📍 10분 테코톡 - [DB] 파티셔닝? 샤딩? 레플리케이션? (partitioning? sharding? replication?)를 보고 정리한 내용이다.
파티셔닝
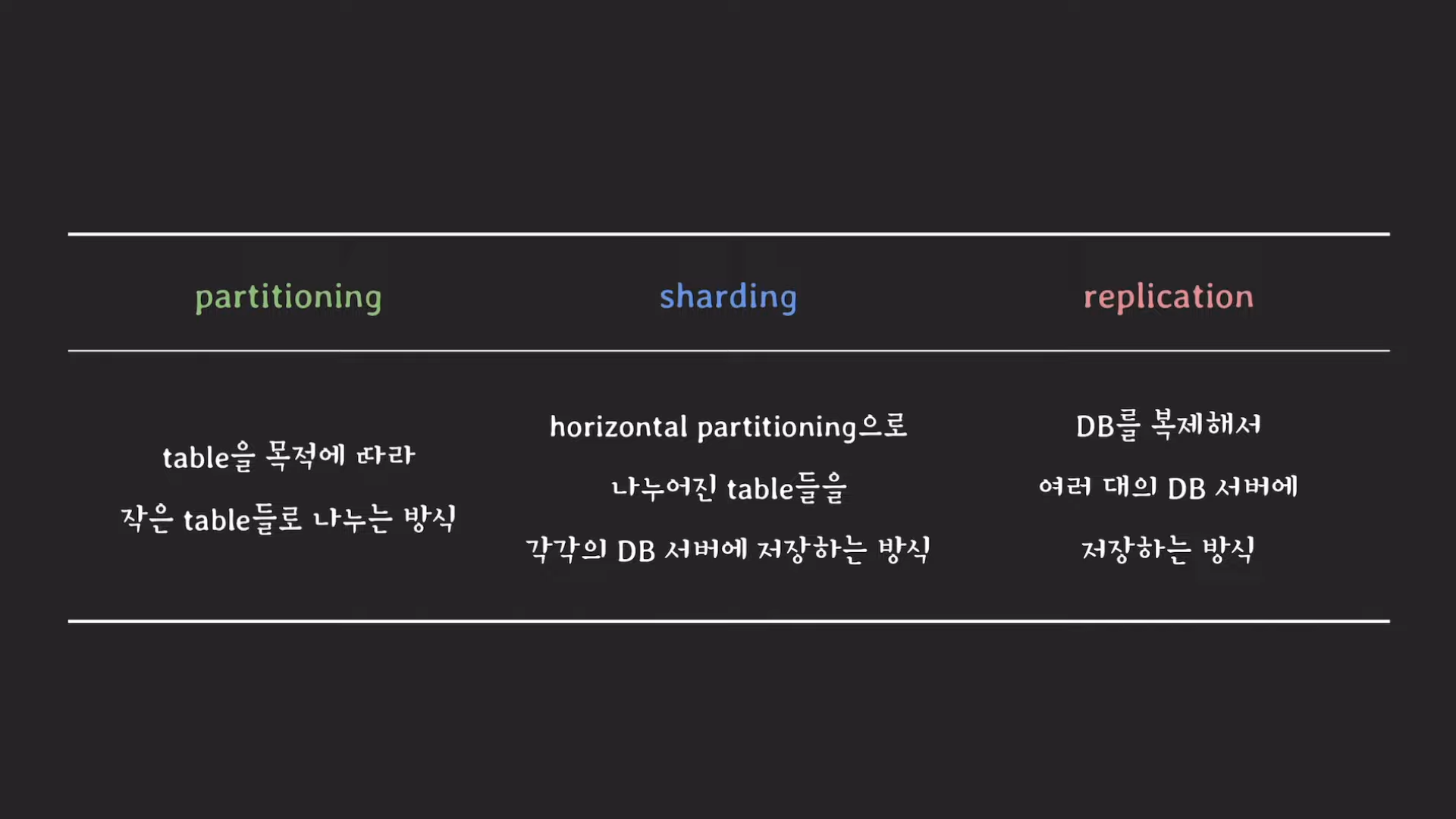
파티셔닝 = 데이터베이스 테이블을 더 작은 테이블들로 나누는 것
-
파티셔닝 종류
-
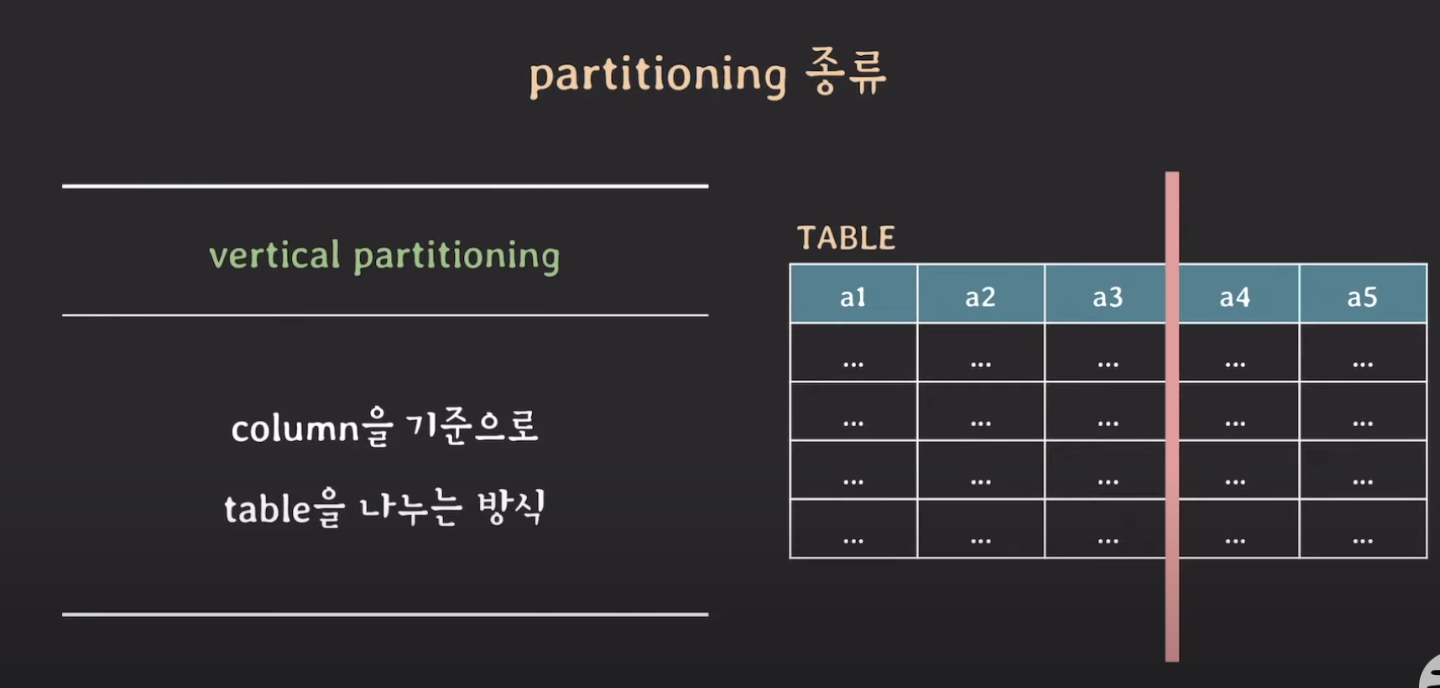
vertical partitioning
- column을 기준으로 테이블을 나누는 방식
- 이미 정규화가 되어있는 테이블이더라도 퍼포먼스를 위해서 vertical partitioning을 수행할 수 있다.
- 민감한 정보에는 함부로 접근하지 못하도록 일부로 vertical partitioning을 수행할 수도 있다.
-
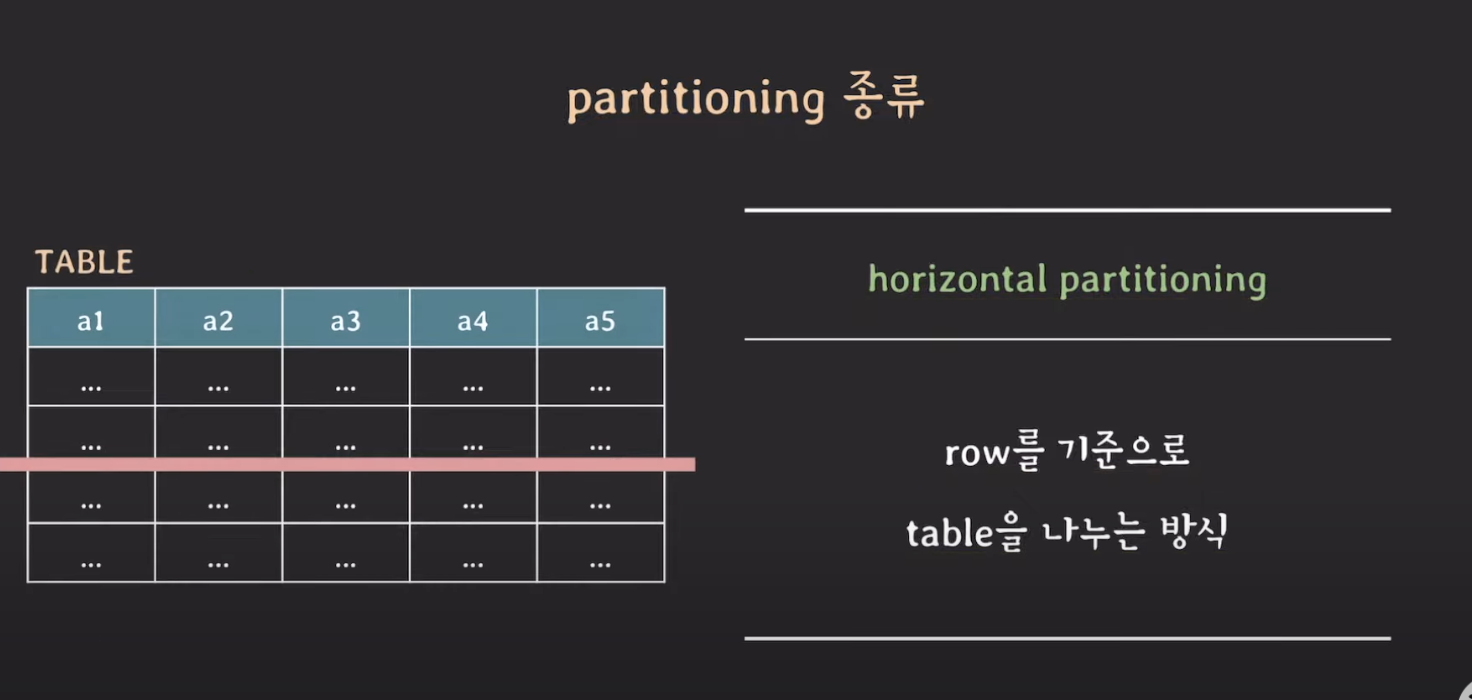
horizontal partitioning
- row를 기준으로 테이블을 나누는 방식
- 테이블의 스키마는 변화없이 유지된다.
- 테이블의 크기가 커질수록 인덱스의 크기도 커진다. 즉, 테이블에 읽기 쓰기가 있을 때마다 인덱스에서 처리되는 시간도 조금씩 늘어난다. 이때 horizontal partitioning을 사용해서 문제점을 해결할 수 있다.
- 가장 많이 사용될 패턴에 따라 partition key를 정하는 것이 중요하다.
- 또한 데이터가 균등하게 분배될 수 있도록 hash function을 잘 정의하는 것도 중요하다.
- hash-based horizontal partitioning은 한번 partition이 나눠져서 사용되면 이후에 partition을 추가하기 까다롭다. 따라서, 처음 partitioning을 설계할 때 잘 기획해야 한다.
-
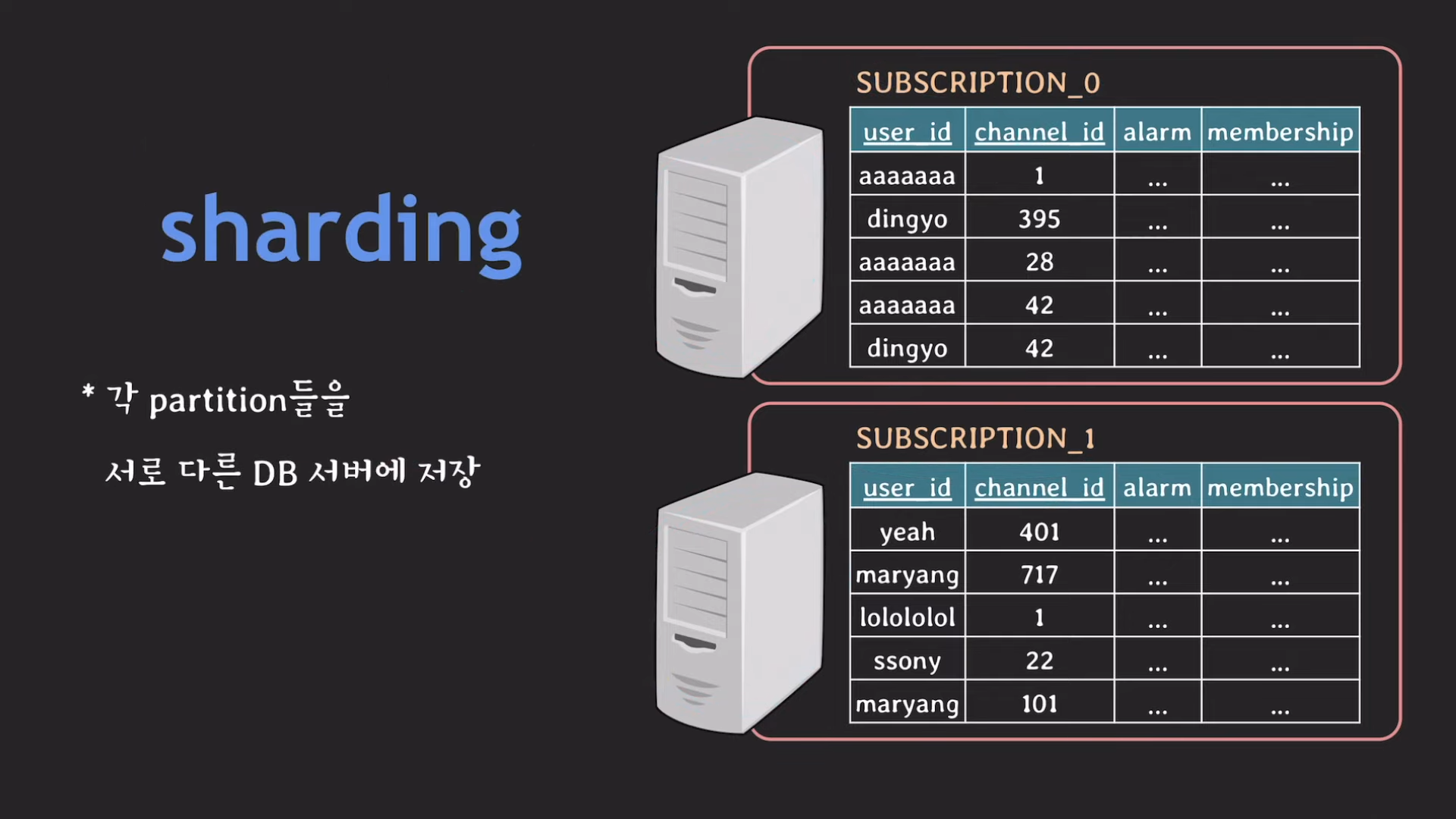
샤딩
샤딩 = horizontal partitioning처럼 동작! 단, 각 partition이 독립된 DB 서버에 저장된다.(차이점)
- 샤딩
- 샤딩은 DB 서버로 오는 부하를 분산시키는 효과를 갖는다.
- paritition key를 shard key라고 부름
- 각 partition을 shard라고 부름
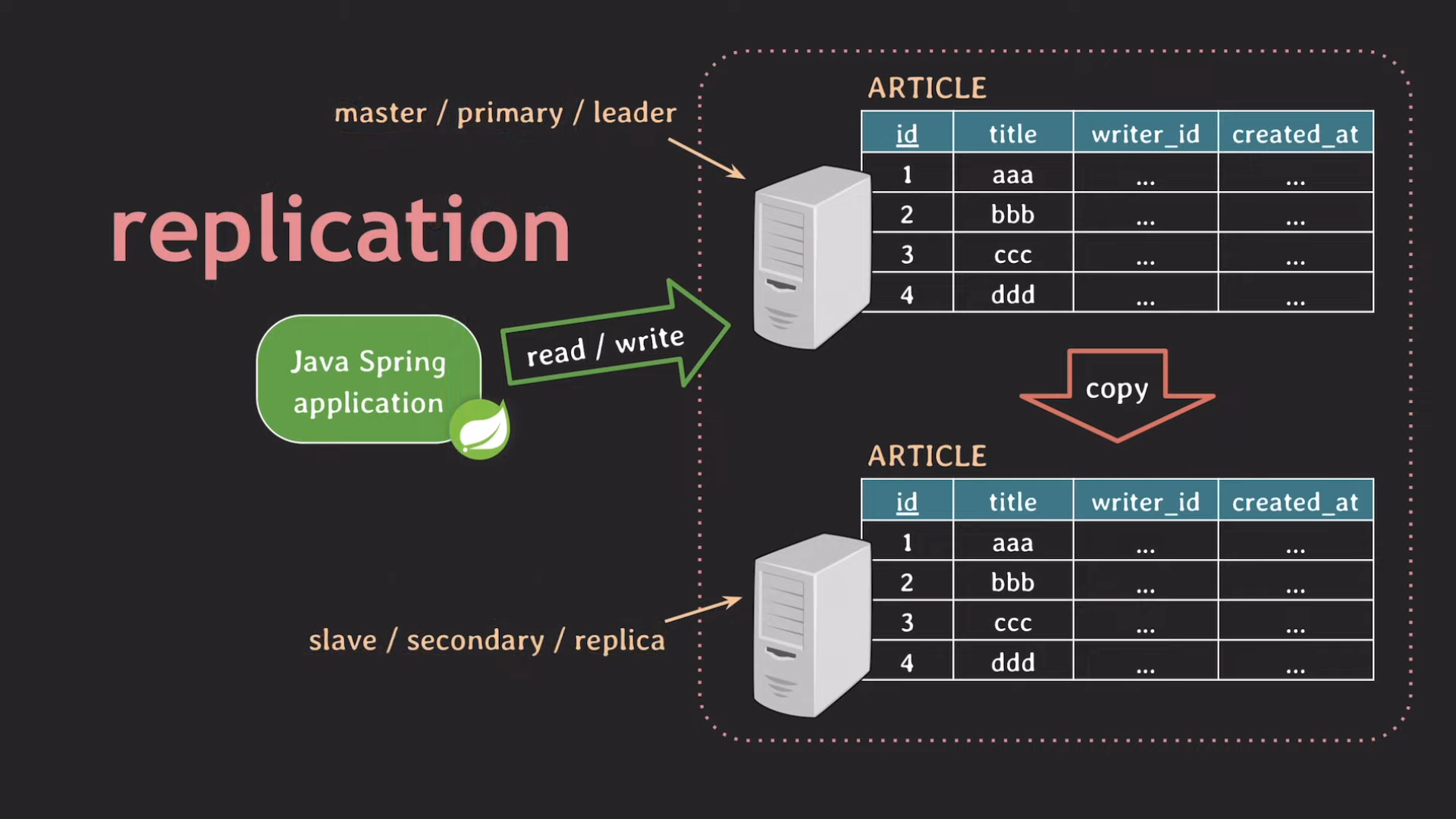
레플리케이션
레플리케이션 = DB를 복재해서 여러 대의 DB 서버를 저장하는 방식
- 레플리케이션
- fail over를 통해 서비스에 최대한 영향이 가지 않도록 한다.(High Availability 보장)
- read 부하를 분산시킬 수 있다.
Q. MySQL8.0의 구체적인 복제 원리 알아보기 👩🏫
기본적으로 복제는 비동기 방식이다. 설정에 따라 전체가 아닌 부분 데이터(일부 데이터베이스, 일부 테이블)를 복제할 수 있다.
MySQL8.0은 다양한 복제 방법을 지원한다.
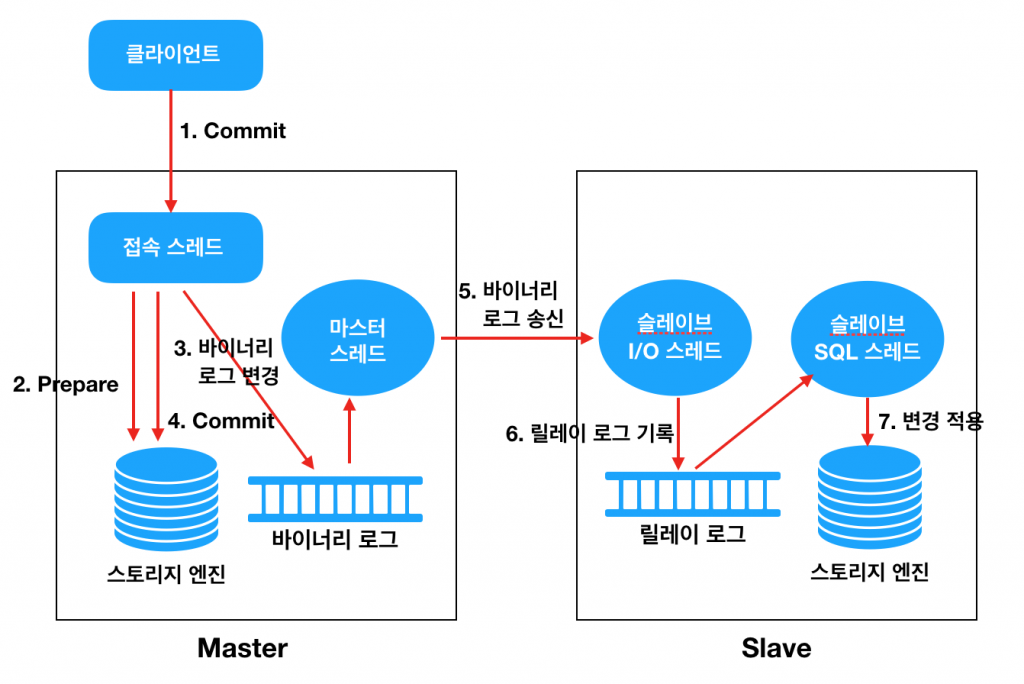
MySQL의 전통적인 복제 방법은 다음과 같다.
Master 데이터에 대한 모든 변경사항을 로그 파일에 기록한다.(일반적으로 SELECT 명령문은 데이터베이스 구조나 내용을 수정하지 않기 때문에 기록되지 않는다.)
Master에 연결하는 각 복제본(Slave)은 바이너리 로그의 복사본을 요청한다. Slave는 수신한 바이너리 로그에서 이벤트를 실행한다. 이렇게 하면 Master에서 변경된 원래 변경 사항을 반복하는 효과가 있다. Master에서 원래 변경된 내용에 따라 데이터가 삽입, 삭제 및 업데이트된다.
각 Slave는 독립적이기 때문에 Master의 바이너리 로그에서 변경 사항을 재생하는 것은 각 Slave에서 독립적으로 발생한다.
Q. replication과 clustering의 차이는? 👩🏫
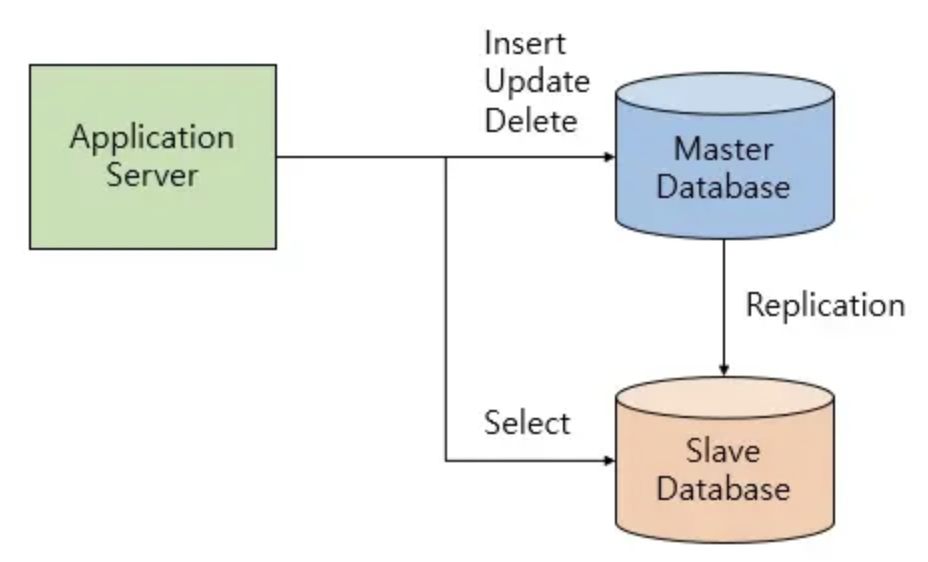
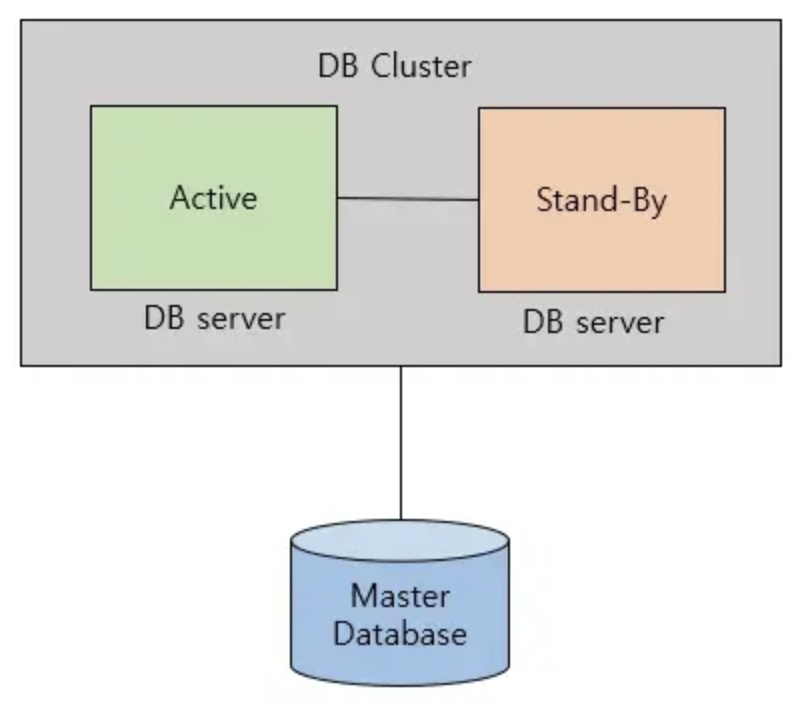
replication은 여러 개의 DB를 권한에 따라 수직적인 구조(Master-Slave)로 구축하는 방식이다. replication에서 Master는 쓰기 작업만을 처리하며 Slave는 읽기 작업만을 처리한다. replication은 비동기 방식으로 노드들 간의 데이터를 동기화한다. 비동기 방식으로 운영되는 덕분에 지연 시간이 거의 없다. 반면에, 노드들 간의 동기화가 보장되지 않아 일관성있는 데이터를 얻지 못할 수 있다.
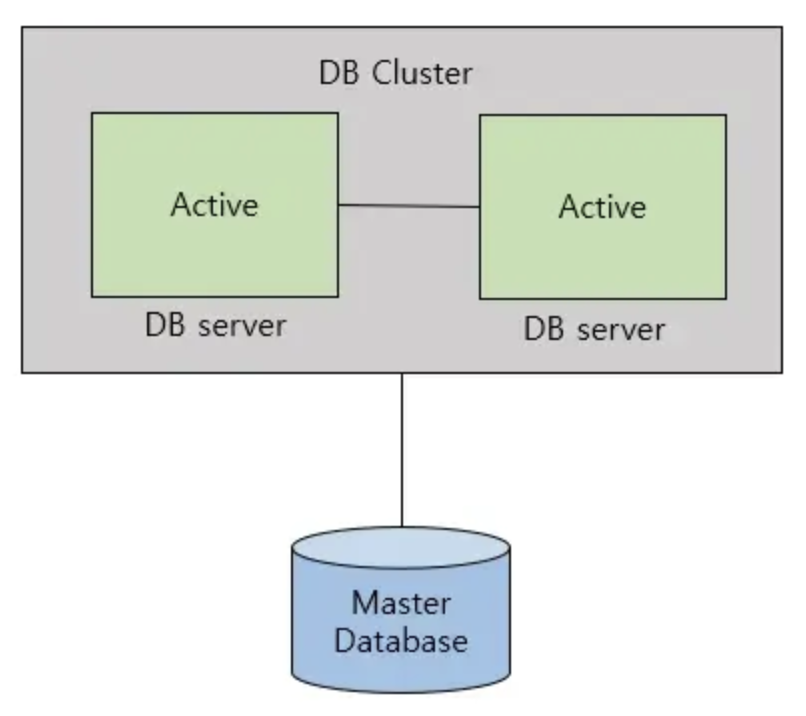
clustering은 여러 개의 DB를 수평적인 구조로 구축하는 방식이다. clustering은 분산 환경을 구성하여 single point of failure와 같은 문제를 해결할 수 있는 fail over 시스템을 구축하기 위해 사용된다. clustering은 동기 방식으로 노드들 간의 데이터를 동기화한다. 따라서, 노드들 간의 데이터를 동기화하여 항상 일관성있는 데이터를 얻을 수 있다. 하지만 여러 노드들 간의 데이터를 동기화하는 시간이 필요하므로 replication에 비해 쓰기 성능이 떨어진다.
정리
[참고자료]
https://www.youtube.com/watch?v=P7LqaEO-nGU&ab_channel=%EC%89%AC%EC%9A%B4%EC%BD%94%EB%93%9C
https://dev.mysql.com/doc/refman/8.0/en/replication-implementation.html
http://cloudrain21.com/mysql-replication
https://mangkyu.tistory.com/97
https://code-lab1.tistory.com/205

여러 곳에서 클러스터링이라는 단어가 나와서 궁금했었는데 덕분에 잘 알고 갑니다.