AWS Tier 0 service ?
Tier 0 service?
Tier 0 (tier zero) is a level of data storage that is faster, and perhaps more expensive, than any other level in the storage hierarchy.
https://www.techtarget.com/searchstorage/definition/Tier-0
개념 정리
Table
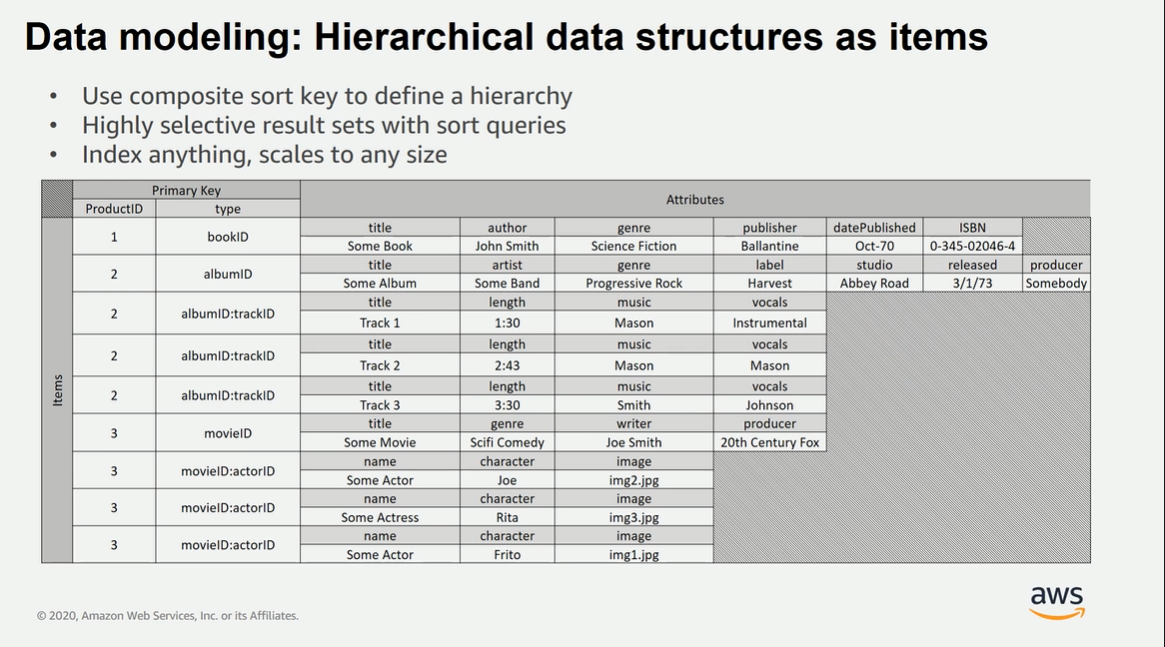
테이블에 저장되는 레코드를 Item
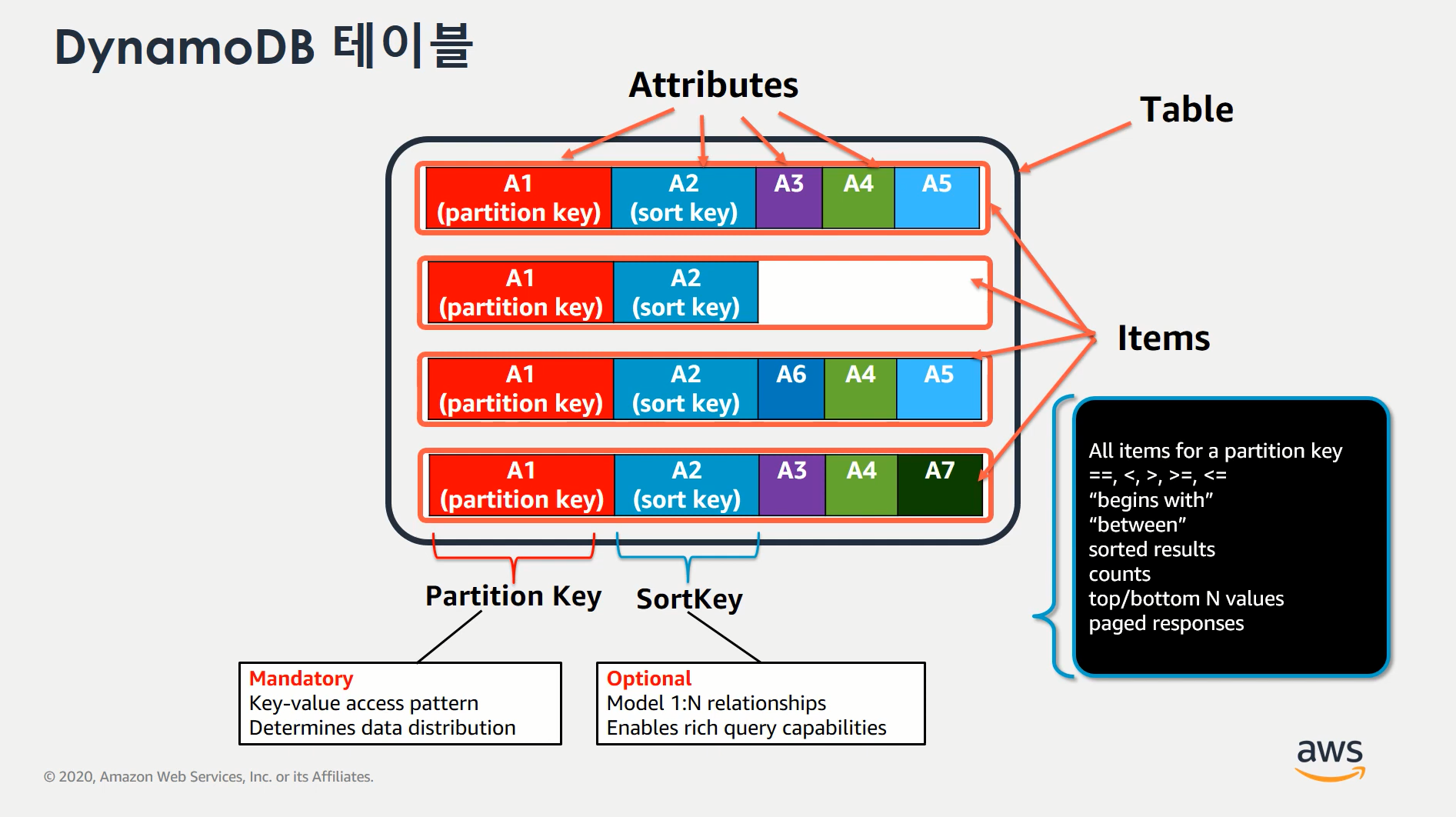
기본적으로 PK에 의해 분산되며 같은 노드에서 sort key로 정렬됨.
Item
내부에서 column이라고 불리는 Attributes로 구성됨
Partition Key
하나의 테이블은 Partition Key로 분리가 됨
그 때문에 반드시 필수적으로 설계 필요
일반적으로 유일성이 있는 사용자 아이디 같은 걸로 함.
=> user 정보라면 사용자 아이디가 유일성이 있는 key
=> 그런데 우리가 만들려고 하는 생육기록 테이블 같은 경우는 유일성이 날짜 ?
=> 아니다 다양한 아이디에서 해당 날짜의 데이터가 생성될 수 있고 심지어 한 아이디에서도 작물이 다른 두개의 데이터도 생성될 가능성은 존재한다.
aws 공식 문서 정리 해주신 블로그
https://hello-world.kr/19
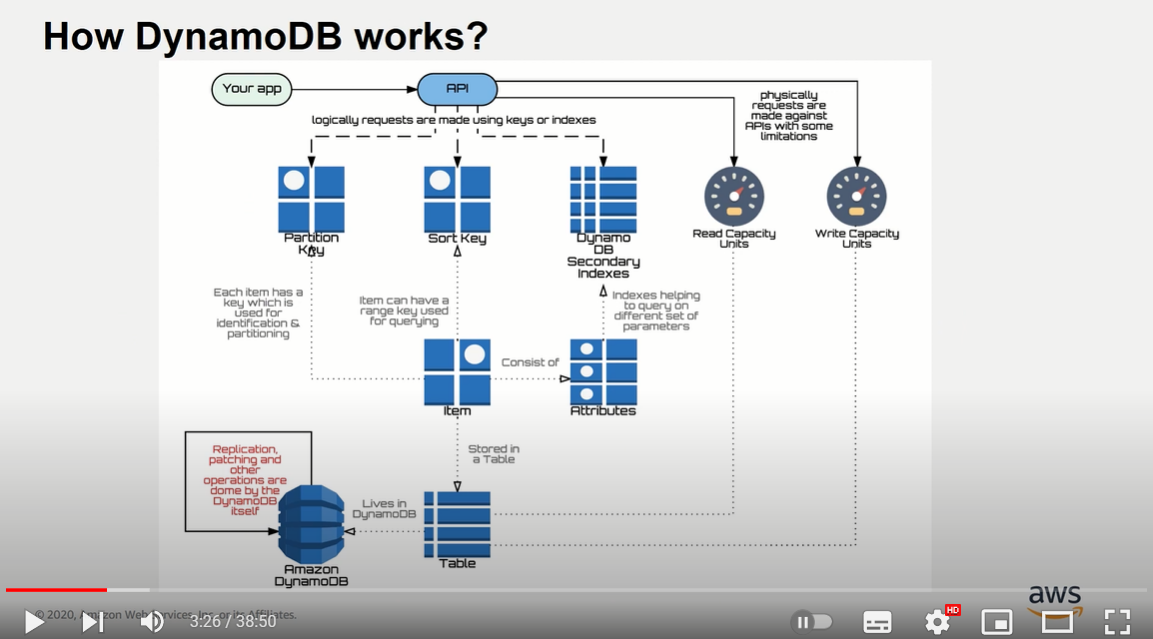
=> Partition Key에 따른 Hash함수에의해 물리적으로 partition된 노드로 저장됨.
=> Partitioning 은 Partition 별로 동일한 Capacity Unit을 제공받기 때문에 균등한 요청, 크기로 Partition 할당이 중요하다. 이를통해 데이터의 분산이 필요하다.
=> DynamoDB의 성능은 RCU(Read Capacity Units)와 WCU(Write Capacity Units)에 의해 결정됨.
=> 고로 우리 시스템에서는 팀으로 대표되는 UserId가 적절.
=> 팀으로 ID가 되기 때문에 인원이 퇴사하더라도 유지가 되고 거의 균일하게 (정상적으로 생육기록이 진행될 경우)
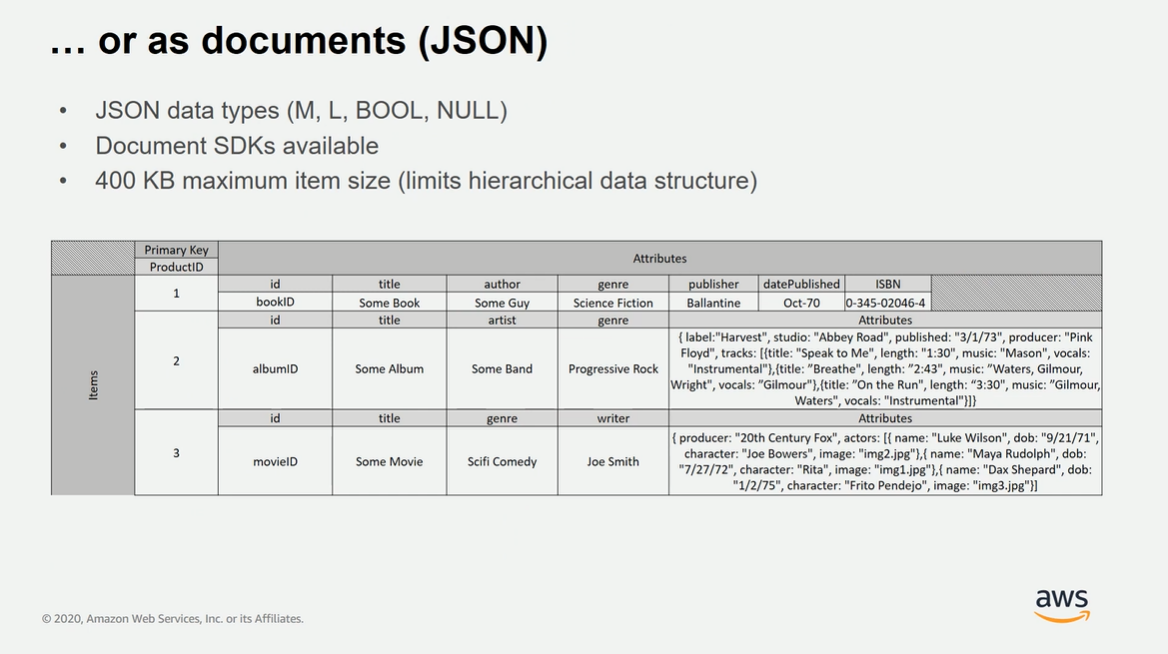
=> Primary Key가 복합키인 경우에도 단일 Partition Key ??
=> Partiction Key와 sort key가 합쳐지는 복합키 Primary key를 계획하려고 할 때 고민이 많다.
https://aws.amazon.com/blogs/database/choosing-the-right-dynamodb-partition-key/
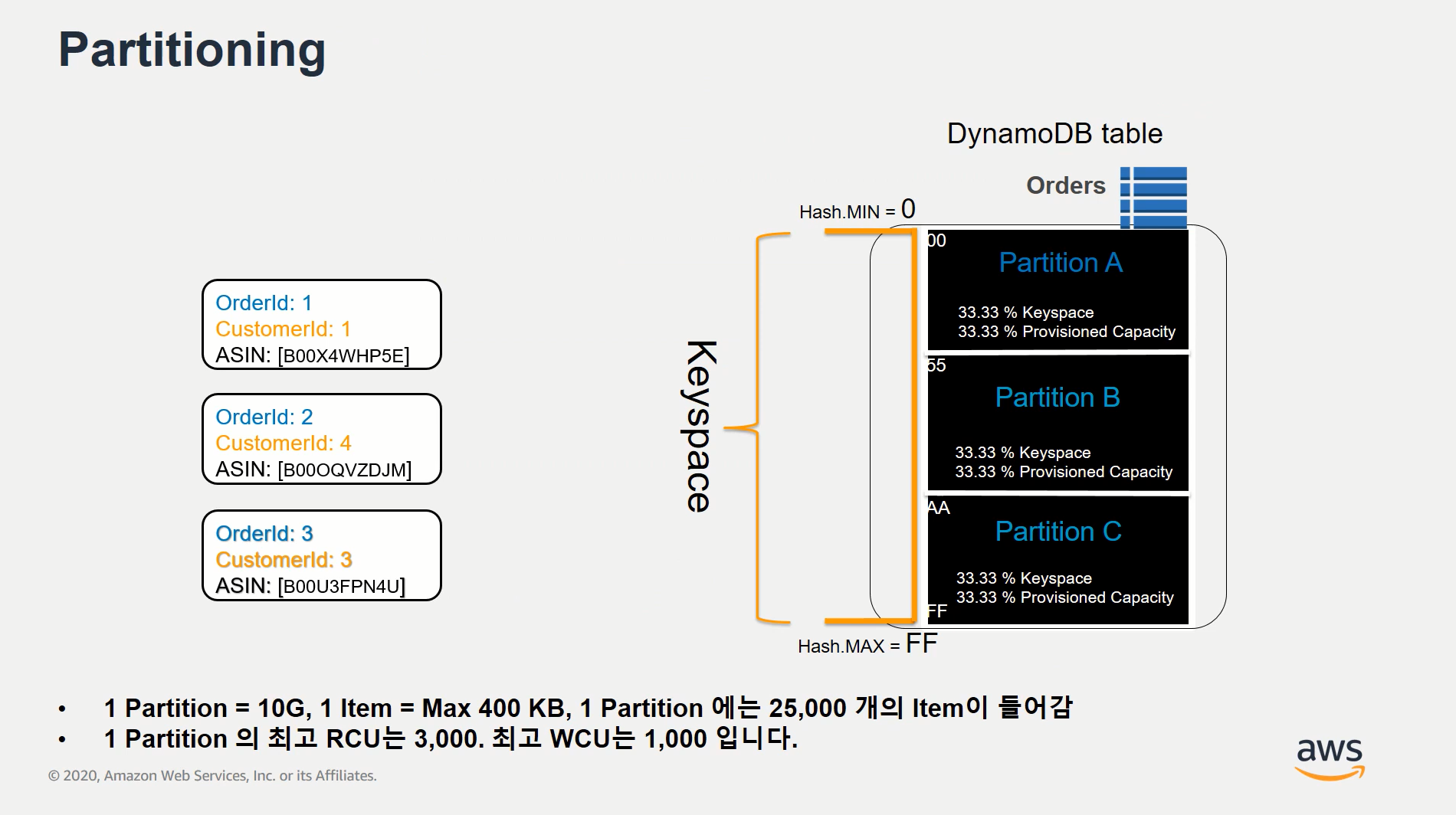
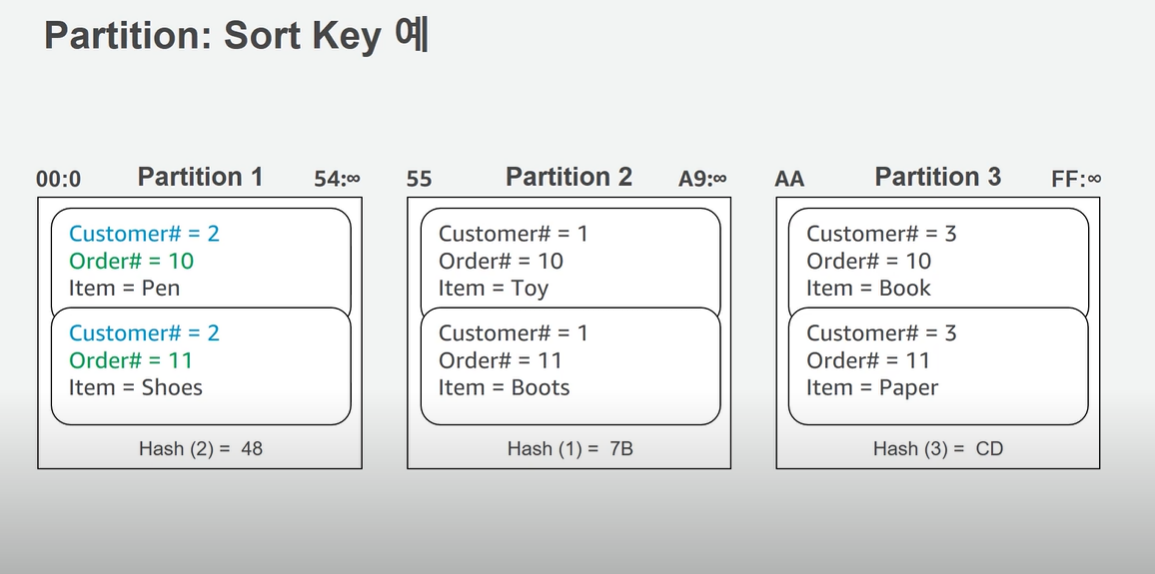
=> Partition은 각 table 안에 Partition Key를 통해 구분이 되는 것을 말함.
=> 좀더 나아가 Partition Key와 SortKey가 합쳐져 PK(Primary Key)를 구성함
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-sort-keys.html
aws dynamodb sdk node.js 연결
https://m.blog.naver.com/nieah914/222006261945
Partition
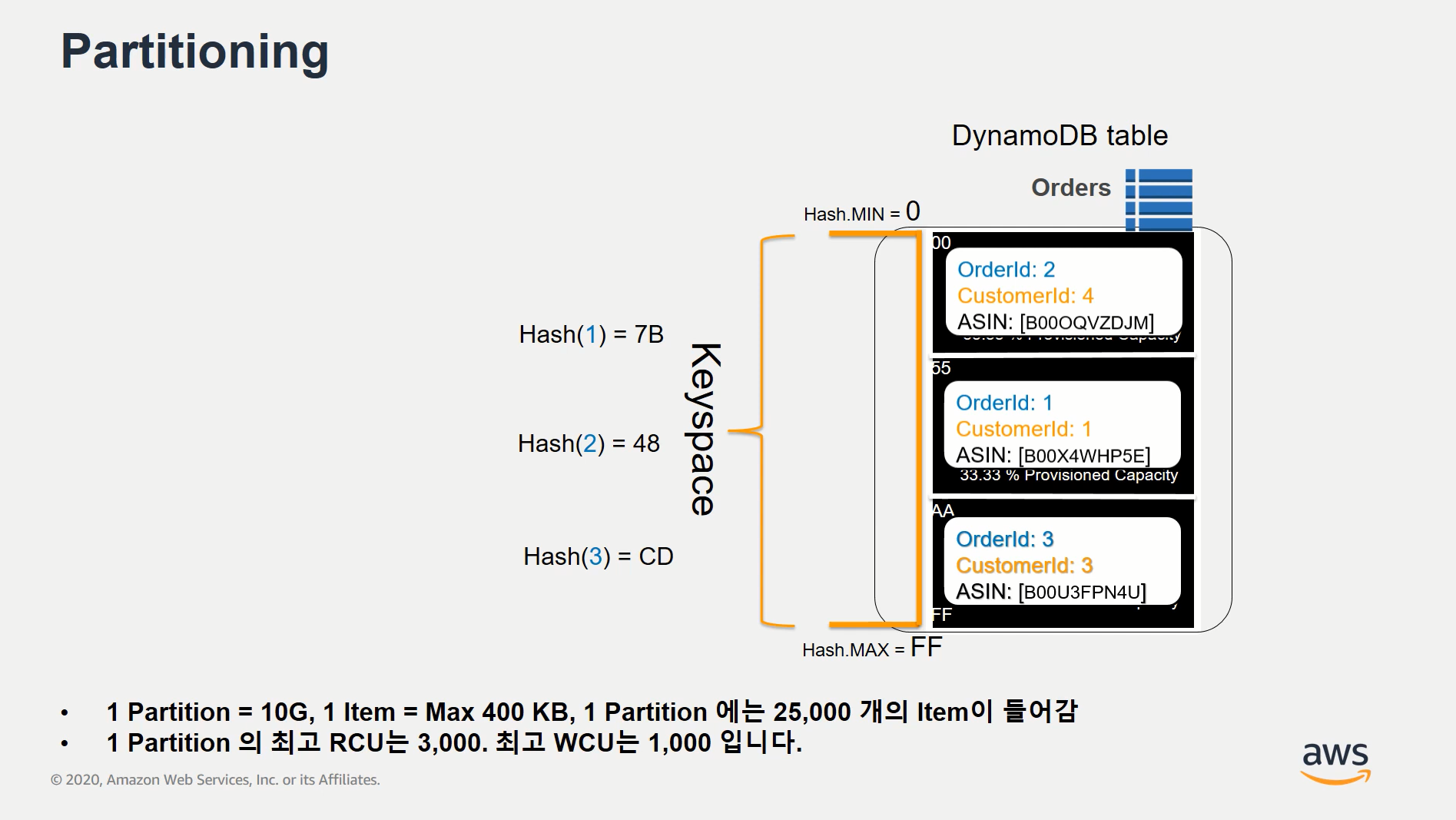
=> 각 Partition 별로 10GB 제한 약 25,000개의 Item
=> 1년에 24개
LSI(Local Secondary Index)
원본 테이블과 PK를 같이 가져간다?
즉, LSI는 테이블에 속한 Index
=> 그래서 이름이 Local이 붙는다.
=> 로컬 변수 이런것보다 로컬 인덱스인셈
GSI(Global Secondary Index)
원본 테이블로부터 복사본을 갖는 별도의 테이블
즉, GSI는 원본 테이블과 다른 PK를 생성할 수 있음
=> 얘네들은 필요에 따라 Partition Key로 별도 생성할 수 있음
=> 그러므로 추후에 필요시에 사용될 것 같은데
=> 여기서 미리 GSI를 설정해야하는지 확인이 필요할듯
=> GSI는 별도로 메모리를 먹기 때문에 적절한 설정이 중요함.
=> 그런데 여기서 나오는 OrderId는 무엇?
auto scailing
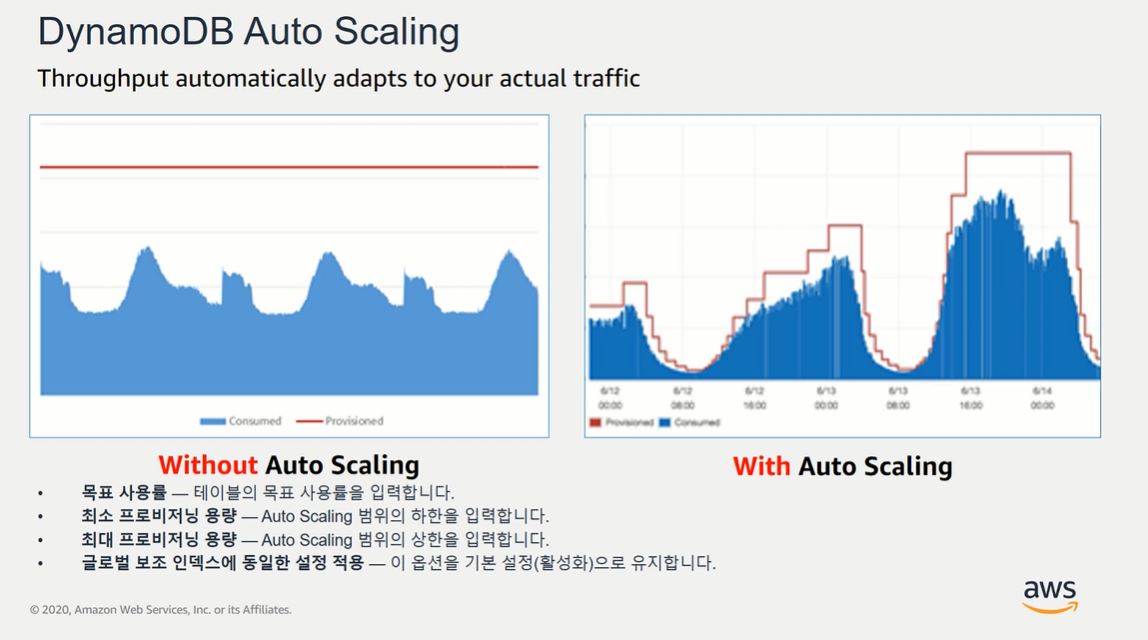
=> 트래픽 scailing을 해주는 것
=> 각각의 Partition 들의 트래픽에 따라 효율적으로 비용을 관리해줄 수 있음. 사진에서와 같이 다양한 옵션들이 존재.
=> 관련 트래픽 데이터를 확보하여 추후 최우선적으로 도입을 시도해야함
Burst
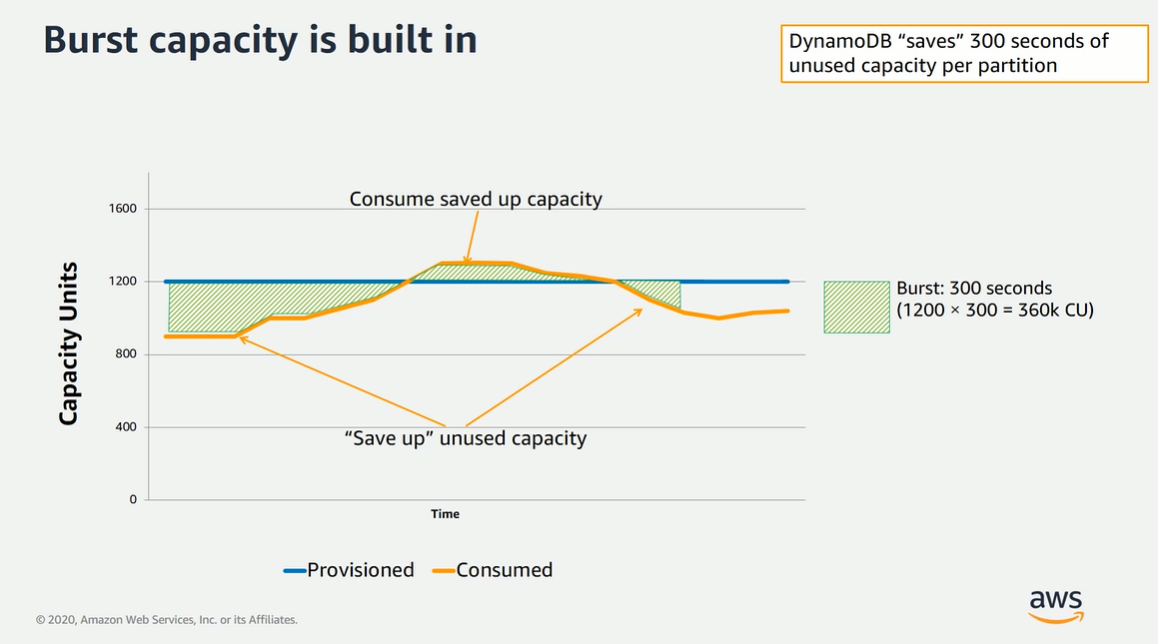
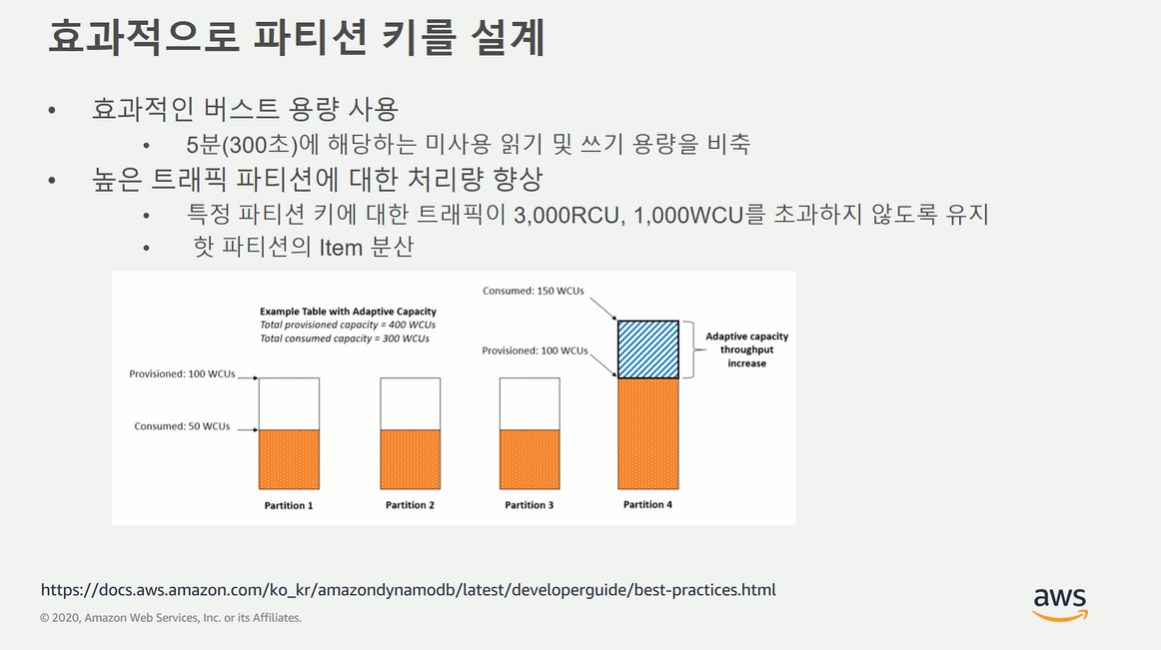
=> 특정 Partition에 트래픽이 몰릴 경우 효과적이고 효율적으로 처리할 수 있는 방법
=> Partition을 아이디로 할 경우 특정 트래픽으로 몰릴 가능성이 매우 낮음으로 신경 안써도 될듯.
Throttling
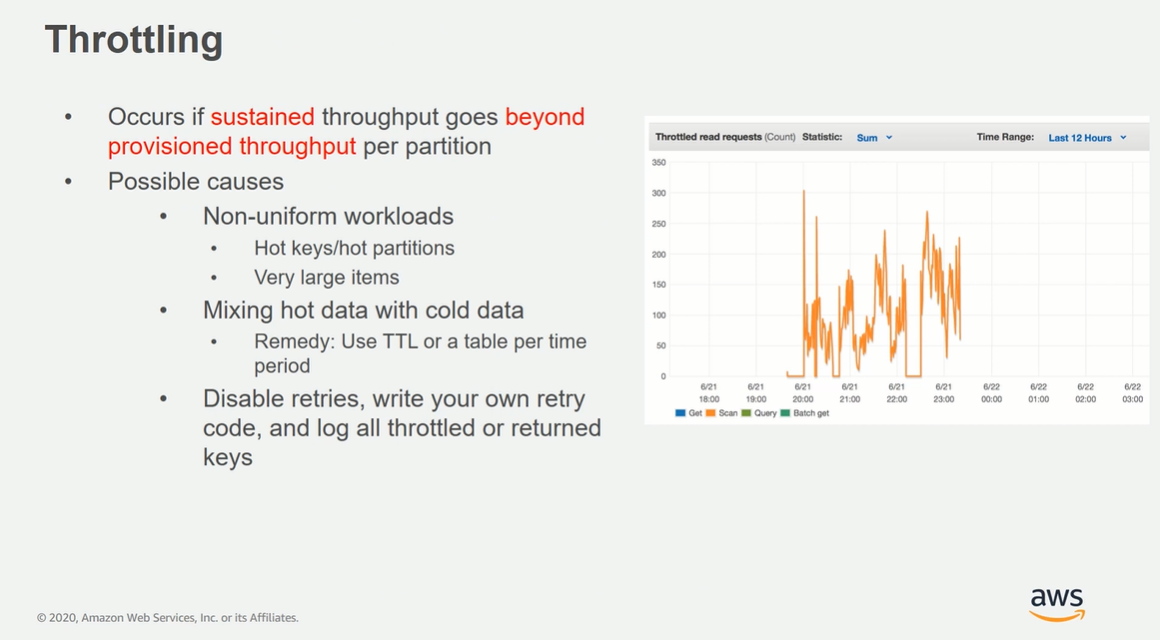
=> 갑자기 예기치 않은 트래픽이 발생할 경우 생길 수 있는 문제
=> 우리는 이러지 않을 것이기에 이것도 신경 안써도 될듯.
Best Practice Data modeling