- 매퍼가 키-값 쌍을 추출
- 셔플과 정렬은 각 고유 키와 연관된 값을 구조화
- 리듀서는 구조화된 정보를 전달받아 최종 출력물을 생산
MapReducer in Hadoop
정말 큰 데이터 세트를 가진 클러스터를 운영하고 있다고 가정하면, 처리 과정을 여러 컴퓨터에 배분하거나 적어도 여러 작업(task)에 걸쳐 진행해야만 한다.
같은 컴퓨터 안에서 다른 프로세스나 컨테이너를 실행할 수도 있다는 것. 혹은 컴퓨터 여러 대에 걸쳐 분배했을 수도 있다
예를들어 3개의 노드에 나눠 매핑한다고 가정한다면, 데이터를 가져오며 세 부분으로 나눠 각각의 노드에 분배함
분산처리가 가능한 이유
- 매핑 단계에서는 다른 노드 있는 줄을 신경쓰지 않아도 됨으로 작업을 병렬화하기에 수월.
- 입력 데이터 한 덩어리를 한 컴퓨터에서 매핑하고 다른 덩어리는 또 다른 컴퓨터에서 동시에 매핑한다면 Hadoop은 이 작업이 끝나면 정보를 받아오기만 하면 됨.
셔플과 정렬 과정에서 분산처리는?
셔플과 정렬 과정을 여러 노드로 나눠 작업을 하게 된다면, 다른 노드에서 같은 키 값이 나올 수도 있다. 이를 같은 키끼리 모아 리듀서로 보내야하는데 어떻게 하는걸까
예를 들어 ID=1의 사용자의 값이 두 노드에 걸쳐있고 셔플과 정렬 작업에서 이 둘은 함께 집계되게 되는데 MapReduce가 이 작업을 대신 수행한다. 네트워크를 활용하여 여러 노드들간 데이터를 보내는 방식을 사용하지 않음. 대신 이 모든 데이터를 merge sort하게 된다.
즉 각각의 노드에서 맵퍼를 통해 키-값 구조로 구조화 시킨 후 합병 정렬을 통해 셔츨과 정렬 과정을 수행한다.
MapReducer Architecture
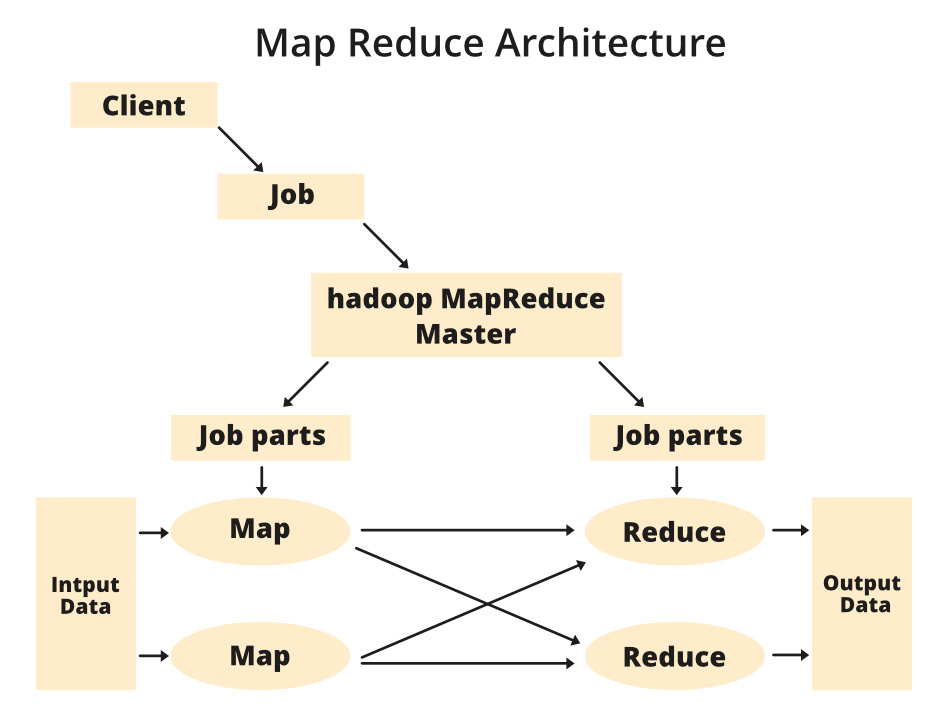
- 클라이언트 노드가 작업을 개시 -> MapReduce 작업을 지시합
- 클라이언트는 먼저 YARN(job)과 소통 -> 어떤 MapReduce 작업이 필요한지
YARN -> 리소스 교섭자, 어떤 머신에서 무엇을 실행할지 관리. 클러스터의 어떤 머신이 가용하고 어떤 머신의 성능은 얼마인지 등의 정보를 기억
- 데이터를 HDFS나 적절한 분산 파일 시스템에 복사합니다
- 'MapReduce Master'
MapReduce Master는 개별 매핑과 리듀싱 작업을 주시하고 리소스 관리자와 협업해 작업을 클러스터에 걸쳐 배분합니다
