📍 자바(Java) 알고리즘 문제풀이 입문: 코딩테스트 대비를 공부하고 주요 내용을 정리
섹션1. String
- 문자열을 대문자 문자열로 변환
String str2 = str1.toUpperCase();
소문자로 변환할 경우toLowerCase() - 문자를 대문자 문자로 변환
char t = Character.toUpperCase(c1);
소문자로 변환할 경우toLowerCase() - 향상된 for문으로 문자열의 각 문자 순회
for(char x : str.toCharArray()) - 문자가 소문자인지 확인
Character.isLowerCase(x) - 주요 아스키 코드
- A: 65
- Z: 90
- a: 97
- z: 122
- 0: 48
- 9: 57
- Integer 타입의 가장 작은 값
int m = Integer.MIN_VALUE;
Integer 타입의 가장 큰 값은Integer.MAX_VALUE - 문자열에서 문자의 위치 반환
pos = str.indexOf(' '))
💡 문자가 문자열에 존재하지 않을 경우 -1을 반환 - 문자열 뒤집기
String tmp = new StringBuilder(x).reverse().toString() - 문자가 알파벳인지 확인
Character.isAlphabetic(c) - 문자열에서 중복되는 문자 제거
- indexOf()를 활용한다.

- indexOf()를 활용한다.
- 대소문자 무시하고 문자열 비교
str.equalsIgnoreCase(tmp) - 문자열에서 영어가 아닌 문자 제거
String str = s.toUpperCase().replaceAll("[^A-Z]", ""); - 문자가 숫자인지 확인
`Charater.isDigit(x) - 두 수 중 최소값 구하기
Math.min(a,b) - 문자열의 문자 변환
- replace(a, b)를 활용한다.
- 바꾸고 싶은 문자가 여러 개일 경우, replace()를 여러번 사용 가능
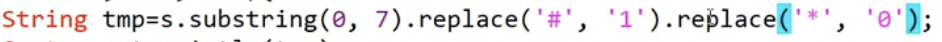
섹션2. Array
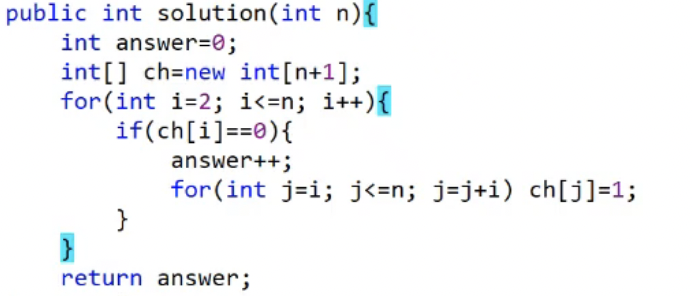
- 배열을 사용해서 소수 구하기
- 주어진 숫자 n 이하의 소수의 개수 m을 구하시오.
- 소수일 경우, i의 모든 배수에 소수가 아니라는 표시를 한다.
- 1은 소수가 아니다.
- 숫자 tmp를 뒤집기
- 숫자 tmp를 뒤집어서 res에 저장

- 숫자 tmp를 뒤집어서 res에 저장
- 상하좌우
- 이중 배열에서 상하좌우 요소 구하기
int[] dx = {-1, 0, 1, 0}; int[] dy = {0, 1, 0, -1}; for(int k=0; k<4; k++){ arr[i+dx[k]][j+dy[k]] // 현재 요소arr[i][j]의 상하좌우 요소를 가리키게 된다. }
- 이중 배열에서 상하좌우 요소 구하기
섹션3. Two Pointers, Sliding Window(효율성: O(n^2) --> O(n))
-
윈도우 사이즈가 k인 슬라이딩 윈도우를 이용해서 최대 sum을 구하기

-
2개 이상의 연속된 자연수의 합으로 정수 N을 표현하는 경우,
N/2+1까지만 고려하면 된다. ex) 15의 경우, 가장 큰 연속된 자연수의 합은 7+8이다.N/2+1보다 큰 연속된 자연수의 합으로 N을 표현할 수 없다. -
2개 이상의 연속된 자연수의 합으로 정수 N을 표현하는 경우, 투 포인터 말고도 '몫과 나머지'를 이용해서 답을 구할 수 있다.
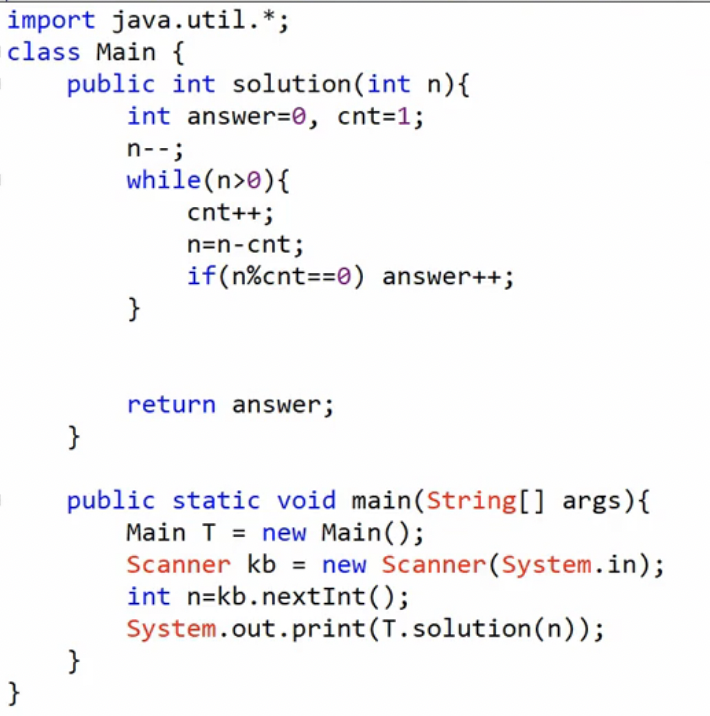
- cnt는 연속된 자연수의 개수이다.
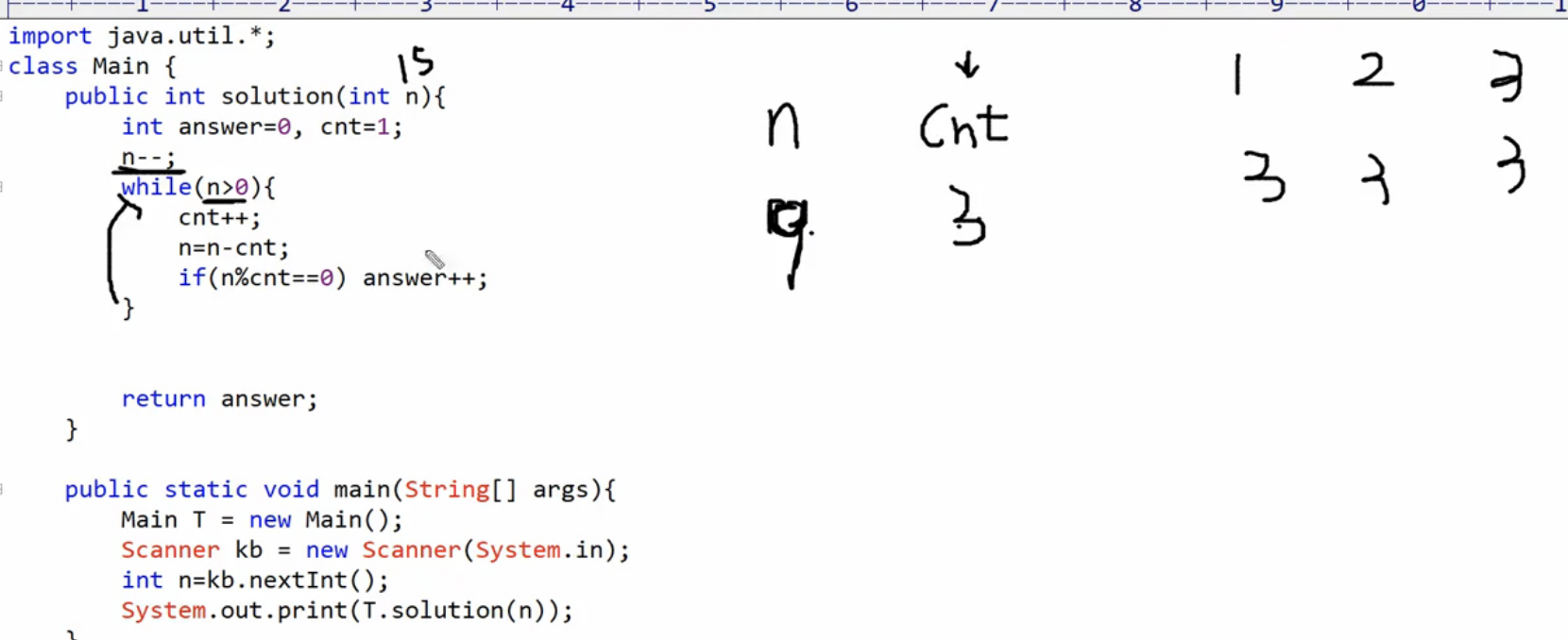
- cnt는 연속된 자연수의 개수이다.
섹션3. HashMap, TreeSet(해쉬, 정렬지원 Set)
-
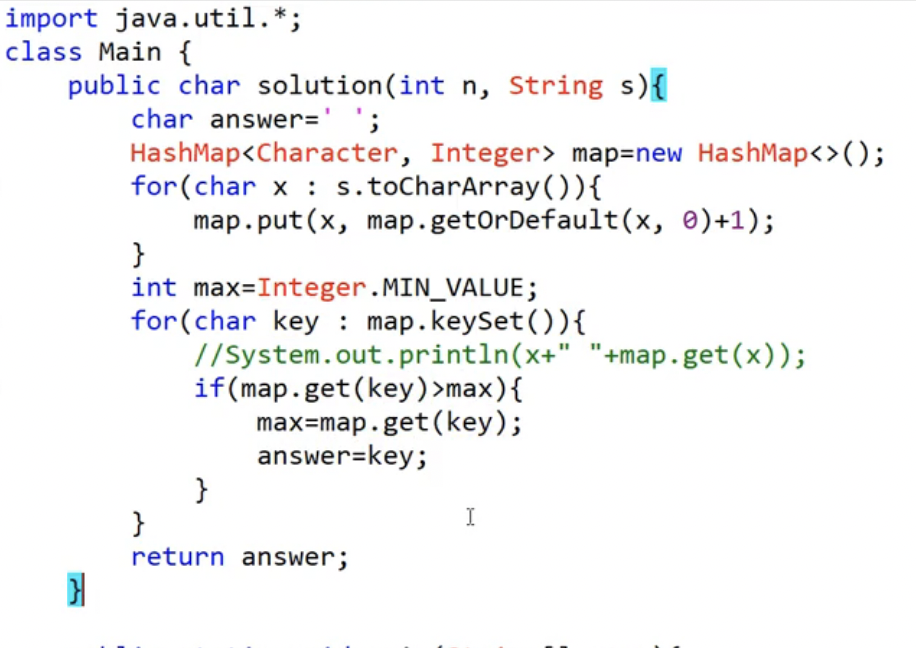
반장투표 문제
- String s가 주어졌을 때 각 문자 별로 투표된 횟수를 구해서 최대 투표수를 받은 문자를 구해야 한다.
- HashMap을 통해 다음과 같이 해를 구할 수 있다.
- HashMap의 주요 메서드
- map.getOrDefault(key, defaultValue): key에 해당하는 value 값을 반환. 만약 key가 존재하지 않다면 defaultValue를 반환
- map.keySet()
- map.get(key): key에 해당하는 value 값을 반환
- map.containsKey(key): 존재여부를 boolean 값으로 반환
- map.size(): key의 개수를 반환
- map.remove(key): 특정 key를 삭제한다.
-
아나그램(어느 한 단어를 재배열하면 상대쳔 단어가 될 수 있는지) 문제를 HashMap을 통해 해결할 수 있다.
- 코드 예시

- 코드 예시
-
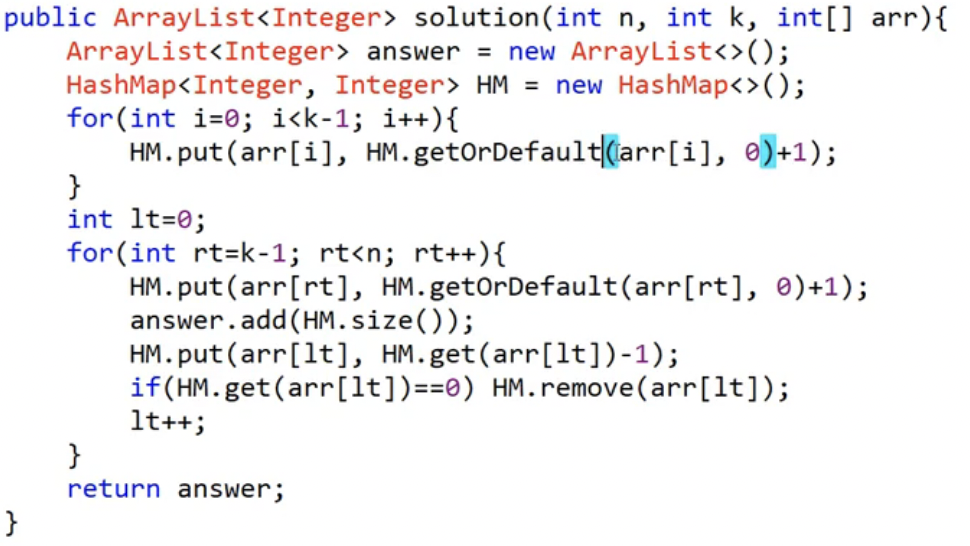
슬라이딩 윈도우로 매출의 종류를 구하는 문제. HashMap을 이용해서 특정 매출에 해당하는 개수를 계산한다. 이때 포인트는 value가 0이면 remove 메서드를 사용해서 키 값을 삭제해준다.
-
TreeSet은 중복 제거 + 정렬을 지원한다. TressSet은 레드-블랙 트리로 구현되어 있다.
- 내림차순으로 자동 정렬하는 TreeSet

- 내림차순으로 자동 정렬하는 TreeSet
-
Q. 3중 for문에서 각 for문의 조건을 i < n-2, j < n-1, l < n 이렇게 설정하지 않아도 된다. i < n, j < n, l < n으로 설정하면 된다.
- 왜? i가 n-2일때 j는 i+1이므로 n-1이되고 l은 j+1이므로 n이되기 때문에 세 번째 for문의 조건에서 걸리게 된다.

- 왜? i가 n-2일때 j는 i+1이므로 n-1이되고 l은 j+1이므로 n이되기 때문에 세 번째 for문의 조건에서 걸리게 된다.
-
TreeSet의 주요 메서드
- Tset.add(value)
- Tset.remove(value)
- Tset.size(): 원소의 개수를 반환
- Tset.first(): 오름차순에서는 최소값 반환. 내림차순에서는 최대값 반환.
- Tset.last(): 오름차순에서는 최대값 반환. 내림차순에서는 최소값 반환.
섹션4. Stack, Queue
-
stack도 배열처럼 i번째 원소를 꺼낼 수 있다. stack.get(i)를 사용하면 된다.
-
후위 연산자 문제
- 숫자를 만나면 push, 연산자를 만나면 2개를 pop해와서 연산 후 push 해주면 된다.
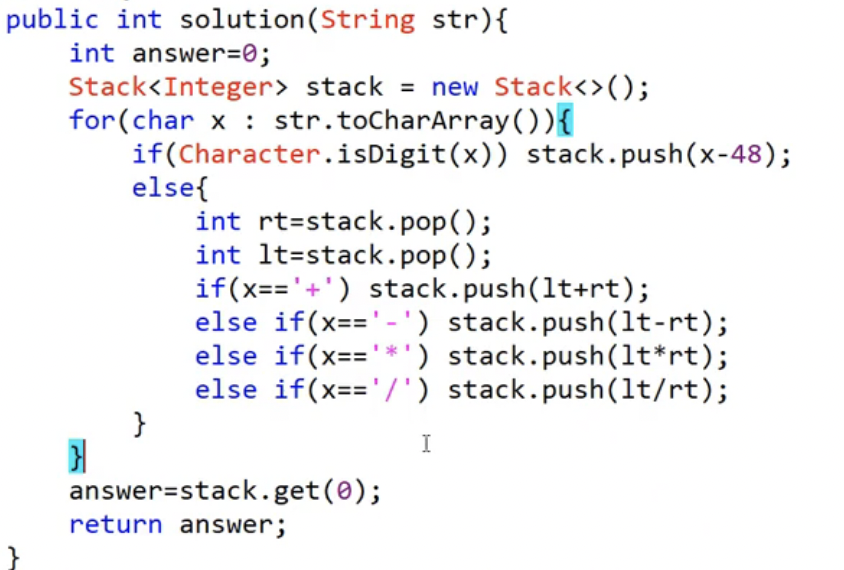
- 숫자를 만나면 push, 연산자를 만나면 2개를 pop해와서 연산 후 push 해주면 된다.
-
Queue의 주요 메서드
- null 반환
- 삽입: offer
- 삭제: poll
- 조회: peek
- 에러 발생
- 삽입: add
- 삭제: remove
- 조회: element
- null 반환
-
우선순위큐 -> PriorityQueue
섹션5. Sorting and Searching(정렬, 이분검색과 결정 알고리즘)
-
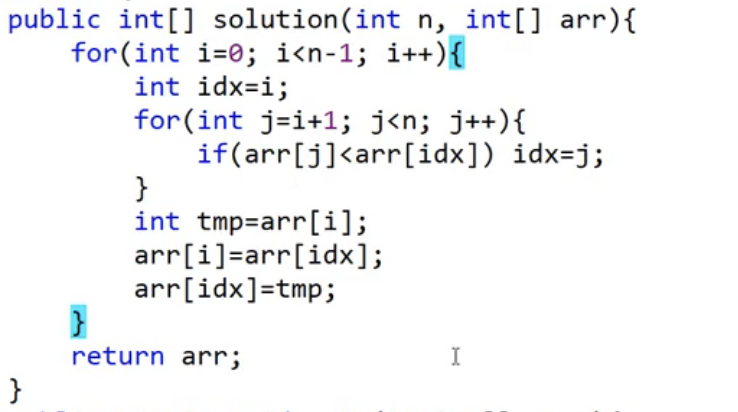
선택 정렬 코드
-
버블 정렬 코드

-
삽입 정렬 코드 -> 어렵다....😢

-
LRU(캐시 히트, 캐시 미스) 문제
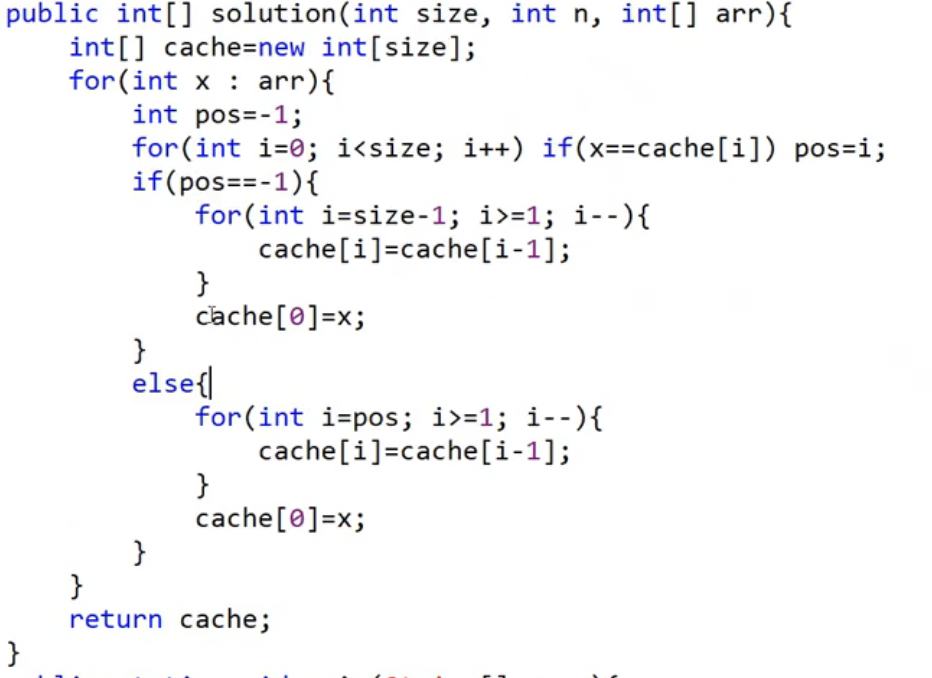
-
array 깊은 복사하는 법 : arr.clone()
- 깊은 복사를 해야지 원본 값에 영향을 주지 않는다.
-
클래스의 정렬 기준 만들기
- Comparable을 implements하는 클래스를 만든다.
- int compareTo(Object o) 메서드를 오버라이드해라! 'this.x - o.x'이면 오름차순! 그 반대이면 내림차순!
- 예시

-
이분검색
- 중간 지점 mid = (lt + rt)/2를 구해서 값의 위치를 찾는다.
- 이분검색의 시간복잡도는 O(logN)이다.
- 예시
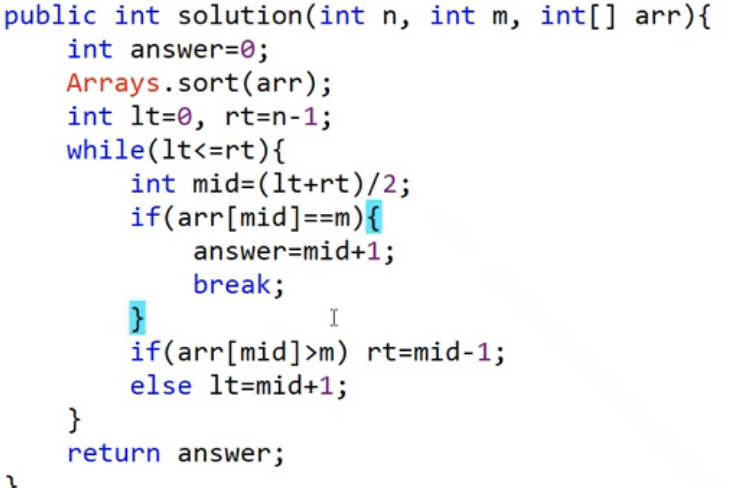
- 결정 알고리즘
- 범위(lt와 rt 사이)에 답이 존재할 때에만 사용 가능
- 예시
섹션7. DFS, BFS 활용
- DFS로 조합 구하기
- 코드
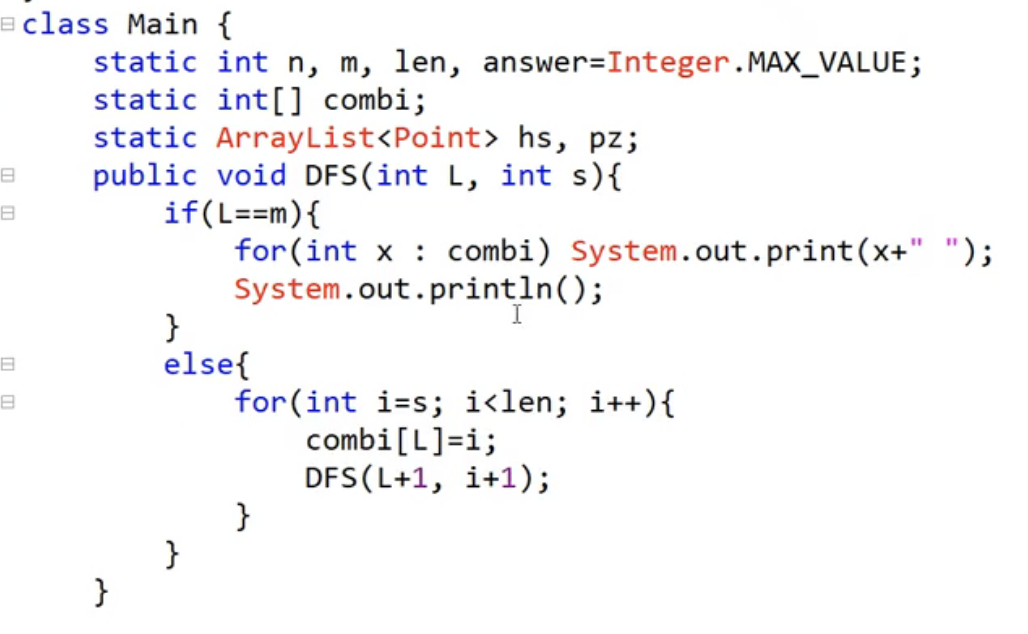
- 결과

- 코드
섹션8. Greedy Algorithm
-
UNION(합집합) 문제 푸는 아이디어
- 자기 인덱스 번호를 값으로 갖는 배열을 만든 다음, 만약 다른 인덱스를 참조한다면(다른 인덱스와 연결되어 있다면) 참조하는 인덱스의 값으로 바꾼다.
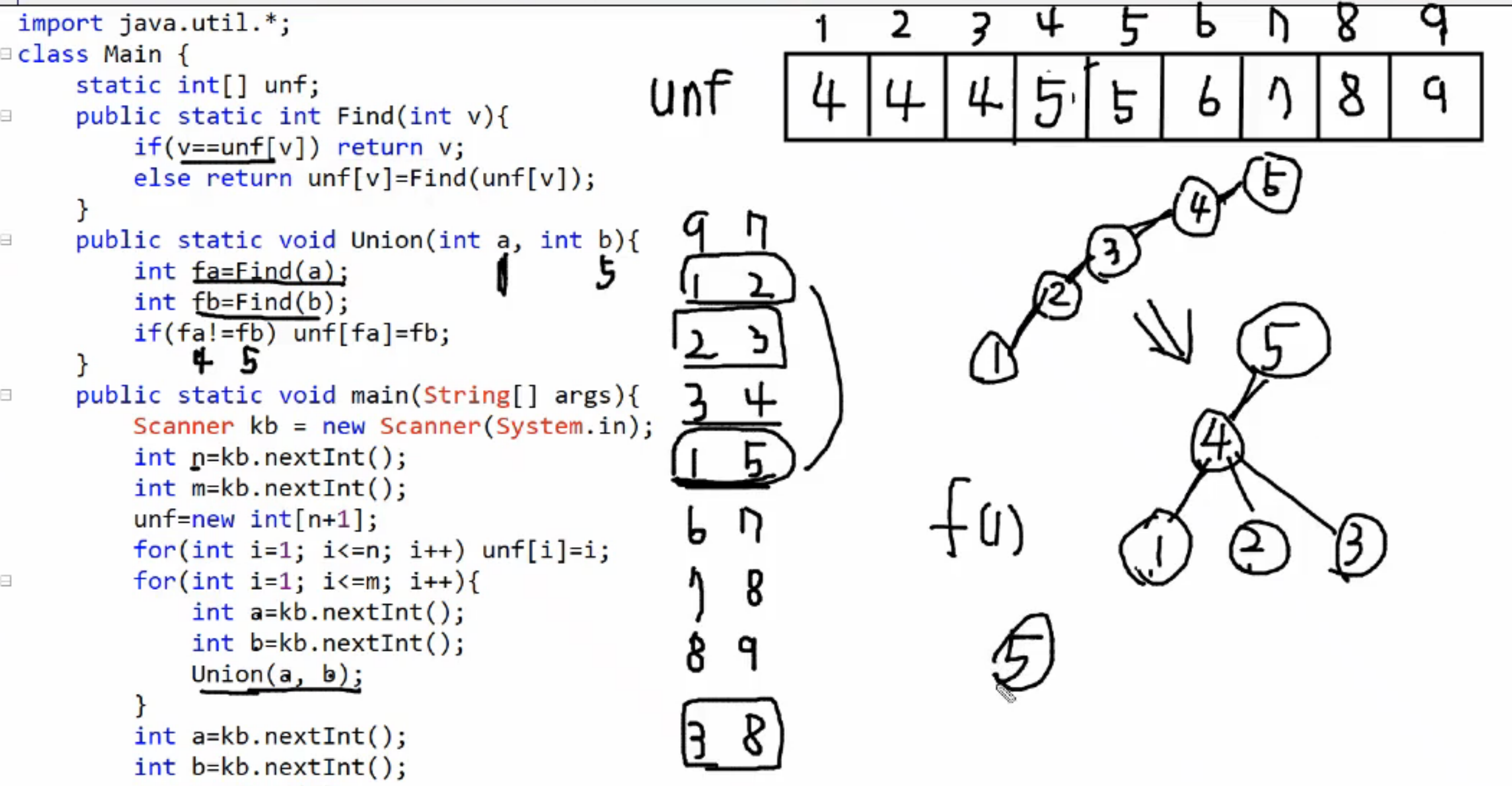
- 자기 인덱스 번호를 값으로 갖는 배열을 만든 다음, 만약 다른 인덱스를 참조한다면(다른 인덱스와 연결되어 있다면) 참조하는 인덱스의 값으로 바꾼다.
-
최소 신장 트리를 찾는 그래프 문제의 경우,크루스칼 알고리즘또는프림 알고리즘을 활용 가능하다.- 크루스칼 알고리즘: UNION & FIND를 활용한다. 문제 예시
- FIND를 통해 같은 뿌리를 가진 그래프인지 확인
- 먼저 FIND로 같은 뿌리인지 확인 후 뿌리가 다르다면 UNION을 통해 뿌리가 같은 그래프로 결합
- 프림 알고리즘: Priority Queue를 활용한다. 문제 예시
- 하나의 노드에 연결되어있는 모든 엣지를 PriorityQueue에 넣는다. PriorityQueue는 엣지의 비용이 작은 순서대로 정렬되어 있다.
여기서 주의할 점은 양방향으로 저장해줘야 한다!!! (s,e), (e,s) 둘 다 저장해줘야 한다. - PriorityQueue에서 하나를 poll()한 다음 checked 배열을 통해 연결된 노드가 이미 지나간 노드인지 확인한다. 지나간 노드가 아니라면 해당 노드를 checked 배열에 true로 변경해주고 cost 비용을 더한다.
- 하나의 노드에 연결되어있는 모든 엣지를 PriorityQueue에 넣는다. PriorityQueue는 엣지의 비용이 작은 순서대로 정렬되어 있다.
- 크루스칼 알고리즘: UNION & FIND를 활용한다. 문제 예시
-
그래프 문제의 경우, 엣지의 개수를 예측할 수 없다. 또한 하나의 노드에서 파생되는 엣지의 개수도 예측할 수 없다.
따라서 엣지의 개수를ArrayList<ArrayList<Edgs>> graph = new ArrayList<ArrayList<Edge>>()자료형에 담는 것이 좋다.graph.get(n번째 노드 번호).get(해당 노드에서 연결되는 m번째 에지)와 같이 노드에서 파생되는 엣지를 찾을 수 있다.
섹션9. dynamic programming(동적계획법)
- 동전 교환 문제(냅색 알고리즘)
- 최소 동전의 수를 저장하는 dy 배열에 최대 동전의 수를 저장한다.
j번째 값에서 coin만큼의 값을 빼고 +1한 값(coin을 사용한 경우)과 이전의 값을 비교한다.

