특징
A.P.I.E
- Abstraction(추상화)
현실의 객체를 추상화해서 클래스 구성
- Polymorphism(다형성)
하나의 객체를 여러가지 타입(형)으로 참조
- Inheritance(상속)
부모 클래스이 자산을 물려받아 자식을 정의함으로 코드의 재사용이 가능
- Encapsulation(데이터 은닉과 보호)
데이터를 외부에 직접 노출시키지 않고 메서드를 이용해 보호
객체
- 주제가 아닌 것, 주체가 활용하는 것
- (사물 / 개념 / 논리)
객체 지향 프로그래밍
- 주변의 많은 것을 객체화해서 프로그래밍 하는 것
- 블록 형태의 모듈화된 프로그래밍
장점
- 신뢰성 높은 프로그래밍 가능
- 추가 / 수정 / 삭제 용이
- 재 사용성이 높다
붕어빵 틀 => Type 규정
붕어빵 => 객체
추상화와 구체화
추상화
다음과 같이 클래스를 만들고 테스트 코드를 만든다.
Person.java
public class Person {
String name;
int age;
boolean isHungry;
public void eat() {
isHungry = false;
}
public void work() {
isHungry = true;
}
}PersonTest.java
public class PersonTest {
public static void main(String[] args) {
Person p1 = new Person();
p1.age = "홍길동";
p1.isHungry = true;
System.out.println(p1.name+" : "+ p1.isHungry);
p1.eat();
System.out.println(p1.name+" : "+ p1.isHungry);
Person p2 = new Person();
p2.name = "임꺽정";
System.out.println(p2.name + " : " + p2.isHungry);
}
}이 코드내의 멤버변수 / 멤버메서드 / 구체화를 구분하면 다음과 같다.
- 멤버변수
String name;
int age;- 멤버메서드
void eat();
void work();- 구체화
Person p = new person;
p.name = "철수";
p.age = 20;
p.work();JVM의 메모리 구조
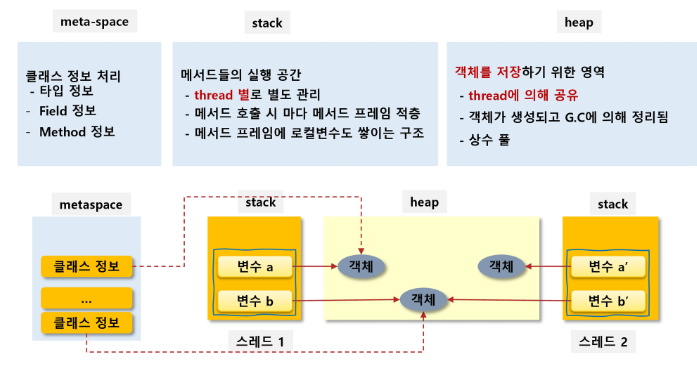
a, b와 같은 변수는 힙 영역의 객체를 참조한다.
다른 스레드의 스택에서도 힙을 공유하므로 같은 주소를 참조할 수 있다.
메모리 공간
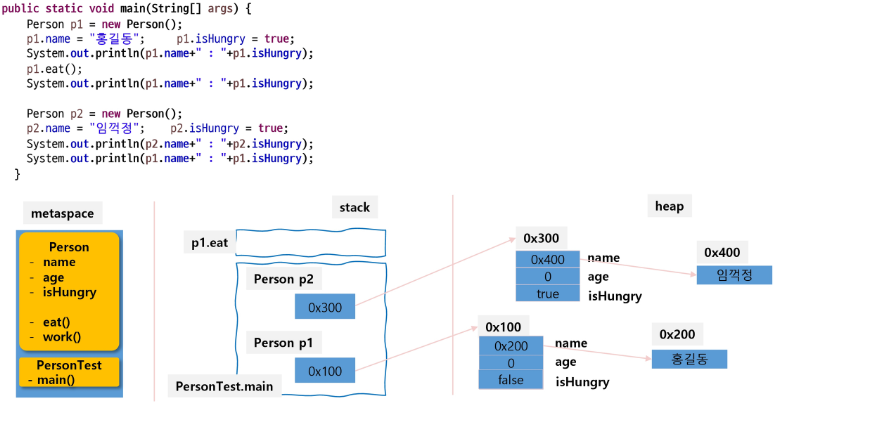
Person형의 p1을 선언하면 metaspace에 클래스를 참조하여 heap에 객체가 생성되고 stack영역에 해당 주소를 참조하는 값이 저장된다.
멤버 변수
객체는 멤버변수인 name, age, isHungry가 있고, 각각의 타입의 기본형으로 초기화 되어있다. name은 String형으로 참조형 타입이므로 주소값이 저장되어 있는데 해당 주소로 가면 p1의 name을 확인할 수 있다.
멤버 메서드
클래스의 멤버메서드의 경우 호출되는 경우 stack에 생성되고 종료되면 stack에서 사라진다.
변수의 종류
타입에 따른 분류
인스턴스 변수의 특징
- 클래스 {} 영역안에 선언
public class Person{
static String scientificName = "Homo Sapiens"
String name;
}- 변수의 생성
- 객체가 만들어질 때 heap에 객체 별로 생성
- 변수의 초기화
- 타입 별로 default 초기화
- 사용하기 전 명시적 초기화 필요
- 변수에의 접근
- 객체 생성 후 (메모리에 올린 후) 객체 이름(소속)으로 접근
외부에서는 접근이 불가하므로 소속 불필요- 내부에서는 이름에 바로 접근
- 객체를 생성하고 객체 이름으로 접근도 가능하다 static에 부합한 표현은 아님
Person p = new Person();
p.scientifiName = "객체를 통한 변경"
Person.scientifiName = "클래스를 통한 변경"- 소멸 시점
- Garbage Collector에 의해 객체가 없어질 때(프로그래머가 명시적으로 소명시킬 수 없음)
- 선언된 영역인 { } 을 벗어날 때
Variable arguments
메서드 선언 시 동일 타입의 인자가 몇개 들어올 지 예상할 수 없을 경우 (또는 가변적)
- 배열 타입을 선언할 수 있으나 메서드 호출 전 배열을 생성, 초기화 해야 하는 번거로움
...을 이용해 파라미터를 선언하면 호출 시 넘겨준 값의 개수에 따라 자동으로 배열 생성 및 초기화
예시)
public PrintStream printf(String format Object ... args){
return format(format, args);
}
public void addAll(int... params){
int sum = 0;
for(int i: params){
sum += i;
}
System.out.println(sum);
}기본형 변수와 참조형 변수
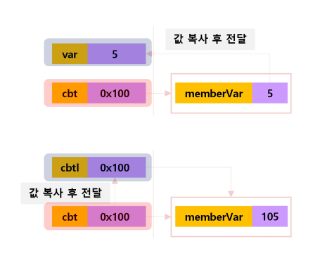
- 메서드 호출 시 파라미터로 입력된
값을 복사해서 전달 - Java는
call by value
public class CallByTest {
int memberVar = 10;
static void change1(int var) {
var += 10;
System.out.printf("change1 : %d%n", var);
}
static void change2(CallByTest cbtl) {
cbtl.memberVar += 100;
System.out.printf("change2 : %d%n", cbtl.memberVar);
}
public static void main(String[] args) {
CallByTest cbt = new CallByTest();
cbt.memberVar = 5;
System.out.printf("change1 호출 전 memberVar: %d%n", cbt.memberVar);
change1(cbt.memberVar); //값 전달 15출력
System.out.printf("change1 호출 후 memberVar: %d%n", cbt.memberVar); // 값 복사 후 전달 => 원본은 그대로 5
change2(cbt); //주소값 전달 => memberVar값 그 자체가 증가 105출력
System.out.printf("change2 호출 후 memberVar: %d%n", cbt.memberVar); //105 출력
}
}위 코드 동작시 메모리 변화는 다음과 같다
메서드 오버로딩
-
동일한 기능을 수행하는 메서드의 추가 작성
-
일반적으로 메서드 이름은 기능별로 의미 있게 작성
-
동일한 기능을 여러 형태로 정의해야 한다면?
eat vs eatUsingChopSticks, eatUsingFork, eatUsingSpoon
입으로 이동하는 부분까지만 다르고 그 이후의 동작은 ?
ex)
System.out.println(1);
System.out.println('C');
System.out.println("Hi");장점
- 기억해야 할 매서드가 감소하고 중복 코드에 대한 효율적 관리 가능
메서드 오버로딩 방법
-
매서드 이름은 동일
-
파라미터의 개수 도는 순서, 타입이 달라야 할 것
-
파라미터가 같으면 중복 선언 오류
-
리턴 타입은 의미 없음
ex)
void walk(){
System.out.println("100cm 이동");
}
void walk(int distance){
System.out.println(distance + "cm 이동");
}
