Scikit-learn 내장 학습용 ML 모듈
사이킷런 패키지에는 머신러닝을 위해 미리 만들어진 여러 모델들이 있다. 사용자는 이 중에서 하나 골라 좋은 데이터들을 넣어주고 학습시키면 손쉽게 머신러닝 모델을 사용할 수 있다. sklean.tree, sklearn.linear_model, sklearn.svm 등 다양한 패키지로 모듈이 나누어져 있지만 사이킷런에서 사용되는 대표적인 분류, 회귀 모듈은 다음과 같다.
분류(Classification)
- DecisionTreeClassifier
- RandomForestClassfier
- GradientBoostingClassifier
- GaussianNB
- SVC
회귀(Regression)
- LinearRegression
- Ridge
- Lasso
- RandomForestRegressor
- GradientBoostingRegressor
이 학습모델들을 묶어서 사이킷런에서는 Estimator라고 부르고, 학습은 fit(), 예측은 predict() 메소드를 이용한다.
연습용 데이터셋 - iris data
사이킷런에서는 학습을 위해서 패키지 내장 샘플 데이터셋들을 제공하며, 다음과 같은 종류가 있다.
- 보스턴 집 피처와 집값 레이블 - 회귀
- 위스콘신 유방암 피처와 악성/음성 레이블 - 분류
- 당뇨 데이터 - 회귀
- 0~9 숫자 이미지 픽셀데이터(MNIST) - 분류
- 붓꽃 피처와 종류 레이블 - 분류
데이터의 구조를 알아보기 위해 대표적으로 붓꽃 피처 데이터세트인 sklean.datasets 의 load_iris 를 확인해보자. 샘플데이터에서 접근할 수 있는 프로퍼티들은 iris 데이터의 key를 확인함으로써 알 수 있다.
# iris 예제데이터 keys 확인
from sklearn.datasets import load_iris
iris_data = load_iris() # iris 예제데이터를 가져온다. Bunch 타입.
# <class 'sklearn.utils._bunch.Bunch'>
keys = iris_data.keys() # iris 데이터의 key를 확인.
# <class 'dict_keys'>
print(keys)
# -> dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])각 key에 대해서 자세히 알아보면 다음과 같다.
-
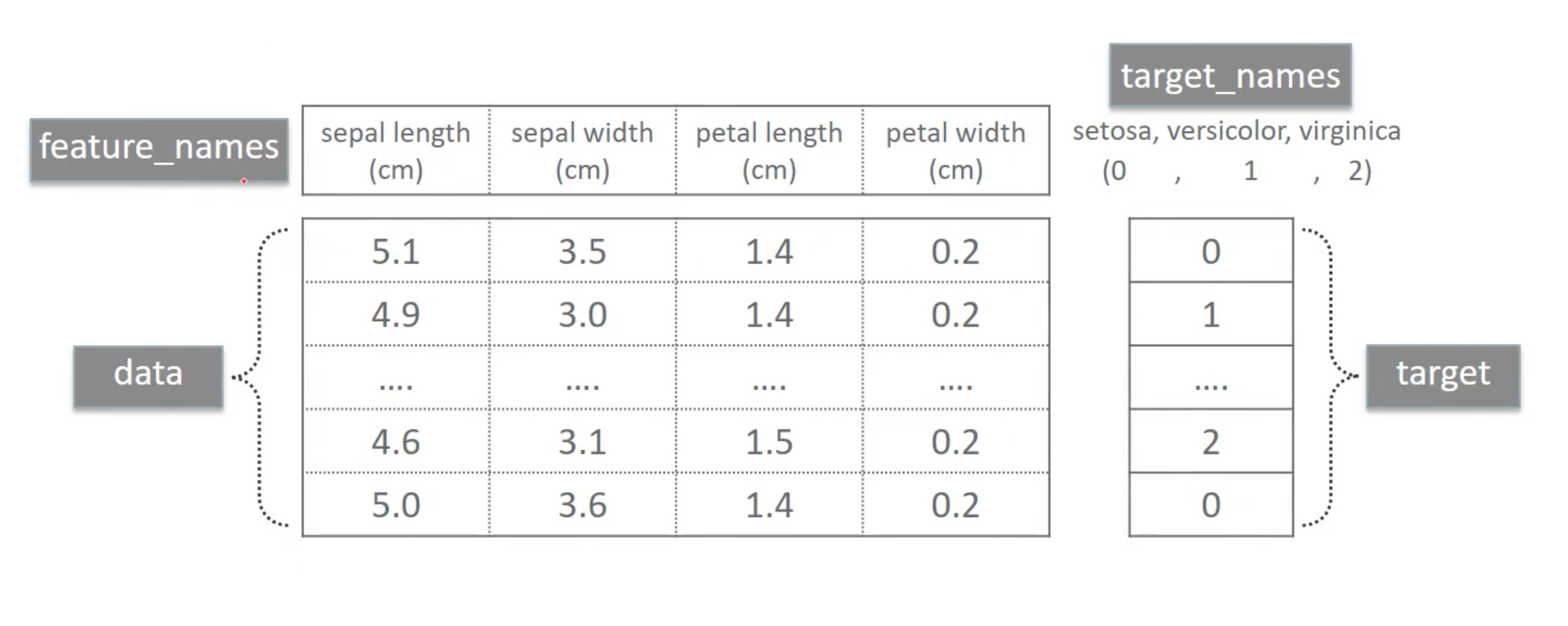
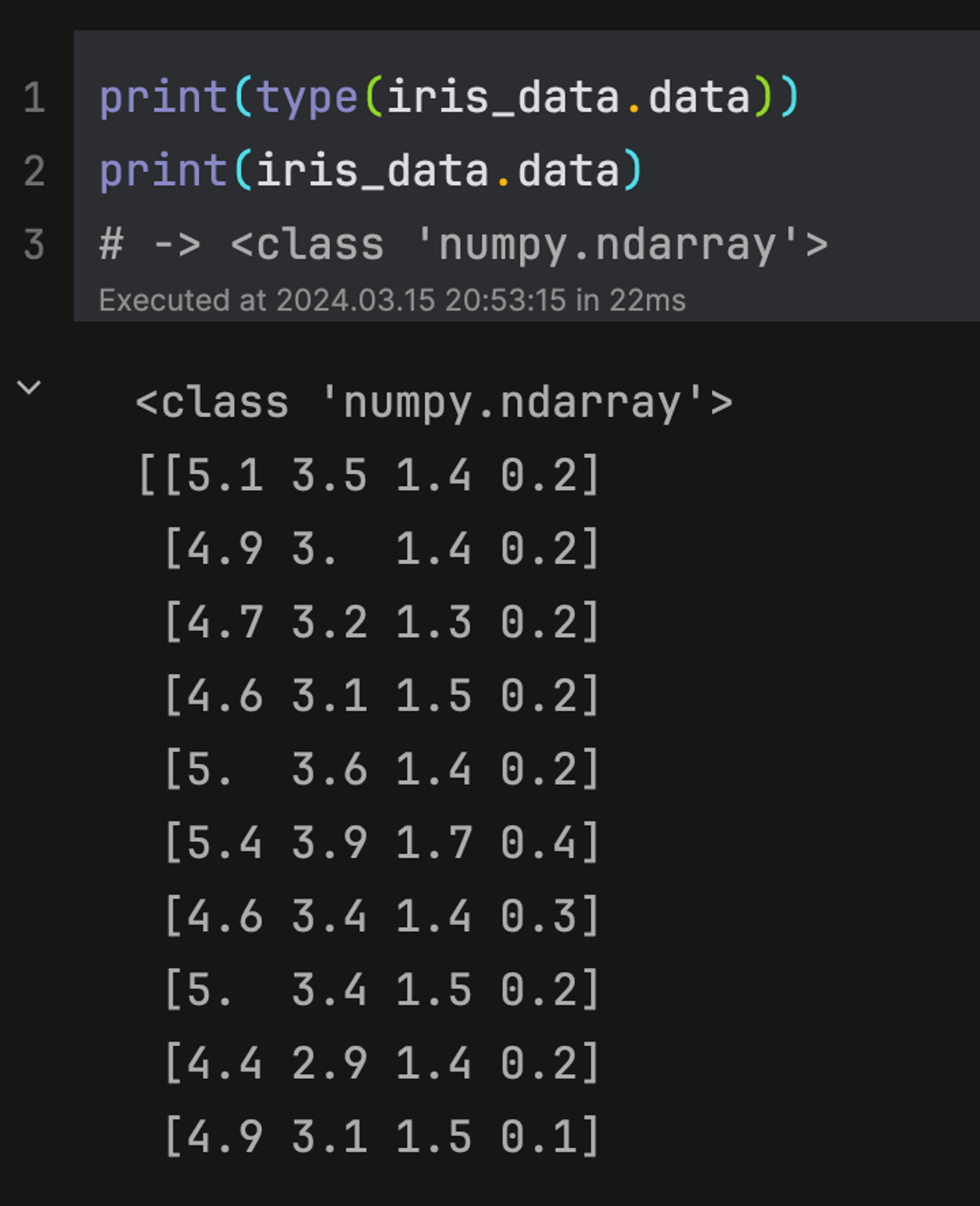
data: 피처에 해당하는 데이터셋. ndarray 타입을 가지며 각 열은 feature_names에 해당하는 값들을 나타낸다.
-
feature_names: 피처 이름. list 형으로, 각각 'sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)’ 를 나타낸다.

-
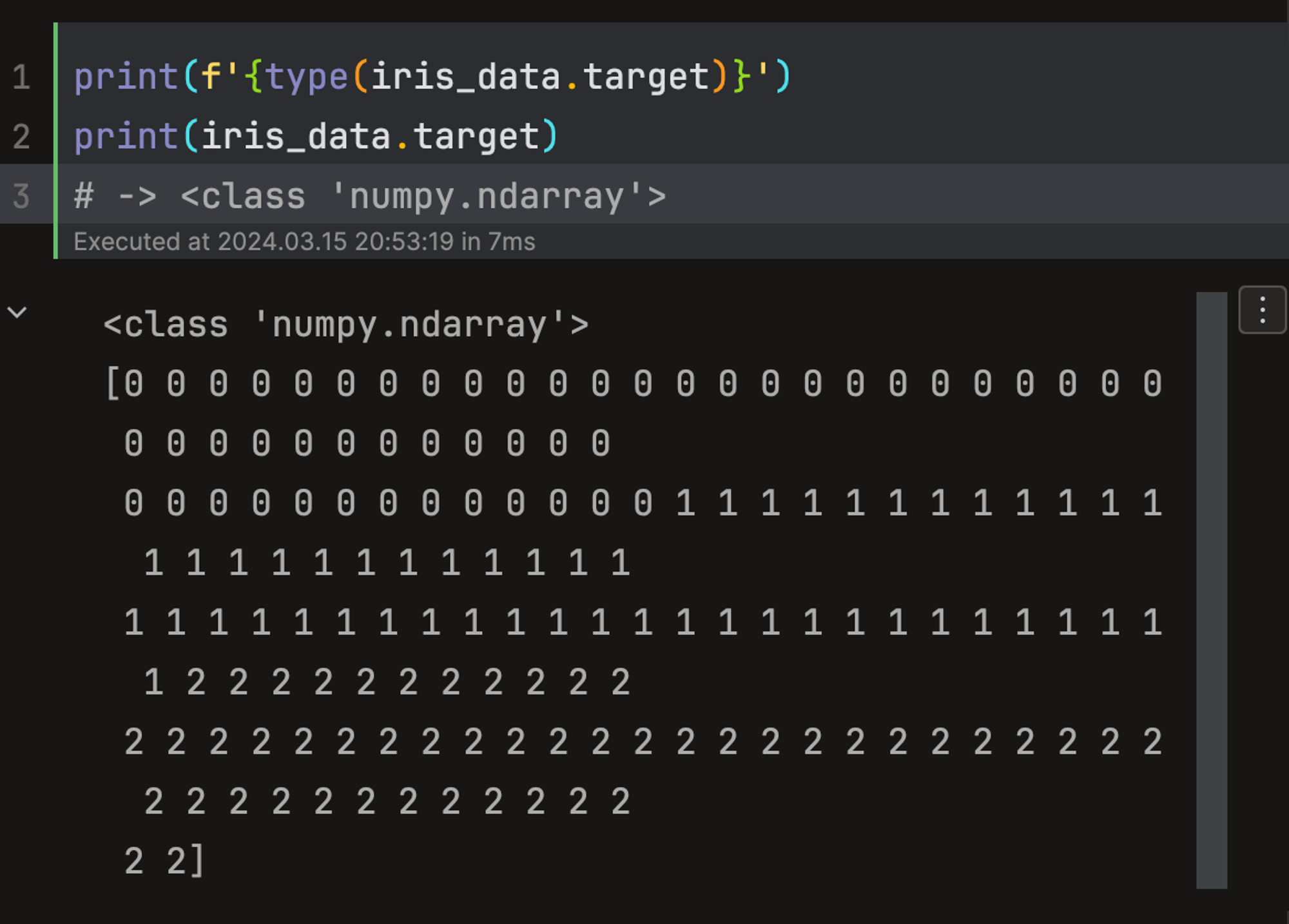
target: 분류일 때는 레이블, 회귀일 때는 숫자 결과값에 해당하는 데이터 세트. ndarray 형.
iris 각 행이 어느 종에 속하는지를 정수로 나타낸 데이터이다. 0, 1, 2의 의미는target_names에 나타나있다.
-
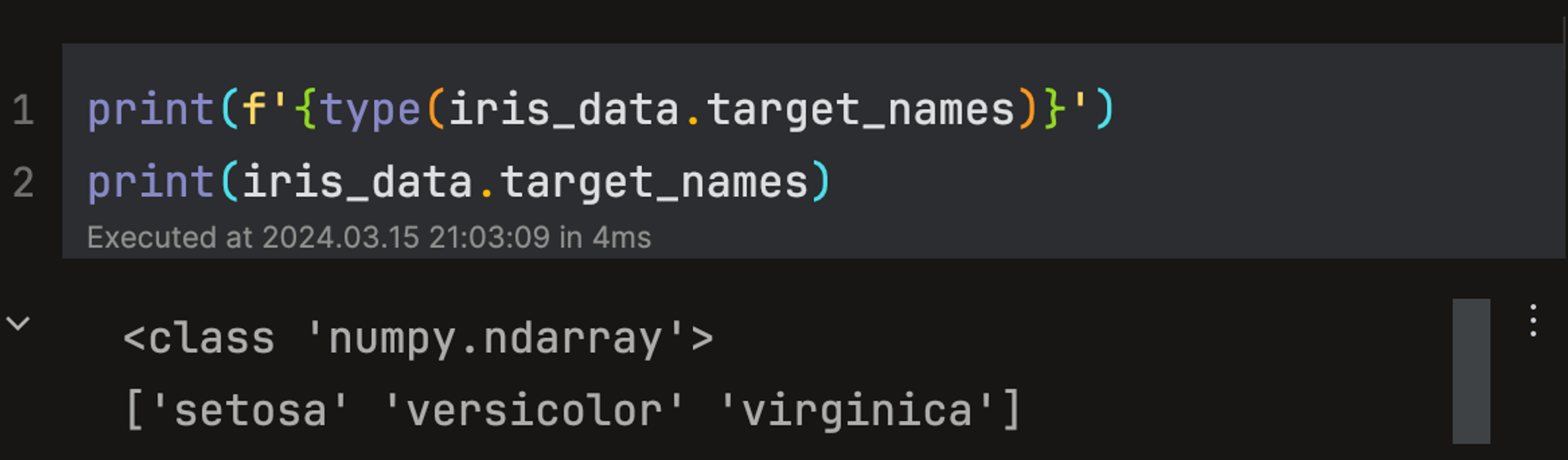
target_names: 개별 레이블의 이름을 나타내며 ndarray 형.
-
frame: 데이터세트를 pandas DataFrame으로 반환할 지 여부. 기본값은 None.
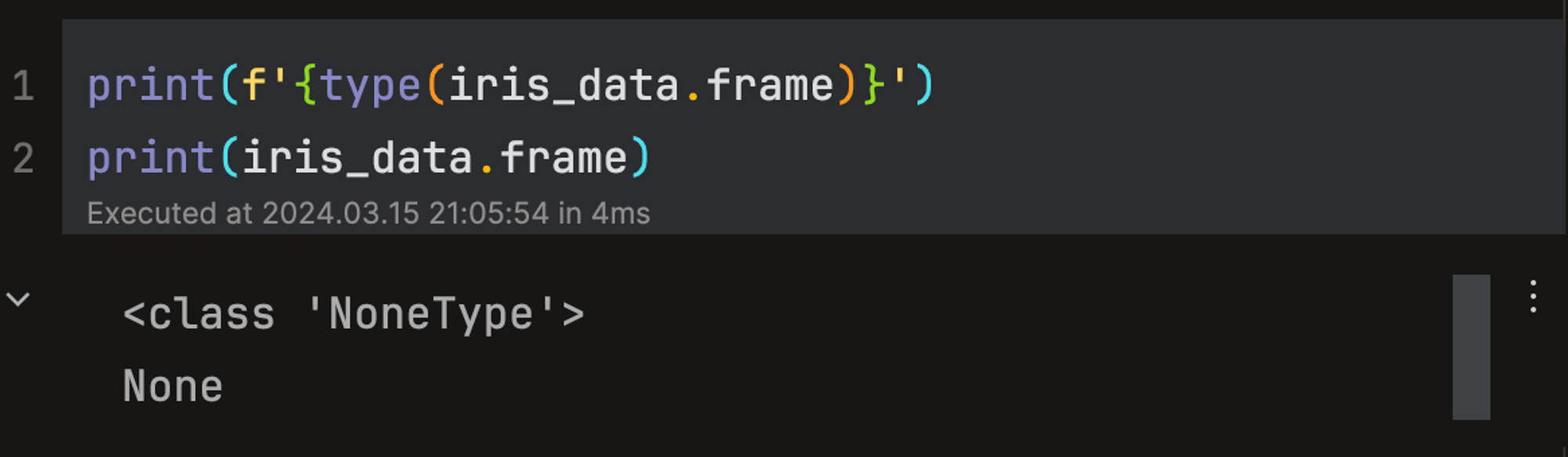
-
DESCR: 데이터 세트에 대한 설명과 각 피처의 설명.
여기서는 iris 데이터셋에 대한 자세한 설명을 나타낸다.
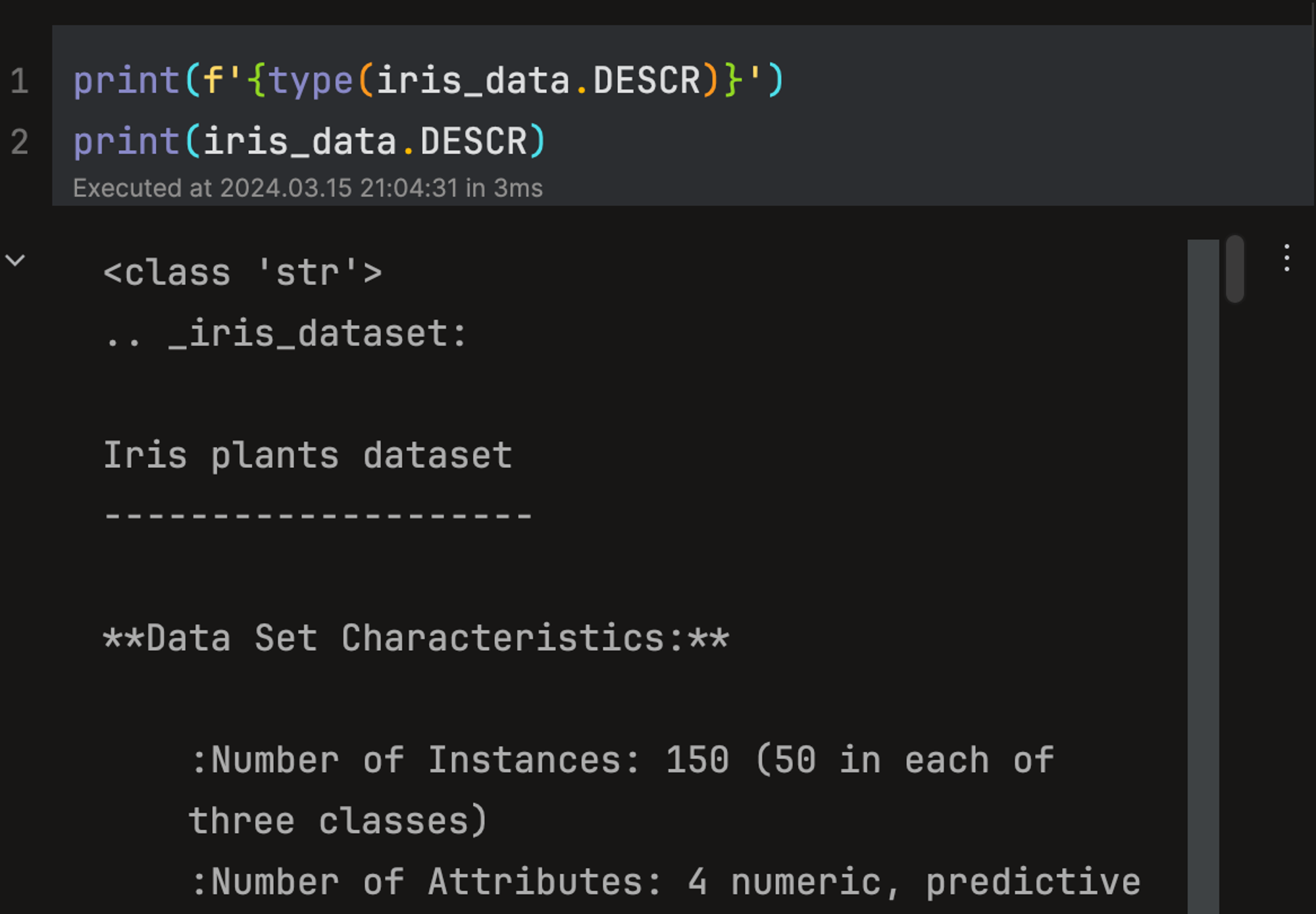
-
filename: 데이터 세트가 저장된 경로를 나타낸다.
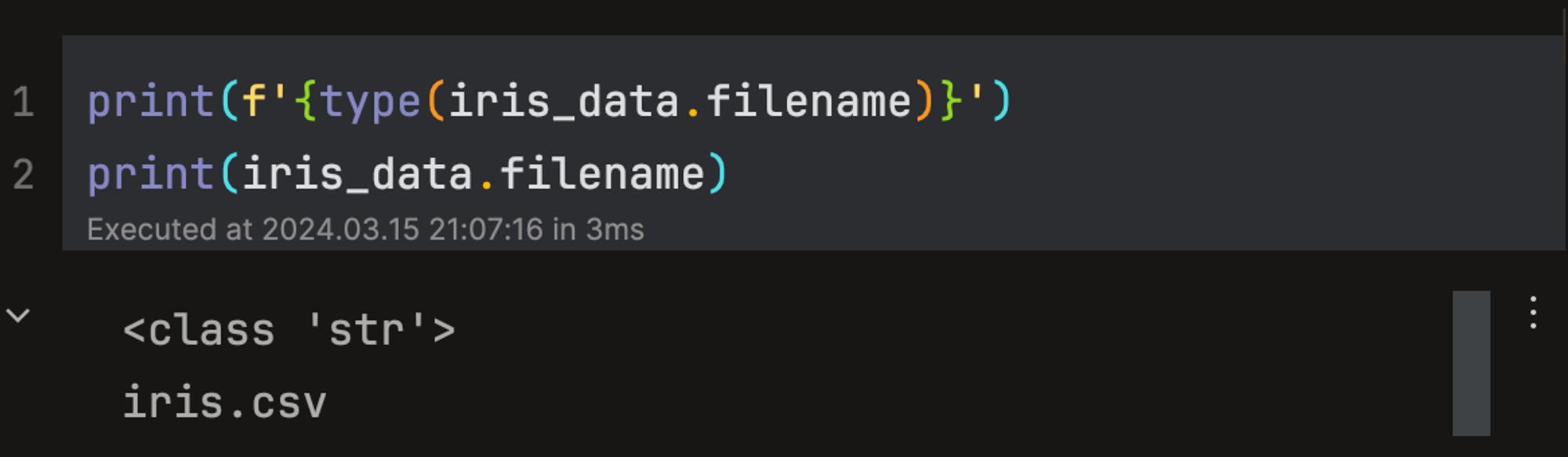
-
data_module: 데이터세트가 어떤 모듈에서 불러져왔는지를 나타낸다.
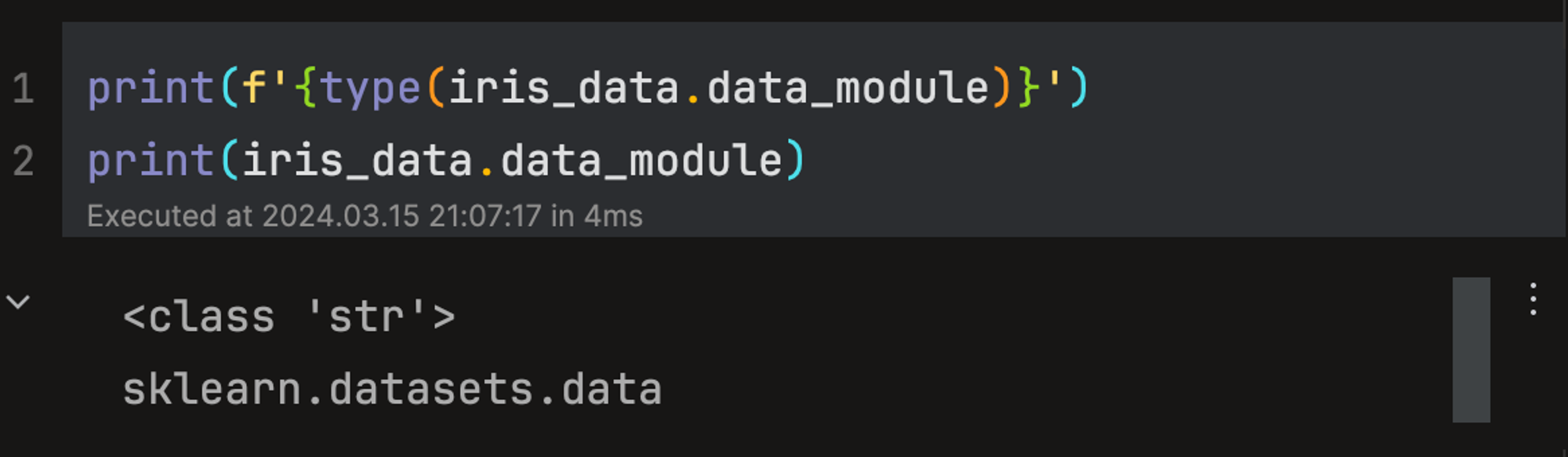
다음 그림과 같이, 피처 의미 정보에 해당하는 컬럼명은 feature_names에, 피처값들은 data에, 타겟 의미 정보는 target_names에, 타겟값들은 target 프로퍼티에서 각각 확인할 수 있다.