최근 바닐라 자바스크립트로 과제 코드를 작성하다가, 돔에 그려 넣은 li 요소들 중 특정 텍스트 노드를 가진 li 요소를 찾아 제거해야하는 상황을 만났다. id, class, data-attribute... 텍스트 노드가 아니어도 우회할 대안은 많겠지만 텍스트 노드로 선택하는 방법도 있을 것만 같아서 궁금했다.
일단 CSS 셀렉터 목록을 찾아보았으나 딱히 답을 찾지 못했다. 아예 텍스트 노드를 통해 요소를 찾는 방법을 검색하다 보니 document.evalute 이라는 메서드와 XPath 라는 경로 언어를 찾게 되었다. (CSS selector 도 경로 언어의 일종이다.)
XPath & document.evaluate
XPath
"XML Path Language"의 약자로, XML/HTML 유형의 문서에 대해 A 지점에서 B 지점까지의 경로를 표현하는 쿼리 언어
scrapfly
document.evaluate
XPath 표현식을 통해 요소를 선택하기 위한 DOM 인터페이스
MDN
XPath 의 특징
XML 문서 변환기 등 XML 문서를 위해 만들어진 XPath 는 다음과 같은 특징이 있다.
- CSS 셀렉터와 달리 자신, 부모, 자식 등 문서 트리의 어느 방향으로나 탐색이 가능하다.
-ul:has(>li)vs {li/parent::ulorul[child::li]}
li요소의 부모ul요소를 선택하고 싶을 때, CSS Selector는ul: li 요소를 자식으로 가진와 같이 하방 탐색으로 쿼리를 변환해야하지만 xpath는 상하 방향 트리 탐색이 모두 가능하다. - 카운트 값을 나타내는 숫자 타입, 조건식 충족 여부를 나타내는 Bool 타입 등, 단순히 요소를 찾아낼 뿐만 아니라 결과 값을 변환하여 반환할 수 있다.
- 경로에 따라 다르지만 CSS Seletor 보다 성능이 더 빠른 경우도 많다.(고 한다)
예제로 보는 XPath 문법
<div id='container'>
<p id='first-paragraph'>first</p>
<p id='second-paragraph'>second</p>
<ul>
<li>apple</li>
<li>banana</li>
<li>pear</li>
</ul>
</div>XPath :
//div/p[@id="first-paragraph"]
결과 :<p id='first-paragraph'>first</p>
//://문서 내 모든 요소를 선택할 수 있다.div: 노드의 이름을 명시한다./: 현재 위치 기준 자식 노드 경로를 의미한다.li: 노드의 이름을 명시한다.[@id="first-paragraph"]: -@표시로 속성의 이름을 표시하며 해당 속성이 명시한 값과 일치하는지 테스트하는 표현식이다.
XPath :
//p[contains(text(),"second")]
결과 :<p id='second-paragraph'>second</p>
[contains(...)]: 첫번째 인자에 속성 이름을, 두번째 인자에 속성 값을 넘겨 해당 속성의 값이 인자로 넘긴 값을 포함하는지 테스트하는 함수text(): 현재 위치 노드의 텍스트 노드를 추출한다
XPath :
li[contains(text(),"apple")]/../..
결과 :<div id='container'> ... </div>
..: 현재 위치의 부모 노드로의 경로를 의미한다
XPath :
//li[text()="apple"]/following-sibling::li[2]/text()
결과 :pear
일부 기초 패턴을 살펴본 것이고 경로 표현 방법이 무궁무진하다. XPath의 경로 표현을 위한 전체 항목은 W3C 문서에 잘 정리되어 있다.
document.evalute
매개변수와 사용법
document.evaluate(
xpathExpression,
contextNode,
namespaceResolver?,
resultType?,
result?
)- xpathExpression : 경로 표현식을 전달한다.
- contextNode : 탐색을 시작하는 기준 위치가 될 노드를 전달한다.
- namespaceResolver(옵션): 네임스페이스 uri 생성을 위한 함수이며 HTML 문서에서는 비워두는 경우가 일반적이다.
- resultType(옵션) : 반환 값의 데이터 타입을 지정할 수 있다.
- result(옵션) : 결과에 사용할 기존 XPathResult를 지정할 수 있다. 없는 경우 새로운 XPathResult를 생성, 반환한다.
콘텍스트 노드
<body>
<main>
<ul class="main-list">
<li>apple</li>
<li>banana</li>
<li>pear</li>
</ul>
</main>
<aside>
<ul class="side-list">
<li>apple</li>
<li>banana</li>
<li>pear</li>
</ul>
</aside>
</body>문서 구조가 위와 같을 때 contextNode의 역할은 탐색 경로의 기준점을 제공하는 것이다.
contextNode로 사용할 세 가지 범위의 노드를 정의한다.
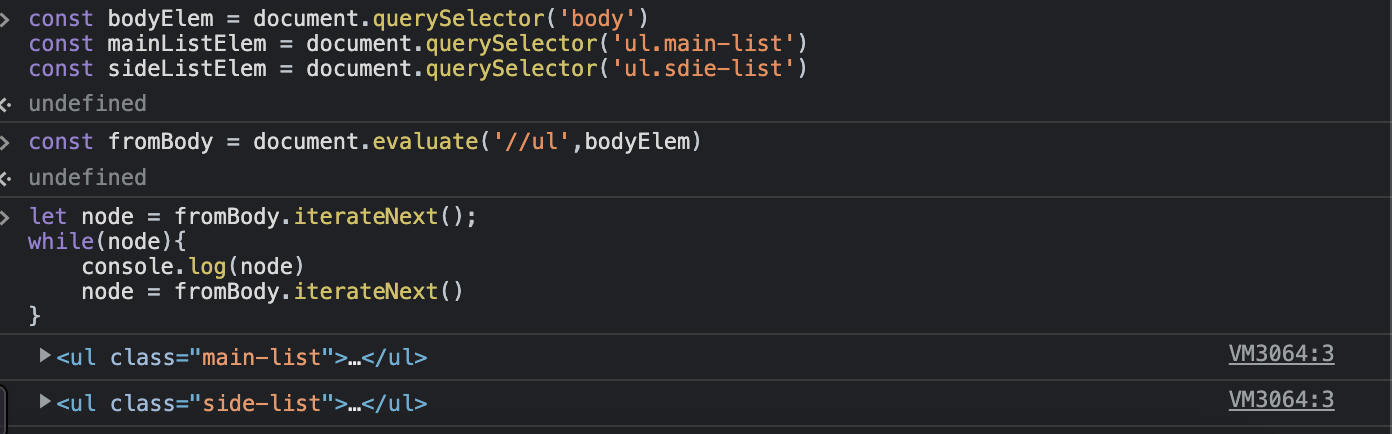
const bodyElem = document.querySelector('body')
const mainElem = document.querySelector('main')
const sideElem = document.querySelector('aside')- contextNode : bodyElem
-
contextNode : mainElem

-
contextNode : sideElem

주의할 점
-
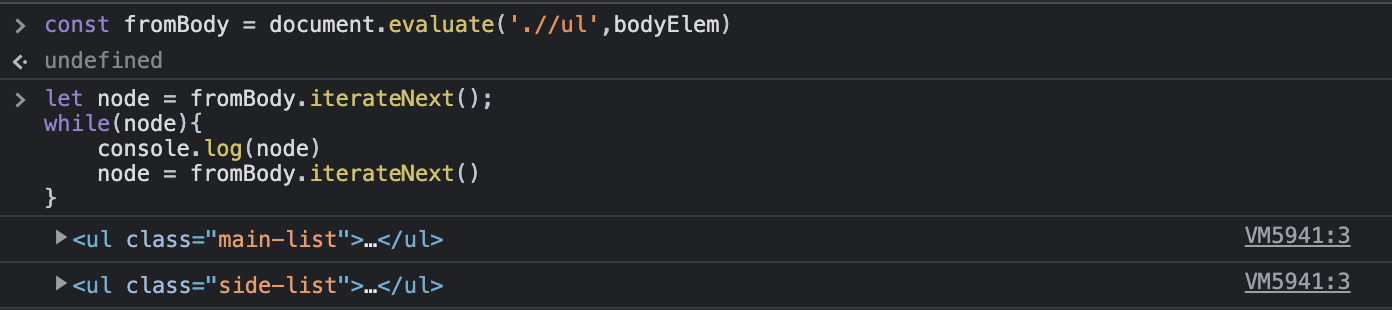
.는 현재 경로를 나타낸다. 만약 콘텍스트노드로 특정 위치의 노드를 명시하더라도 xpath 경로를.없이//등으로 시작하는 경우 콘텍스트노드와 관계없이 문서 전역을 탐색하므로 이 점을 주의한다.
-
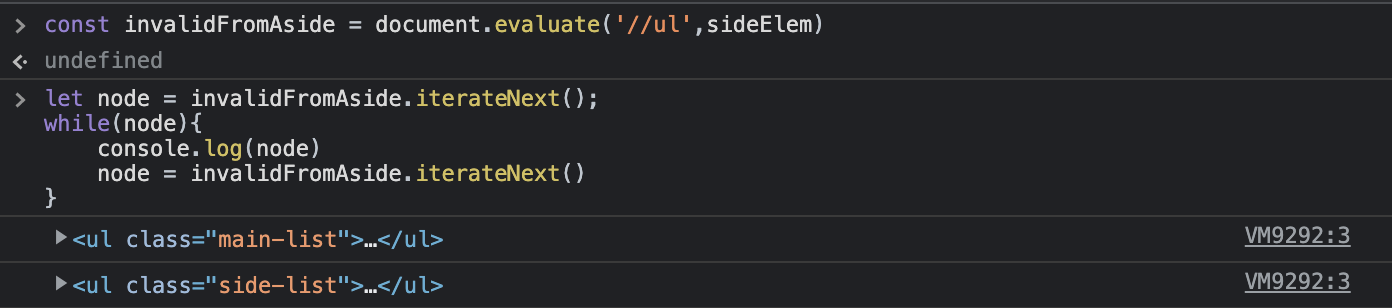
resultType이NODE_ITERATOR_TYPE인 경우iterateNext라는 메서드를 통해 값에 접근하지만 실제로는 iterable 객체가 아니기 때문에 전개연산자를 사용하거나 배열로 변환할 수 없다.
마침
scrapfly - Parsing Html With Xpath
XPath 개념 자체가 낯설고 문법도 낯설어서 이 글, 저 글 검색하다 찾은 페이지인데 관련된 개념들부터 설명하고 있어서 낯가림 해결에 큰 도움을 받았다. 간단한 문법부터 조금 더 복잡한 경로 표현까지 직접 입력하고 결과를 확인할 수 있는 예제 툴까지 제공하고 있어서 가볍게 XPath 찍먹에 관심이 있다면 추천하고 싶은 Scrapfly의 블로그 글!
굳이 CSS Selector를 두고 XPath사용할 필요는 없겠지만, CSSSelector로 원하는 경로를 표현하기 어려운 경우에 사용한다면 답답함을 해소해줄 수 있는 풍부한 접근 방법을 제공하는 것 같다.
근데 생각해보면 리액트를 주로 하니까... 쓸 일이 더더욱 자주 없을 것 같긴 하네. DOM에 이렇게까지 더듬어 직접 접근해야하는 일은 아마 없어야겠죠.
