Mesos
- 클러스터의 리소스를 관리하는 또 하나의 방법.
- YARN과 협업이 가능하다.
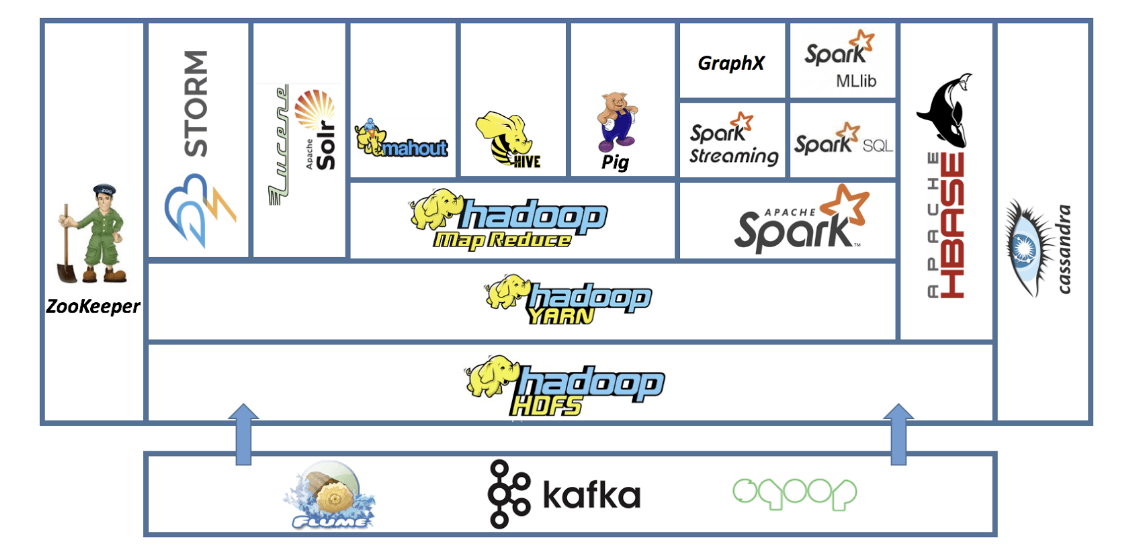
Spark
- Hadoop 생태계에서 가장 흥미로운 기술.
- Spark는 YARN이나 Mesos중 어느 쪽을 기반으로 하든 데이터에 쿼리를 실행할 수 있음.
- Pyhon, Java, Scala를 사용해 스크립트를 작성.
- 클러스터의 데이터를 신속하고 효율적으로 처리가 가능하다.
- 많은 다양성을 갖고있음.
- 클러스터에 걸친 정보로 머신 러닝을 수행하는 SQL쿼리.- 실시간으로 스트리밍되는 데이터를 처리하는 등.
TEZ
- 방향성 비사이클 그래프
- TEZ는 MapReduce의 일을 할 때 더 유리함.- 쿼리실행에 더 효율적인 계획을 세우기 때문.
- Hive와 함께 사용하면 성능을 극대화 시킬 수 있음.
HBASE
- HBASE는 클러스터의 데이터를 트랜잭션 플랫폼으로 노출하는 역할을 하며 NoSQL 데이터베이스라고 불린다.
- 기둥형 데이터 스토어
- 단위 시간당 실행되는 트랜잭션의 수가 큰 아주 빠른 데이터베이스- 데이터를 웹 애플리케이션이나 웹사이트에 노출시켜 OLTP 트랜잭션을 하는데 적합하다.
- HBASE는 클러스터에 저장된 데이터를 노출시킨다.
- 데이터는 Spark나 MapReduce 등에 의해 전환되었을 수도 있고 후에 그 결과를 다른 시스템에 노출시킬 빠른 방법을 제공한다.
Apache STORM
- STORM은 스트리밍 데이터를 처리하는 방식.
- 센서나 웹로그로부터 데이터를 스트리밍 한다면 STORM이나 'Spark Streaming'을 통해 실시간으로 처리할 수 있다.
- 일괄로 처리할 필요가 없음.
- 데이터가 실시간으로 입력됨에 따라 실시간으로 '기계 학습'을 업데이트하거나 데이터를 데이터베이스에 저장할 수 있다.
OOZIE
- OOZIE는 일정에 따라 작업을 순차적으로 진행할 수 있도록 스케줄링.
예를 들어 데이터를 Hive에 불러와서 Pig를 통해 통합하고 Spark를 통해 쿼리한 후에 결과를 HBASE로 변환시킨다고 하면 OOZIE가 이 모든 것을 관리해 안정적이고 일관성 있게 실행할 수 있다.
