Pandas
pandas 는 통상 pd로 import하고
수치해석적 함수가 많은 numpy(넘파이)는 통상 np로 import한다
pandas의 데이터형을 구성하는 기본은 Series이다.
index 와 value로 구성
한가지 데이터 타입만 가질 수 있다.
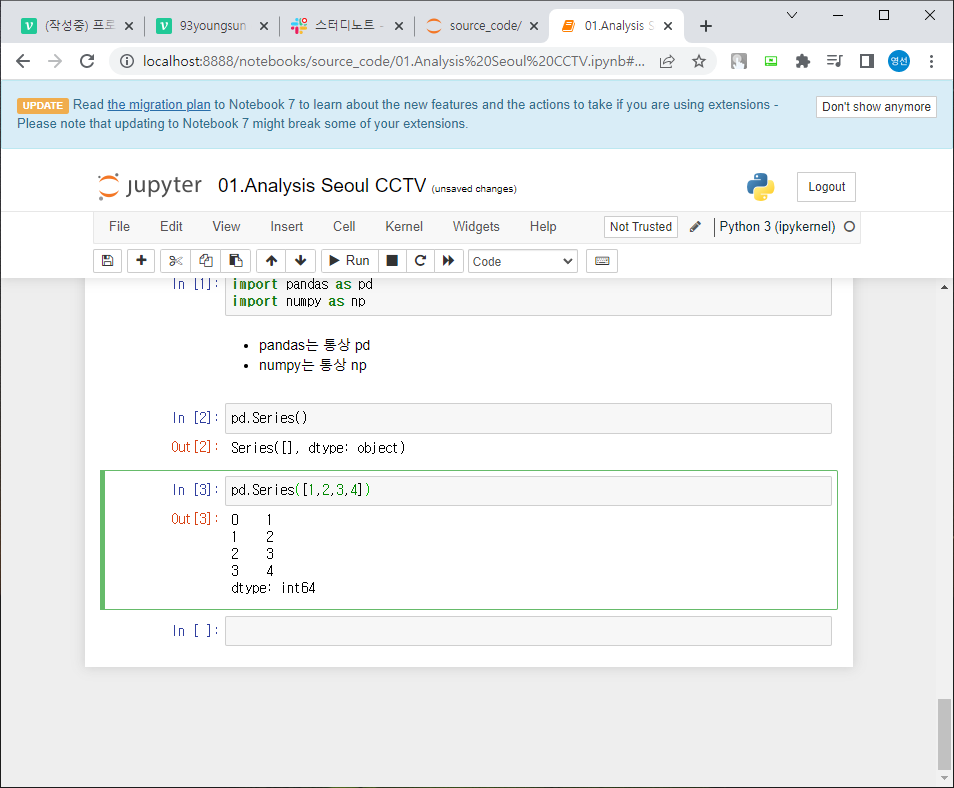
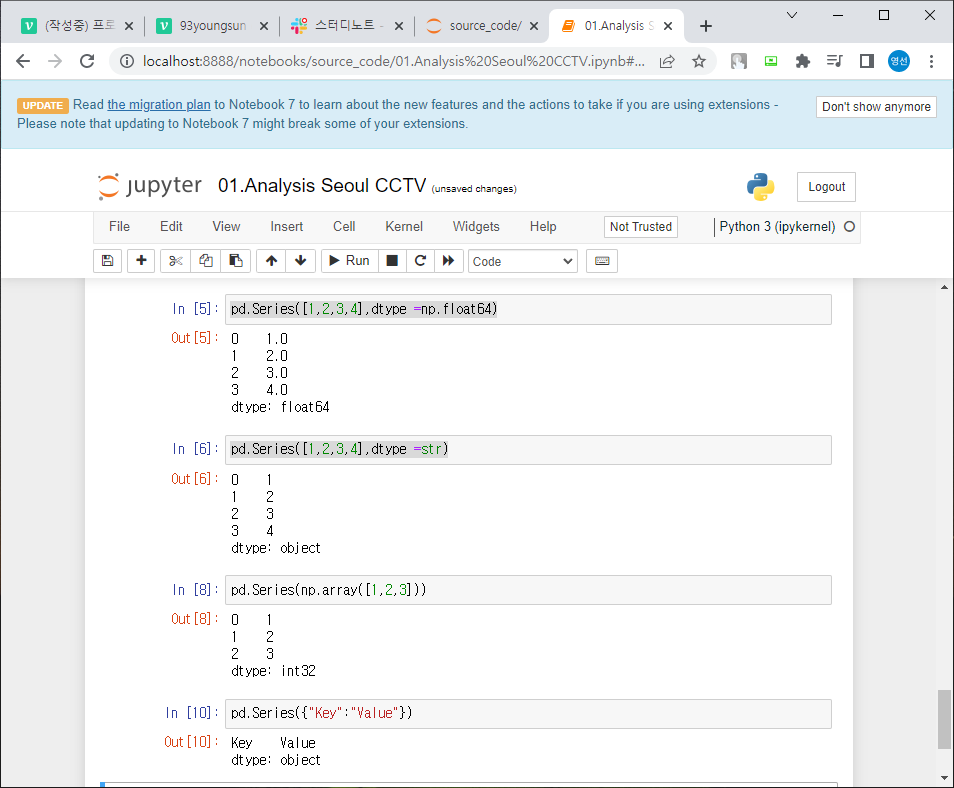
기본은 int 형 / 다른 형태 데이터로 dtype을 통해 변경 가능
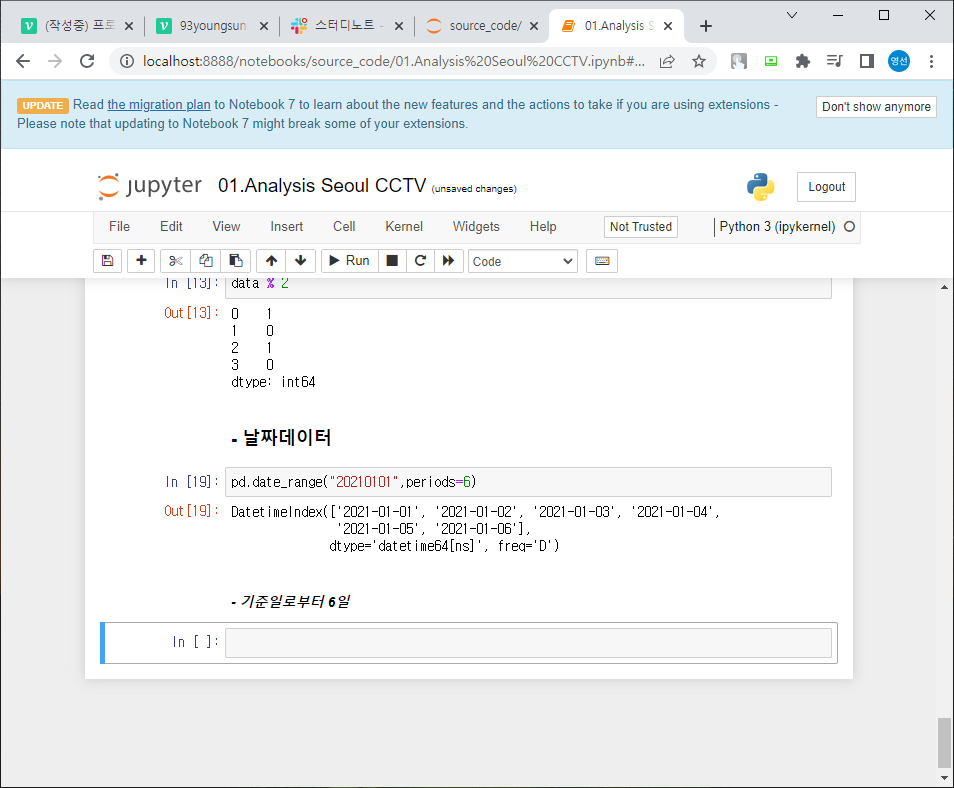
date = pd.date_range("20130101",periods=6) 같이 사용해서 날짜(시간)이용 가능
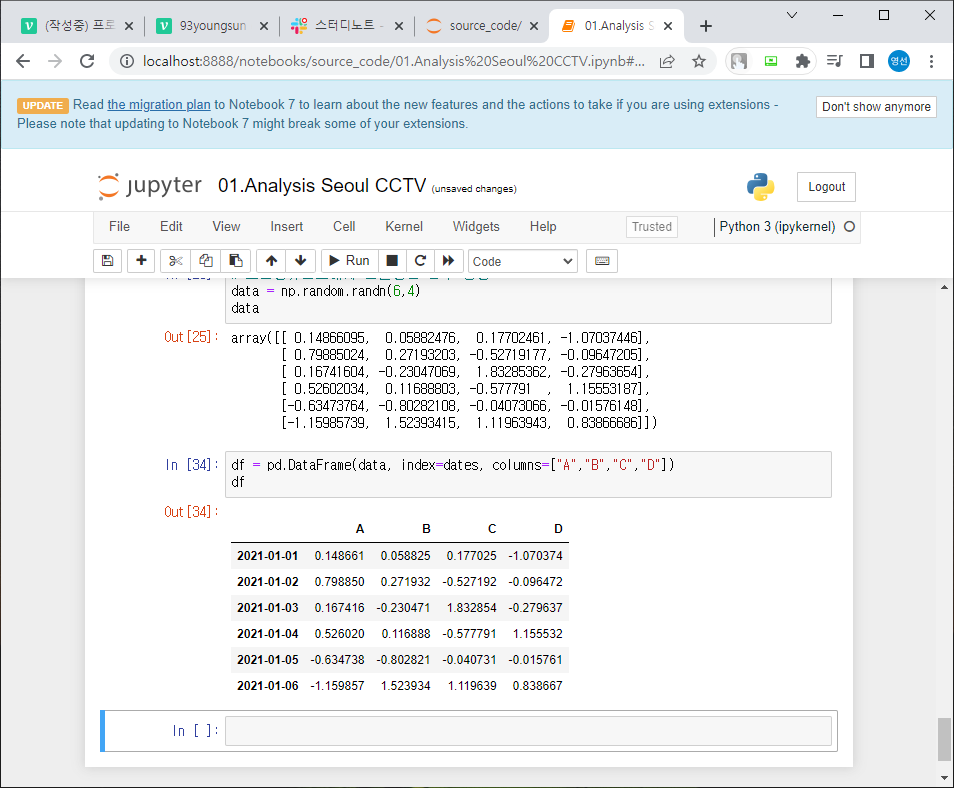
pandas에서 가장 많이 사용되는 데이터형은 DateFrame이다.
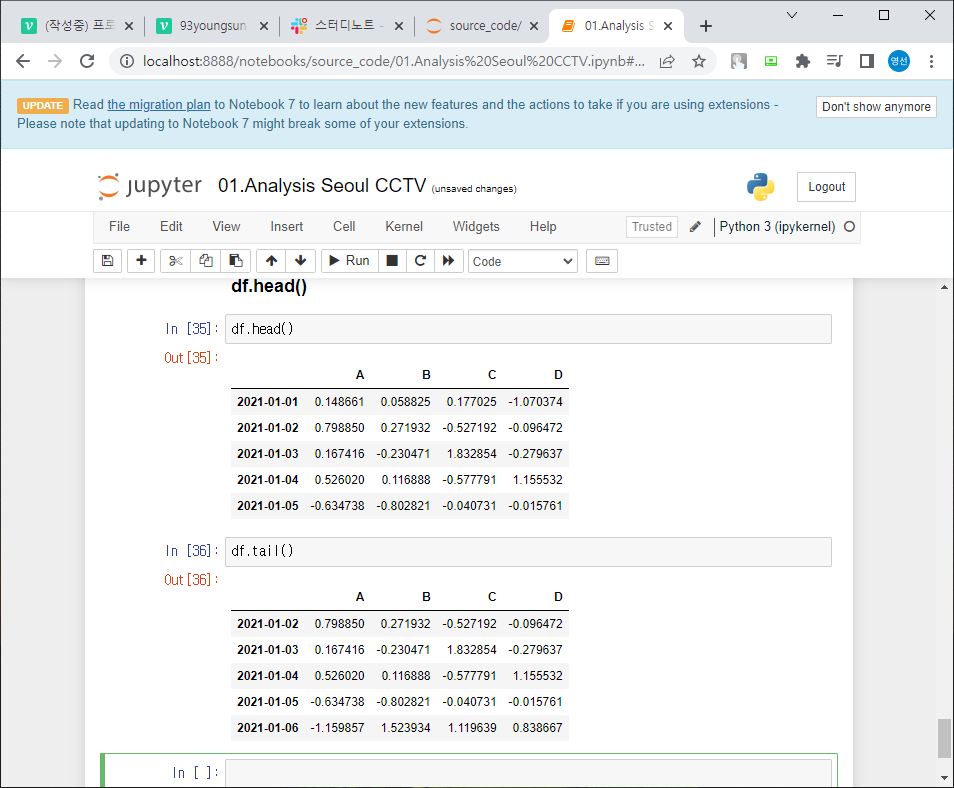
df.head() = 앞부분 5개 데이터확인
df.values = DataFrame의 value 확인
df.info() = DataFrame의 기본정보 확인 / 컬럼 크기와 데이터형태 확인을 많이함

df.describe() = DataFrame의 통계적 기본정보 확인(최솟값, 편차 등)

df.sort_values(by="B", ascending = False) = B컬럼 기준으로 내림차순으로 정렬해라
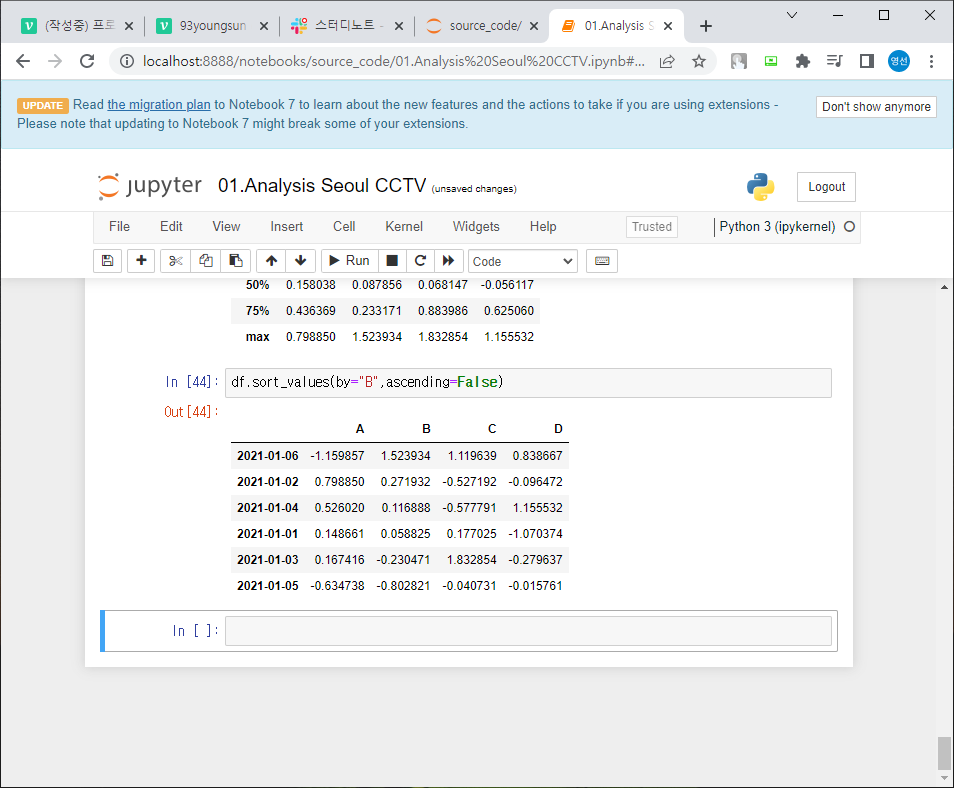
*inplace = True 추가하면 정렬된 값 그대로 저장하여 추후에도 적용가능
df["A"] = 특정 컬럼만 읽기 /컬럼명이 문자면 df.A 로도 가능

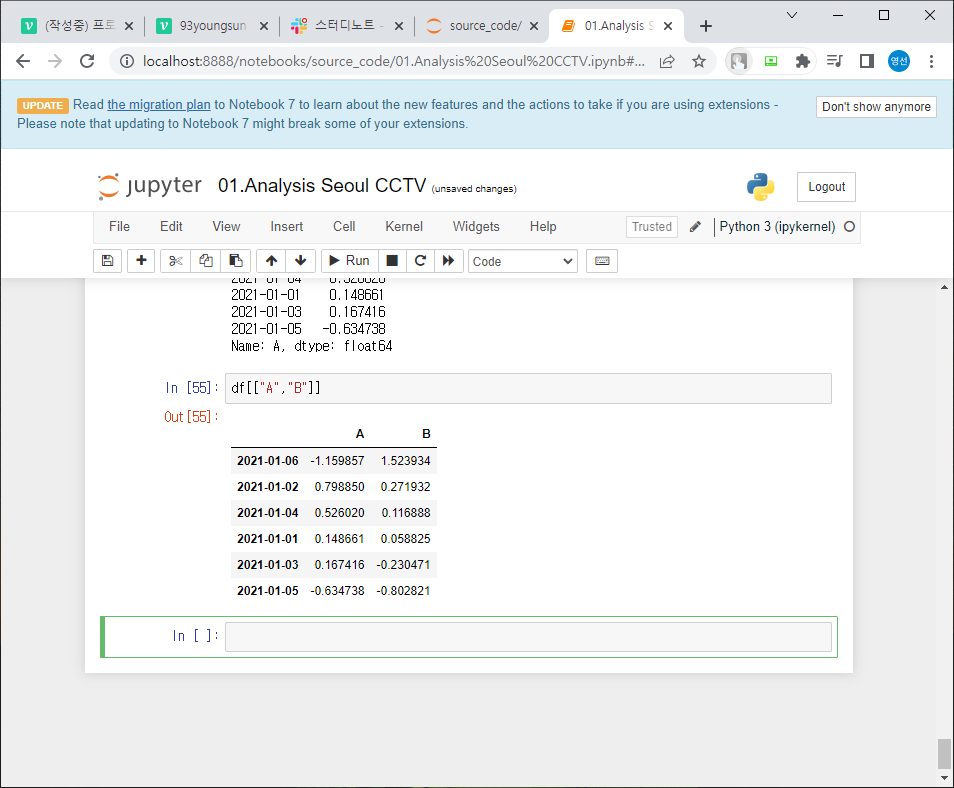
두개 이상 컬럼 부르기
df[n:m] = n부터 m-1까지 읽기 / 그러나 인덱스나 컬럼 이름으로 slice하는 경우 끝을 포함
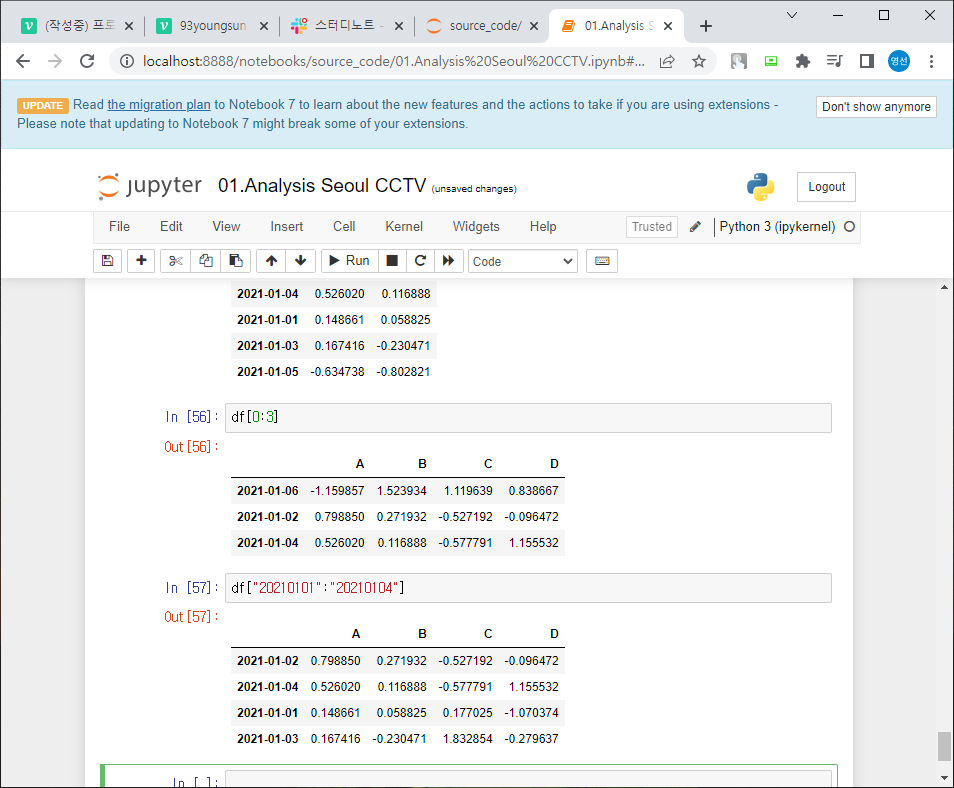
df.iloc[3:5, 0:2] = 3번,4번행의 0,1,2번열 선택
df.iloc[[1,2,4],[0,2]] = 1,2,4번행 의 0번 2번 열 선택
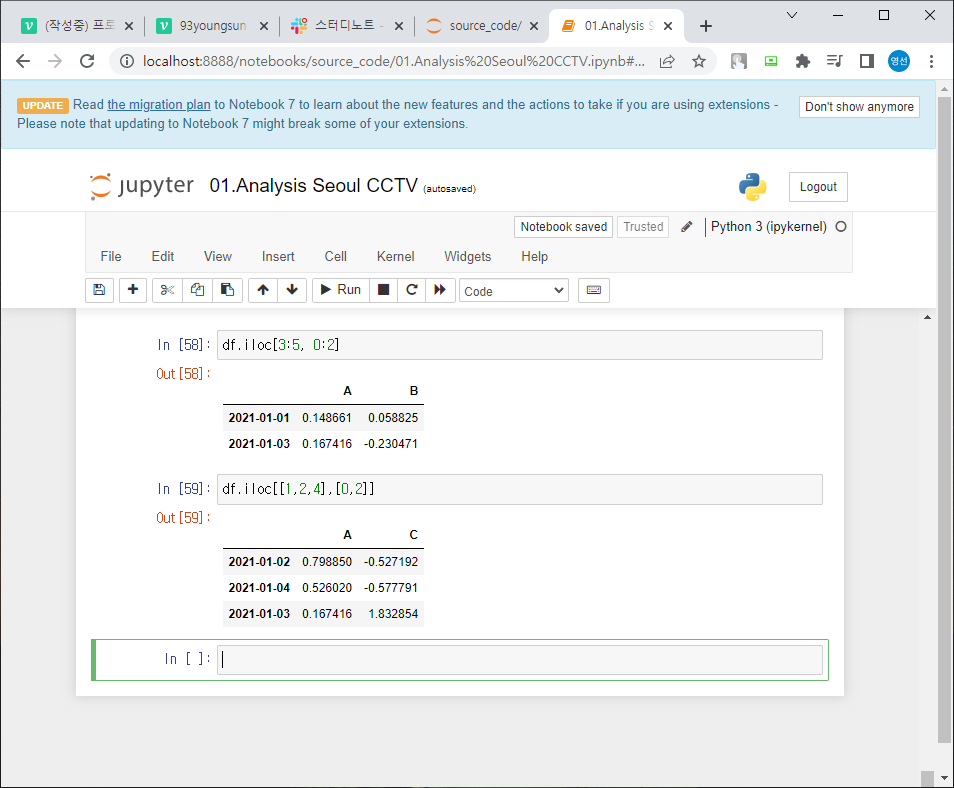
df["A"] >0
df[df["A"]>0] = A열에서 0보다 큰 값들
df[df>0] = 전체에서 0보다 큰 값들 / 0보다 작으면 Nan (not a number)
df["E"] = ["one","one","two","three","four","five"]] = E라는 열 만들고 값 삽입
열 길이 일치해야함
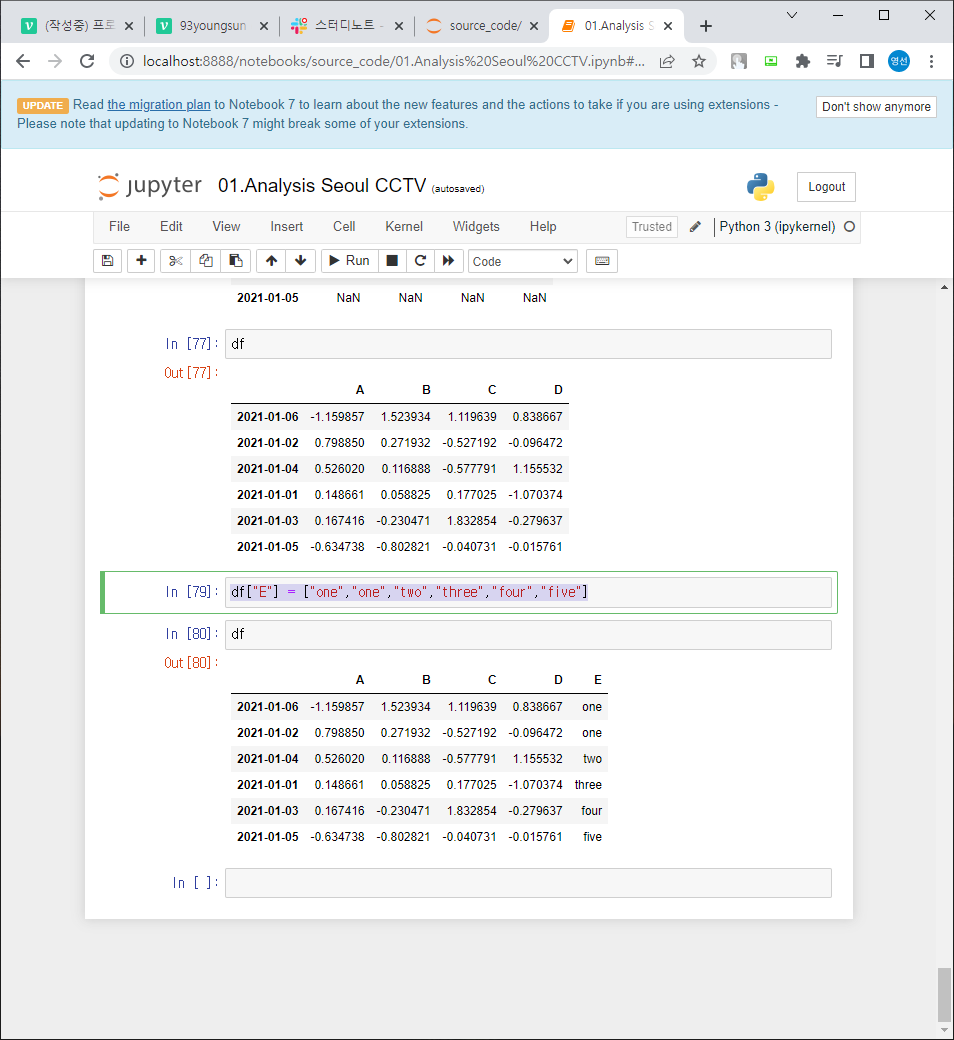
기존 컬럼이 있으면 수정됨
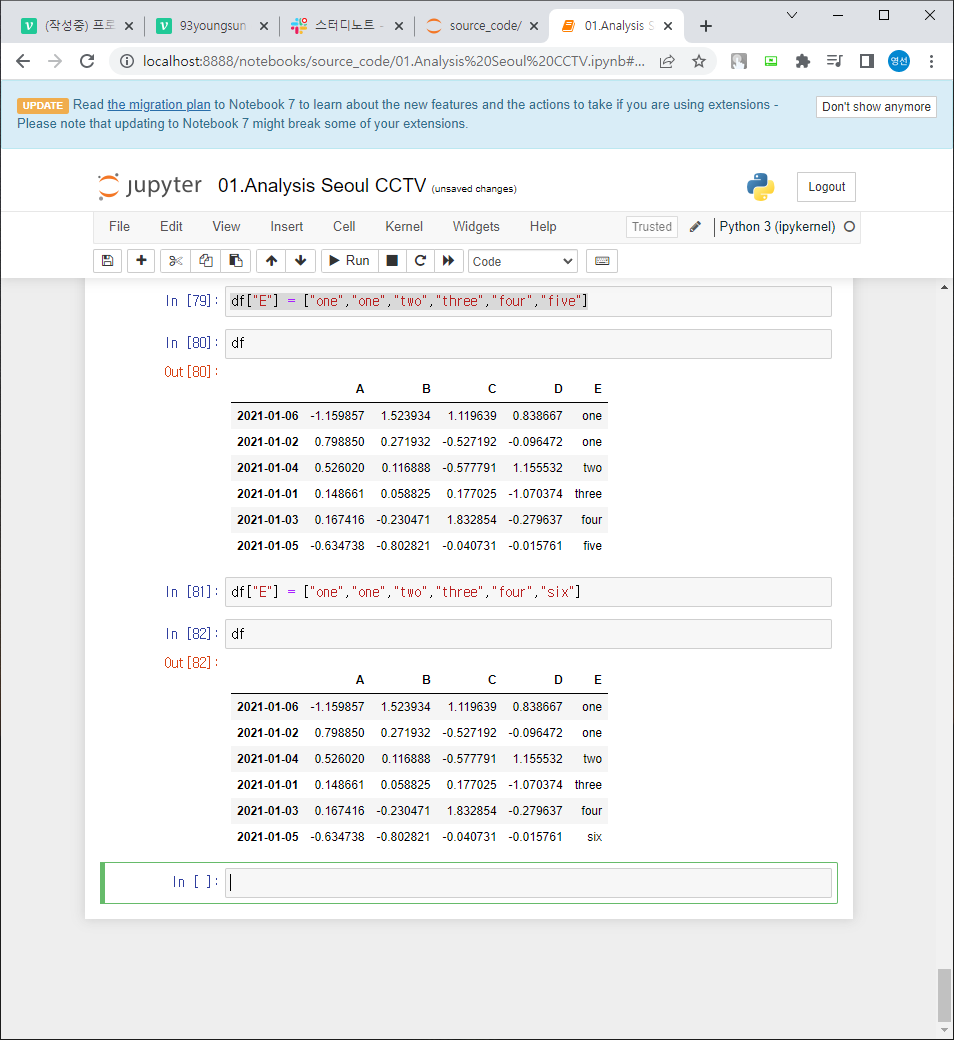
df["E"].isin(["two","four"]) = E 안에 two, four 라는 값이 있는가 확인
df[df["E"].isin(["two","four"])] = two랑 four가 있는 컬럼만 보여줌

del df["E"] 열 삭제
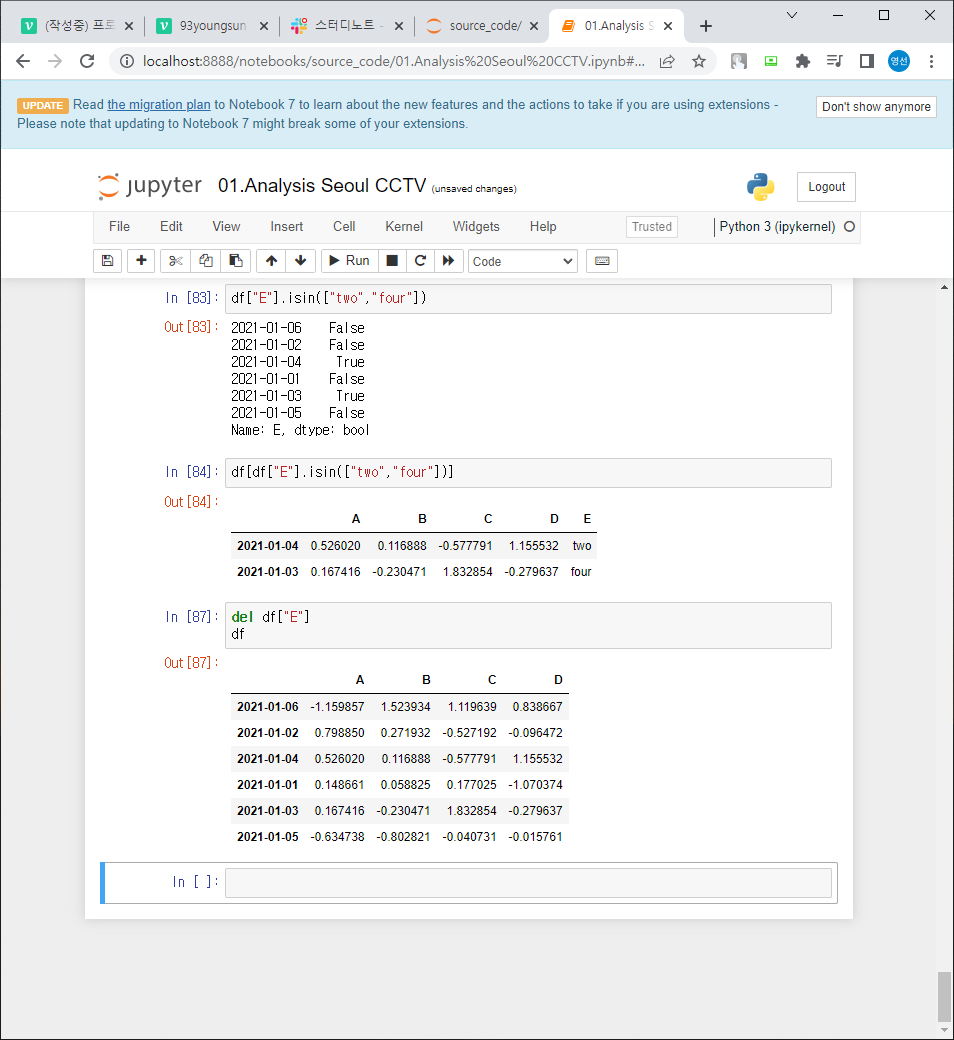
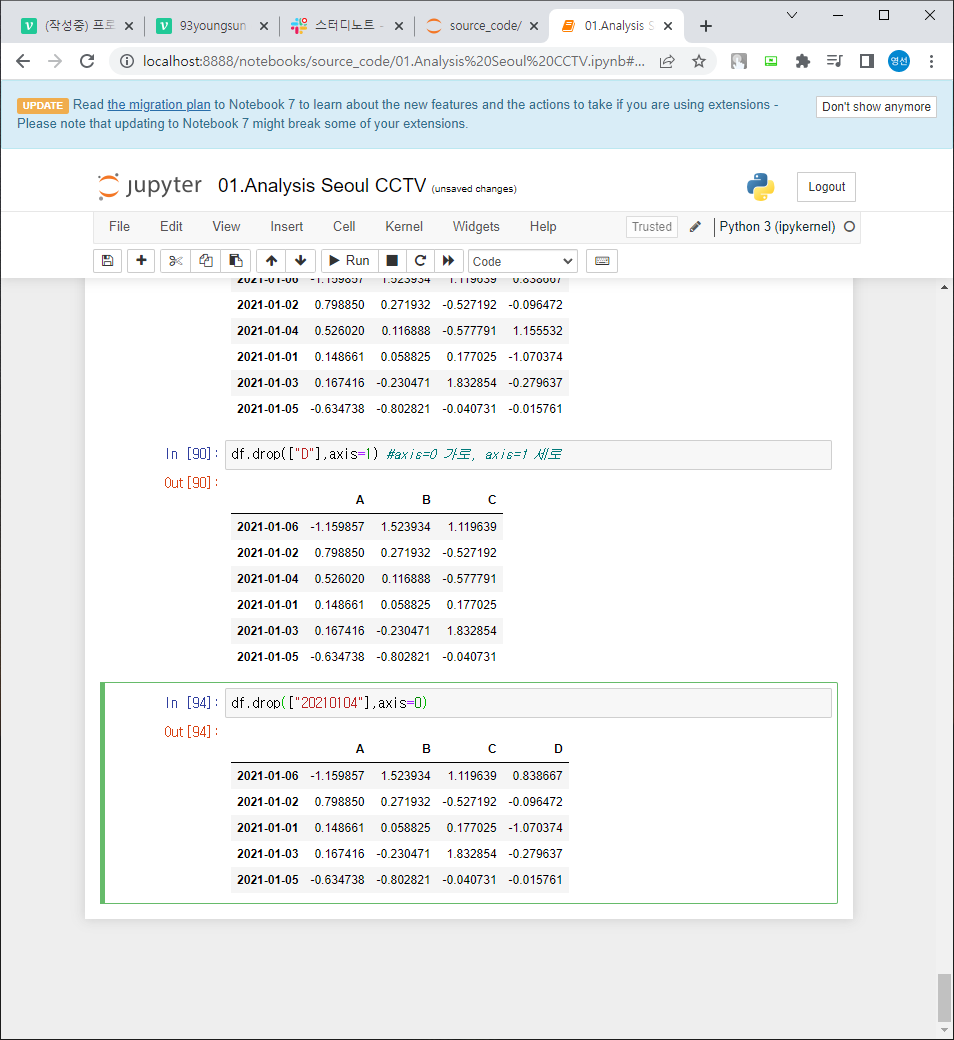
df.drop(["D"],axis=1) #axis가 0이면 index값 중 하나를 삭제하겠단 소리
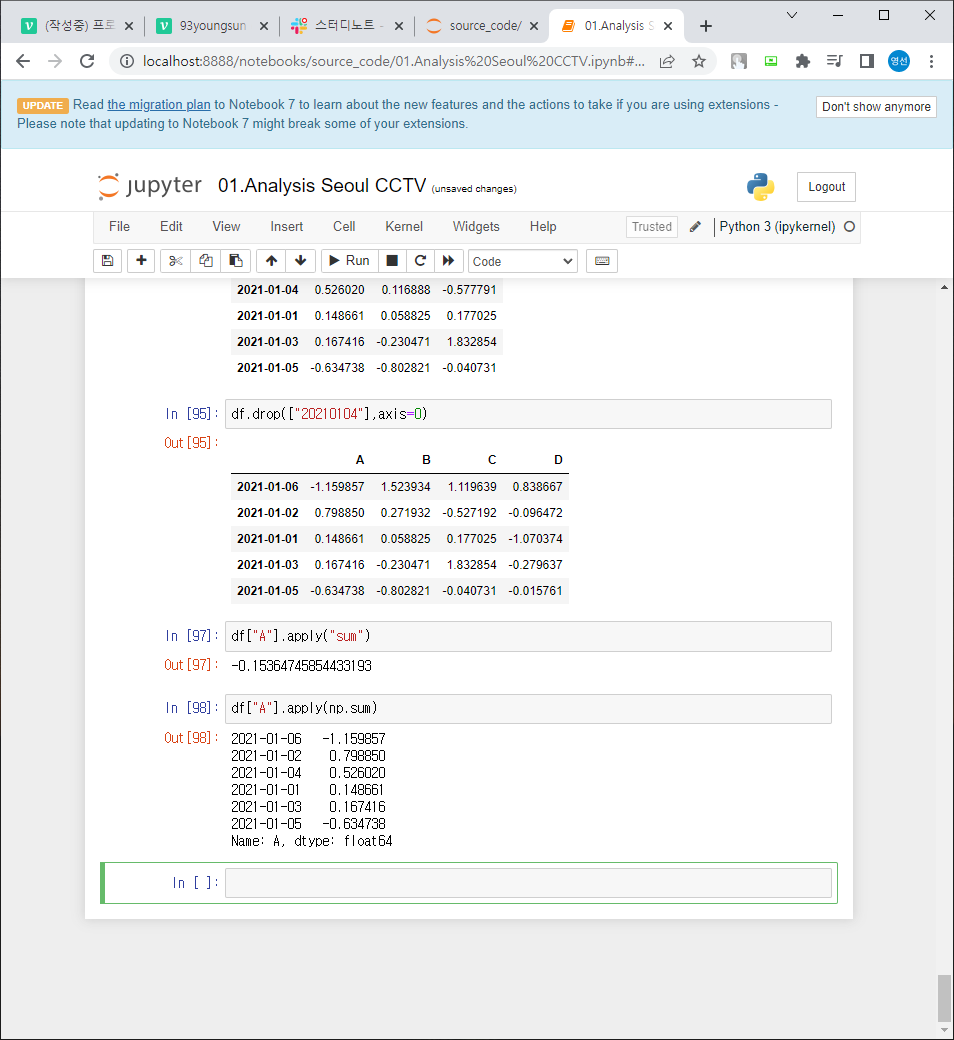
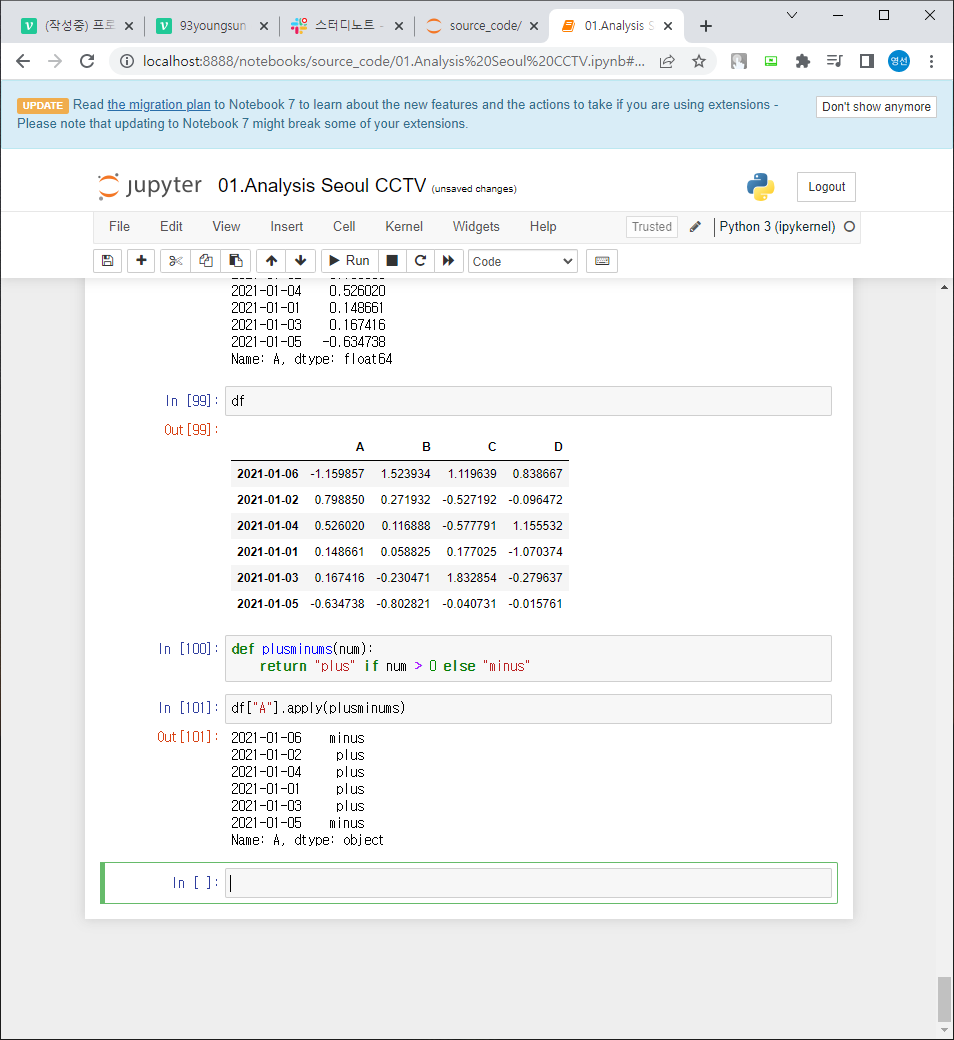
df["A"].apply("sum") # A열 총합 / sum 외에 min최솟값, max최댓값 등 가능
df[["A","D"]].apply("sum") 처럼 2개 이상 열 사용 가능
df["A"].apply(np.sum)
apply 사용하면 함수 적용 가능
ex) 음수와 양수 구분하는 함수 생성 후 A열에 적용
마크다운
주피터 노트북에서 # 누르고 글 작성 후 esc, m버튼 누르면
이렇게 표기 가능
