Spring Data JPA 설정
Spring Boot를 사용하지 않는 상황이면 다음과 같이 설정해야 한다.
@SpringBootApplication
@EnableJpaRepositories(basePackages = "Data jpa인터페이스가 위치한 패키지 경로명")
public class Appliction {
...
}스프링 부트를 사용하면 따로 설정하지 않아도 된다.
맛보기
import com.example.demo.entity.Member;
import org.springframework.data.jpa.repository.JpaRepository;
public interface MemberRepository extends JpaRepository<Member, Long> {
}인터페이스를 정의해 놓고, 이를 사용하면 마치 구현체를 사용하는 것 처럼 사용할 수 있다.
Spring Data JPA가 Proxy 기술을 사용해서 자동으로 구현체를 만든뒤 주입하는 것이다.
@Repository를 붙이지 않아도 Spring Data JPA가 알아서 처리해준다.
참고
@Repository는 단순히 Component Scan의 대상으로 등록하는 작업 뿐만 아니라, JPA 예외를 Spring의 공통 예외로 변환하는 작업도 수행한다.
JpaRepository
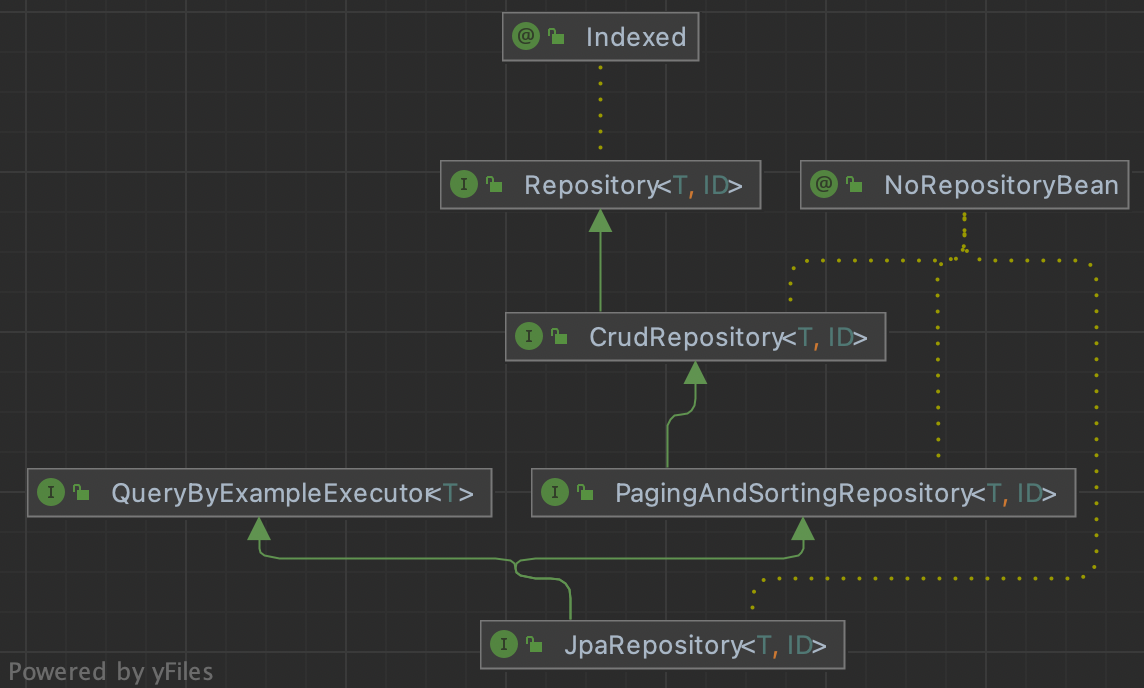
Spring Data의 인터페이스
PagingAndSortingRepository
CrudRepository
Repository
Spring Data JPA의 인터페이스
JpaRepository
JpaRepository는 Spring Data가 제공하는 인터페이스의 JPA 특화 버전이다.
- 기본적인 메서드를 제공한다.
쿼리 메서드기능을 통해 도메인 특화된 메서드를 손쉽게 사용할 수 있다.
쿼리 메서드
도메인 특화된 메서드를 손쉽게 사용하게 하는 기능
1. 메서드 이름으로 쿼리 생성
이름이 일치하고, 특정 나이 이상인 멤버 조회순수 JPA (JQPL)은 다음과 같을 것이다.
public List<Member> findByUsernameAndAgeGreaterThan(String username, int age) {
return em.createQuery(
"SELECT m FROM Member m WHERE m.username = :username AND m.age > :age",
Member.class
).setParameter("username", username)
.setParameter("age", age)
.getResultList();
}Spring Data JPA는 다음처럼 해결 할 수 있다.
public interface MemberRepository extends JpaRepository<Member, Long> {
public List<Member> findByUsernameAndAgeGreaterThan(String username, int age);
}어떠한 구현체도 만들지 않고, 단순히 메서드를 선언했는데 실제로 작동한다.
자세한 사용법은 다음을 참고
쿼리를 직접 작성하지 않아도 되는 장점이 있으나, 다음과 같은 단점도 존재한다.
- 파라미터 개수에 따라 메서드 이름이 너무 길어진다.
- 모든 종류의 쿼리를 만들지는 못한다.
- Entity 필드명이 변경되면 Repository 메서드 이름도 변경해야 한다.
2. 메서드 이름으로 NamedQuery 호출
참고: Named Query
NamedQuery를 EntityManager의 createNamedQuery를 사용하여 사용할 수도 있으나, Spring Data JPA를 사용하면 더 편리하게 사용할 수 있다.
// Member Entity
@Entity
@NamedQuery(
name = "Member.findByUsername"
query = "SELECT M From Member AS m WHERE m.username = :username"
)
public class Member {...}
// repository
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query(name = "Member.findByUsername")
List<Member> findByUsername(@Param("username") String username);
}createNamedQuery을 사용하지 않고, Spring Data JPA에서도 NamedQuery를 사용할 수 있다.
@Query를 사용해서 어떤 NamedQuery를 사용할 지 명시하고,
@Param을 사용해서 파라미터를 바인딩 한다.
Spring Data JPA의 NamedQuery는 다음의 관례를 따라 실행된다.
- @Query의 name에 명시된 NamedQuery를 찾아서 실행
- @Query가 없는 경우,
Repositry의 대상.메서드_이름으로 된 NamedQuery를 찾아서 실행 - NamedQuery가 없는 경우, 메서드 이름으로 쿼리를 생성
3. @Query을 사용해서 쿼리 직접 정의
@Query에 JPQL를 직접 사용할 수 있다.
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("SELECT m FROM Member m WHERE m.username = :username")
public List<Member> findByUsername(@Param("username") String username);
}NamedQuery와 @Query + JPQL은 크게 다르지 않다.
둘 다 App Loading 시점에 JPQL을 SQL로 미리 파싱하기 때문에, 그 과정에서 SQL 문법 오류를 확인할 수 있다는 장점이 있다.
실무에서는 NamedQuery보다 @Query + JPQL을 더 많이 사용한다고 한다.
@Query로 값, DTO 조회하기
@Query를 사용해서 Entity뿐만 아니라 단순 값도 조회할 수 있다.
@Query("SELECT m FROM Member m")
List<Member> findAll();
@Query("SELECT m.username FROM Member m")
List<String> findAllNames();DTO도 가능하다.
// DTO
@Data
@AllArgsConstructor
public class MemberDto {
private Long id;
private String username;
private String teamName;
}
// Repository
@Query(
"SELECT new 패키지명.MemberDto(m.id, m.username, t.teamName) " +
"FROM Member m JOIN FETCH m.team t"
)
List<MemberDto> findMemberDto();파라미터 바인딩
JQPL은 위치 기반, 이름 기반 파라미터 바인딩을 지원한다.
@Query("SELECT m FROM Member m WHER m.username = :name")
public List<Member> findByUsername(@Param("username") String name);
// Collection기반 IN도 지원한다.
@Query("SELECT m FROM Member m WHER m.username IN :username")
public List<Member> findByUsernames(@Param("username") Collection<String> names);반환 타입
Spring Data JPA는 다양한 반환 타입을 지원한다.
// Collection
List<Member> findByUsername(String name);
// 단 건
Member findByUsername(String name);
// Optional
Optional<Member> findByUsername(String name);
그 외에도 primitive type, Interator, Stream, Page등 다양한 반환 타입을 지원한다.주의사항
- Collection을 사용했는데 조회 결과가 0건이면, null이 아닌 size == 0인 Collection을 반환한다.
- 단 건을 사용했는데 조회 결과가 0건이면, null을 반환한다.
- 순수 JPA는
NoResultException이 발생한다. - Spring Data JPA는 이를 try-catch로 감싼뒤 null을 반환한다.
- 순수 JPA는
- 단 건을 사용했는데 조회 결과가 여러 건이면,
IncorrectResultSizeDataAccessException이 발생한다.- JPA의
NonUniqueResultException이 먼저 발생하고, Spring Data JPA가 이를 Spring Exception으로 변환해서 던진다.
- JPA의
페이징, 정렬
순수 JPA
public List<Member> findByAge(int age, int offeset, int limit) {
return em.createQuery(
"SELECT m FROM Member m WHERE m.age = :age ORDER BY m.username DESC",
Member.class
).setParameter("age", age)
.setFirstResult(offset)
.setMaxResult(limit)
.getResultList();
}요청 페이지 번호에 따라 offset을 계산해야 한다.
Spring Data
Spring Data는 정렬, 페이징을 추상화하여 제공한다.
org.springframework.data.domian.Sort
org.springframework.data.domian.Pageable
org.springframework.data.domain.Page
org.springframework.data.domain.Slice
...public interface MemberRepository extends JpaRepositry<Member, Long> {
Page<Member> findByAge(int age, Pageable pageable);
}위 처럼 인터페이스를 정의하고, 아래 처럼 사용하면 된다.
// PageRequest: 페이징 조건
// Pageable 인터페이스 구현체
// 0번째 페이지 부터, 3개를 가져오는데, 다음의 Sort조건을 사용
PageRequest pageRequest = PageRequest.of(0, 3, Sort.of(Sort.Direction.DESC, "username"))
Page<Member> page = memberRepository.findByAge(10, pageRequest);
// 페이징 쿼리 결과
List<Member> content = page.getContent();
// 총 검색 개수
long totalElements = page.getTotalElements();
// 현재 페이지 번호
int pageNumber = page.getNumber()
// 총 페이지 개수
int totalPageNumber = page.getTotalPages();
// 첫 번째 페이지인가?
boolean isFirst = page.isFirst();
// 다음 페이지가 있는가?
boolean hasNext = page.hasNext();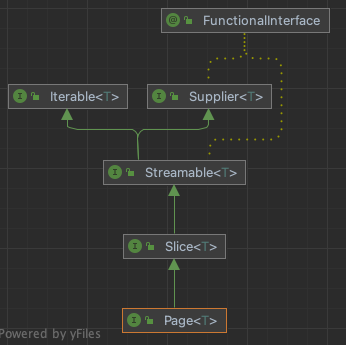
Page, Slice
PageRequest pageRequest = PageRequest.of(0, 3, Sort.of(Sort.Direction.DESC, "username"))
Page<Member> page = memberRepository.findByAge(10, pageRequest);
// findByAge가 Page가 아닌 Slice를 반환해야 함
Slice<Member> slice = memberRepository.findByAge(10, pageRequest);Spring Data는 페이지 번호가 0번 부터 시작한다.
Page는 PageRequest에 따라 페이징 쿼리를 날리고, 총 개수를 구하는 쿼리 또한 알아서 날린다.
Page는 Request에 따라 3개의 데이터를 가져오는 반면, Slice는 추가로 한 개를 더 가져온다.
현재 보여줄 데이터 개수 + 총 데이터 개수를 다루는 Page와 달리,
Slice는 '더보기' 버튼을 눌렀을 때 동적으로 데이터를 Loading하는 기법에서 사용한다.
그렇기 때문에 Slice는 getTotalElements와 같은 메서드를 지원하지 않는다.
PageRequest pageRequest = PageRequest.of(0, 3, Sort.of(Sort.Direction.DESC, "username"))
List<Member> members = memberRepository.findByAge(10, pageRequest);Page, Slice 기능이 필요 없으면 그냥 Collection으로 받으면 된다.
countQuery
반환 타입에 따라 총 개수 쿼리를 날릴지가 결정된다.
Page는 자동 발생
Slice는 발생 X총 개수 쿼리 JOIN이 들어갈 경우, 데이터 개수가 많아질 수록 성능적인 부담이 생긴다.
총 개수 쿼리는 실제 데이터를 불러올 필요가 없다.
그러므로 데이터 조회 쿼리와 총 개수 쿼리를 따로 관리할 필요가 있다.
다음과 같이 분리할 수 있다.
@Query(
value = "SELECT m FROM Member m LEFT JOIN m.team t",
countQuery = "SELECT COUNT(m.username) FROM Member m")
Page<Member> findByAge(int age, Pageable pageable);DTO로 감싸기
Page결과도 DTO로 변환하여 전달해야 한다.
Page<Member> page = memberRepository.findByAge(age, pageRequest);
Page<MemberDto> maped = page.map(p -> new MemberDTO(...));Page가 extends하는 Streamable을 통해 람다 비스무리한 방법을 사용할 수 있다.
Bulk Operation
JPA는 명식적 Update를 사용하지 않고, Dirty Checking을 통해 Update하기를 권장한다.
모든 직원의 나이를 n씩 올려라그런데 위와 같은 작업은 모든 Employee를 불러와서 Dirty Checking으로 하나씩 Update 쿼리를 날릴 필요 없이, Bulk 연산으로 처리하는게 더 효율적이다.
순수 JPA
// 반환값: Update 영향 받은 row 개수
public int bulkAgePlus(int age) {
return em.createQuery(
"Update Member m " +
"SET m.age = m.age + :age"
).setParameter("age", age)
.executeUpdate();
}Spring Data
public interface memberRepository extends JpaRepository<Member, Long> {
@Modifying
@Query("Update Member m SET m.age = m.age + :age")
public int bulkAgePlus(@Param("age") int age);
}@Modifying을 사용하지 않으면 executeUpdate대신에 getResultList, getSingleList가 호출되어서 예외가 발생한다.
주의사항: PC-DB 불일치
Bulk 연산은 Persistence Context를 무시하고 연산을 수행한다.
즉, Persistence Context와 DB간 데이터 불일치가 발생할 수 있다.
memberRepository.save(new Member("name#1", 30));
// PC에는 30살로 저장
memberRepository.bulkAgePlus(20);
// Bulk 연산은 PC를 무시하고 바로 DB에 반영
// DB는 50살, PC는 30인 상황
// PC에서 Entity를 찾아옴
Member member = memberRepository.findByName("name#1").get(0);
sout(member.getAge()); // 30따라서 관습적으로 Bulk 연산을 수행하고 나서 PC를 clear해줘야 한다.
memberRepository.save(new Member("name#1", 30));
// PC에는 30살로 저장
memberRepository.bulkAgePlus(20);
// 혹시 모를 아직 DB에 반영 안된 변경사항 전달
em.flush();
// PC 비우기
em.clear();Spring Data JPA는 간편한 방법을 제공한다.
public interface memberRepository extends JpaRepository<Member, Long> {
@Modifying(clearAutomatically = true)
@Query("Update Member m SET m.age = m.age + :age")
public int bulkAgePlus(@Param("age") int age);
}@Modifying(clearAutomatically = true)로 설정하면 쿼리 발생 이후 자동으로 PC를 clear한다.
Entity Graph
Spring Data JPA의 findAll을 사용하려고 하는데, 연관관계가 Lazy Loading으로 설정되어 있다.
@Query를 사용해서 명시적으로 FETCH JOIN을 사용할 수 있으나, 이러면 Spring Data JPA의 장점을 살리지 못한다.
그러므로 @EntityGraph를 사용한다.
@EntityGraph
@Override
@EntityGraph(attributePaths = {"team"})
List<Member> findAll();@EntityGraph는 이미 존재하는 JQPL에 FETCH JOIN을 추가하는 용도로 사용할 수 있다.
@Query("SELECT m FROM Member m")
@EntityGraph(attributePaths = {"team"})
List<Member> findMemberEntityGraph();쿼리 메서드 - 메서드 이름으로 쿼리 생성 기능에도 사용할 수 있다.
@EntityGraph(attributePaths = {"team"})
List<Member> findByUsername(@Param("username") String username);@NamedEntityGraph
JPA 표준 스펙에 정의된 @NamedEntityGraph를 사용하면, FETCH JOIN으로 불러올 Entity를 미리 정의해 놓을 수 있다. (마치 @NamedQuery 처럼)
// Entity
@Entitty
@NamedEntityGraph(
name = "Member.all",
attributeNodes = @NamedAttributeNode("team")
)
public class Member {...}
// Repository
@EntityGraph("Member.all")
List<Member> findByUsername(@Param("username") String username);참고
FETCH JOIN은 기본적으로LEFT OUTER JOIN을 발생시킨다.
RIGHT JOIN FETCH처럼 Join 방향을 지정할 수도 있다.- 간단한 관계에서만
@EntityGraph를 사용하고, 복잡한 관계에서는@Query에 명시적으로FETCH JOIN을 사용한다.
JPA Hint
SQL이 아닌, JPA 구현체에게 제공하는 힌트를 의미함
예시: readOnly
- JPA는 dirty checking을 위해, snapshot을 저장해 놓고 있음
- 어떤 비즈니스 로직에서 데이터를 조회하는데, 그 데이터에 변경이 일어나지 않을 것이 확실함
- 성능 최적화를 위해, 변경이 일어나지 않을 것이 확실한 경우에는 snapshot을 메모리에 저장하지 말도록 하고 싶음
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true"))
Member findReadOnlyByUsername(String username);주의사항
readOnly로 읽은 데이터를 변경하면 dirty checking이 발생하지 않음- 모든
ReadOnly Operation에 위 내용을 전부 적용하는 건 생산성 측면에서 좋지 못함. 다음 경우에만 적용하길 권장- 엄청 성능이 중요한 API
- 성능 개선이 확실한 상황
JPA Lock
Spring Data JPA에서 Lock을 제공한다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
public List<Member> findLockByUsername(String username);다음과 같은 SQL이 발생한다.
SELECT ...
FROM ...
WHERE member.username = ? FOR UPDATELock에 대한 내용은 따로 다루겠다.
