현재 3학년 2학기에 환경인공지능이라는 과목을 수강하고 있다.
이 과목은 기말마다 강의시간에 했던 내용을 토대로 개인프로젝트를 진행하여 발표해야하는데 나는 기존에 전처리 되어있는 데이터를 이용하여 랜덤포레스트 대신 순환신경망을 적용시키기로 했다.
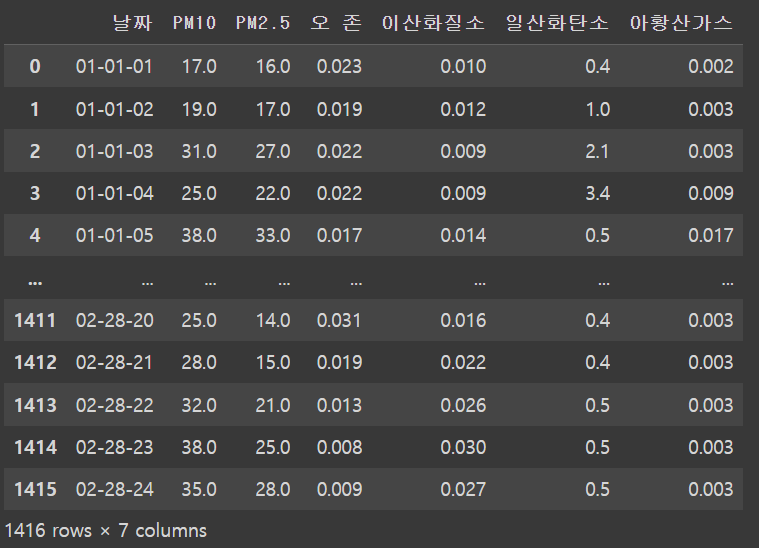
우선 강의시간에는 대기질 데이터를 이용해 이산화질소 농도로 오존 농도를 예측하는 모델을 만들었다.
날짜컬럼에 시간이 1일씩 순차적으로 증가하는 형태를 띔에 따라 내가 가지고 있는 교통량, 속도 데이터도 시간을 세로로 출력되게 할 필요가 있었다.
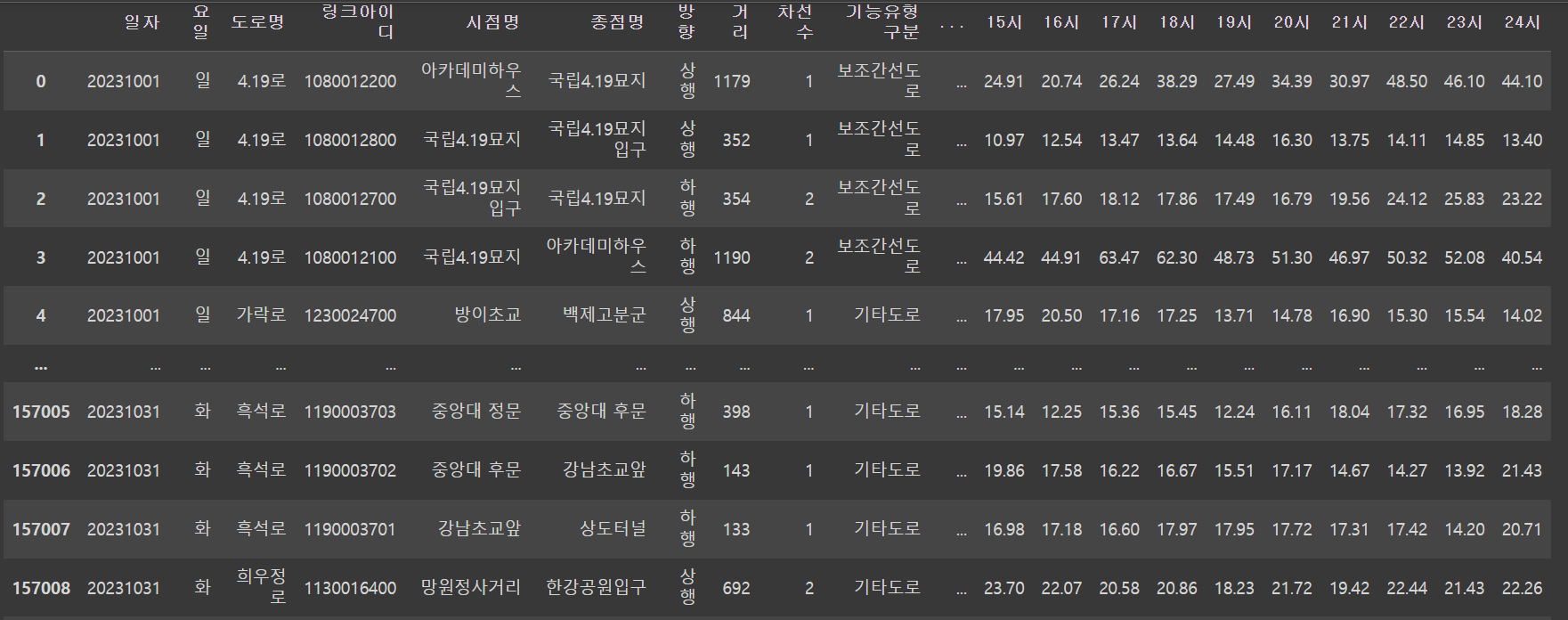
위는 속도데이터를 출력한 모습인데 1시부터 24시까지 가로로 출력됨을 볼 수 있다.
따라서 이를 세로로 출력되게 하기 위해서 melt()함수를 사용했다.
traffic_2023_10_df.melt(id_vars=['일자','링크아이디'],value_vars=traffic_2023_10_df.columns[1:],var_name=['시간'], value_name = '교통량')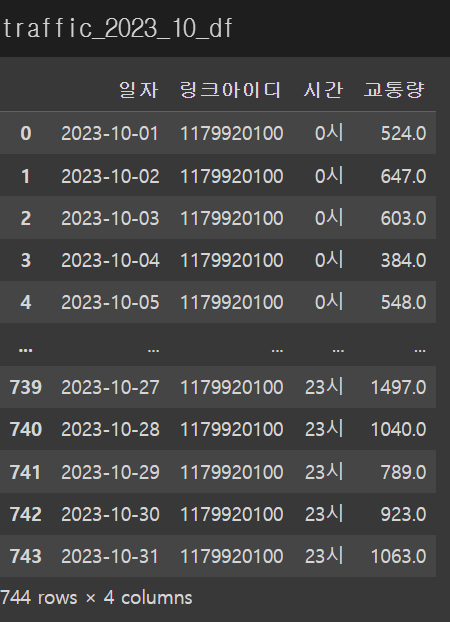
일자와 링크아이디는 고정시키고 가로로 있는 컬럼은 var_name[]에 넣고 컬럼명을 지정해주고 그 컬럼의 값은 value_name=''에 지정할 컬럼명과 함께 설정해주면 된다.
사실 이 함수하나 찾는데 너무오래 걸렸다ㅜㅠflatten()을 사용해서 다시 세로로 바꿀까 등 많은 고민을 했다!
그 다음 시간적인 연산을 쉽게 하고 싶어서 '시간'컬럼의 값을 datetime형태로 바꾸고 싶었다.
그래서 먼저 시라는 문자를 공백으로 대체함으로써 제거해주었다.
traffic_2023_10_df['시간'].str.replace('시','')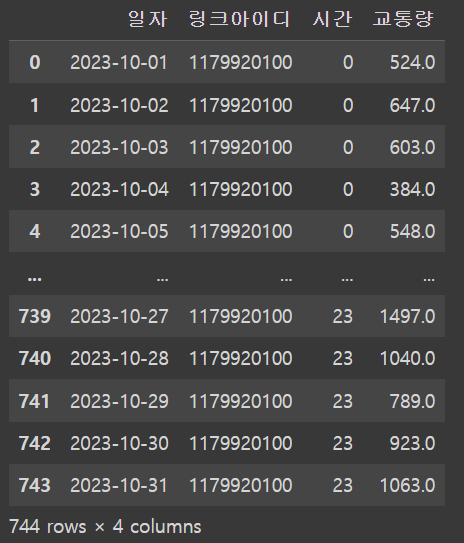
숫자로 값이 정리됐으니 datetime의 형태로 데이터타입을 바꿔주었다.
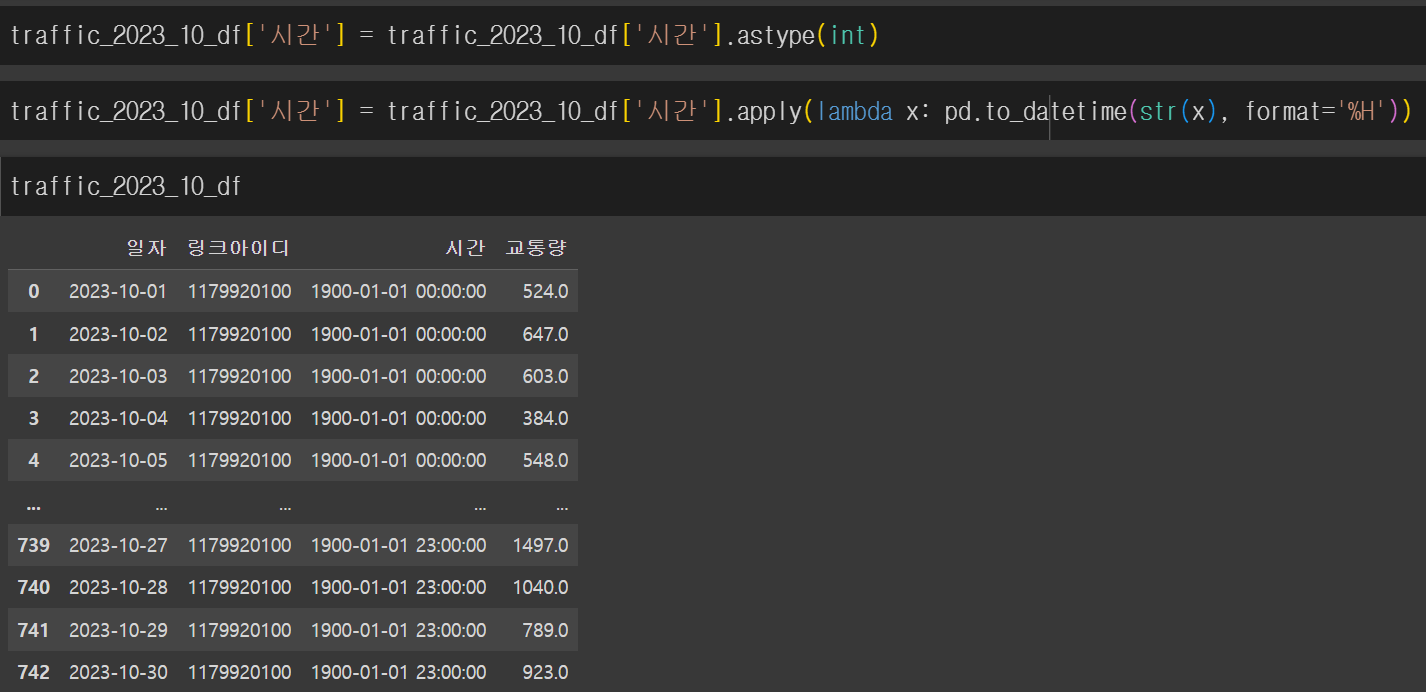
여기서 내가 새롭게 알게된 문법은 lambda 함수다.
이는 def 함수와 비슷한 역할을 하는데 더 간단한 형태라고 생각하면 된다.
람다함수로 datetime의 시간부분으로 출력되게 format = %H으로 입력해주었다.
위의 사진처럼 시:분:초 이렇게 출력이 됨을 확인할 수 있는데 기본적으로 내재되어있는 년:월:일 값이 있어서 이를 제거해줄 필요가 있었다.
def extract_time(row):
return row.strftime('%H:%M:%S')
traffic_2023_10_df['시간'] = traffic_2023_10_df['시간'].apply(extract_time)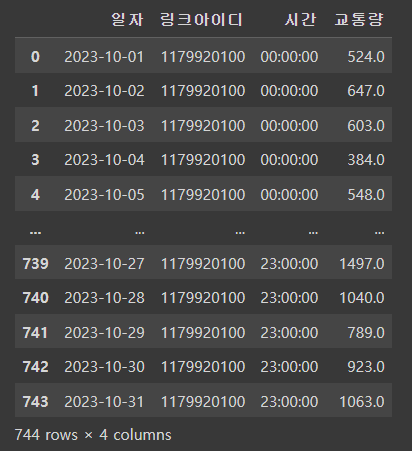
이번 프로젝트를 하기 전에는 함수를 잘 다루지못했고 낯설다 생각했는데 가장 많이 배운 부분이 함수라고 말할 수 있을 정도로 많이 배운 것 같다!🤓
마찬가지로 '일자'컬럼에도 기본적으로 저장된 시,분,초 값이 있을테니 이 부분도 람다함수로 적용하여 제거해주었다.
그리고 몇 시간 뒤 예측을 할 것이기에 일자와 시간 컬럼의 값들을 합쳐주었다.
traffic_2023_10_df["날짜"] = traffic_2023_10_df["일자"].map(str) + " " + traffic_2023_10_df["시간"]정말 간단하게 말그대로 더해주면 되는데 이 방법이 생각이 안나서 사실 교통량 예측 주제를 포기하려고도 했다.!
물론 map()을 이용하여 더할 수 있게 형태를 지정해주어야 했지만 조금은 내가 어렵게 생각하고 있었나?라는 생각이 드는 문장이었다.
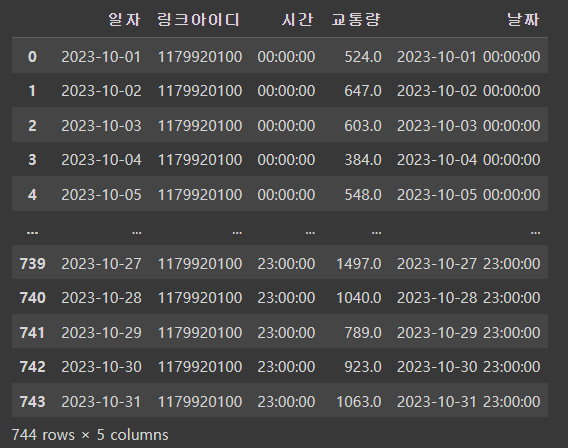
쨘-🔥
이게 진짜 이렇게 정리해놔서 간단해 보이는거지 생각해내느라 일정부분 스트레스를 좀 받은 바가 있다..😭
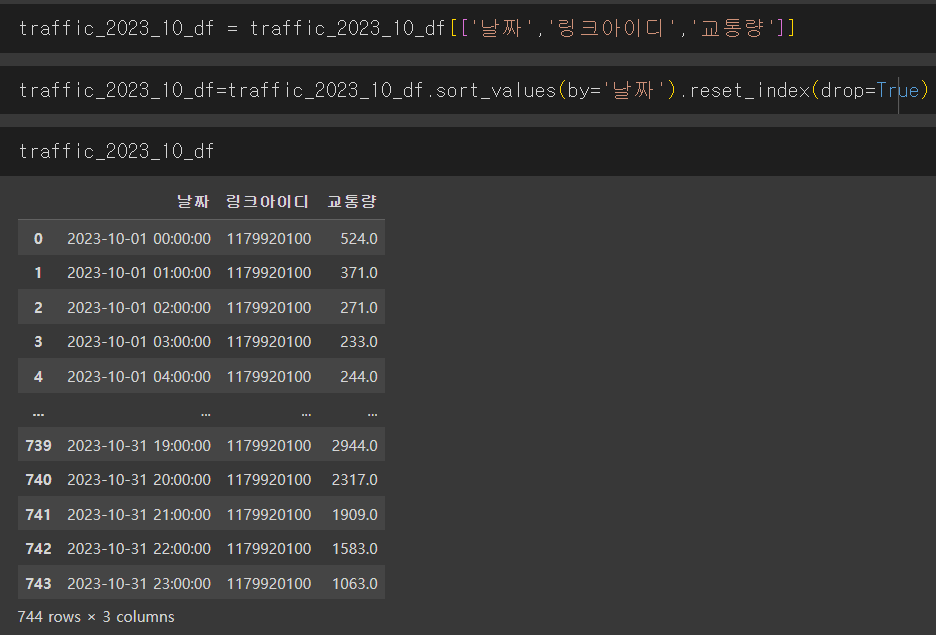
그런데!
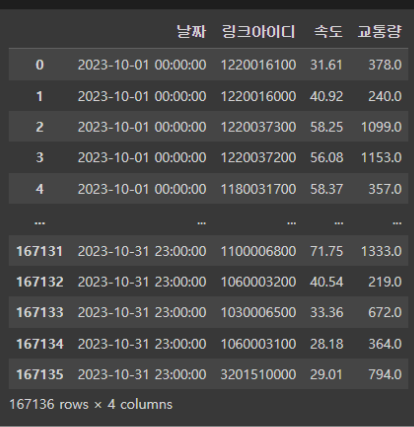
위에 보이는 사진이 내가 맨 처음에 구상했던 데이터 구성이다.
단순하게 시간 값들을 세로로 하나에 모아야된다고 생각해서 별다른 처리 없이 바로 진행을 했다.
여러 개의 링크아이디가 있으면 속도가 엉켜서 예측을 할 수가 없다는 것을 그래프를 그리고 나서까지 알았다.
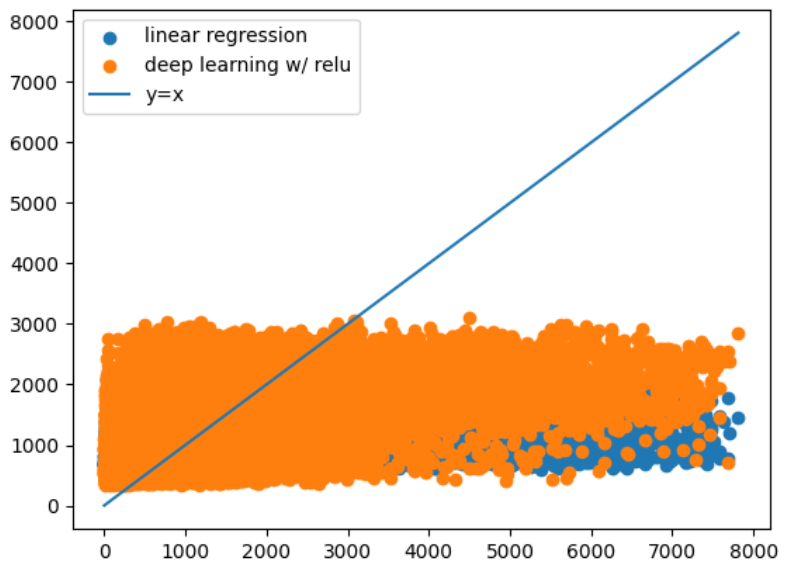
이렇게 카스테라(?)같은 산점도가 그려지기 전까지 몰랐다는..말이다..
이거를 발표자료제출 2시간 전에 알아서 연구실 오빠에게 급하게 SOS치구 피드백 받았다...
그래도 결국은 하나의 링크아이디에 대해서 분석한 바를 발표했으니 아마 평생 까먹지는 않을 전처리 순간이 될 것 같다..!ㅎㅎ
..................................
속도 데이터도 이전에 동일한 형태로 전처리 해주어서 마찬가지로 형태를 바꿔준다!
중간에 혹시 NaN값이 있을 수도 있어서 속도와 교통량 데이터를 merge에서 inner로 연결해준다.
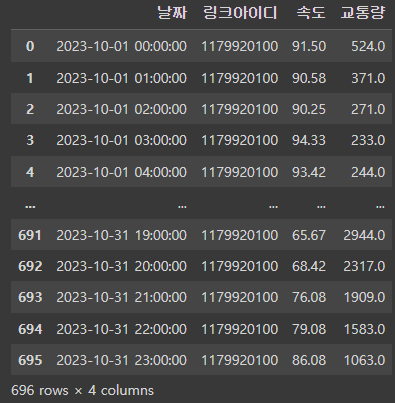
행 값이 적어진거 보니 교통량데이터에 결측치가 있었나보다.
이 다음부터는 강의시간에 교수님께서 짜주신 코드를 적용했다.
velo = pd.concat([velo_traffic_total['속도'],
velo_traffic_total['속도'].shift(-1),
velo_traffic_total['속도'].shift(-2),
velo_traffic_total['속도'].shift(-3),
], axis=1, ignore_index=True)속도 컬럼만 빼서 1시간 뒤(shift(-1)), 2시간 뒤(shift(-2)), 3시간 뒤(shift(-3))로 미룬 데이터를 더해준다.
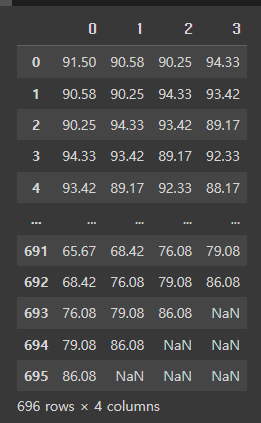
마찬가지로 교통량 데이터도~
pd.concat([velo_traffic_total['교통량'],
velo_traffic_total['교통량'].shift(-1),
velo_traffic_total['교통량'].shift(-2),
velo_traffic_total['교통량'].shift(-3),
], axis=1, ignore_index=True)target = velo_traffic_total['교통량'].shift(-6)그리고 타겟데이터는 6시간 뒤로 설정해준다.
input_target_nonan=pd.concat([traffic, velo, target],
axis=1,
ignore_index=True).dropna()n시간 씩 미뤄준 열들을 다 더해준다.
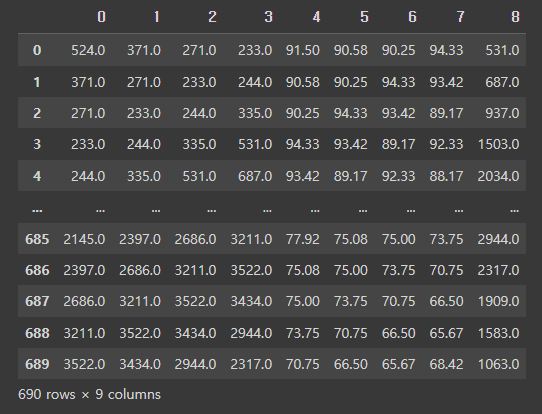
0-3번은 교통량, 4-7번은 속도, 8번은 타깃 데이터다.
그 다음에는 train_test_split으로 80퍼, 20퍼로 학습, 테스트 세트를 나눠준다.
검증세트로 만들어준다.
rom sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = \
train_test_split(input_final, target_final,
test_size=0.2,
random_state=42)
train_input, val_input, train_target, val_target = \
train_test_split(train_input, train_target,
test_size=0.2,
random_state=42)
요렇게!
그리고 MinMaxScaler도 해준다.
from sklearn.preprocessing import MinMaxScaler
mm = MinMaxScaler()
mm.fit(train_input)
train_scaled = mm.transform(train_input)
val_scaled = mm.transform(val_input)
test_scaled = mm.transform(test_input)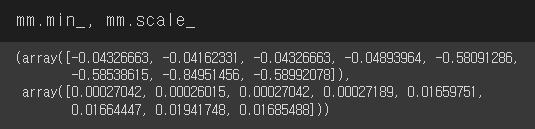
잘 정리된 것 같다.
그 다음 형태를 맞춰주기위해 reshape()을 사용해서 바꿔주는데 그 과정을 설명하겠다.
사실 내가 좀 이해가 안됐어서ㅜ
일단 1번째 행이다.
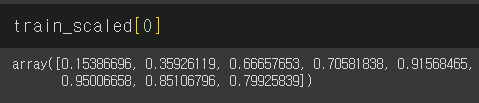
8번째 컬럼까지 있으니까 8개가 출렸됐다.
이를 reshape(-1,2,4)니까
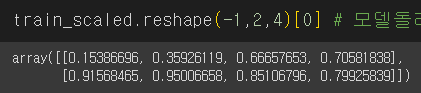
이제 3차원(?) x 2차원 (2) x 1차원(4) 으로 되는데
reshape에서 -1은 원래 배열의 길이와 남은 차원이라고 한다.
즉 전체(?)에서 2 x 4로 했으니까 위의 그림 처럼 출력된다.
이거를 transpose해주면
import numpy as np
np.transpose(train_scaled.reshape(-1,2,4), (0,2,1))[0]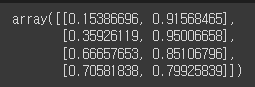
요렇게 새로로 출력된다.
학습 세트도 형태 맞춰주고 검증 세트로 같게 해준다.
테스트도ㅎ

형태가 잘 된 것 같다.
회귀분석 먼저 진행했다.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_seq.reshape(-1,8), train_target)x = np.arange(0,1000).reshape(-1,1)
y = 2*x
lr = LinearRegression()
lr.fit(x,y)from tensorflow import keras
model_lr = keras.Sequential()
model_lr.add(keras.layers.Flatten(input_shape=(4,2)))
model_lr.add(keras.layers.Dense(1))
model_lr.compile(loss='mse',
metrics='mae')
checkpoint_cb=keras.callbacks.ModelCheckpoint(
'best-lr-model.h5',
save_best_only=True
)
early_stopping_cb=keras.callbacks.EarlyStopping(
patience=3,
restore_best_weights=True
)
history_lr=model_lr.fit(
train_seq, train_target,
epochs=1000,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb,
early_stopping_cb]
)에포크는 1000번 진행했다.

loss값이 너무 크게 나왔다...
다음에는 렐루함수를 적용해서 돌려보았다.
from tensorflow import keras
model_deep = keras.Sequential()
model_deep.add(keras.layers.Flatten(input_shape=(4,2)))
model_deep.add(keras.layers.Dense(20, activation='relu'))
model_deep.add(keras.layers.Dense(20, activation='relu'))
model_deep.add(keras.layers.Dense(1))
model_deep.compile(loss='mse',
metrics='mae')
checkpoint_cb=keras.callbacks.ModelCheckpoint(
'best-deep-model.h5',
save_best_only=True
)
early_stopping_cb=keras.callbacks.EarlyStopping(
patience=10,
restore_best_weights=True
)
history_deep=model_deep.fit(
train_seq, train_target,
epochs=1000,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb,
early_stopping_cb]
)
여전히 조금은 큰 값이지만 어느정도 값이 잡혀졌다.
mae도 500대 정도로 오차가 생겼다.
이번에는 심층신경망을 적용해보았다.
from tensorflow import keras
model_relu = keras.Sequential()
model_relu.add(keras.layers.Flatten(input_shape=(4,2)))
model_relu.add(keras.layers.Dense(10, activation='relu'))
model_relu.add(keras.layers.Dense(1))
model_relu.compile(loss='mse',
metrics='mae')
checkpoint_cb=keras.callbacks.ModelCheckpoint(
'best-relu-model.h5',
save_best_only=True
)
early_stopping_cb=keras.callbacks.EarlyStopping(
patience=3,
restore_best_weights=True
)
history_relu=model_relu.fit(
train_seq, train_target,
epochs=1000,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb,
early_stopping_cb]
)

loss값이 더 올라간걸보니 이 자료값은 심층신경망이 안 맞나보다..ㅎㅎ
해서 결과는
import matplotlib.pyplot as plt
plt.scatter(test_target, pred_lr, label='linear regression')
plt.scatter(test_target, pred_deep, label='deep learning w/ relu')
plt.plot([min(test_target),max(test_target)],
[min(test_target),max(test_target)], label='y=x')
plt.legend()
plt.show()
카스테라 산점도에 비하면 선형식에 가깝게 잘 나왔다.
(비록 이것도 좋은 성능을 나타냈다고 할 순 없지만ㅎㅎ)
교수님이 이걸보고 linear Regression은 학습이 안된 것 같다고 말씀해주시긴 했다..(나도 잘 모르겠다..ㅜ)
성능을 더 높이기 위해서
1. 더 많은 데이터 사용
: 10월 데이터로만 진행했는데 3개년 정도 적용시켜볼 것.
2. 더 다양한 링크아이디 적용
: 여러 개의 링크아이디에 대해 한번에 적용시킬 수 있는 방법을 고안해볼 것. 함수식 이용해서 정리해볼까?
3. 다른 모델 적용
: LSTM이나 CNN등으로 적용시켜서 더 나은 성능을 기대해볼 것.
사실 딥러닝에 대한 개념이 잘 잡히지 않아보인다. 딥러닝에 대한 개념적인 부분을 더 보완하고 탄탄하게 정립한 다음에 각 모델에 대한 특성을 이해해서 적용시켜보면 더 나은 엔지니어로서 성장할 수 있을 것 같다!
.
.
.
더불어,
작년 겨울방학부터 1년동안 전공이 아닌 새로운 길을 만들어가면서 지금의 나에 대해 드는 생각을 조금 적어보려 한다.
내가 이런 분야를 준비해가면서 내가 좋아하는 것이니까 더 열심히했고 또 연쇄작용으로 내 역량보다 더 좋은 결과를 냈다.
하지만 지금 생각해보면 몇 가지 해내면서 가졌던 자신감이 나를 일정부분 해이하게 만들었던 것 같다.
비전공자일수록 몇 배는 더 열심히 해야되겠지하면서도 이정도면 잘하는 것 아닌가라는 생각이 들어서 다소...자만심을 가졌던 것 같다.
어려운 길을 애써 피하면서 쉬운 길로만 가면서 해냈다라고 뿌듯해 하는 건 너무 우물 안의 개구리이지 않았을까..
직접 데이터를 다뤄보면서 프로젝트를 진행하는 것도 중요하지만 인공지능에 대한 개념적인 부분을 더 탄탄하게 다진다음에 새로이 등장하는 트렌드에 맞춰서 더 나은 지식의 장을 펼쳐나가야 할 것 같다.
그래야 추후에 팀이나 개인으로 프로젝트를 진행할 때 유의미있는 결과가 나오는데 도움을 줄 수 있지 않을까..ㅎㅎ!!
1월부터 개발직종으로 인턴을 나가지만 AI 엔지니어, 데이터 애널리스트, 데이터 사이언티스트의 꿈은 접지 않으려고 한다.
회사에 다니면서도 꾸준히 공부하고 자격증도 따고 그래야지!
그래도 1년동안 마음고생하면서 공부한 거 너무 수고했어 진희야.
앞으로도 화이팅-! 더 멋지고 큰 사람이 되자!
