
🔥 Consumer 빠르게 돌아보기
Kafka Broker는 크게 두 가지의 개념이 존재합니다. 바로 Producer, Consumer입니다. Producer의 경우 생산자의 개념으로 보시면 되고, Consumer의 경우 소비자라고 생각하시면 편합니다.
Consumer는 Kafka Broker에 존재하는 Topic을 구독하여 데이터를 가져오는데요, 이번 포스트에서는 Consumer에 대해서 실습을 해보도록 하겠습니다.
🔥 일단 빠르게 가장 간단한 Consumer를 만들어보도록 하겠습니다.
우선 기존의 프로젝트에서 module을 하나 추가하겠습니다. 이름은 chapter3-part4-consumer 모듈이고 해당 module의 build.gradle.kts는 아래와 같이 작성합니다! (이전 포스트의 build.gradle.kts와 구성이 같습니다.)
🔨 build.gradle.kts
plugins {
kotlin("jvm")
}
dependencies {
implementation(kotlin("stdlib-jdk8"))
implementation(kotlin("reflect"))
implementation("org.apache.kafka:kafka-clients:2.5.0")
implementation("org.slf4j:slf4j-simple:1.7.30")
}
tasks.register("prepareKotlinBuildScriptModel") {}그리고 SimpleConsumer를 작성하도록 하겠습니다.
🔨 SimpleConsumer.kt
class SimpleConsumer {
private val logger = LoggerFactory.getLogger(this::class.java)
private val TOPIC_NAME = "test"
private val BOOTSTRAP_SERVER = KafkaInfo.BOOTSTRAP_SERVER
// 컨슈머 그룹을 통해서 컨슈머의 목적을 구분할 수 있다.
private val GROUP_ID = "test-group"
fun testConsumer() {
val configs = Properties()
configs[ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG] = BOOTSTRAP_SERVER
configs[ConsumerConfig.GROUP_ID_CONFIG] = GROUP_ID
configs[ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java.name
configs[ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java.name
val consumer = KafkaConsumer<String, String>(configs)
// consumer에게 구독 처리를 하여서 consumer에 대해 토픽을 하나 할당한다
consumer.subscribe(listOf(TOPIC_NAME))
// 지속적인 데이터 처리를 위해서 무한 루프로 구현
while (true) {
val records = consumer.poll(Duration.ofSeconds(1))
records.forEach { record ->
logger.info("$record")
}
}
}
}Consumer의 경우 Consumer-group을 통해서 관리가 됩니다. 따라서 Consumer 구현에 있어서 consumer-group을 configs에 등록을 해줘야합니다.
그리고 아래의 코드를 보겠습니다.
consumer.subscribe(listOf(TOPIC_NAME))이 코드에서 Consumer는 TOPIC_NAME에 해당하는 test라는 토픽을 구독하게됩니다. 이를 subscribe라는 메소드를 통해서 구독을 시행하게 되는데요, 이러한 subscribe 메소드에는 다양한 파라미터가 들어갈 수 있습니다. 이는 나중에 다시 보도록 하겠습니다.
그리고 아래의 코드도 보겠습니다.
val records = consumer.poll(Duration.ofSeconds(1))consumer가 topic으로부터 데이터를 가져올 때 poll이라는 메소드를 사용해서 가져오는데, 이러한 poll 메소드의 반환형은 ConsumerRecord입니다.
그리고 파라미터로 Duration 타입의 인스턴스를 받는것을 확인할 수 있는데요, 이는 Consumer가 Kafka Broker로부터 데이터를 가져올 때 Consumer buffer에 데이터를 기다리기 위한 타임아웃 기간을 의미합니다.
이제 Consumer를 동작시킨 후에, kafka-console-producer를 이용해서 데이터가 잘 consume되는지 확인하도록 하겠습니다.
# test 토픽에 데이터를 넣어준다
$ bin/kafka-console-producer.sh --bootstrap-server [my-kafka]:9092 --topic test
> cheetah!위의 shell 명령어를 이용하면 topic에 cheetah! 라는 데이터가 들어가게되고 해당 데이터에 대해서 콘솔에 로그가 잘 찍힌다면 성공한 것입니다! 결과는 까먹고 캡쳐를 안해서...죄송합니다 ㅎㅅㅎ
다음 단락에서는 Consumer의 중요 개념을 알아보도록 하겠습니다.
🔥 Consumer group에 대해서 자세하게 알아보도록 하겠습니다.
아마 제가 카프카에 대해서 다루기 시작한 두번째 포스트부터 consumer group 이라는 단어를 사용했던 것으로 기억합니다. 이번 단락에서는 이전에 모호하게 설명하고 넘어갔던 Consumer group 이라는 단어에 대해서 깊게 알아보고 가고자합니다.
우선 Consumer group의 존재 의의부터 알아보도록 하겠습니다. Kafka Broker에서 컨슈머를 다루는 전략은 크게 두 가지로 나뉩니다.
- 1개 이상의 컨슈머로 구성된 Consumer group을 운영한다
- 특정 파티션을 구독하는 컨슈머를 사용한다
이 중에서 첫번째 방법, Consumer group 을 이용해서 consumer를 운영하는 방식의 의의는 다음과 같습니다.
👉 Consumer를 group 단위로 격리시켜서 Kafka Broker를 안전하고 효율적으로 관리하기 위함이다.
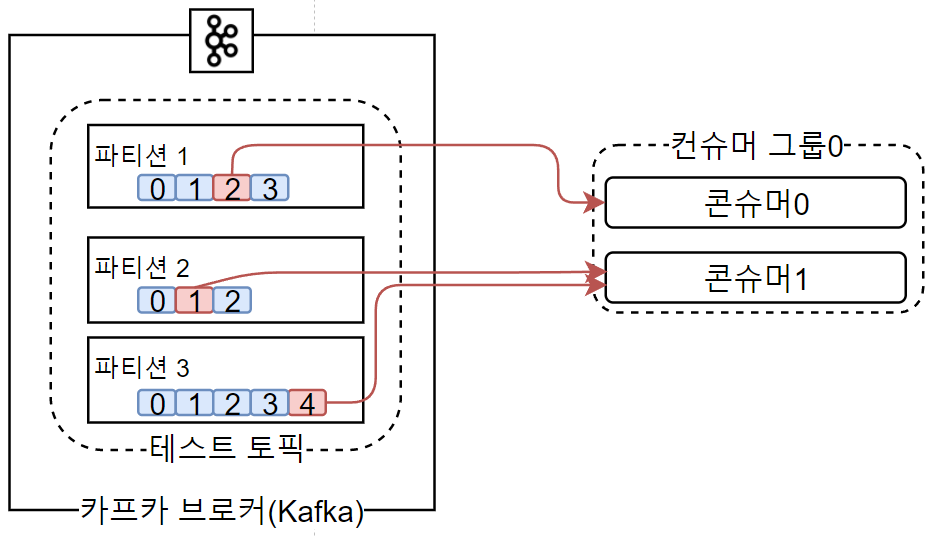
이 때 Consumer group으로 묶인 컨슈머들은 구독하고있는 토픽에서 1개 이상의 파티션을 할당받아 데이터를 가져올 수 있습니다.
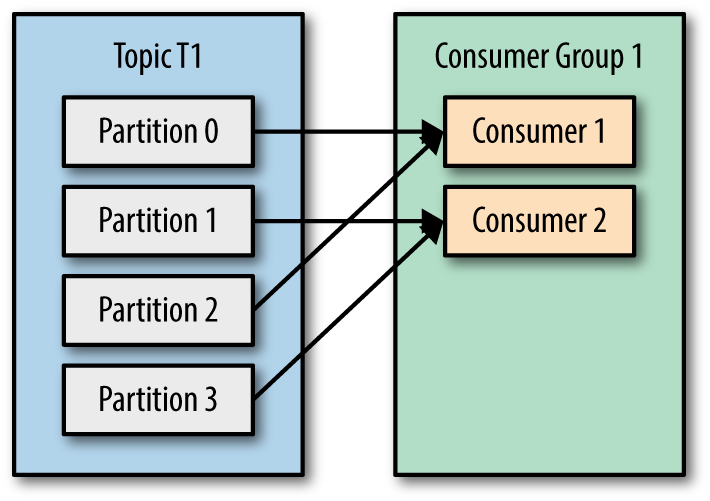
이 때 중요한 점은 Kafka의 Partition은 최대 1개의 컨슈머에 할당이 가능하다는 것입니다. 아마 이는 여러분들이 고등학교 때 배웠던 정의역의 개념에 대입해보면 이해가 쉬울겁니다.
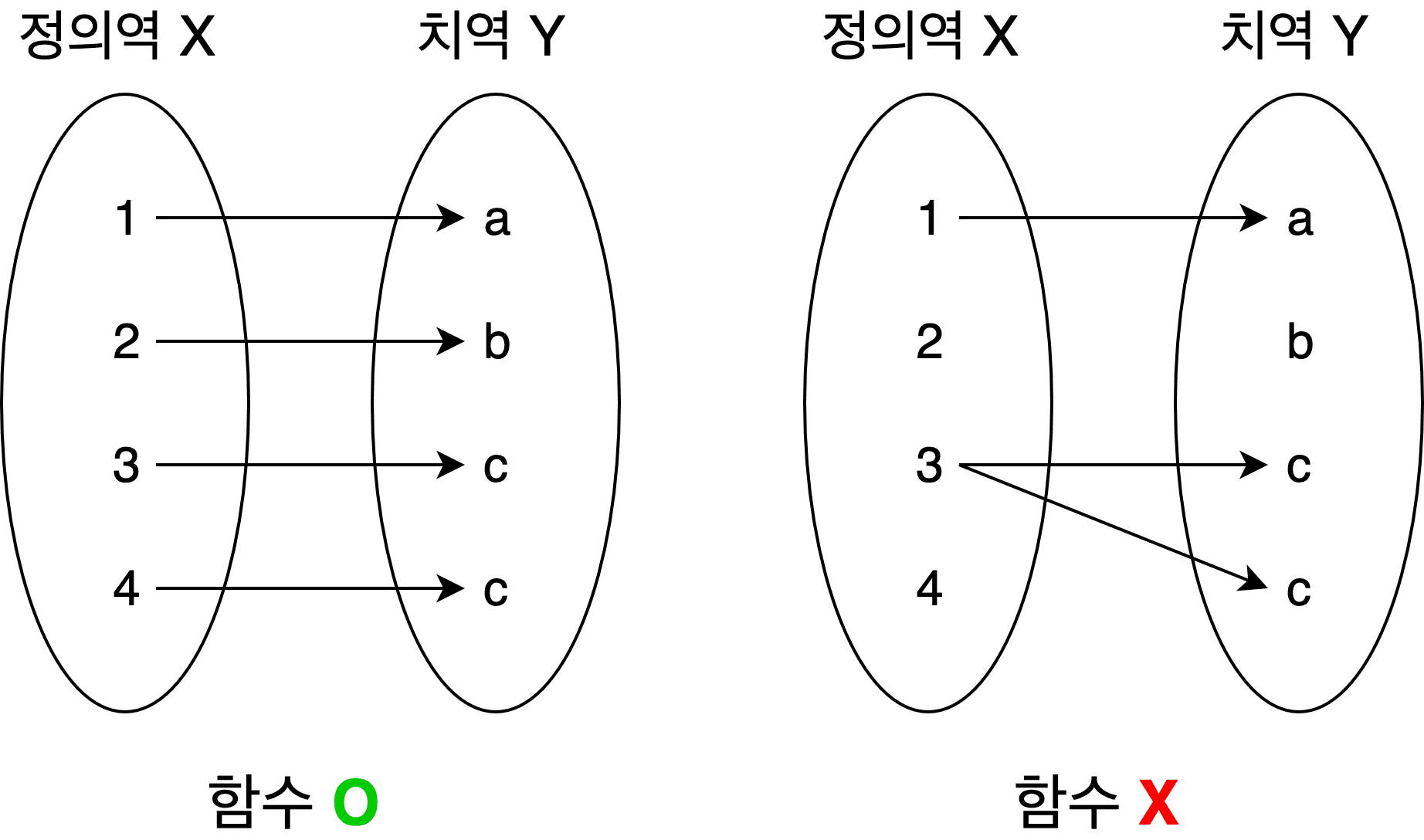
수학에서 등장하는 정의역은 정의역의 어떠한 원소도 치역의 원소 2개에 대응할 수 없습니다. 이와 매우 비슷하다고 볼 수 있겠습니다.
그러나 하나의 컨슈머 그룹의 컨슈머가 여러개의 파티션을 구독하는 것은 가능합니다. 이러한 특징 때문에 Consumer group에 소속된 Consumer의 개수는 구독중인 Topic의 partition 개수보다 같거나 적어야합니다.
만약 Consumer의 개수가 Topic의 개수보다 많다고 가정을 해보도록 하겠습니다.
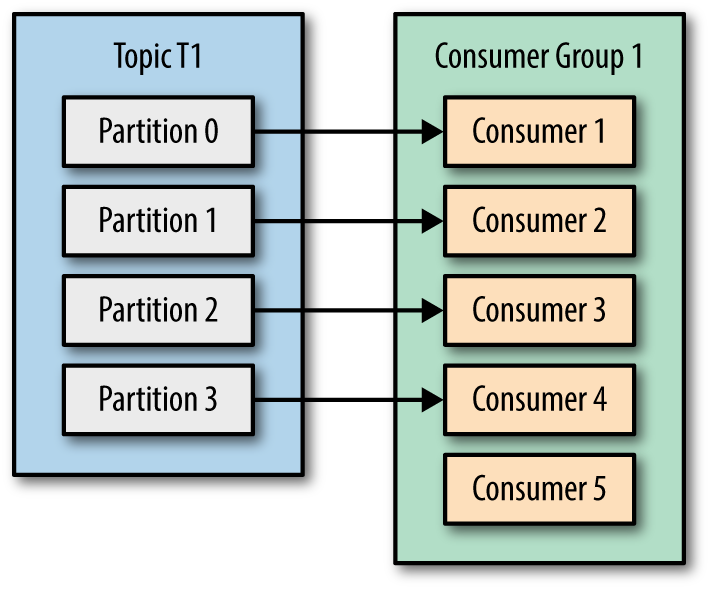
이 경우에는 Consumer 하나가 idle 상태에 빠져있기 때문에 Resource의 낭비가 발생하게됩니다. 다른 말로, 불필요한 스레드가 운영되고있는 상황이기 때문에 리소스의 낭비를 막기 위해서라도 partition의 개수보다 적은 개수로 consumer의 개수를 하나의 그롭에서 운영해야합니다.
그리고 Consumer group 간에는 독립이 되어있기 때문에 아래와 같은 운영도 가능할겁니다.
Kafka Streams를 통해서 발생한 데이터들이 토픽에 적재되면 각기 다른 컨슈머 그룹 2개가 Topic의 데이터를 독립적으로 읽어와서 한 그룹에서는 DynamoDB에 데이터를 적재하고, 또 다른 그룹에서는 Redis에다가 싱크를 맞춰준다.
이는 Consumer group간에 독립성이 보장되어있기 때문에 가능한 일입니다. 따라서 Consumer group의 경우 나눌수만 있다면 최대한 나눠주는것이 효율성 측면에서 아주 좋을겁니다!
다음으로는 Rebalancing 과정에 대해서 알아보겠습니다.
🔥 Rebalancing이란 무엇인가?
Rebalancing이라는 단어를 처음 들어보면 아래와 같은 생각이 드실겁니다.
🤔 다시 균형을 맞춘다..?
우선 저희가 컨슈머 그룹을 설명하면서 다루지 않았던, 그리고 지극히 고려해야할 상황에 대해서 설명하지 않았습니다. 그것은 바로 만약에 컨슈머 그룹에 속하는 컨슈머에서 장애가 발생하면 어떡해? 에 관한 것입니다.
컨슈머 그룹에 속하는 컨슈머에서 장애가 발생하게되면, 해당 컨슈머가 구독하고있던 파티션을 다른 컨슈머로 넘겨줄 필요가 있습니다. 그 때 파티션의 소유권을 다른 컨슈머에 넘기는 행위를 Rebalancing이라고 부릅니다.
Rebalancing은 다음의 두가지 상황에서 발생합니다.
- Consumer group에 새로운 consumer가 추가되어서 partition을 새로 분배해야할때
- Consumer group에서 컨슈머 하나 이상이 제외되는 상황 (i.e. Consumer가 장애를 일으켰거나 종료될 때)
리밸런싱 이전
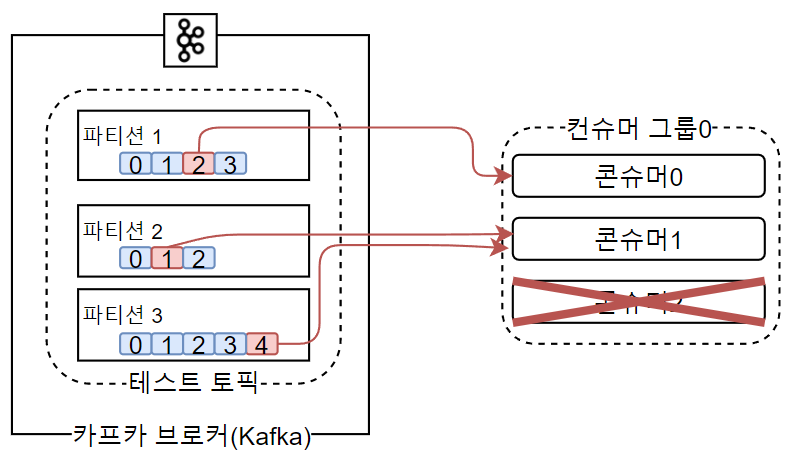
리밸런싱 이후
사실 더 나쁜 경우는 두번째 경우입니다. 두번째 상황이 발생하게 되면 리밸런싱 과정이 존재하지 않으면 데이터 처리에 있어서 지연이 생기거나 장애가 발생하기 때문에 Rebalancing 과정을 통해서 파티션을 재분배해줘야합니다.
그런데 Rebalancing 과정에서 파티션이 새로 분배가 되기 때문에 Consumer group에 속한 모든 코드들은 Rebalancing에 대한 대응 코드를 작성해야합니다. 이는 나중에 소개해드리겠습니다.
🔥 Rebalancing에 대해서 이야기를 해봤으니 Commit에 관해서도 설명하겠습니다.
이전 단락에서 Rebalancing에 대해서 이야기를 했습니다. 그런데 이제는 Rebalancing에 의해서 Commit에도 문제가 발생할 수 있음을 깨닫고, 그에 대해서 대응을 할줄 알아야할겁니다.
우선 SimpleConsumer 코드를 살펴보면 Commit 에 대한 코드는 존재하지 않음을 알수있습니다. 분명히 CLI를 다룰때는 Consumer는 데이터를 읽어올 때 offset을 커밋한다고 들었는데 말이죠! 그 비밀은 여기에 있습니다.
👉 Kafka Client에서 Consumer를 사용할 때 Auto_Commit(자동 커밋)의 기본 값은 true입니다. 따라서 configs에서 그에 대한 별도의 설정이 없으면 poll을 하면서 commit이 자동으로 이뤄집니다.
그리고 자동커밋의 경우 auto.commit.interval.ms 속성에 저장된 타임유닛 단위로 오프셋 커밋을 수행합니다. 만약에 poll 메소드를 실행하고 commit을 수행하는 사이에 컨슈머에 장애가 발생하여 rebalancing이 일어난다면 데이터의 중복이 발생할겁니다. 따라서 자동 커밋 옵션을 비활성화하고 명시적으로 commit을 수행하는것이 데이터의 유실 혹은 데이터의 중복을 방지하는 방법입니다!
그리고 commit을 수행하는데는 두 가지 방법이 존재하는데, 동기적으로 commit을 수행하느냐, 혹은 비동기적으로 commit을 수행하느냐입니다.
각자의 장단점에 대해서 알아보겠습니다.
1️⃣ 동기 처리를 통한 commit의 장단점
- 장점
- 데이터의 중복 처리가 발생하지 않는다.
- 단점
- 커밋이 완료될 때까지의 응답을 기다려야하기 때문에 카프카 브로커의 데이터 처리량에 악영향을 미친다.
2️⃣ 비동기 처리를 통한 commit의 장단점
- 장점
- 데이터 처리량이 높아진다.
- 단점
- 이전의 커밋 요청이 실패했을 경우 현재 처리중인 데이터의 순서를 보장하지못한다.
- 데이터의 중복 처리가 발생할 수 있다.
🔥 poll() 메소드의 실행 과정
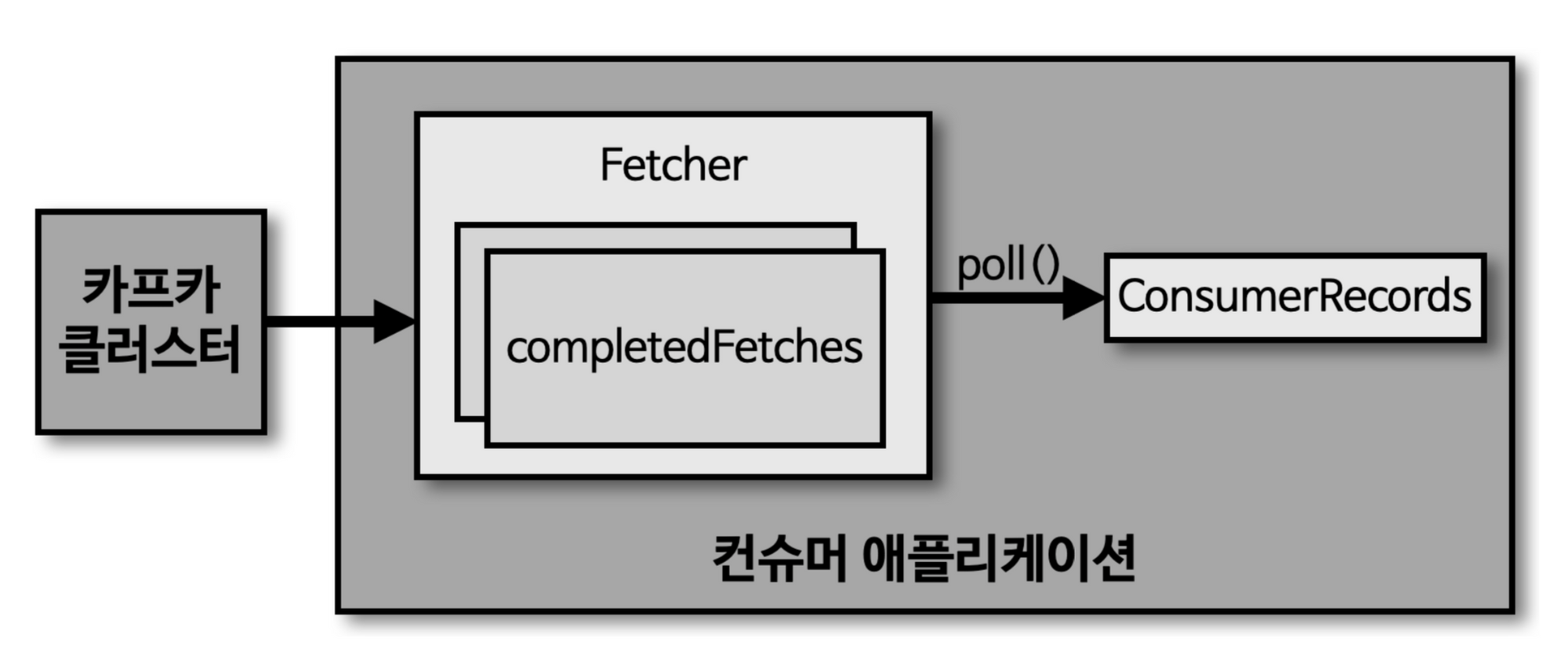
사실 이전 단락에서 poll() 메소드가 실행되면 record를 가져온다는 뉘앙스로 설명을 드렸지만, 사실은 아닙니다. poll() 메소드가 실행되기 이전에 컨슈머 애플리케이션이 실행되는 시점에서 fetcher 인스턴스가 생성되어 미리 record를 가져오게됩니다. 그리고 그 record는 모두 내부의 queue에다가 저장을 미리 해둡니다.
그리고 poll() 메소드를 호출하는 시점에서 comsumer는 queue에 존재하는 record를 반환받아서 처리를 수행하게됩니다.
그런데 문제가 하나 존재합니다. 만약에 내부 queue에 존재하는 record의 개수에 비해서 요청하는 데이터의 수가 많은 경우가 문제입니다. 이 경우에 대해서는 나중에 다뤄보도록 하겠습니다. 아직 나도 모르니까...
🌲 글을 마치며
글을 작성하다보니 그 이후의 실습 코드까지 작성하면 호흡이 지나치게 길어질까봐 여기서 흐름을 중단하고 그 이후의 실습코드는 2편에서 마저 작성하도록 하겠습니다.
다음 포스트에서 뵙겠습니다. 감사합니다!
