RAM용량이 터진 이후로 다시 심기일전해서 데이터를 붙잡아보았다.
내가 생각해도 그게 뭐길래 그 한줄에 용량이 터질 수 있는지 이해가 안돼서...내가 잘못했거니 생각했다.
속도데이터 말고도 교통량 데이터를 처리하고 있어서 셀이 많아서 문제였나 싶어서 새로운 노트북을 열어 시간 부분을 수정하기로 했다.
업그레이드 먼저 해주고
!pip install --upgrade xlrd구글 드라이브에 마운트해주었다.
from google.colab import drive
drive.mount('/content/drive')1일차에 해준 방식과는 거의 똑같지만 변수의 이름만 일부 변경해주었다.
사실 내가 헷갈려서 바꿔줌😂
velo = pd.read_excel("/content/drive/MyDrive/Colab Notebooks/data/2023년 1월 서울시 차량통행속도.xlsx")그리고 어제했던 코드는 너무 돌아돌아 작성한 것 같아서 조금 생각이란걸 해서 과정을 줄였다.
맨처음에 불러왔던 속도 데이터 'velo'에서 바로 datetime으로 바꾸어 주었다.
어짜피 1일 추가한 데이터나 전체 데이터나 둘 다 형태를 같이 해줘야 했기 때문이다!
어제는 따로 따로 해주는 바보같은 짓을 했다.
어제 했던거긴 하지만 다시 복습!
velo['일자']velo['일자']=velo['일자'].astype('str')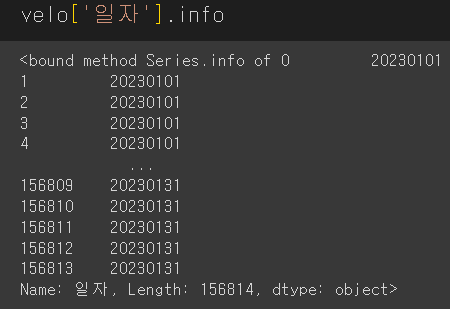
astype('str')을 사용하니까 데이터 타입이 object로 변했다.
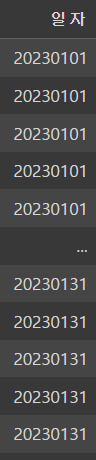
velo['일자']=pd.to_datetime(velo['일자'])
전체 데이터에서의 '일자'가 datetime으로 잘 바뀐 것을 알 수 있다!
그리고 '일자'컬럼에 1일을 더한 데이터는 'velo2'라고 한 다음 똑같이 처리해주었다.
그리고 마찬가지로 머지함수를 사용해 셀을 실행했는데....
램 용량이 또 다운됐다...!!!😵💫
그러다 한가지 생각이 내 뇌리를 스쳤다.
"
그렇다면 이전의 노트북에서 했던건 문제가 아니라 오직 머지함수를 이용해 실행시킨 셀이 문제였던 것이다..!
도대체 어떻게 했길래..그 이유는 사실 아직도 모른다.

그래서 오늘도 열심히 적어가면서 이 고난을 헤쳐 나갔다.
어제 SQL공부하면서 JOIN절을 공부했는데 거기서 분명히 이해를 어느정도 했다고 생각했는데..
그러다 한가지 생각이 내 뇌리를 스쳤다.
"아😯 데이터에서 일자는 중복되어있는게 많았지?"
그렇다. 이것은 나에게 주어진 그 데이터에 대한 이해의 부재에서 기인한 문제였다.
merge()함수에서 on=매개변수를 사용할 때 나는 '일자'를 기준으로 데이터를 병합하려고 했다.
그런데 당장 볼 수 있듯 일자는 중복되어있는게 매우매우매우 많았다.
RAM용량이 안 꺼진게 이상했다는...
그렇게 해서 생각을 해보니까 머지함수를 이용해서 이 데이터들을 합치기는 어렵다 판단했다.
다음에 내가 생각할 수 있는 것은 concat()을 사용하는 것.
concat()은 전공 수업시간에도 한번 접해 본 친구라 걱정되진 않았다.
concat()은 어떠한 동일성 그런 것과 관련 없이 그냥 붙이기만 하는거라 날짜별로 행의 순서가 같다면 문제가 생기지 않을 것이라 생각했다.
회색형광펜이 쳐진 저 문구는 나중에 문제가 발생한다.
위의 사진에서 볼 수 있듯 내가 생각한 방향은
- 20230101:00시 => 2022년 12월 데이터에서 31일:24시를 따로 추출
- 20230102~20230131 => 기존의 데이터에서 행 자르기
- 20230131:24시 => 2023년 2월 데이터에서 1일:00시를 따로 추출
이렇게 세개의 데이터 프레임을 만든 다음concat()으로 묶으려 했다.
vel3_del=velo3.drop(labels=range(0,5054),axis=0) #20230102~2023013120230102부터 20230131의 행을 'vel3_del'으로 drop해주었다.
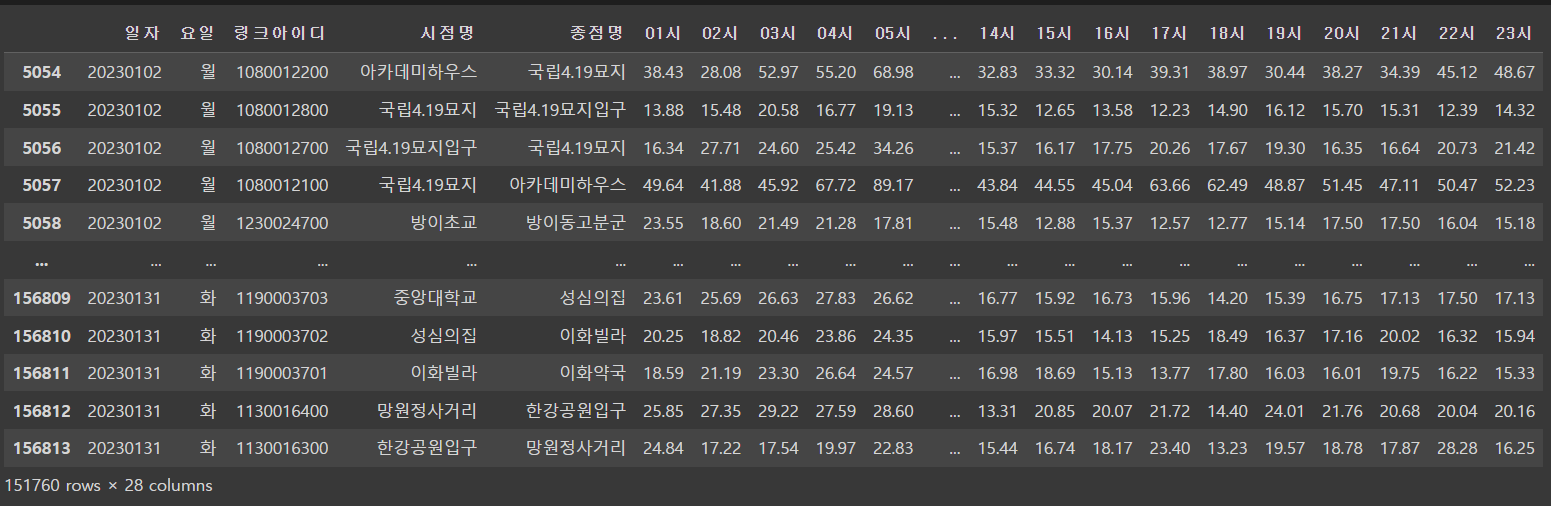
1월2일부터 31일까지 잘 출력됐다.
velo2.drop(velo2[velo2['일자']=='2023-02-01'].index,axis=0)그리고 1일씩 증가한 데이터에서 2월의 데이터를 없애는 작업 해줬다.
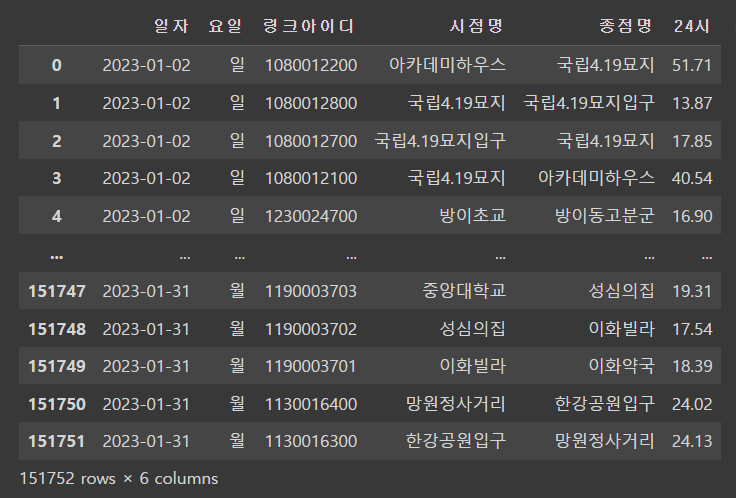
그렇게 이 두개의 데이터의 행의 개수를 살펴보았는데...
151760, 151752로 개수가 달랐다...😭
내가 생각한 방향이 틀렸다는 것이 실감났던 순간이 됐다.
NaN값이 생기는 것은 물론 각 일에 대한 순서 그리고 정확도도 보장할 수 없어서 이 방법은 사용할 수가 없다고 생각했다.
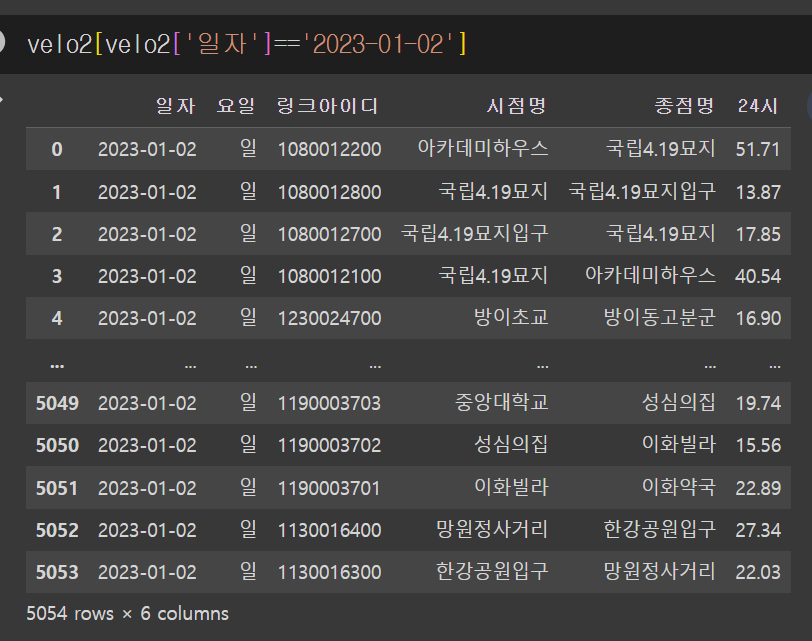
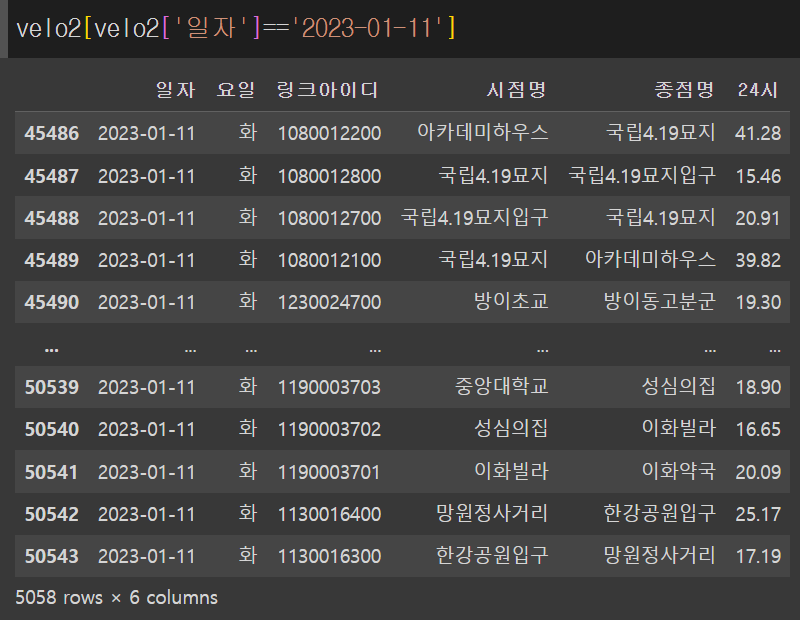
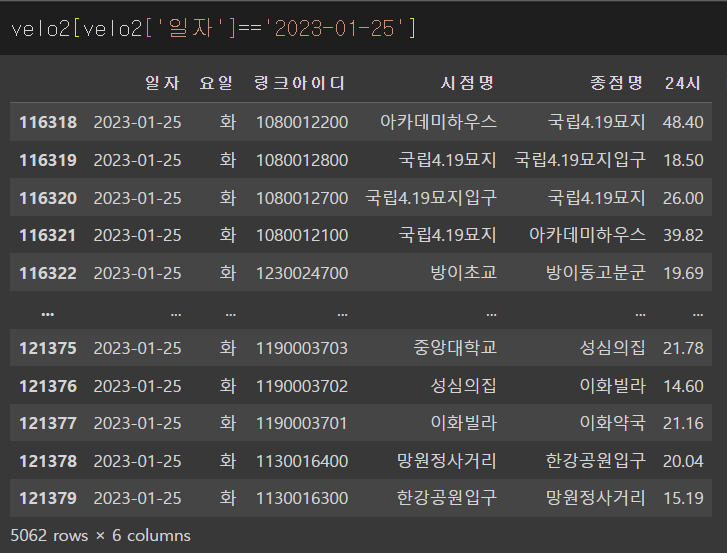
행의 개수가 달랐다..
아무래도 concat()도 사용하지 못할 것 같다...
다음주에 또 다른 방법을 서칭해봐야지...
