
문서 목적
해당 문서는 실무로 배우는 빅데이터 기술에서 HBase에 대해 공부하기 위해 작성된 문서이다.
HBase
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
> https://hbase.apache.org/
하둡 기반의 컬럼 지향 NoSQL 데이터베이스로서 스키마 변경이 자유롭고, 리전이라는 수십~수백 대의 분산 서버로 샤딩과 복제 등의 기능을 지원해 성능과 안정성을 보장한다.
하둡의 확장성과 내고장성을 그대로 유지할 수 있어 대규모 실시간 데이터 처리를 위한 스피드 레이어 저장소에 HBase가 주로 사용된다.
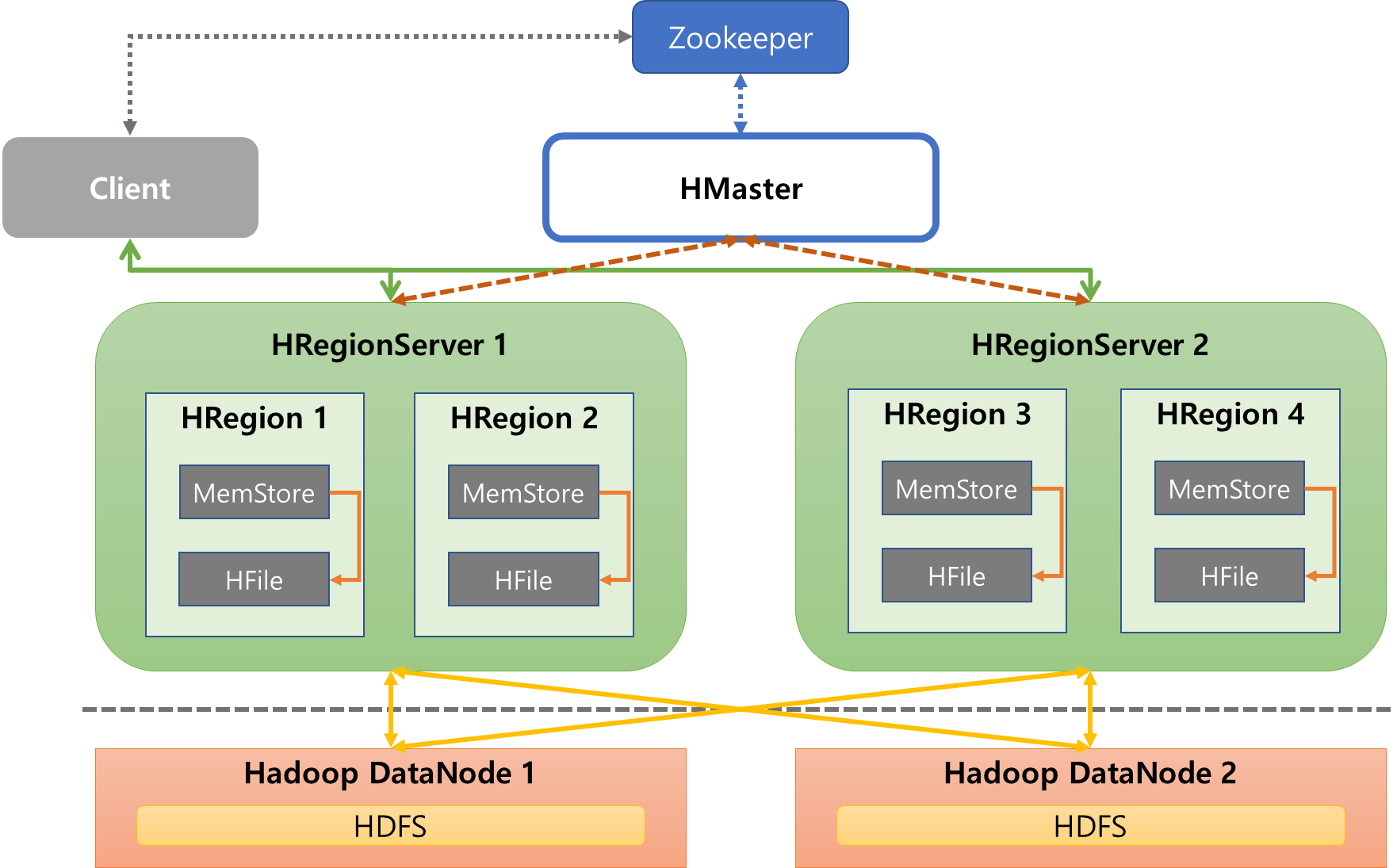
주요 구성 요소
- HTable : 컬럼 기반 데이터 구조를 정의한 테이블, 공통점이 있는 컬럼들의 그룹을 묶은 칼럼 패밀리와 테이블의 로우를 식별해서 접근하기 위한 로우키로 구성
- HMaster : HRegion 서버를 관리하여, HRegion들이 속한 HRegion 서버의 메타 정보를 관리
- HRegion : HTable의 크기에 따라 자동으로 수평 분할이 발생하고, 이때 분할된 블록을 HRegion 단위로 지정
- HRegionServer : 분산 노드별 HRegionServer가 구성되며, 하나의 HRegionServer에는 다수의 HRegion이 생성되어 HRgion을 관리
- Store : 하나의 Store에는 칼럼 패밀리가 저장 및 관리되며, MemStore와 HFile로 구성됨
- MemStore : Store 내의 데이터를 인메모리에 저장 및 관리하는 데이터 캐시 영역
- HFile : Store 내의 데이터를 스토리지에 저장 및 관리하는 영구 저장 영역
Architecture
HDFS를 기반으로 설치 및 구성된다는 것이 가장 큰 특징으로, 가용성과 확장성을 그대로 물려받음
저장 방식
- Client가 HBase에 테이블에 특정 데이터를 저장하기 전 주키퍼를 통해 HTable의 기본 정보와 해당 HRegion의 위치 정보를 알아냄
- 해당 정보를 기반으로 클라이언트가 직접 HRegionServer로 연결되어 HRegion의 Memory영역인 MemStore에 데이터를 저장
- MemStore에 저장된 데이터는 특정 시점이 되면 HFile로 HDFS에 flush 되고, HFile은 HRegion의 상황에 따라 최적의 HFile로 재구성되는 작업이 이루어짐(Minor/Major Compaction)
load 방식
- 주키퍼를 통해 RowKey에 해당하는 데이터의 위치 정보를 알아내고 해당 HRegionServer의 Memory 영역인 MemStore에서 데이터를 가져옴으로써 디스크 I/O를 최소화하면서 빠른 응답 속도를 보장
- 만일 데이터가 MemStore에서 플러시되어 존재하지 않으면 HFile 영역으로 이동해 데이터를 찾음
- 이때 HBase와 HDFS 사이의 모든 데이터 스트림 라인들은 항상 열려 있으므로 레이턴시가 발생하지 않음

열심히 정리하는 습관 기르기..