데이터로봇으로 AutoML 맛보기 (feat. Titanic 생존자 예측)
💡 AutoML 솔루션 데이터로봇을 이용하여 캐글 타이나틱 생존자를 예측하는 포스팅.
(📢주의) 저자는 연습용 컴피티션인 "타이타닉"을 했기 때문에 가능했지만 실제 캐글 컴피티션을 참가할 시 AutoML로 예측한 결과를 그대로 제출해서는 안된다. 엄연히 상금이 걸려있는 경진대회이기 때문에 부정 제출로 된다.(설사 높은 점수를 얻었다고 하더라도 향후 수상시 박탈되기 때문에 큰 의미는 없다)
AutoML이란.
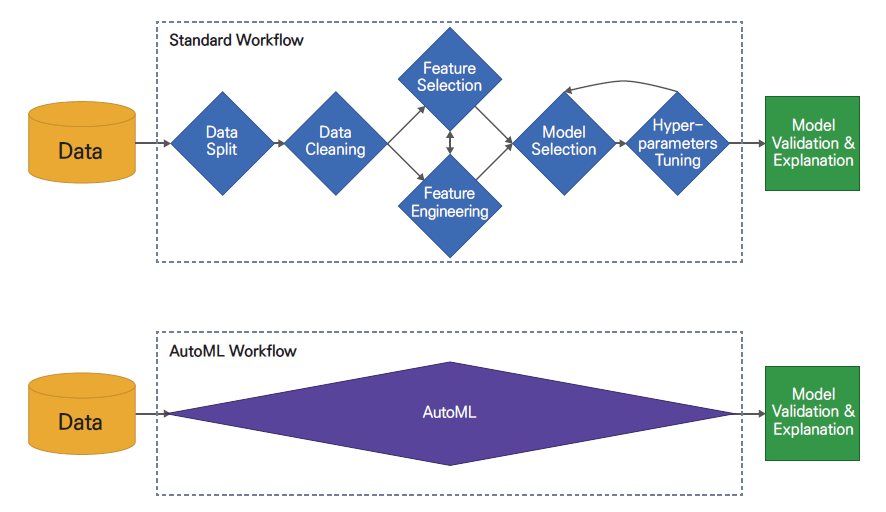
이 한장으로 요약된다.
AutoML(Automated machine learning)
자동화된 기계 학습은 기계 학습을 실제 문제에 적용하는 작업을 자동화하는 프로세스입니다.
AutoML에는 원시 데이터 세트에서 시작하여 배포 준비가 된 머신 러닝 모델 구축에 이르기까지 모든 단계가 잠재적으로 포함됩니다. 위키백과(영어)
짧게 요약하면, 데이터의 전처리부터 결과까지 모두 컴퓨터가 “자동화” 하는 프로세스를 뜻 함.
사람은 데이터를 입력하고 나온 결과를 해석하는 부분만 하면 된다.
DataRobot 소개

-
공식홈페이지 : https://www.datarobot.com/
-
소개 : Data Robot이란? DataRobot은 AI에 대한 접근을 민주화하기 위해 2012년에 설립되었습니다. 현재 DataRobot은 모든 사용자, 모든 데이터 유형 및 모든 환경을 위한 통합 플랫폼을 제공하여 모든 조직의 프로덕션 환경에 AI를 신속하게 제공한다는 비전을 가진 AI 클라우드 선두업체입니다.
-
데이터로봇은 엔터프라이즈급의 AutoML Tool로 2021 캐글 서베이에 따르면 사용율이 4.6% 전체시장점유율로는 낮은편이지만 3대 클라우드(AWS,GCP,Azure)의 상품들과 견주었을때 낮지 않은 점유율로 보여진다.
-
데이터로봇 공식문서
https://docs.datarobot.com/
데이터로봇을 도입하지 않더라도 무료로 제공하는 문서 내용들을 공부하여도 얻어갈 것이 정말 많다. 글로벌한 데이터사이언티스트 전문가분들이 만든 툴이니 그만큼 신뢰성이 높다고 생각. (Glossary페이지를 참고하여서 사내 데이터모델링 용어의 기준을 잡아도 좋다고 생각!)
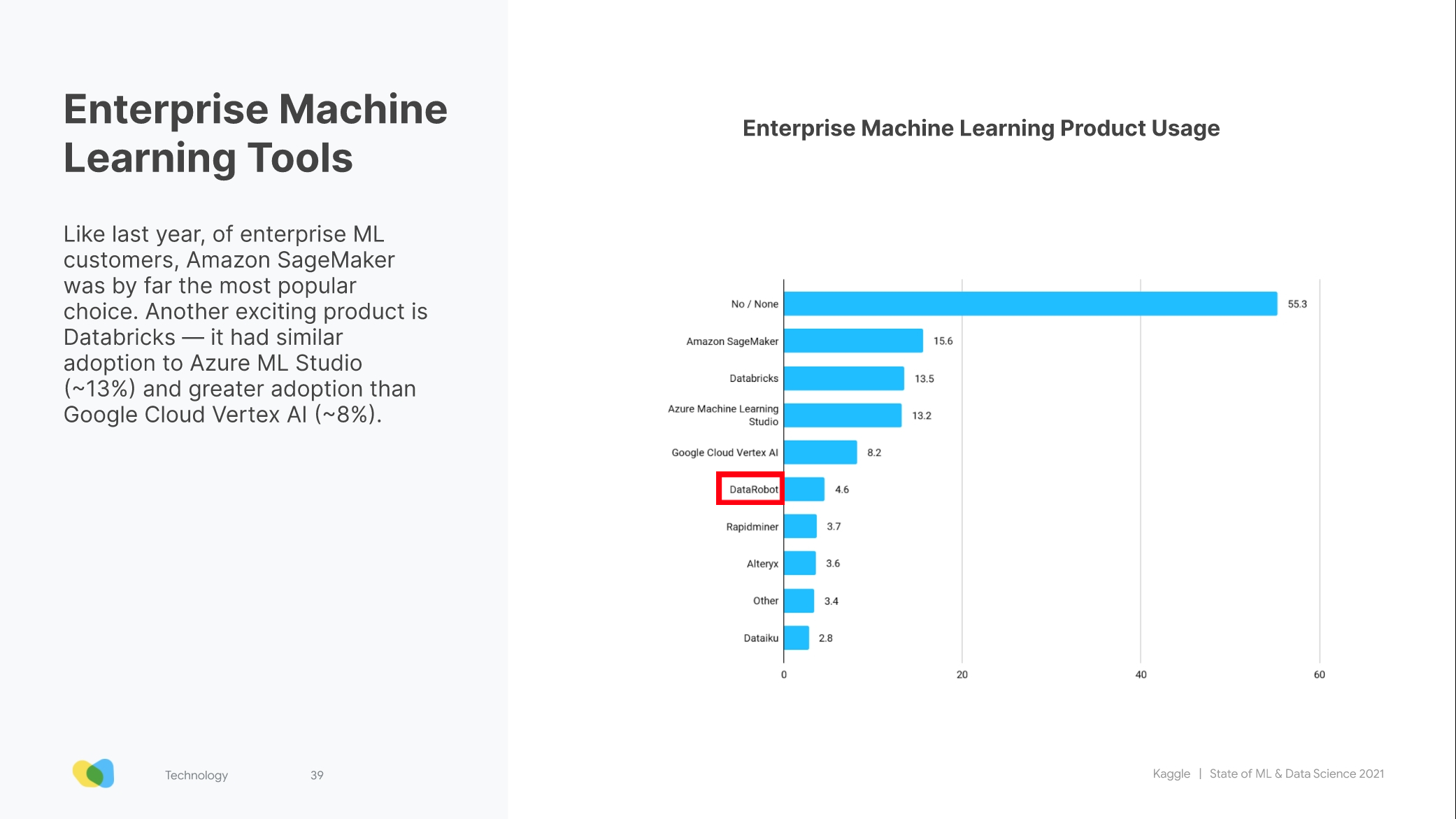 출처 :
출처 : -
데이터로봇 유니버시티
https://university.datarobot.com/
학생 대상으로 파격적인 가격인 $300(1년 구독)로 데이터로봇 기능을 사용가능한 플랜을 판매하는 것 같다. 별도 강의서비스도 제공하고 있으니 참고해봐도 좋을 것 같다. (프리미엄은 $1200)
-
커뮤니티
https://community.datarobot.com/
그 외에도 사용자 커뮤니티 등이 활발하여서 사용중에 어려운 점들이나 새로운 기능 릴리즈 등을 서로 공유하고 빠르게 도움을 받을 수 있을 수 있다.
1. 데이터로봇 접속 & 계정생성
- https://www.datarobot.com/ 로 접속 > [START FOR FREE] 버튼 클릭.
계정을 “생성” 후 이메일 인증하기. (gmail을 권장함)
2. 프로젝트 생성 & 데이터 입력
- [Quick Start] 선택. 프로젝트명은 기본으로 설정. 데이터는 타이타닉 “train.csv” 를 업로드하기
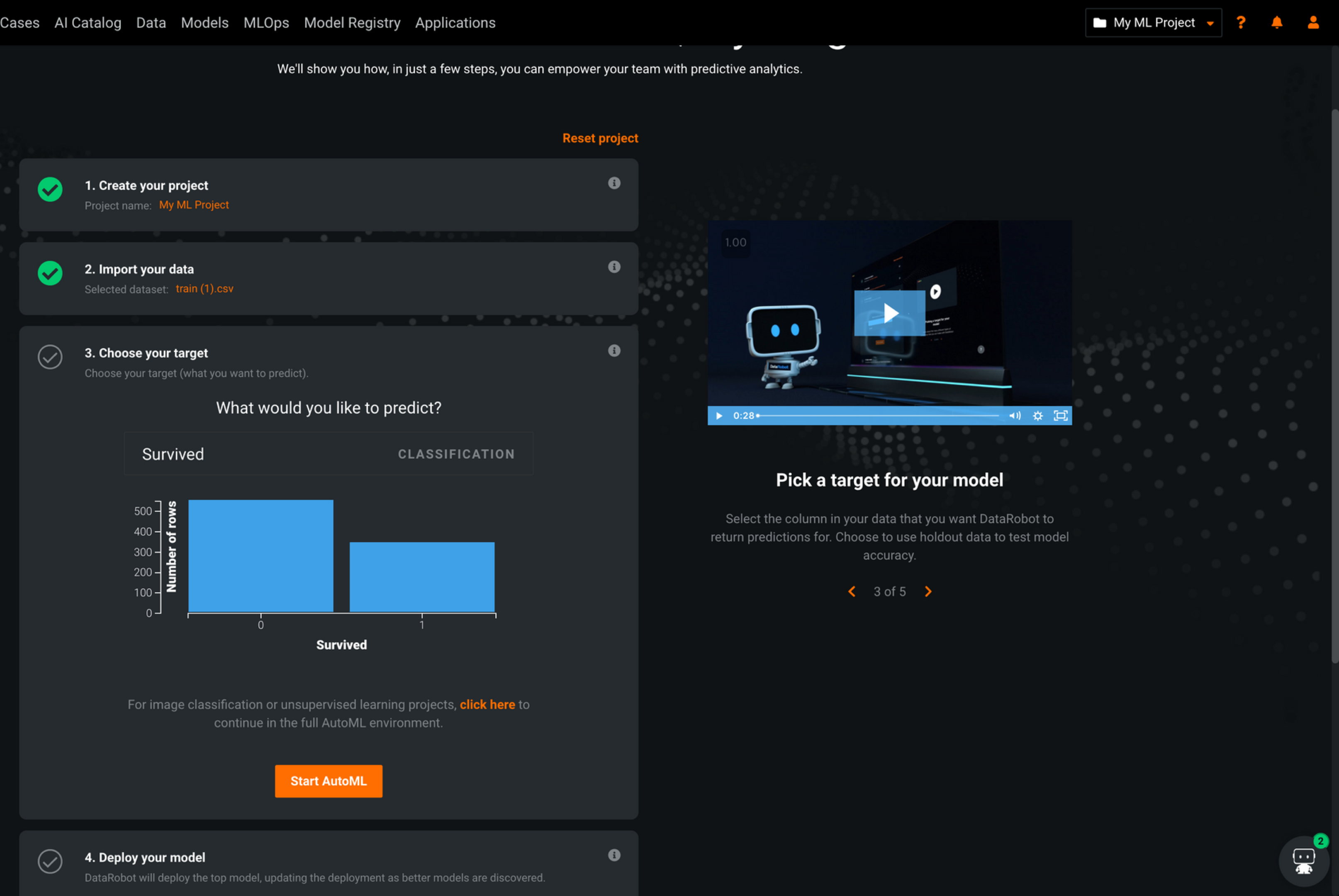
3. 타켓을 정하기
- 예측하고 싶은 타겟컬럼을 선택. 타이타닉 데이터는 생존여부를 알고 싶은 것이므로 “Survived”를 선택.
확인 후 [Start AutoML] 클릭.
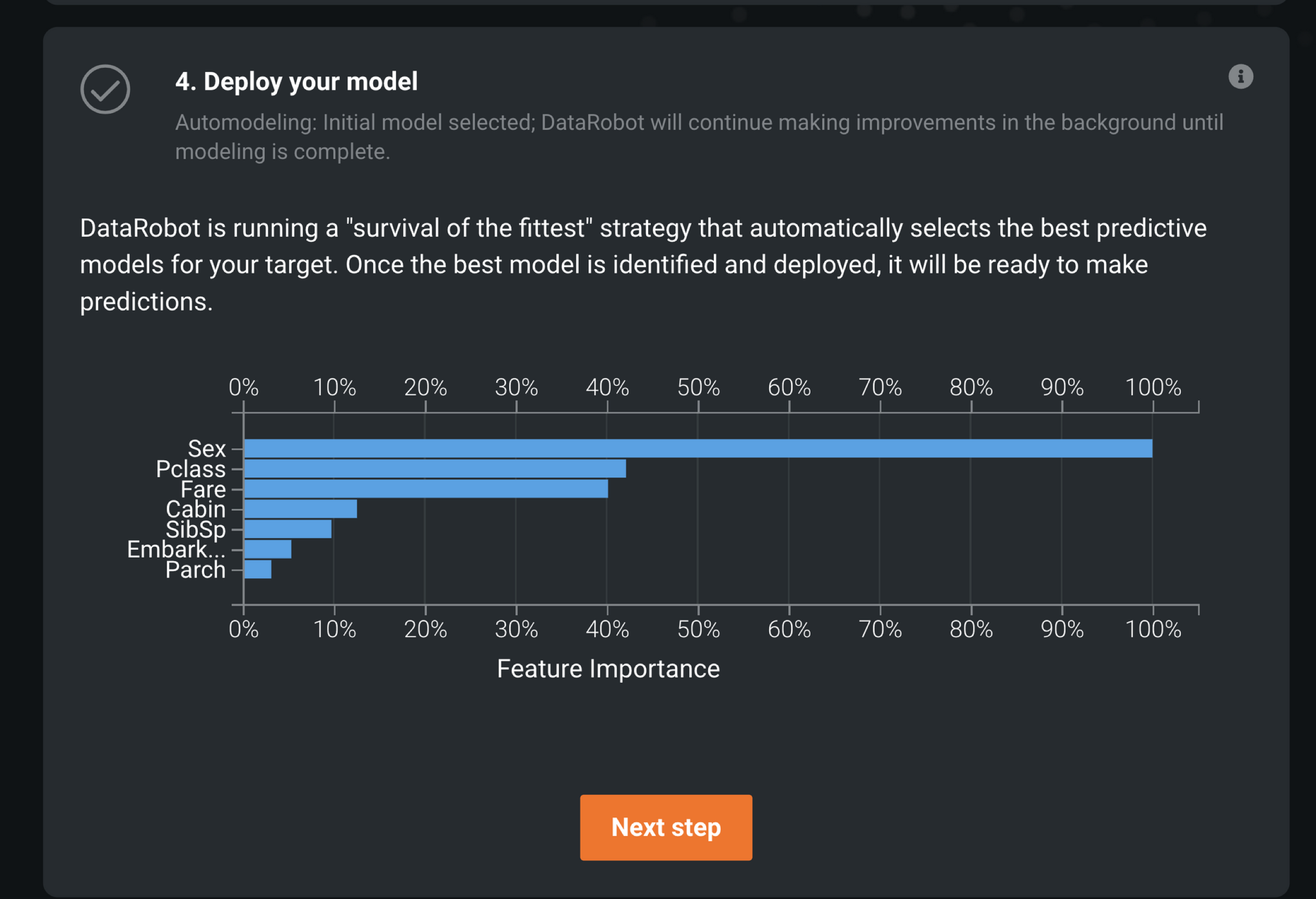
4. 모델 배포하기
- 일정 시간이 지나면 학습된 모델이 생성됨.
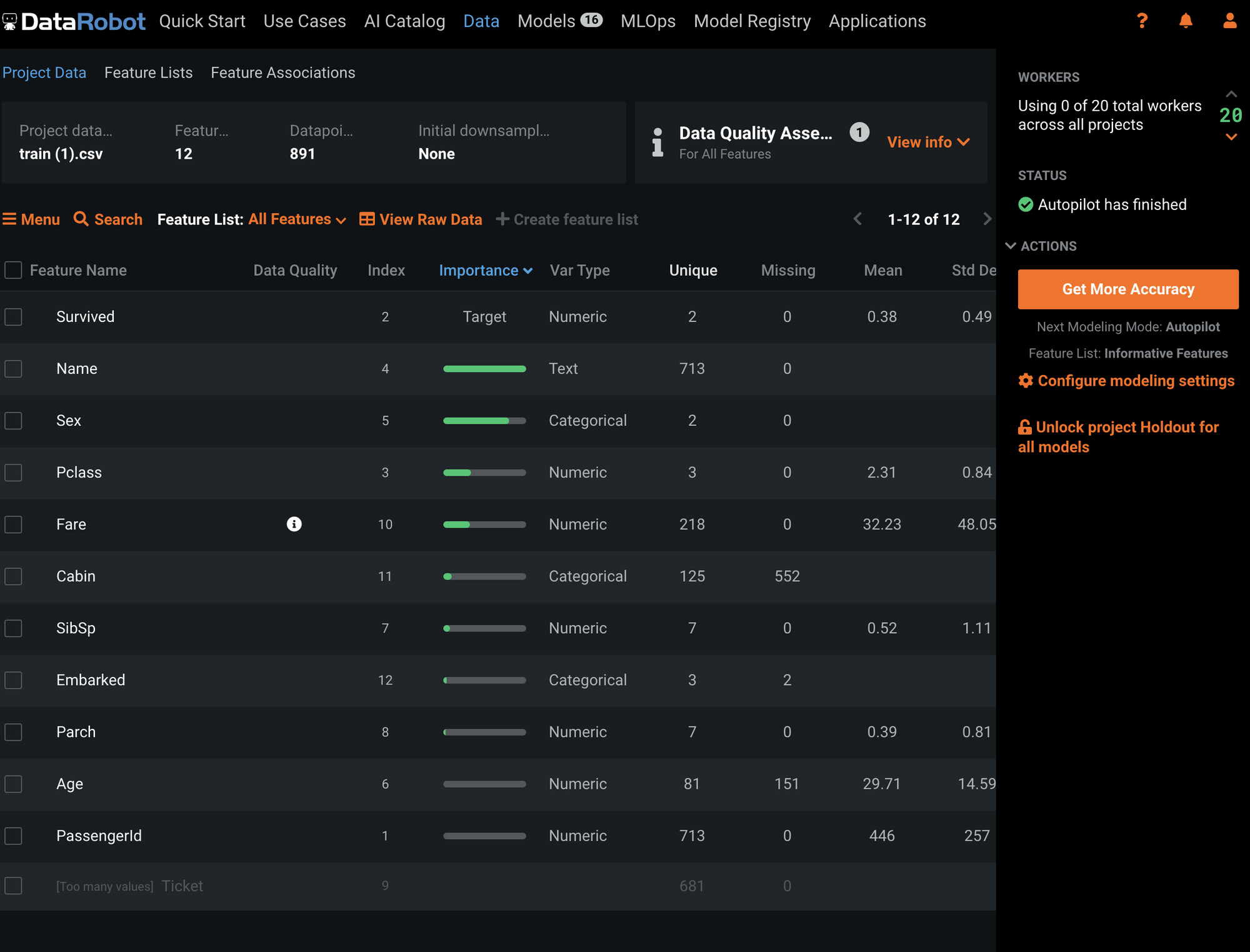
모델에서 가장 중요도가 높은 피쳐들의 순위를 보여줌.
[Next Step] 누르기
5. 모델 예측하기
- 데이터는 타이타닉 “Test.csv”를 업로드하기.
일정 시간이 지나면 Test를 예측한 결과를 도출함.
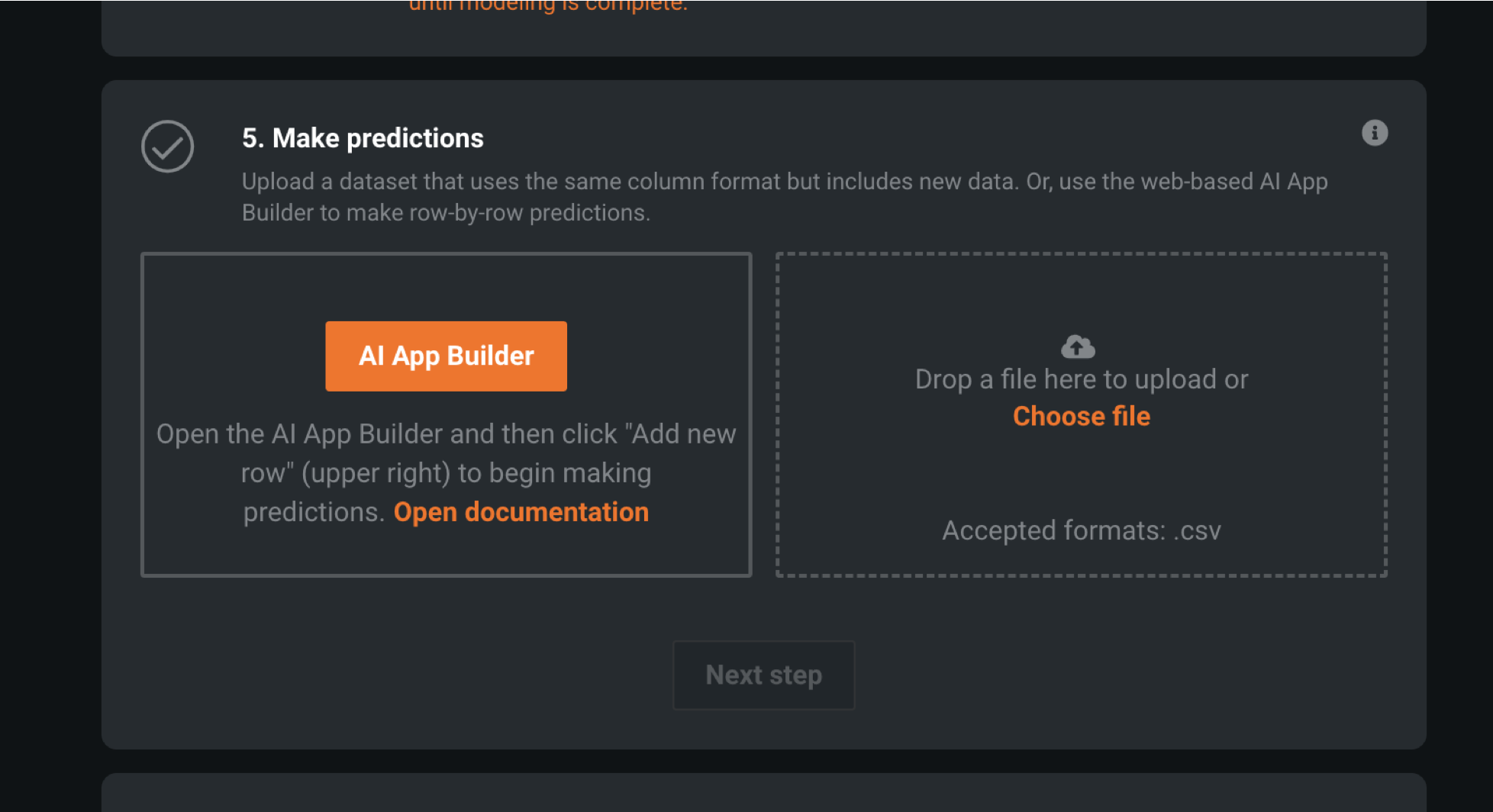
- 예측된 결과 레포트를 다운로드하기
6. 캐글 "타이타닉" 프로젝트로 업로드하기.
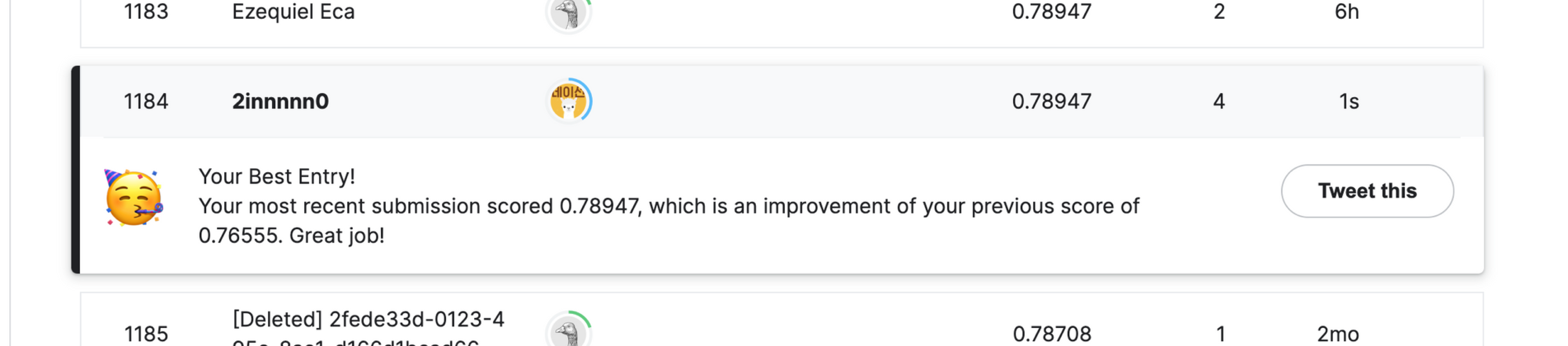
- submission 결과양식에 맞게 업로드하면 다음과 같은 결과를 나온다. 정확도Accuracy가 0.78947로 최고점을 받았다.(기존 점수 0.76555는 sklearn을 이용한 예측결과)
7. 결과 리포트 해석하기
- 위에 같이 어떤 방식으로 높은 결과를 도출했는지 모델을 별도 리포트로 설명해준다.
- Overview
- 프로젝트의 전반적인 요약 설명이 적혀있음. 16개의 모델(청사진)을 생성함.

- Trusted AI(신뢰가능한 AI)
- 14가지 기준에 근거하여서 모델의 신뢰성을 높임
- 본 리포트에서는 그 중 가장 높은 인사이트를 가지는 3가지를 소개.(데이터퀄리티, 정확도, 해석능력)
- 학습에 사용한 데이터는수는 891개. 12개의 피쳐를구분하였고, 타켓피쳐는 Surived (0,1). 12개 피쳐중 11개는 “정보성”을 갖춘 피쳐로만 채택(3개 카테고리. 7개 수치형. 1개 문자)

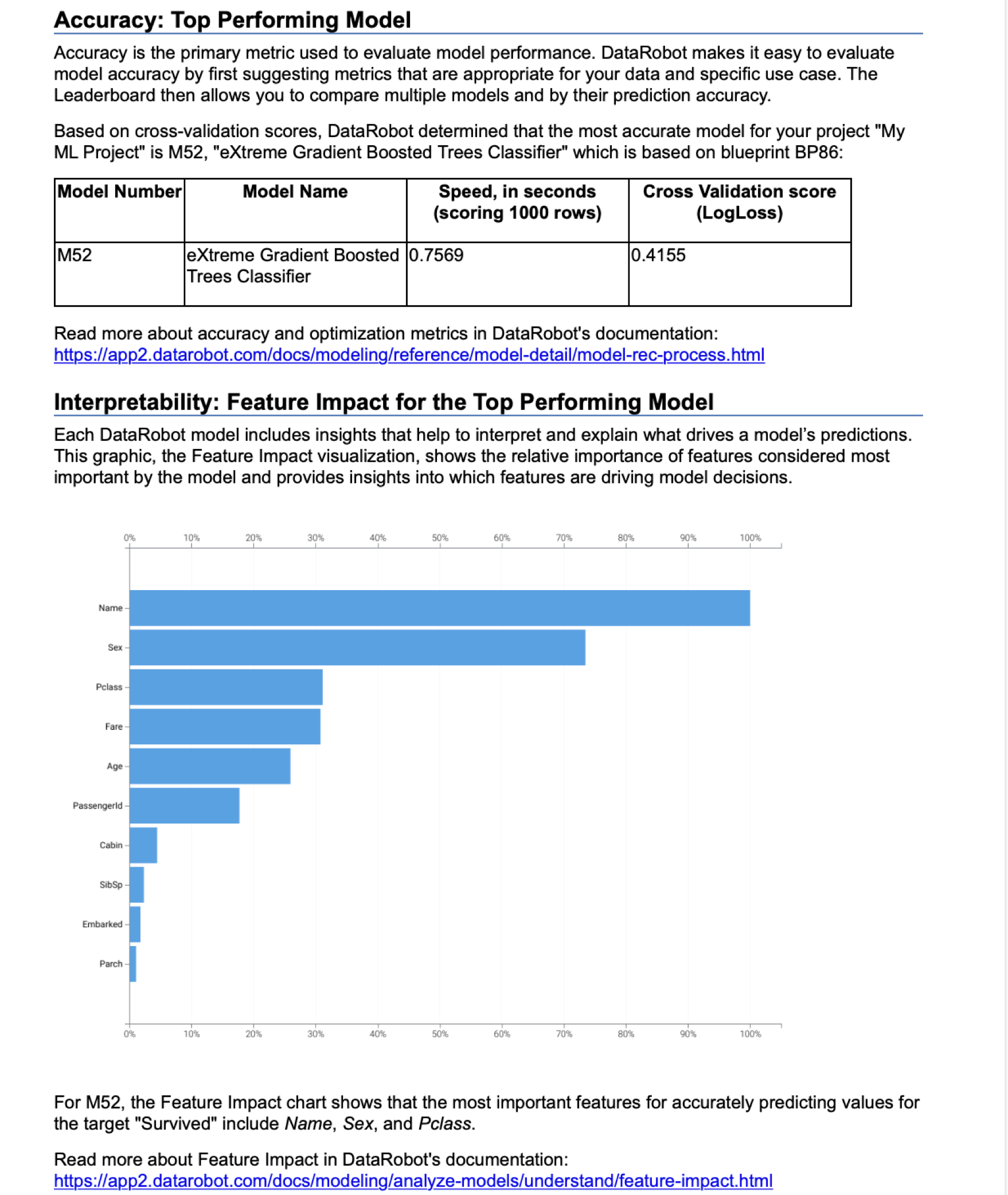
- Accuracy(정확도:최고 성능 모델)
- "52번 모델” XGBoost 분류나무 기법으로 만들어진 것. 에러스코어는 0.4155
- Interpretablility 해석력(Feature Importance)
-
가장 모델 학습에 영향을 미친 피쳐를 설명. 컴퓨터가 해석했을 때, Name > Sex > Class 순으로
중요도가 정해졌음. -
컴퓨터는 우리가 보기에 알기 어려운 패턴이나 정보들을 추출함.
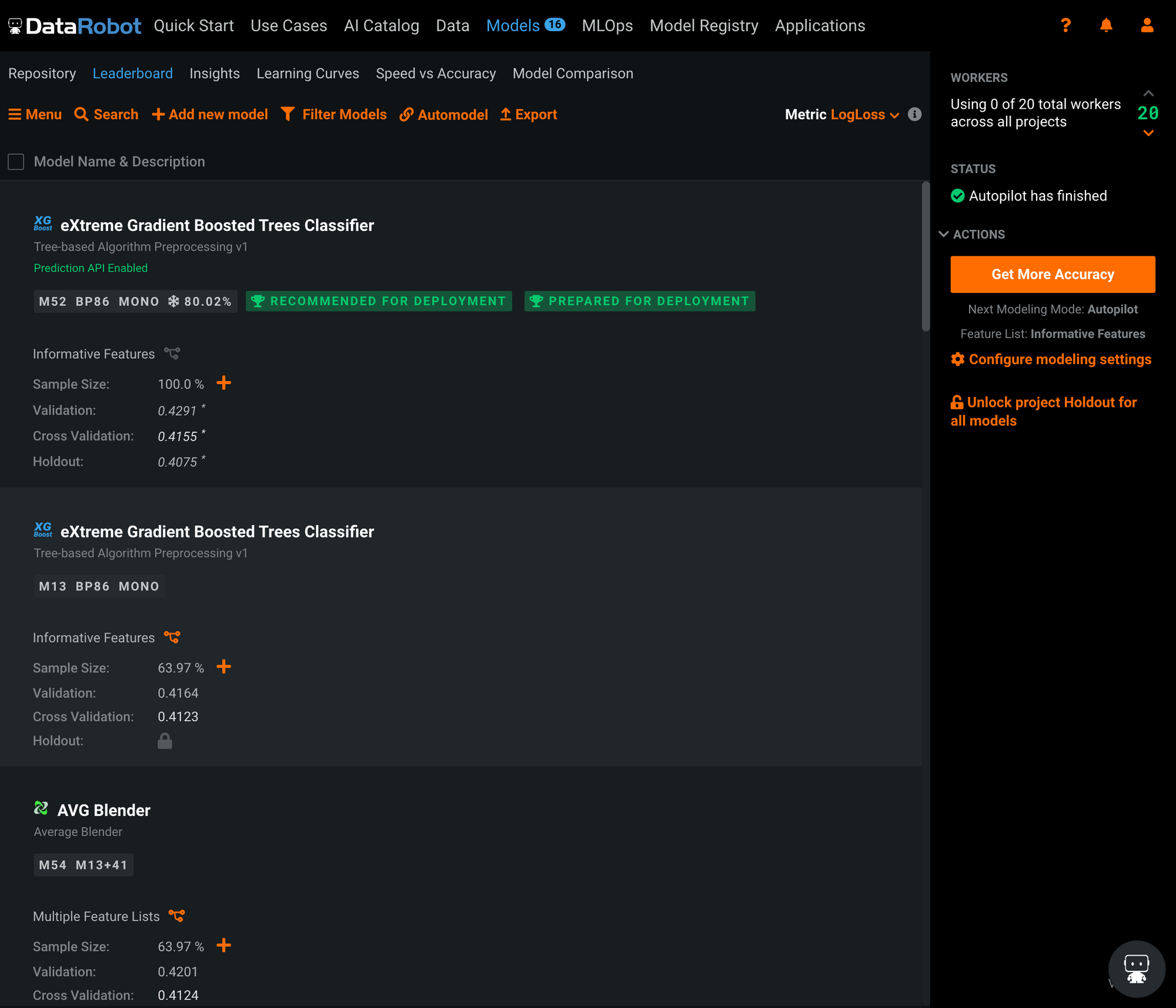
8. 생성된 모델 살펴보기
- 이 부분은 기회가 되면 다음 포스팅으로..
마무리(느낀점)
- AutoML로 데이터모델링이 좀 더 쉬워졌다는 것을 충분히 경험할 수 있었다. (데이터 입력하고 결과까지 도출하는데 5분 미만.)
Name같이 큰 의미없어 보이는 피쳐도 컴퓨터는 사람이 발견하지 못하는 패턴을 발견하는 것이 무척이나 신기했다. 그리고 컴퓨터가 발견해준 패턴을 토대로 좋은 영감을 얻어 사람이 새로운 피쳐들을 개발하는 가능성을 얻게됨.- AutoML 역시 만능이 아니기 때문에
Garbage In Garbage Out원칙을 따른다. - 여전히 사람의 손을 많이 타야하고 현업에서는 "왜" 모델이 그렇게 해석했는지 이해가 필요하기 때문에 모델링 결과를 프로덕션에 적용하기까지에는 많은 논의가 필요하다.
- AutoML 오남용하지 말자. 모델을 이해하고 쓰자! 라고 끝으로 정리해보고 싶다.

좋은 글 감사합니다! AutoML 서비스 시장 조사를 하고 있어서 흥미롭게 읽었네요.