실리콘밸리에서 날아온 데이터 엔지니어링 스타터 키트 with Python 를 강의를 요약한 내용입니다.
빠르게 옮겨쓰여져서 오탈자가 많습니다. 빠른 수정이 어려우니 양해부탁드립니다.
서론 - 조급해하지 말자.
-
지금 내가 하는 일에서 작은 성공을 계속해서 하는 것. 불안감을 해소하기.
-
내가 지금 뭔가 배우고 있다는 것에 집중하기.
-
맥스의 본인 이야기를 하면서 인생의 굴곡과 변곡점을 보여줌.
- Explore and Exploit
- 탐색하고 폭발적으로 터뜨리기.
- 다양하게 많이 해보고 실패를 경험하면서 내가 잘할 수 있는 것 재미를 찾을 수 있는 것을 찾은후 계속해서 정진하면서 행복해지기.
-
배움의 패턴
- 처음에는 버티는 힘이 중요.
- 내가 뭘 모르는지는 생각해야함 → 어디서 막혔는지 구체적으로 질문하기.
- 지금까지 5기를 진행하면서 알았던 점은 취업준비를 많이 함.
- 본인이 생각했을때 풀타임으로 6개월은 집중해야함. 그러나 실제로는 그것이 어렵기 때문에 2~3달에 하려고함. 그러다보니 포기하고 정체가 생기고 계속 딜레이됨. 계속해서 정체기를 극복하지 못하면 거기에 머무를 수 밖에 없음.
- 본인이 보았던 어느 취업준비생은 4년째 했다고 함.
- 잘하는사람보고 기죽지 않기.
- 자신감의 상실 - 남과 비교.
- 서포트 네트워크, 커뮤니티의 부재. 나와 비슷하게 일하는 사람들과 많이 만나자
- 재교육의 필요성
데이터 팀의 역할 소개
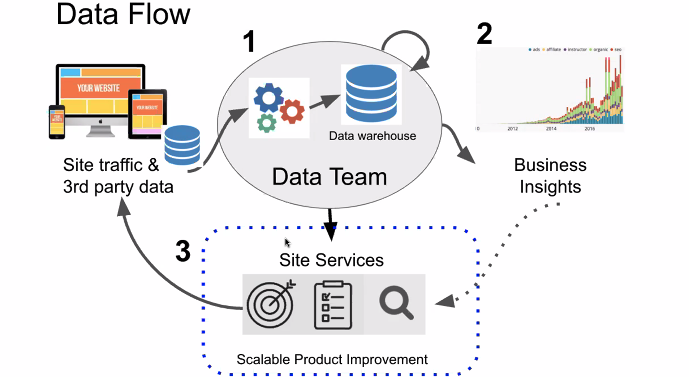
- 데이터 플로우
- 웹트래픽 또는 서드파티로 부터 발생한 데이터
- 데이터팀은 이런 데이터를 수집하여서 데이터웨어하우스에 저장함. (이것을 데이터 인프라 작업)
- 수집하는 것은 ETL 작업. (Extract - Transform - Load) 요새는 ELT가 대세. 빠르게 적재하고 변환을 나중에
- 이런 업무를 하는 것을 엔지니어가 함.
- 이제 데이터를 활용해서 볼 수 있는 분석가를 뽑음. → 비즈니스의 지표를 추출하고 문제가 있는 부분을 질문을 통해 보려고 하는 니즈.
- 지표를 정의 및 시각화해서 결정자들의 방향을 잡도록 하는 역할.
- 분석가의 역할 = dicision Science 결정과학 이라고 부르기도함.
- 분석가는 코딩하지 않지만, 데이터웨어하우스에 계속 쿼리를 날려야 함.
- 분석가로 시작해서 사이언티스트나 엔지니어로 가고 싶어하는 니즈가 있음.
- 이제 데이터사이언티스트가 비즈니스에 적용할 수 있는 기능을 만듬.
- e.g. 추천화 서비스
- 데이터 조직의 비전.
- 데이터로 돈을 버는 조직.
- 신뢰할 수 있는 데이터. - 회사에 부가가치를 만들어주는 데이터
- 데이터가 가치 자체를 만들진 않지만, 부가가치를 만듬.
- 대체로 데이터조직은 서포트하는 조직. 운영단이 잘 할 수 있도록 도와줌
- 그러면 어떻게 부가가치를 만드는가? - Desicion Science.
- 주요한 데이터를 잘 시각화하여 방향성을 잘 전달.
- data driven : 데이터가 하라는 데로 하라.
- data informed : 데이터를 참고삼아 내 판단을 하라.
- 데이터는 왼쪽이지만, 하지만 여러 상황을 고려했을때 나는 오른쪽으로 가는게 맞을거 같다.
- 이게 궁극적으로 맞는 방향이라 생각. 데이터는 과거의 것. 혁신을 위해서는 의사결정자가 데이터를 보고 판단하여야 함.
- 데이터로 돈을 버는 조직.
- 데이터 조직의 구성원
- 데이터분석가 (Decision Science)
- 내부 직원들이 주 고객 (Internal)
- BI 책임.
- 지표 설계 및 대시보드 생성.
- 내부 고객의 질문에 답변을 해야함.
- 질문이 너무 많고 빨리 달라고 하고.. 함
- 이러다 보면 커리어패스에 문제가 생김.
- 질문이 너무 많고 빨리 달라고 하고.. 함
- 스킬셋
- SQL/HIVE
- R/SAS
- 비즈니스 도메인 지식이 필요.
- 기본적으로 코딩을 하지 않지만 점점 에어플로우와 개발지식을 많이 선호함.
- 풀스택 데이터 직군.
- 그래서 비교적 문과생이 쉽게 접근가능한 직무.
- 딜레마
- 질문답변이 재미가 있지 않고.
- 퍼포먼스 측정이 어렵고
- 어느 팀에 속해있는지 모르겠고
- 나의 커리어성장이 어떻게 될지 모르겠음.
- 데이터사이언티스트 (Product Science)
- 서비스를 사용하는 주 고객(External)
- 알고리즘으로 유저의 경험을 상승 시켜주는 업무
- 인내와 실용적인것이 필요 - 박사학위가 있을수록 좋음(포기를 잘하지 않는 성격)
- 스킬셋
- 파이썬/스파크 코딩 기본.(못하면 절름발이 - 속도가 안남)
- 머신러닝의 깊은 지식과 경험이 필요.
- SQL
- R/SAS/Matlab (수학, 통계지식)
- 데이터엔지니어
- 데이터 웨어하우스 (vs. 데이터 레이크)
- 여기서 실습은 redshift로 함.
- 대용량 데이터를 다루는 DB : 레드시프트, 빅쿼리, 스노우플레이크, 스파크
- 데이터 파이프라인(ETL)
- 에어플로우
- A/B 테스트
- 데이터툴
- 데이터팀 조직 구조 : 면접볼때 물어보기. 어떤 형태로 하는지.
- 중앙집중 - centralized
- 소통이 좀더 내부적으로 유리함.
- 데이터팀에서 좀더 행복도가 높음.
- 그러나 현업단에서는 답을 빠르게 얻지 못해서 느리다고 생각해서 불만이 쌓임.
- 분상 구조 - Decentralized
- 아무리 잘한다고 해도 내 커리어는 해당 도메인 말고는 발전이 없음.
- 하이브리드
- 다양한 경험을 할 수 있도록 로테이션 돌면서 업무를 진행.
- 그래서 커리어패스도 생기고, 현업의 불만도 잠재울수 있음.
- 중앙집중 - centralized
- 레슨런
- 데이터로는 반드시 돈을 벌어야 함. 그렇지 않다면 존재 이유가 없음.
- 데이터조직 운용 비용은 큼.
- 이 팀이 하는 역할을 명확히 보여주지 못하면 존재가 어려움.
- 리더는 매니저를 잘해야 함. 그리고 피어와의 관계도 잘해야함.
- 인프라가 먼저
- 인프라가 없으면 아무것도 못함.
- 작은 조직은 인프라 구축이 힘듬.
- 첫번째 데이터엔지니어는 분석도 하고 ML도 해야함.
- 데이터 품질이 중요.
- 가장 많은 곳에 소요하는데 쓰는 시간은 - 데이터전처리.
- 지표가 처음
- 머신러닝이 아니더라도 모든 피쳐의 지표는 필요함.
- 성공과 실패를 결정 짓는 부분.
- 간단한 솔루션일수록 좋다.
- 데이터로는 반드시 돈을 벌어야 함. 그렇지 않다면 존재 이유가 없음.
- 데이터분석가 (Decision Science)
데이터 엔지니어링이란?
- skip 전동스쿠터 사례
- 이용자가 떨어져서 서베이를 했음 돌아온 답변은
- "아 이제 스쿠터를 사서 안씁니다."
- 데이터엔지니어의 역할.
- DW 관리
- 데이터 파이프라인 관리 생성
- 데이터 파이프라인
- 배치 프로세싱 vr. 실시간 프로세싱
- A/B 테스트 분석.
- 요약 데이터
- 데이터 파이프라인
- 이벤트 수집
- UBL
- 스킬셋
- 파이썬, SQL 기본
- 대용량 - spark 하나만 잘 알아도 됨
- 주니어가 다 알긴 어렵.
- 오늘부터 데이터 엔지니어 시작. 무엇부터 해야할까?
- 데이터 인프라 생성
- 데이터웨어하우스
- Mysql 데이터를 분석을 위해 마이그레이션하기.
- 데이터웨어하우스란
- 데이터팀의 첫번째 스탭.
- 프로덕션 DB와 별개.
- 스케일어블 해야함.
- 데이터 ETL, ELT.
- 회사가 작으면 cronjob으로 해도 됨. 규모가 늘어나면 에어플로우.
- 데이터 인프라 생성
1주차 요약
- 이번 스터디에서는 1번을 배우고 약간의 2번을 배움.
- 엔지니어링을 배우는 것이 먼저일거라 생각했는데, 멘탈관리에 대한 언급을 하여서 신선하였음. 롱런을 바라보고 하는 공부이기에 지금 누가 당장 잘하냐를 따지기 보다는 어제의 나와 계속 비교해가며 앞으로 나아가는 것이 중요!

성장한 데이터분석가