모던 자바 인 액션 6장을 학습하고 정리한 내용입니다.
6장 스트림으로 데이터 수집
앞에서는 스트림을 List 또는 단순한 결과(sum, max 등)로 처리한 결과만 확인했다.
Stream에 toList를 사용하는 대신, 더 범용적인 컬렉터 파라미터를 collect 메서드에 전달함으로써 연산을 간결하게 구현할 수 있다.
6.1 컬렉터란 무엇인가?
collect 메서드에 Collector인터페이스 구현체를 전달함으로써 스트림 요소를 어떤 식으로 도출할지 지정한다. (지금까지는 Collector.toList()만 사용했었다)
6.1.1 고급 리듀싱 기능을 수행하는 컬렉터
스트림에 collect를 호출하면 스트림의 요소에, 컬렉터로 파라미터화된 리듀싱 연산이 수행된다.
collect에서는 리듀싱 연산을 이용해서 스트림의 각 요소에 방문하면서 컬렉터가 작업을 처리한다.
collector인터페이스의 메서드를 어떻게 구현하느냐에 따라 스트림에 어떤 리듀싱 연산을 수행할지 결정된다.
6.1.2 미리 정의된 컬렉터
미리 정의된 컬렉터인 Collectors에서 제공하는 메서드의 기능은 크게 세 가지로 구분된다.
- 스트림 요소를 하나의 값으로 리듀스하고 요약 (리듀싱, 요약)
- sum, max 등 다양한 계산을 수행할 때 사용
- 요소 그룹화 (그룹화)
- 그룹화, 서브그룹에 추가로 리듀싱 연산을 적용
- 요소 분할 (분할)
- Predicate를 그룹화 함수로 사용
6.2 리듀싱과 요약
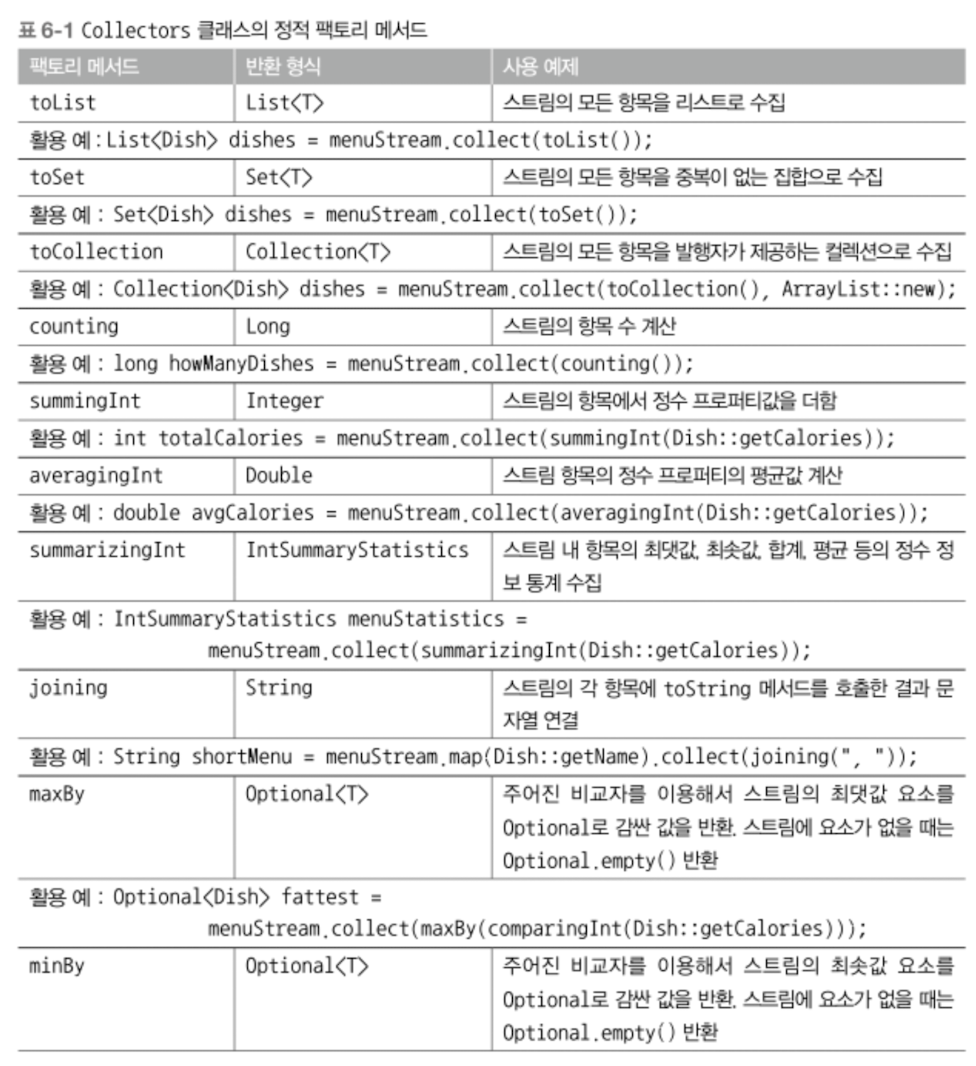
다음에 사용되는 메서드들은 Collectors 클래스의 정적 팩토리 메서드이다.
6.2.1 스트림값에서 최댓값과 최솟값 검색(maxBy, minBy)
Comparator<Dish> dishCaloriesComparator = Comparator.comparingInt(Dish::getCalories);
Optional<Dish> mostCalorieDish = dishes.stream().collect(maxBy(dishCaloriesComparator))6.2.2 요약 연산 (summingInt, avgeragInt, summerizeInt)
객체의 숫자 필드의 합계, 평균 등을 구하는 연산을 요약 연산이라고 부른다.
int totalCalories = dishes.stream().collect(Collectors.summingInt(Dish::getCalories)); // int 합
double totalCalories = dishes.stream().collect(Collectors.summingDouble(Dish::getCalories)); // double 합
double avgCalories = dishes.stream().collect(avgeragInt(Dish::getCalories)); // int 평균
long avgCalories = dishes.stream().collect(avgeragLong(Dish::getCalories)); // long 평균
// count, sum, min, avg, max 정보가 들어있는 객체
IntSummaryStatistics statistic = dishes.stream().collect(summerizeInt(Dish::getCalories));6.2.3 문자열 연결 (joining)
스트림의 각 객체에 toString을 호출한 결과를 하나의 문자열로 합침
// 각 Dish객체의 toString을 실행한 결과를 합침
String shrotMenu = dishes.stream().collect(joining());
// 구분자 추가 가능
String shrotMenuWithSeperator = dishes.stream().collect(joining(", "));내부적으로 StringBuilder를 사용해서 문자열을 만든다.
6.2.4 범용 리듀싱 요약 연산 (reducing)
앞서 살펴본 메서드들은 전부 Collectors.reducing으로 구현할 수 있다.
reducing은 파라미터 세 개를 사용한다.
int totalCalories = dishes.stream().collect(reducing(0, Dish::calories, (i, j) -> i + j));1. 첫 번째 파라미터: 연산 시작값 or (스트림이 비어있을 때) 반환값
2. 변환 함수
3. BinaryOperator또는 하나만 사용할 수도 있다.
Optional<Dish> mostCalories = dishes.stream().collect(
reducing((d1, d2) -> d1.getCalories() > d2.getCalories() ? d1 : d2)
);메서드 참조를 사용하면 코드를 단순화 할 수 있다.
int totalCalories = dishes.stream().collect(reducing(0, Dish::calories, Integer::sum));
// 5장에서 배운 방식
int totalCalories = dishes.stream().map(Dish::getCalories).reduce(Integer::sum).get();6.3 그룹화 (groupingBy)
함수형을 이용해서 가독성 있는 그룹화를 구현할 수 있다.
Map<Dish.Type, List<Dish>> = dishesByType = dishes.stream()
.collect(Collectors.groupingBy(Dish::getType));
// {FISH=[a, b], OTHER=[c,d], MEAT=[e,f]}public enum CaloricLevel = {DIET, NORMAL, FAT}
// 칼로리 기준별로 메뉴를 그룹화
MAP<CaloricLevel, List<Dish>> dishesByCaloricLevel = dishes.stream()
.collect(Collectors.groupingBy(dish -> {
int calorie = dish.getCalories();
if (calorie <= 400) return DIET;
else if (calorie <= 700) return NORMAL;
else return FAT;
}))6.3.1 그룹화된 요소 조작 (filtering, mapping, flatMapping)
문제: 그룹화를 유지한 상태로, 칼로리가 500이하인 메뉴만 보고 싶다.
// 시도1: groupingBy + filter
Map<Dish.Type, List<Dish>> map = dishes.stream()
.filter(dish -> dish.getCalories > 500)
.collect(groupingBy(Dish::getType));
// 결과: {OTHER=[c,d], MEAT=[e,f]}
// 문제: Fish에는 칼로리가 500미만인 메뉴가 없어서, 아얘 키 자체가 추가되지 않았다.groupingBy는 두번째 인자로 Predicate를 추가해 필터링 조건을 추가할 수 있다.
Map<Dish.Type, List<Dish>> map = dishes.stream()
.collect(groupingBy(
Dish::getType,
Collectors.filtering(dish -> dish.getCalories() > 500,
toList())));
// 결과: {FISH=[], OTHER=[c,d], MEAT=[e,f]}용도에 따라 Mapping을 사용할 수도 있다.
Map<Dish.Type, List<Dish>> map = dishes.stream()
.collect(groupingBy(
Dish::getType,
Collectors.mapping(Dish::getName, toList())));
// {FISH=[고등어조림], OTHER=[애플파이], MEAT=[소고기구이]}Map의 value가 List인 경우, 원하는 결과를 얻기위해선 평면화를 진행해야 한다.
menu.stream()
.collect(groupingBy(Dish.Type, flatMapping(dish -> dishTags.get(dish.getName()).stream(),
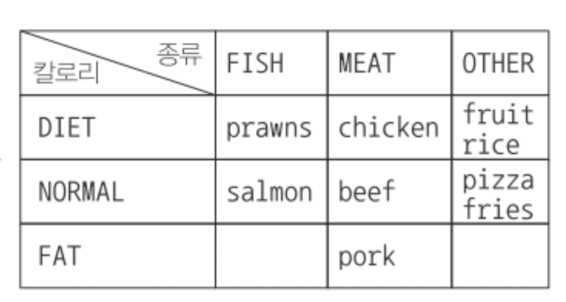
toSet()));6.3.2 다수준 그룹화 (groupingBy 중첩)
groupingBy를 여러개 사용해서 그룹화 기준을 추가할 수 있다.
Map<Dish.Type, Map<CaloricLevel, List<Dish>>> dishesByTypeCaloricLevel =
menu.stream()
.collect(
groupingBy(
Dish::getType,
groupingBy(dish -> {
int calorie = dish.getCalories();
if (calorie <= 400) return DIET;
else if (calorie <= 700) return NORMAL;
else return FAT;
})
)
// 다음과 같은 형태의 결과를 얻을 수 있다
{
MEAT={DIET=[chicken], NORMAL=[beef], FAT=[port]},
FISH={DIET=[prawns], NORMAL=[salmon]},
OTHER={DIET=[rice], NORMAL=[french fries]}
}
6.3.3 서브그룹으로 데이터 수집 (counting)
개수 새기
List<String> strings = List.of("a", "b", "a", "c", "c", "c");
Map<String, Long> collect = strings.stream().collect(Collectors.groupingBy(String::valueOf, Collectors.counting()));
// {a=2, b=1, c=3}groupingBy(f) == groupingBy(f, toList())
만약 groupingBy의 인자로 기준 역할을 하는 파라미터 하나만 주면, groupingBy(f, toList())로 작동한다.
List<String> strings = List.of("a", "b", "a", "c", "c", "c");
Map<String, List<String>> collect = strings.stream().collect(Collectors.groupingBy(String::valueOf));
// {a=[a, a], b=[b], c=[c, c, c]}각 그룹의 최댓값 (maxBy, collectingAndThen)
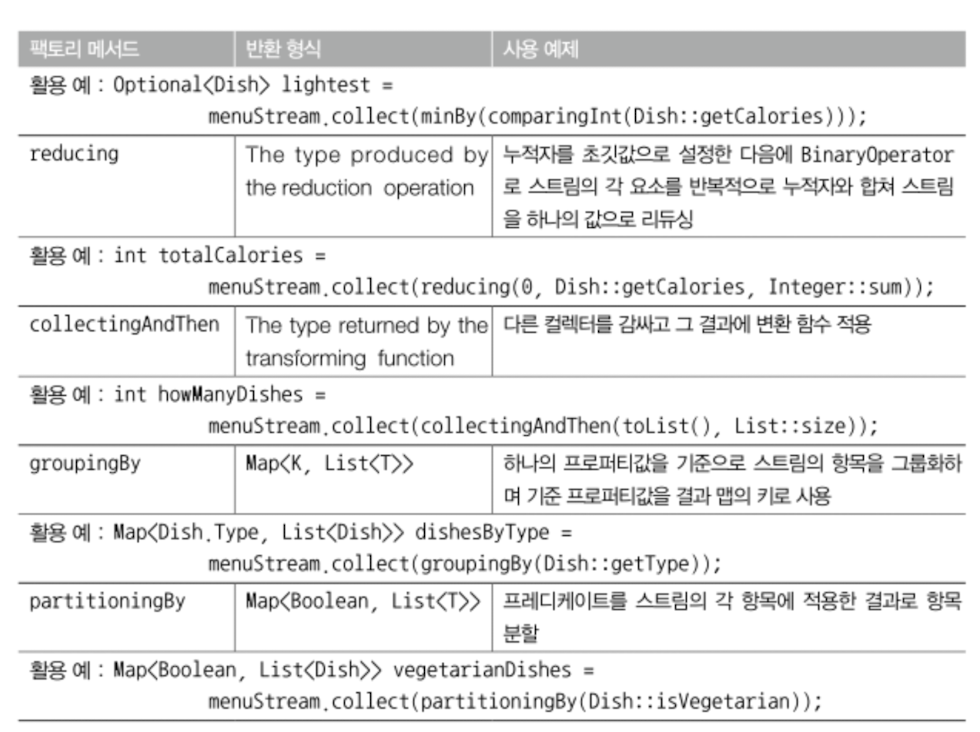
Map<Dish.Type, Optional<Dish>> mostCalories = dishes.stream()
.collect(groupingBy(Dish::getType, maxBy(comparingInt(Dish::getCalories))));
// {Fish=Optional[salmon], OTHER=Optional[pizza], MEAT=Optional[pork]}맵의 모든 값을 Optional로 감싸기 싫으면 collectingAndThen을 사용한다
Map<Dish.Type, Dish> mostCalories =
dishes.stream()
.collect(groupingBy(
Dish::getType,
// 첫 번째 파라미터로 전달받은 함수로 처리 한 뒤, 각 결괏값을 두 번째 파라미터로 처리한다.
collectingAndThen(maxBy(comparingInt(Dish::getCalories)), Optional::get)
)
);collectingAndThen은 적용할 컬렉터와 변환 함수를 파라미터로 받은 뒤, 다른 컬렉터를 반환한다.
각 그룹별 총합 구하기 (summingInt, groupingBy + mapping)
// 방법1: summingInt 사용
Map<Dish.Type, Integer> totalCaloriesByType = dishes.stream()
.collect(groupingBy(Dish::getType, summingInt(Dish::getCalories)));
// 방법2: grouping + mapping 사용
Map<Dish.Type, Integer> totalCaloriesByType = dishes.stream()
.collect(groupingBy(
Dish::getType,
mapping(dish -> {
int calories = dish.getCalories();
if (calories <= 400) return DIET;
else if (calories <= 700) return NORMAL;
else return FAT;
},
toSet()
)
));6.4 분할 (partitioningBy)
Boolean으로 표현할 수 있는 두 집합으로 분할할 수 있다.
파라미터로 Predicate를 사용한다.
EX) 채식인 요리와 채식이 아닌 요리로 분할하기
Map<Boolean, List<Dish>> partition = dishes.stream().collect(partitioningBy(Dish::isVegetarian));
// {flase=[...], true=[...]}
List<Dish> vegetarianDishes = parition.get(true);
// 동일한 결과
List<Dish> vegetarianDishes = menu.stream().filter(Dish::isVegetarian).collect(toList());6.4.1 분할의 장점
- 두 그룹으로만 분할 =>
negate로 반대 결과값을 얻을 수 있다. - partitionBy는 파라미터 2개를 받을 수 있도록 오버로딩됨 -> 컬렉터를 두 번째 파라미터로 전달해서 결괏값 형태 지정 가능
// '채식'으로 분할 후, 타입으로 별로 그룹핑
Map<Boolean, Map<Dish.Type, List<Dish>>> vegetarianDishesByType = dishes.stream()
.collect(
partitioningBy(
Dish::isVegetarian,
groupingBy(Dish::getType)
)
);
// 결과는 다음과 같다.
{
false = {
FISH=[p,s],
MEAT=[p, b, c]
},
true = {
OTHER=[r,s,p]
}
}
// '채식'으로 분할 후, 각 분할의 칼로리 최댓값
Map<Boolean, Dish> = dishes.stream()
.collect(
partitioningBy(
Dish::isVegetarian,
collectingAndThen(
maxBy(comparingInt(Dish::getCalories)),
Optional::get
)
)
);
// 결과는 다음과 같다
{
false = P,
true = r
}6.4.2 숫자를 소수와 비소수로 분할하기
// 소수 판단 Predicate
public Boolean isPrime(int number) {
// 2이상 number미만의 숫자 중, 나누어 떨어지는 숫자가 없으면 소수
// 제곱근 이하로 개선 가능
return IntStream.range(2, number).noneMatch(i -> number % i == 0);
}
// 숫자 스트림
Map<Boolean, List<Integer>> partition = IntStream.rangeClose(2, n).boxed()
.collect(
partitioningBy(c -> isPirme(c))
);6.4.a 중간 정리
모든 컬렉터는 Collector 인터페이스를 구현한다.
6.5 Collector 인터페이스
6.6 커스텀 컬렉터를 구현해서 성능 개선하기
추후 정리....
