같이 사용한다.
a=[1, 2, 3, 3, 5] #list
for i in a:
print(i)출력:
1
2
3
3
5
다음과 같이 한줄로 사용하기도 한다. (특히 새로운 list만들 때)
a = [1, 2, 3, 3]
b= [2*i for i in a]
print(b) # [2, 4, 6, 6]enumerate(list)
for문과 함께 다음과 같이 사용하면, list내 요소만 반환하는 것이 아니라 index까지 함께 사용할 수 있다.
a=[1, 2, 3, 3, 5] #list
for index, element in enumerate(a):
print(index, element)출력:
0 1
1 2
2 3
3 3
4 5
break
조건문과 함께 사용해 중간에 반복을 멈출 수 있다.
a=[1, 2, 3, 3, 5] #list
for i in a:
if(i == 3):
break
print(i)출력:
1
2
1-4. 함수(function)
함수는 반복사용이 잦은 코드를 미리 저장해두고 필요할때 호출해서 쓸 수 있게 해놓은 것으로, 입력(없을 수 있다)을 가지고 어떤 일을 수행한다.(return이 있을 수도 없을 수도 있다)
def sum_two_int(a,b):
return a+2*b
print(sum_two_int(10,20)) # 10+2*20=50ⅰ. Parameters와 Arguments 정리
Parameter(매개변수)는 함수(메서드)의 입력 변수 명을 의미한다.
Arguments(인자, 전달인자)는 함수(메서드)가 호출시 넘겨받는 입력 값을 의미한다.
def sum_two_int(a,b): # a와 b는 매개변수
return a+2*b
print(sum_two_int(10,20)) # 10, 20은 전달인자Default Parameter(Argument)
함수를 정의할 때 기본값을 지정하면, 호출 시 값을 넘겨받지 않아도 않아도 된다. 인자를 명시하면 순서대로 값이 대입된다.
def sum_two_int(a=10,b=10):
return a+2*b
print(sum_two_int()) # 10+2*10=30
print(sum_two_int(20)) # 20+2*10=40
print(sum_two_int(20,30)) # 20+2*30=80
print(sum_two_int(b=20, a=30)) #30+2*20=70positional Arguments
함수에 인자를 넣을 때 기본적으로 순서에 따라 매개변수에 넘겨주게된다.
def sum_two_int(a,b):
return a+2*b
print(sum_two_int(10,20)) # 10+2*20=40keyword Arguments
함수에 인자를 넣을 때 어떤 매개변수에 넘겨줄지 순서에 상관없이지정할 수 있다.
def sum_two_int(a=10,b=10):
return a+2*b
print(sum_two_int(b=20, a=30)) #30+2*20=70전달인자 방식 혼용
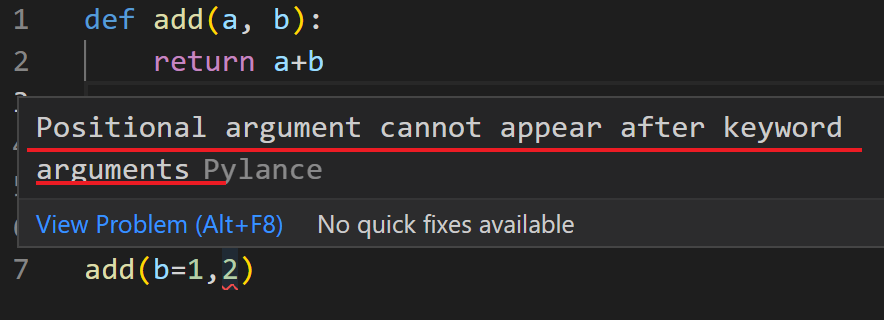
keyword 인자와 positional 인자를 사용할 때 positional 인자는 순서대로넘겨주어야 하므로 keyword인자 뒤에 올 수 없다.
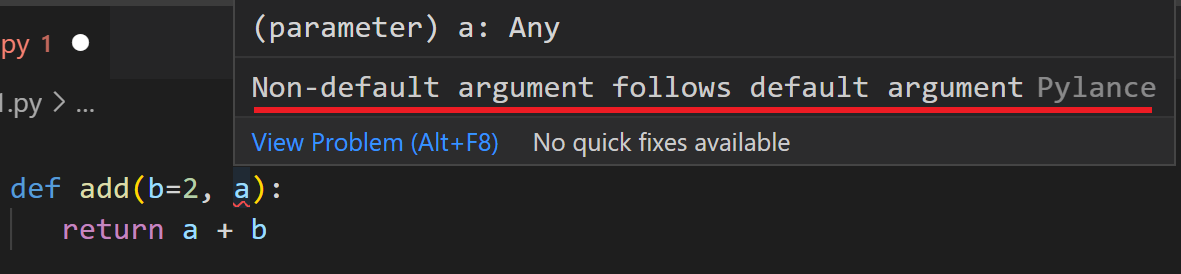
positional 인자는 순서대로넘겨주어야 하므로 default argument또한 그 뒤에 와야한다.
*args, **kwargs (packing)
*args매개변수를 통해 인자 갯수 지정없이 여러개를 순서 대로 받을 수 있다. args가 tuple이 되는 것이다.
def func(**kwargs):
sum=0
print(func(name='smith',age=10,score=100)) # 15**kwargs매개변수를 통해 키워드 인자의 갯수 지정없이 여러개를 순서 없이 받을 수 있다. kwargs가 dictionary가 되는 것이다.
def get_kwargs(**kwargs):
print(f"{kwargs['name']} is {kwargs['age']} old.")
get_kwargs(name='john', age='27') # john is 27 old.이렇게 함수가 인자의 갯수에 상관없이 유연하게 인자를 받을 수 있게하는 것을 packing이라고 한다.
둘 모두 모든 전달인자를 하나의 묶음으로 만드므로, 매개변수의 중간에 오면 안된다. 가장 마지막에 위치해야한다.
def foo(a, *args, b):
print(a)
for i in args:
print(i)
print(b)
foo(1, 2, 3, 4, 5)
# error: foo() missing 1 required keyword-only argument: 'b'unpacking
5번에서와 같이 여러 인자를 packing하는 함수에 list/tuple이나 dictionary를 입력하기 위해서는 각 요소를 풀어 헤쳐서 넣어야한다. 이를 다음과 같이 할 수 있다.
def foo(*args):
for i in args:
print(i)
numbers=[1, 2, 3, 4, 5]
foo(*numbers) # same as foo(1, 2, 3, 4, 5)def foo(**kwargs):
for i in kwargs.keys():
print(i, kwargs[i])
person = {'name': 'Bob', 'age': 30}
foo(**person) # same as foo(name='Bob', age=30)ⅱ. return 타입
비슷해보여도 실제로는 반환형이 다른 함수가 있으며 이들은 서로 사용법이 다르다.
예시)
list.sort():반환없음 Vs.sorted():list반환
검색, 공식문서 이외에 반환형을 확인하는 방법은 다음과 같다.
-
docstring 확인하기:
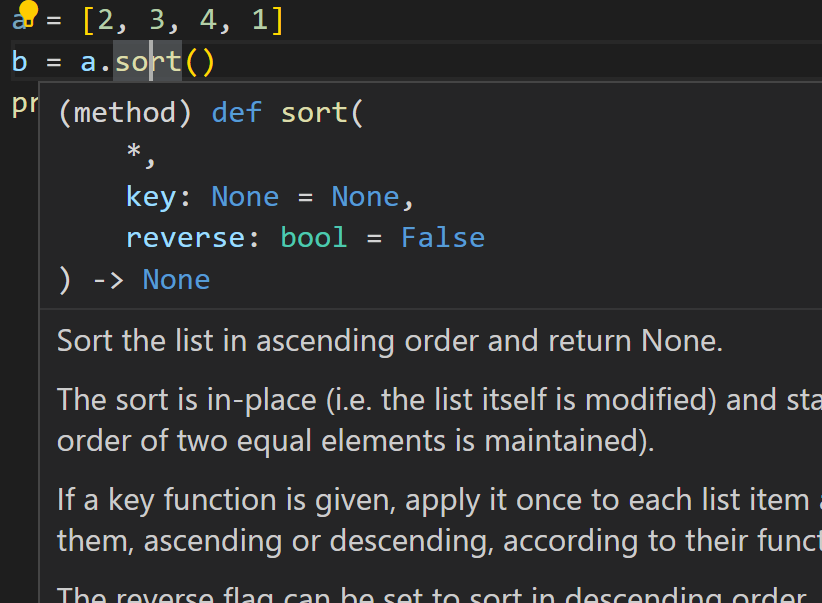 함수의 기능, 매개변수에 받을 인자, 반환형 등을 확인할 수 있다.
함수의 기능, 매개변수에 받을 인자, 반환형 등을 확인할 수 있다. -
구현 코드 확인: 사용하고 있는 함수를
ctrl + click하면 해당 함수가 구현된 부분을 볼 수 있다. python으로 구현된 함수라면 공부에 도움이 된다.
1-5. 예외처리(try-exept)
코드에서 에러가 발생하였어도 실행을 종료하지 않고, 건너 뛰어 다음 줄을 실행할 수 있게 하는 구문이다.
a = {'age':10}
try:
print(a['name'])#줄1
b = 10/0 #줄2
except KeyError as e:
print("키에러", e)
except Exception as e:
print("예측못한 에러", e)
print('end')줄1 실행:
키에러 'name'
end
줄1 주석처리:
예측못한 에러 division by zero
end
execpt 뒤에 에러 종류(KeyError 등)를 지정할 수 있다. Exception은 모든 error를 처리한다. 여러종류의 예외처리를 if/elif/.../else처럼 처리할 수 있다. 디버깅 시 혼동스러우므로 남발하지 않는다. as를 사용해 에러메시지를 변수로 받아올 수 있다.
1-6. 모듈 불러오기(import, from import)
파이선 소스코드를 여러 파일로 분리하면 package를 import하듯 import를 통해 안의 내용을 불러올 수 있다. 이를 모듈을 불러온다고 한다.
from function1 import * # function1 파일로부터 모든 내용 import
from fucntion2 import func2 # function2 파일로부터 f2만 import
import function3 as f3 # function3 파일 전체 import, f3으로 줄여씀
a=10
b=20
func1(a,b) #function1에서 불러온 함수
func2(a,b) #function2에서 불러온 함수
f3.func3(a,b) #function3에서 불러온 함수1-7. map, filter
map(함수,리스트/튜플 등 반복가능한(iterable) 자료형-str,tuple,list,set)def double_plus_one(x):
return 2*x + 1
a = [1, 2, 3, 4]
b = list(map(double_plus_one, a))
print(b) # [3, 5, 7 ,9]map함수는 반복가능한 (요소가 여러개 들어있고 한번에 하나씩 꺼낼 수 있는) 객체의 요소들에 한번에 원하는 함수를 적용하는 함수이다.
map형식 객체를 반환한다.(이를 list, tuple로 형변환해 사용가능하다)
filter(조건함수,리스트/튜플 등 반복가능한(iterable) 자료형-str,tuple,list,set)def is_10(x):
return x == 10
a = [10, 20, 10, 40]
b = filter(is_10, a)
print(list(b)) # [10, 10]filter함수는 반복가능한 객체의 요소들을 한번에 조건함수(입력에 따라 True, False만 반환하는 함수)에 적용해 True인 요소만 포함하는 filter 자료형의 객체를 반환한다.(이를 list, tuple로 형변환해 사용가능하다)
1-8. lambda 함수
lambda함수는 함수를 따로 정의하지 않고 간단한 함수를 즉석에서 쓰게 해준다. 위의 map, filter와 함께 사용시 좋다.
a = [10, 20, 10, 40]
b = filter(lambda x: x==10, a)
print(list(b)) # [10, 10]a = [{'name':'tom','age':30},{'name':'eve','age':17}]
b = list(map(lambda x: 'adult' if x['age']>20 else 'kid', a))
print(b) # ['adult', 'kid']1-9. Class & Object & Instance
Object(객체)는 현실세계의 객체와 유사한 개념이다. 상태(데이터)와 행동(메서드)를 가지는 소프트웨어적인 개념묶음이자 실제로 메모리 상에 존재하고 구별되는 유일한 존재이다. Class는 이런 객체를 소프트웨어 세계에서 구현 하기 위한 일종의 설계도, 틀과 같은 것이다. Instance는 파이썬에서는 구분되는 용어가 아니나 타 객체지향 언어에서는 둘이 다른의미를 가지기도한다.
참고 자료 'Class vs Object vs Instance'
CLASS
class에는 기능(method)와 데이터를 함께 묶을 수 있다.
# 클래스 선언
class Monster():
health = 1000
power = 450
alive = True
# __init__함수는 class의 인스턴스가 생성됨과 동시에 실행되는 함수이다.
def __init__(self, name) -> None:
self.my_name = name
def get_damaged(self, loss):
self.health -= loss
if self.health <= 0:
self.alive = False
def check_alive(self):
if self.alive:
print(f"{self.my_name} is alive.")
else:
print(f"{self.my_name} is dead.")
def do_attack(self, target):
target.get_damaged(self.power)
kate = Monster('Kate') # Monster 객체인 kate instance
mermaid = Monster('ugly mermaid') # Monster 객체인 mermaid instance
for i in range(4):
kate.do_attack(mermaid)
print(kate.health) # 1000
print(mermaid.alive) # FalseClass 상속
class를 생성할 때 부모 클래스(혹은 super class)에 선언된 변수, 메서드를 그대로 가져와 사용가능할 수 있다. 동일한 코드를 조금씩 수정해 사용하거나 내장 class를 변형하고 싶을 때 사용한다. 상속받은 class는 자식 클래스(혹은 sub class)라고한다.
class Monster():
type = 'monster'
def __init__(self, health):
self.health = health
class Goblin(Monster):
def __init__(self, health):
self.type = 'goblin'
print(super().type)
print(self.type)
super().__init__(health) # 부모클래스의 함수 쓰기
class Orc(Monster):
def __init__(self, health):
self.type = 'Orc'
print(super().type)
print(self.type)
super().__init__(health)
a = Goblin(30)
b = Orc(100)자식에서 부모와 같은 변수/메서드를 선언하면 자식이 선언한 것이 우선되며 이를 Overriding이라고 한다. 부모의 메서드를 그대로 쓰고싶다면 super().<메서드명>과 같이 작성한다.
class PreType():
def add(self, a, b):
print(a+b)
class ModifiType(PreType):
def add(self, a, b):
print(2*a+b)
a = PreType()
b = ModifiType()
a.add(10, 10) # 20
b.add(10, 10) # 30
Object 사용
객체는 지금까지 사용해온 자료형 데이터를 포함하는 개념이다. 어떤 객체안의 데이터나 메서드에 접근할 때는 .을 사용한다.
numper_list = [1, 3, 2, 0]
number_list.sort() # [0, 1 ,2, 3]객체에서 어떤 데이터/메서드를 사용할 수 있는지는 함수와 마찬가지로 docstring을 보거나, 구현코드를 통해 알 수 있다.
2. Python 심화
2-1. Code Convention
개발자간에 서로 코드를 알아보기 쉽게 하기위해 만든 코딩 스타일의 약속이다. 이를 지키지 않는 것만으로도 취업에서 감점 요소가 될 수 있다.
PEP-8
PEP-8은 python에서 정한 컨벤션 가이드이다.
PEP-8의 네이밍 컨벤션은 다음과 같다.
- 변수/함수를 이름지을 때는 Snake표기법(this_is_snake)
- Class를 이름지을 때는 Pascal(ThisIsPascal)
- camel case는 쓰지 않는다.(thisIsCamel)
- 상수를 이름지을때는 전부 대문자로 (THIS_IS_CONSTANT)
- list를 이름지을 때는 복수형으로 표기(
names)하거나,name_list와 같이 표기. - 함수를 네이밍할때는 함수의 역할이 표현되어야한다.
- 이미 정의된 변수나 메서드와 겹칠때는 뒤에
_를 붙인다.
PEP-8 자동적용
VSC에서는 자동으로 서식을 컨벤션에 맞추어주는 formatter가 존재한다.
- 설정(
ctrl+,)에 진입해 python formatting을 검색 - Python > Formatting: Provider 설정을 autopep8로 설정
- format on save 검색 후 활성화
위와같이 하면 저장시마다 자동으로 컨벤션에 맞추어진다.
2-2. Variable Scope
모든 변수가 영구히 메모리에 저장되어 있을 순 없다. 변수가 선언된 위치, 키워드 등에 따라 어떤 변수들은 코드가 실행종료될 때 까지 저장되어 있지만, 어떤 변수들은 그렇지 않다. 어떤 변수가 유효한 범위를 variable scope라고 한다.
전역 변수(global variable)
전역변수는 scope가 코드 전체이다. 실행 종료될 때 까지 메모리에 남아있으며, 코드 상의 모든 곳에서 접근이 가능하다.
함수의 안이 아닌 곳에 선언되면 전역변수가 된다. 또한 지역변수가 선언될 위치(함수 내부)에서도 global키워드를 이용해 전역변수로 선언할 수 있다.
지역 변수(local variable)
지역변수는 함수안에서 선언된 변수이다. 함수의 실행이 종료될 때 까지만 메모리에 남아있는다. 다른 함수에 영향을 끼치지 못한다.
a = 10
def foo():
b = 20
print(a)
def foo2():
print(b)
foo() # 10
foo2() # error
print(b)# error어떤 함수 내에서 전역변수를 그냥 사용하려고 하면, 이는 지역변수를 선언하여 사용하게된다. 즉 지역변수가 전역변수보다 우선시된다. 전역변수를 사용하기 위해선 global키워드를 이용해 전역변수임을 표시해주면된다.
a = 10 # global
def foo():
print(a) # global
def foo2():
a = 20 # local
print(a)
def foo3():
global a # global
a = 30
foo() # global
foo2() # local
print(a) # global
foo3() # global
print(a) # global
2-3. 정규표현식(regex)
문자열이 특정 패턴과 일치하는지 판단할 때 쓰인다. 정규식이 없이 slicing과 반복문, 조건문을 사용하여 복잡하게 판별할 것을 간단하게 할 수 있다.
from pprint import pprint
import re # 패키지를 import해야 사용할 수 있다.
# rstring : backslash(\)를 문자 그대로 표현
email_regex = re.compile(r"^[\w\.-]+@([\w-]+\.)+[\w-]{2,4}$")
def verify_email(email):
return bool(email_regex.fullmatch(email))
정규식 패턴을 직접 짜는것은 어려우며 각 언어마다 조금씩 다를 수 있으므로 예제 사이트등을 참고한다.
2-5. 여러 유용한 모듈
pprint
데이터를 더 보기 좋게 출력해주는 pprint함수를 쓸 수 있다.
# pprint는 pretty print의 약자이며, 데이터를 더 예쁘게 출력해 줍니다.
from pprint import pprint
sample_data = {
"rows":
[
{"id": "01", "name": "Alice"},
{"id": "02", "name": "Bob"},
{"id": "03", "name": "Cyan"},
{"id": "04", "name": "Dave"}
]
}
pprint(sample_data)출력:
pprint:{'rows': [{'id': '01', 'name': 'Alice'}, {'id': '02', 'name': 'Bob'}, {'id': '03', 'name': 'Cyan'}, {'id': '04', 'name': 'Dave'}]}print:
{'rows': [{'id': '01', 'name': 'Alice'}, {'id': '02', 'name': 'Bob'}, {'id': '03', 'name': 'Cyan'}, {'id': '04', 'name': 'Dave'}]}
random
난수가 필요할 때나 랜덤성이 필요할 때 사용한다.
import random
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
random.shuffle(numbers) # numbers를 무작위하게 섞기
random_number = random.randint(1, 10) # 1 ~ 10 사이에서 랜덤한 숫자
time, datetime
import time
start_time = time.time() # 현재 시간 저장
time.sleep(0.5) # 0.5초간 대기
# 코드 실행 시간.
print(f"{time.time()-start_time:.3f}") # ':.3f':소숫점 3자리까지from datetime import datetime, timedelta
# 현재 날짜 및 시간 출력
print(datetime.now()) # 현 날짜+시간
# str to datetime(strptime)
string_datetime = "2023/03/21 13:20:45"
datetime_ = datetime.strptime(string_datetime, "%Y/%m/%d %H:%M:%S")
print(datetime_) # 2023/03/21 13:20:45
# datetime to str(strftime)
now = datetime.now()
string_datetime = datetime.strftime(now, "%m/%d %H:%M:%S")
print(string_datetime) # 03/21 13:26:44
# 전/후 날짜+시간 데이터 : timedelta 사용
two_hr_later = datetime.now() - timedelta(hours=2)format code:
| code | 설명 | 예시 |
|---|---|---|
| %y | 두 자리 연도 | 20, 21 |
| %Y | 네 자리 연도 | 2020, 2021 |
| %m | 두 자리 월 | 01~12 |
| %d | 두 자리 일 | 01~31 |
| %I | 12시간제 시간 | 01~12 |
| %H | 24시간제의 시간 | 00~23 |
| %M | 두 자리 분 | 00~59 |
| %S | 두 자리 초 | 00~59 |
2-6. 파일/디렉토리
glob 패키지를 사용해서 외부 파일과 디렉토리를 조회/조작할 수 있다.
1. 목록보기
from pprint import pprint
import glob
# 현재 디렉토리 아래의 venv 폴더아래 모든 파일/디렉토리 표시
path = glob.glob("./venv/*")
pprint(path)
# **은 해당 경로 하위 모든 파일을 의미. recursive 플래그와 사용
# recursive=True: 내부의 파일들을 재귀적으로 탐색
# 현재 디렉토리 아래의 venv아래의 모든 파일과 디렉토리 내부까지 재귀적으로 표시
path = glob.glob("./venv/**", recursive=True)
pprint(path)
# *.py: py확장자 파일만 조회
# venv하위 모든 폴더들을 재귀적으로 탐색하여 .py 확장자 파일의 경로만 출력
path = glob.glob("./venv/**/*.py", recursive=True)
pprint(path)
2. 파일 열기/편집/닫기
# case 1. open 함수를 사용해 파일 열기
# 파일 경로, 모드(r:읽기/w:비우고 쓰기/a: 줄 추가), 인코딩 지정
f = open("file.txt", "w", encoding="utf-8")
f.write("파이썬 파일 쓰기 테스트!\n") # 쓸 내용 적용
#파일에 대한 작업이 끝나면 닫기
f.close()
# with 구문:끝나면 자동으로 파일이 close
with open("file.txt", "a", encoding="utf-8") as w:
w.write("파이썬 내용 추가 테스트!")
# r: 읽기모드
with open("file.txt", "r", encoding="utf-8") as f:
while True:
# 한 줄 씩 출력
line = f.readline()
# 파일 끝:반복중지
if not line:
break
# 줄바꿈 문자 제거
line = line.strip()
print(line)2-7. itertools 모듈
ittertools는 반복적인 무한 패턴을 만들어내거나 반복적인 배열의 연산 등을 할때 빠르고 메모리효율적인 도구를 제공한다.
from itertools import *
#무한 등차수열
a = count(10,5)
for i, e in enumerate(a):
print(e, end=" ")
# 출력: 10 15 20 25 ...
#무한 순환형 리스트
a = cycle('1234')
for i, e in enumerate(a):
print(int(e), end=" ")
# 출력: 1 2 3 4 1 2 ...
# 데카르트곱
a = product(['A', 'B', 'C'], [1, 2, 3])
for i, v in enumerate(a):
print(v, end=" ")
if i % 3 == 2:
print('')
'''출력:
('A', 1) ('A', 2) ('A', 3)
('B', 1) ('B', 2) ('B', 3)
('C', 1) ('C', 2) ('C', 3)
'''
# 순열
for i in permutations([1, 2, 3], 2):
print(i, end="")
# 출력: (1, 2)(1, 3)(2, 1)(2, 3)(3, 1)(3, 2)
# 조합
for i in combinations([1, 2, 3], 2):
print(i, end="")
# 출력: (1, 2)(1, 3)(2, 3)2-8. requests 모듈
http통신을 가능하게한다. api동신이 필요하거나 웹 크롤링에 쓰인다.(BeautifulSoup과 함께 쓰임)
http method에 따라 4가지 method가 있다: GET, POST, PUT, DELETE
요청에 대한 응답은 content와 status code로 이루어진다.
GET 요청:
import requests
r = requests.get("url")
# r.text: content
# r.status_code: status codePOST 요청:
data = {...}
r = requests.post("url", data=data)
# r.text: content = 보낸 내용
# r.status_code: status code2-9. JSON, CSV
JSON과 CSV는 데이터를 저장하는 형식이다.
JSON
JSON은 dictionary와 유사하게 key:value쌍으로 이루어져 있어 python에서는 dictionary로 변환해 사용하기 좋다.
import json
import requests
# request로 응답을 r로 받아옴...
response_content = json.loads(r.text) # 텍스트 형식 json을 dict로 변환
...
json_output=json.dumps(response_content) # dic to json
CSV
,로 필드를 구분하는 텍스트 형식의 데이터 형식이다. 이러한 특성으로 인해 간단하게 csv파일을 편집, 생성할 수 있다.
읽기
import csv
from pprint import pprint
csv_path = "sample.csv"
# 파일 열고 csv를 list 자료형으로 읽기
csv_file = open(csv_path, "r", encoding="utf-8")
csv_data = csv.reader(csv_file)
pprint(list(csv_data))
csv_file.close()
'''
[['email', 'birthyear', 'name', 'Location'],
['laura@example.com', '1996', 'Laura Grey', 'Manchester'],
['craig@example.com', '1989', 'Craig Johnson', 'London']]
'''
# 파일 열고 csv를 dict 자료형으로 읽기
csv_file = open(csv_path, "r", encoding="utf-8")
csv_data = csv.DictReader(csv_file)
pprint(list(csv_data))
csv_file.close()
'''
[{'Location': 'Manchester',
'birthyear': '1996',
'email': 'laura@example.com',
'name': 'Laura Grey'},
{'Location': 'London',
'birthyear': '1989',
'email': 'craig@example.com',
'name': 'Craig Johnson'}]
'''쓰기
import csv
csv_path = "sample.csv"
# newline='': 공백 라인이 생기는 것을 방지
csv_file = open(csv_path, "a", encoding="utf-8")
csv_writer = csv.writer(csv_file) #writer로 작성기 생성
# writer.wirterow(list)로 csv에 row 추가
csv_writer.writerow(["alabama@us.com", '1060', "smith", "TEXAS"])
csv_file.close()
Pandas Dataframe과 호환한다.
import pandas as pd
data = pd.read_csv('파일경로/파일이름.csv') # 열기
data.to_csv('파일경로/파일명.csv', index = False) # 저장2-10. Decorator
데코레이터는 함수를 장식하여 함수가 실행될 때 함께 실행되도록 한다.
선언:
# 호출 할 함수를 인자로 받는다
def decorator_trackingfunc(func):
# 호출 할 함수를 감싸는 wrapper 함수
def wrapper():
# func.__name__: 호출 한 함수의 이름
print(f"{func.__name__} 함수에서 데코레이터 호출")
func()
print(f"{func.__name__} 함수에서 데코레이터 끝")
# wrapper 함수를 반환한다.
return wrapper함수가 실행될 때 wrapper안에 함수 앞 뒤의 코드들이 함께 순차적으로 실행된다.
사용: 함수 선언 위에 '@[데코레이터 이름]'을 쓴다.
@decorator_trackingfunc
def decorator_func():
print("hello")
decorator_func()
# 출력:
"""
decorator_func 함수에서 데코레이터 호출
hello
decorator_func 함수에서 데코레이터 끝
"""데코레이터를 이용해 인자 조작:
def longer(func):
def wrapper(a, b):
# 함수에서 인자를 가로채 조작
longer_a = a+a
longer_b = b+b
return func(longer_a, longer_b)
return wrapper
@longer
def attach1(a, b):
return a + b
def attach2(a, b):
return a + b
print(attach1('hello', 'world'))
print(attach2('hello', 'world'))
#출력:
'''
hellohelloworldworld
helloworld
'''