
1. Pyspark 설치
!pip install pyspark2. Pyspark Session 생성
from pyspark.sql import SparkSession
spark=SparkSession.builder.appName('Dataframe').getOrCreate()
spark
3. 데이터셋 불러오기
df = spark.read.option('header','true').csv('train.csv',inferSchema=True)- option('header','true')를 통해 첫행을 컬럼명으로 지정. 주의할 점은 모두 소문자로 작성한다.
- csv(, inferSchema=True)를 통해 데이터형을 추론된 것으로 자동적으로 부여된다. (수치형은 IntegerType 또는 DoubleType, 문자열은 StringType) False로 하면 StringType으로 모두 설정된다. 데이터형을 불러올 때 잘 가져와야 나중에 번거롭지 않다.
4. 데이터셋 표시하기
df.show()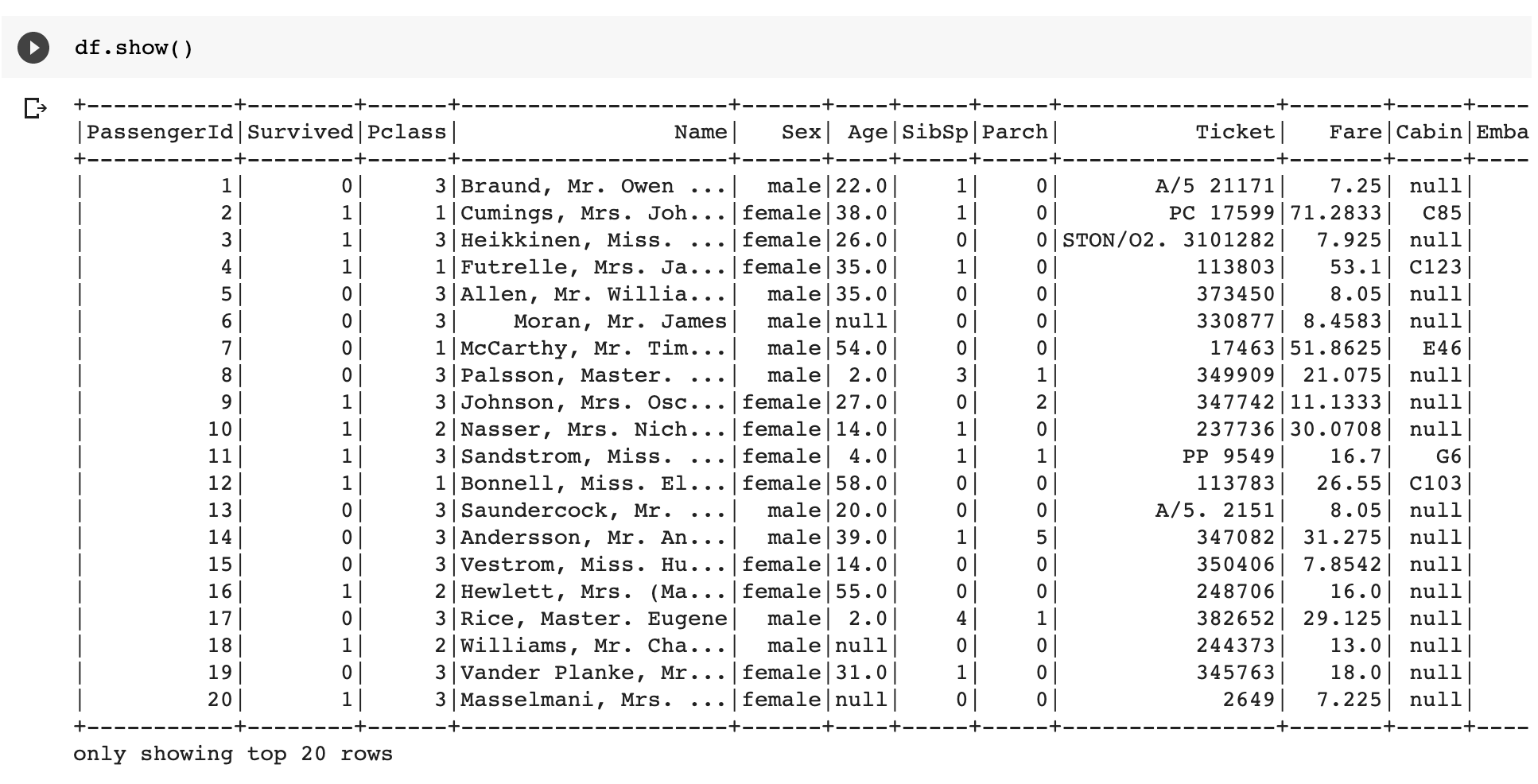
- 상위 5개만 출력한다면 아래와 같이 입력.
df.head(5)

성장하고 싶은 데이터분석가.