타이타닉 탑승객 Embedding 시각화
이번 AI Tech에서 캐글 스터디를 진행하게 되었는데, 첫주에는 타이타닉 데이터를 이용한 분석을 하기로 했다.
나는 새로운 접근법으로 타이타닉 데이터를 분석해보고 싶어, 타이타닉 탑승객의 임베딩을 구해서 이 값을 2차원에 시각화 해보기로 했다.
내가 처음에 생각한 방법은 각 변수에 차원축소 알고리즘(t-SNE, PCA 등)을 적용해 Embedding을 만드는 것 이었다. 그런데 이 방식은 그렇게 끌리지도 않았고, 단순히 one-hot encoding된 변수는 좋은 패턴을 찾을 수 없다고 생각하여 시도하지 않았다.
그래서 내가 생각한 방식은 Word2Vec을 이용한 Embedding 만들기다. Word2Vec의 CBOW 방식을 적절하게 이용하면, 반복되는 단어 사이에 적절한 패턴을 찾아 타이타닉 탑승객의 Embedding을 구할 수 있을 것 같았고, 이를 활용하여 타이타닉 탑승객들은 2차원에 시각화 하기로 했다. 솔직히 결과에 상관없이 그냥 새로운 접근법을 시도해보고 싶었는데 나름 결과도 좋게 나온 것 같아 뿌듯하다.
(0) 소개 및 요약
나는 항상 simple is the best라는 생각으로 어떻게 하면 모든 변수들의 특징을 반영할 수 있게 데이터들을 2차원에 시각화 할 수 있을 가에 대해 고민하는 편이다. 그 고민에 대한 해답이 바로 이번에 진행한 타이타닉 탑승객 시각화 이다. 본 분석에서 저는 탑승객에 대한 정보를 하나의 문장으로, 각 변수를 단어로 생각하여 Wrod2Vec - CBOW 알고리즘을 이용해 탑승객들에 대한 임베딩 값을 구했다. 본 임베딩을 t-SNE 알고리즘을 통하여 차원을 축소하여 2차원에 시각화 하였고, 시각화 결과를 보면 각 데이터들이 특정한 군집을 형성한다는 것을 알 수 있다. 이 군집들을 세세하게 분석한다면 데아터의 패턴을 더욱 쉽게 알아낼 수 있을 것이다. 왜냐하면 Word2Vec 알고리즘의 학습과정에서 데이터에 패턴 정보가 반영되어 있을 것 이기 때문이다.
(1) 간단한 EDA
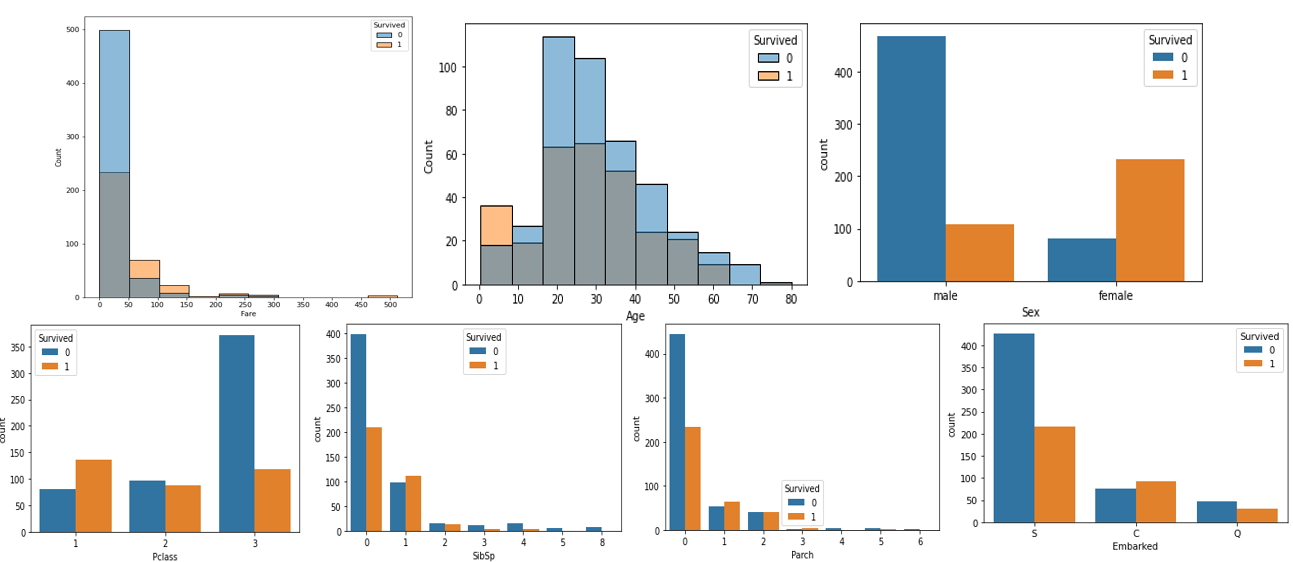
- 우선은 각 변수에 따른 생존 여부를 판단하기 위해서 간단한 EDA를 진행했다.
- 분석 결과 여자라면, 나이가 어리다면, 1등석 손님이라면, 비싼 티겟을 구매했다면, 등에 요인에 따라서 생존율이 높은 것을 확인했다.
(2) 결측치 확인

- 간단한 EDA 결과, Age는 생존에 영향을 주는 변수라는 것을 확인했다. 그런데 이 Age에는 상당히 많은 결측치가 존재한다는 것을 확인했다.
- Cabin 이라는 변수는 1등석, 2등석 등 숙소의 위치를 나타낼 수 있는 변수기 때문에, 생존에 영향을 주는 변수라고 생각을 했다. 그런데 Cabin 에도 나이보다도 더 많은 결측치가 존재한다는 것을 확인했다.
- 그래서 이 결측치를 효과적으로 채울 수 있는 방법을 고민했다.
(3) 결측치 채우기

- Age의 경우 Name에 Mr, Mrs, Master 등의 격식 표현에 따라서 Age를 유추해볼 수 있다는 것을 확인했다. 그래서 본 표현에 따른 평균 Age를 기준으로 결측치를 채웠다.
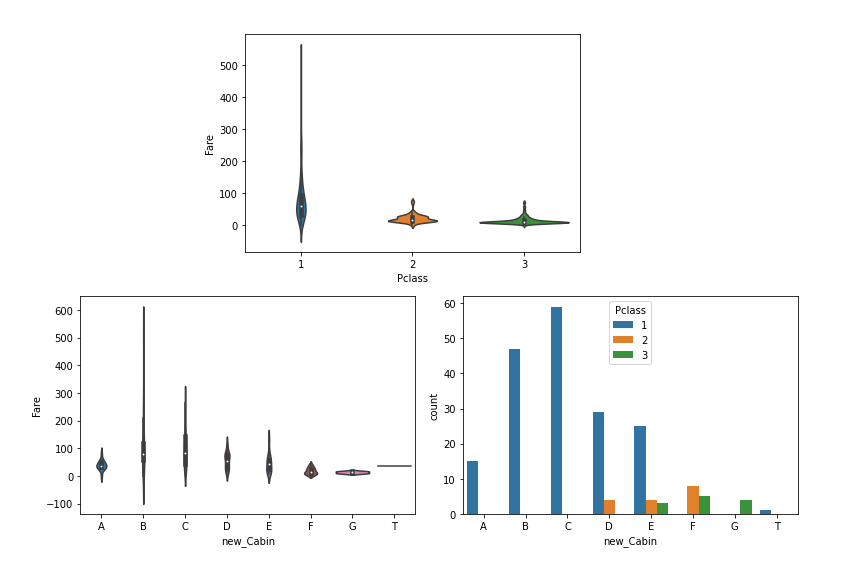
- Cabin의 경우 Pclass, Fare등과 연관성이 존재한다는 것을 확인했고, 1등석 손님일 수록 앞쪽 알파벳에 존재한다는 것을 확인했다. 그런데 본 변수의 경우 너무 많은 결측치를 가지고 있고, 또한 이미 Pclass, Fare에 Cabin에 대한 정보가 어느정도 반영되어 있다고 판단하여 결측치를 채우지 않았다.
(4) Word2Vec - CBOW
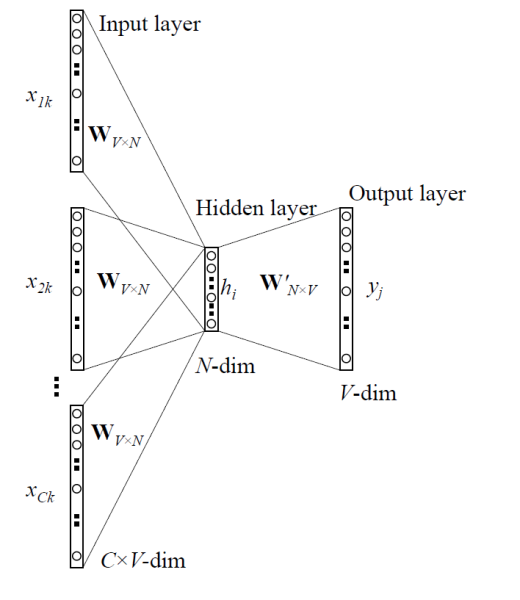
- 하나의 행이 탑승객의 정보를 의미하고, 하나의 행을 하나의 Sequence Data 즉 문장으로 생각해본다면, 각 변수들은 단어로 볼 수 있으며, 이를 Word2Vec을 활용해 탑승객의 Embedding을 구할 수 있다고 생각했다.
- 그래서 유저의 고유 정보와 Cabin 변수를 제외하고 생존에 영향을 줄 수 있는 변수를 활용해 탑승객의 Embedding을 구했다.
- 알고리즘의 경우 CBOW를 활용했는데, CBOW는 그림처럼 주변 단어가 주어졌을 때 타겟 단어가 나타날 확률을 최대화 해주는 방식으로 학습되는 알고리즘이다. 나는 이 CBOW 알고리즘을 활용하여 주변 단어 즉 주변 변수가 주어졌을 때, 타겟 단어 즉 해당 탑승객이 나타날 확률를 최대화 하여 탑승객의 Embedding을 구했다.
- Word2Vec 알고리즘의 특성상 서로 비슷한 변수가 존재하는 탑승객 끼리 가까워지는 방식으로 Embedding이 생성되었을 것이다.
- 그런데 나는 변수를 단어로 만들때 각 변수가 연속형 변수라면 그 값의 수가 매우 많아져 효과적인 학습이 될 수 없다고 판단했다. 그래서 연속형 변수를 범주화 하여 모델을 학습시켰다.
(5) 연속형 변수의 범주화
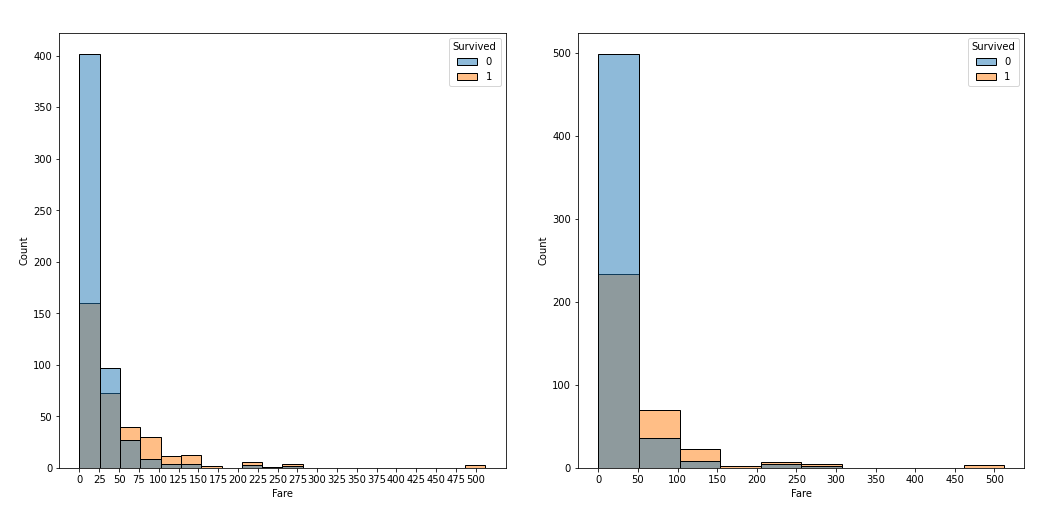
- Fare의 경우 25달러, 50달러를 기준으로 범주화를 시도해봤다. 결과적으로 25달러는 더 밚은 특징을 살릴 수 있지만 너무 세분화 되어 비슷한 변수의 수가 줄어들 수 있다고 판단하여, Fare의 특징을 살리면서 범주의 수도 적당한 50달러를 기준으로 범주화를 진행했다.

- Age의 경우 4살, 8살, 10살을 기준으로 범주화를 시도해봤다. Age 또한 Fare와 동일한 이유로 Age의 특징을 살리면서 범주의 수도 적당한 8살을 기준으로 범주화를 진행했다.
(6) 시각화 결과
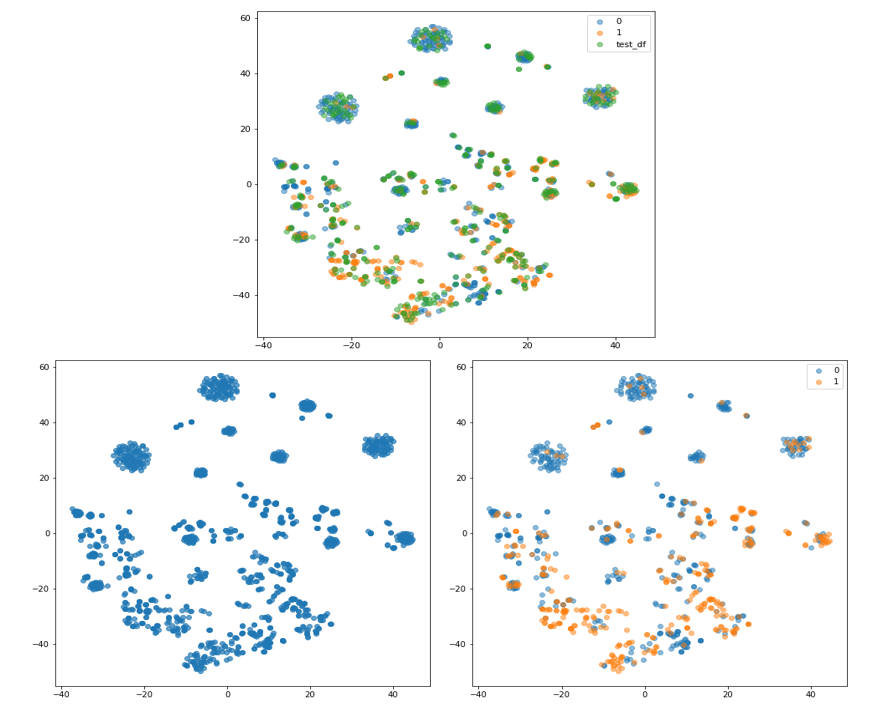
- Embedding을 t-SNE 알고리즘을 이용한 2차원으로 축소하여 시각화했다.
- 시각화 결과 생존 여부에 따라서 형성되는 군집의 특성이 다르다는 것을 확인할 수 있었다.(0의 경우 특정 군집을 형성하고 있음)
- 본 임베딩을 가지고 k-NN 알고리즘을 이용해 분류를 한다면 좋은 결과를 가져다 줄 수 있지 않을까 생각된다.
- 나아가 시각화 속에 나타나는 군집들은 특정한 패턴이 존재하기 때문에 서로 뭉쳐있을 것이다. 따라서 본 군집을 세세하게 분석하면 본 데이터의 특징을 더욱더 잘 파악할 수도 있을 것이다.
Code
참고자료

우와 Word2Vec을 이용한 Embedding 시각화 과정이 정말 깔끔합니다! 잘 읽었습니다