이번 프로젝트의 구성은 Stockfish를 활용하여 Chess engine과의 대결을 할 수 있는 사이트와, chess 기보를 읽어들이는 data pipeline, 그 데이터를 저장하는 data warehouse를 구성하는 것이 목표.
Why Chess?
평소 체스와 바둑 장기 등 여러 보드게임을 즐겨하는 중에 체스에 대한 매력을 느껴 여러 사이트를 전전하던 중 사람들과 대결한 기보를 체스 엔진에다가 분석을 맡기는 기능을 유료로 서비스하는 사이트들이 많았다.
물론 lichess같이 무료로 모든 것을 제공하는 사이트도 있지만, datapipeline을 구축해보고 엄청난 data(약 1.2TB)를 다뤄볼 수 있다는게 엄청난 매력 아닌가.
이번 프로젝트를 통해 대용량 데이터를 관계형 데이터베이스(MYSQL, POSTGRESSQL)과 NoSQL(MongoDB, HBASE)를 활용해서 대용량 데이터베이스에서 빠른 쿼리 응답을 수행할 수 있도록 하는 것으로 목표를 잡았다.
(이 데이터를 활용해서 여러 기능들을 추가하는것은 덤.)
Chess Data
모든 체스 데이터는 lichess.data에서 가져왔음. 오픈소스고 무료!
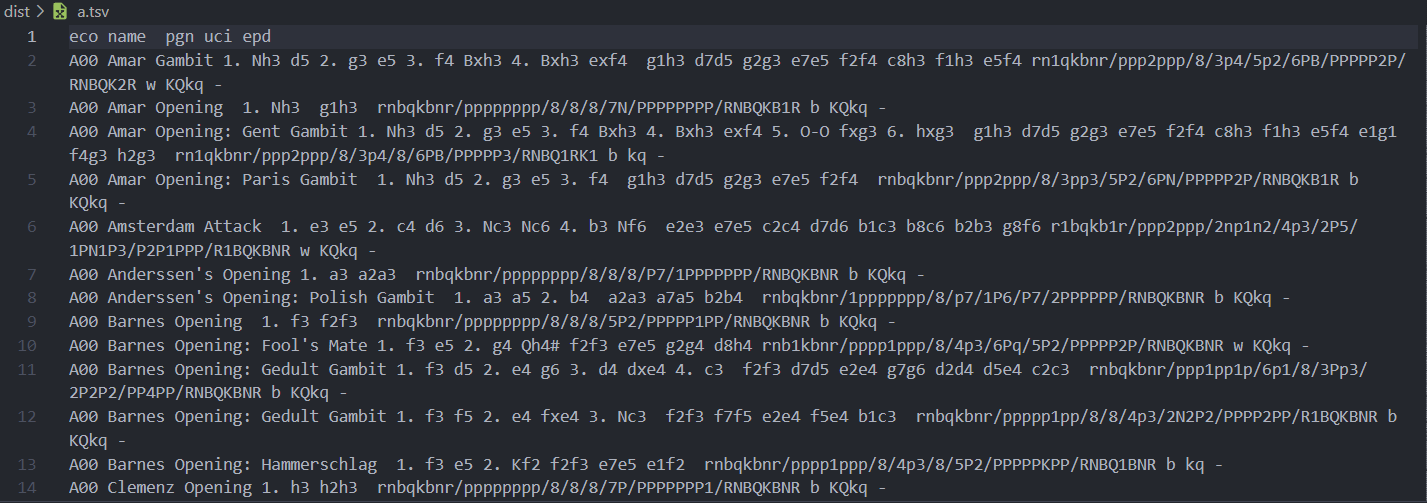
이번 포스트는 체스 오프닝 데이터를 처리하고 데이터베이스에 저장하는 포스팅을 해보겠다.
lichess에서 제공해주는 체스 오프닝 데이터는 5개의 tsv파일로 이루어져 있고

dataframe으로 나타내면 이렇다.
import pandas as pd
data = pd.read_csv(fpath, sep="\t")
print(data)데이터 수집을 용이하게 하기 위해 5개의 tsv파일을 합쳐주자
data = pd.read_csv(fpath, sep="\t")
k = ['b','c','d','e']
for i in k:
fpath = <filepath>
sub = pd.read_csv(fpath, sep='\t')
data = pd.concat([data, sub])
data.to_csv(<path>/<to>/<store>, sep='\t')pandas를 활용하여 간단하게 tsv파일을 합칠 수 있다.
Chess opening Pipeline
기본적으로 데이터를 저장하는 구조는 business process model의 구조를 활용 할 생각이다.
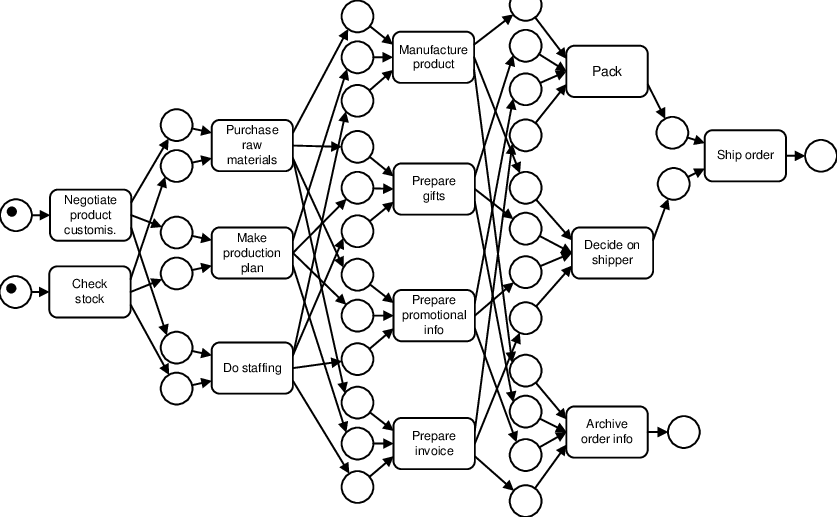
비지니스 프로세스 모델을 한줄로 설명하면 시작에서 완료까지 계획된 비즈니스 프로세스의 단계를 모델링하는 흐름도 메소드.
lichess에서 제공하는 오프닝 데이터의 기보를 살펴보면,
체스는 검은색, 흰색 플레이어가 번갈아가면서 한 수씩 두는 게임으로
1. 뒤에 Nh3는 흰색이 d5은 검은색이 둔 수이다. 비지니스 프로세스 모델처럼 시작과 끝이 있고 순차적인 데이터인걸 확인 할 수 있다.
한 줄의 데이터만 본다면 위의 프로세스 모델처럼 될 수 없지만, 여러개의 데이터를 조합하면 위의 모델을 도출할 수 있다.
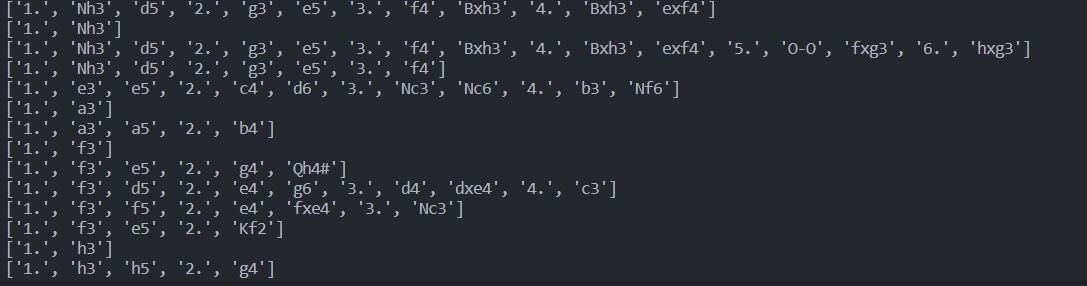
Feature of chess opening data
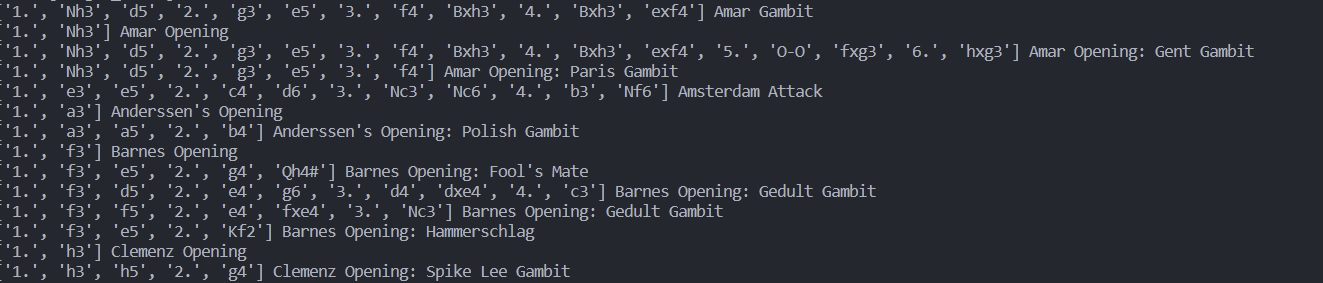
위의 사진은 체스 오프닝 데이터의 일부이다.
['1.', 'Nh3', 'd5', '2.', 'g3', 'e5', '3.', 'f4', 'Bxh3', '4.', 'Bxh3', 'exf4'] Amar Gambit
['1.', 'Nh3'] Amar Opening
['1.', 'Nh3', 'd5', '2.', 'g3', 'e5', '3.', 'f4', 'Bxh3', '4.', 'Bxh3', 'exf4', '5.', 'O-O', 'fxg3', '6.', 'hxg3'] Amar Opening: Gent Gambit
['1.', 'Nh3', 'd5', '2.', 'g3', 'e5', '3.', 'f4'] Amar Opening: Paris Gambit
['1.', 'e3', 'e5', '2.', 'c4', 'd6', '3.', 'Nc3', 'Nc6', '4.', 'b3', 'Nf6'] Amsterdam Attack
['1.', 'a3'] Anderssen's Opening
['1.', 'a3', 'a5', '2.', 'b4'] Anderssen's Opening: Polish Gambit
데이터들의 한가지 공통점은 특정 부분을 기점으로 오프닝의 이름이 바뀐다는 것.
- ['1.', 'Nh3'] Amar Opening
Nh3로 시작되는 오프닝은 Amar Opening이라는 이름이 붙고 위의 예시 데이터에서 Nh3로 시작되는 오프닝은
Amar Gambit, Amar Opening: Gent Gambit, Amar Opening: Paris Gambit이 존재한다.
그리고 이들 간 f4이후 분기가 나뉘고 Bxh3이후엔 완전히 나눠진다.
Nh3로 시작되는 다른 이름이 오프닝도 있지만 위의 예시처럼 특정 분기에서 나뉘어 진다는 특징이 있다.
PreProcessing Opening Data
lichess에서 제공한 chess opening dataset에서 우리는 png, name, epd 컬럼을 추출하여 우리가 원하는 방식대로 변경하여 csv로 저장할 것이다.
#pipline.py
from .utils import *
class ChessOpeningPipeline:
def data_preprocessing(self, fpath):
return import_data_csv(fpath=fpath)
def export_to_csv(self, fname, data):
data.to_csv(f'C:\\Users\\aaa57\\chess\\dist\\{fname}.csv')
return
#utils.py
import pandas as pd
def import_data_csv(fpath, sep = '\t'):
data = pd.read_csv(fpath, sep=sep)
df = split_data(data)
df = pd.DataFrame(df, columns=['pgn','name','epd'])
return df
def split_data(data):
df = []
for i in data.index:
val = data.loc[i, 'pgn'].split(' ')
name = data.loc[i, 'name']
epd = data.loc[i,'epd']
k = _revmove_number(val)
df.append([k,name,epd])
df.sort(key=lambda x: len(x[0]))
return df
def _revmove_number(value):
a = list(filter(None ,map(_is_number, value)))
return a
def _is_number(value):
if value.endswith('.'):
return
else:
return value
#data_processor.py
from .pipelines import ChessOpeningPipeline
class DataProcessor:
def data_processor():
k = ChessOpeningPipeline()
return k간단한 코드 몇줄로 데이터를 정제할 수 있었는데, pipeline과 data_processor를 따로 정의한 이유는 후에 django에서 사용하기 위함.
,pgn,name,epd
0,['Nh3'],Amar Opening,rnbqkbnr/pppppppp/8/8/8/7N/PPPPPPPP/RNBQKB1R b KQkq -
1,['a3'],Anderssen's Opening,rnbqkbnr/pppppppp/8/8/8/P7/1PPPPPPP/RNBQKBNR b KQkq -
2,['f3'],Barnes Opening,rnbqkbnr/pppppppp/8/8/8/5P2/PPPPP1PP/RNBQKBNR b KQkq -
3,['h3'],Clemenz Opening,rnbqkbnr/pppppppp/8/8/8/7P/PPPPPPP1/RNBQKBNR b KQkq -
4,['g4'],Grob Opening,rnbqkbnr/pppppppp/8/8/6P1/8/PPPPPP1P/RNBQKBNR b KQkq -
5,['g3'],Hungarian Opening,rnbqkbnr/pppppppp/8/8/8/6P1/PPPPPP1P/RNBQKBNR b KQkq -
6,['h4'],Kádas Opening,rnbqkbnr/pppppppp/8/8/7P/8/PPPPPPP1/RNBQKBNR b KQkq -
7,['d3'],Mieses Opening,rnbqkbnr/pppppppp/8/8/8/3P4/PPP1PPPP/RNBQKBNR b KQkq -
8,['b4'],Polish Opening,rnbqkbnr/pppppppp/8/8/1P6/8/P1PPPPPP/RNBQKBNR b KQkq -
9,['c3'],Saragossa Opening,rnbqkbnr/pppppppp/8/8/8/2P5/PP1PPPPP/RNBQKBNR b KQkq -
10,['Na3'],Sodium Attack,rnbqkbnr/pppppppp/8/8/8/N7/PPPPPPPP/R1BQKBNR b KQkq -이제 체스 오프닝 데이터를 프로세스화 시기키위한 준비는 다 되었다.
다음 포스팅은 django orm과 database를 활용하여 이 데이터를 저장하고 쿼리를 하는 포스팅을 할 예정.
