자연어처리모델의 이해
서론
최근 자연어처리와 관련한 대학원 수업을 들으면서 너무 이해가 안되어서 공부하는겸 정리를 해보려고 한다. 매번 소프트웨어 공학에서 마이크로서비스와 관련한 논문만 읽다가 Language Model과 관련하여 최신 트렌드의 논문을 읽는 것은 고문 그 잡채였다....
RNN
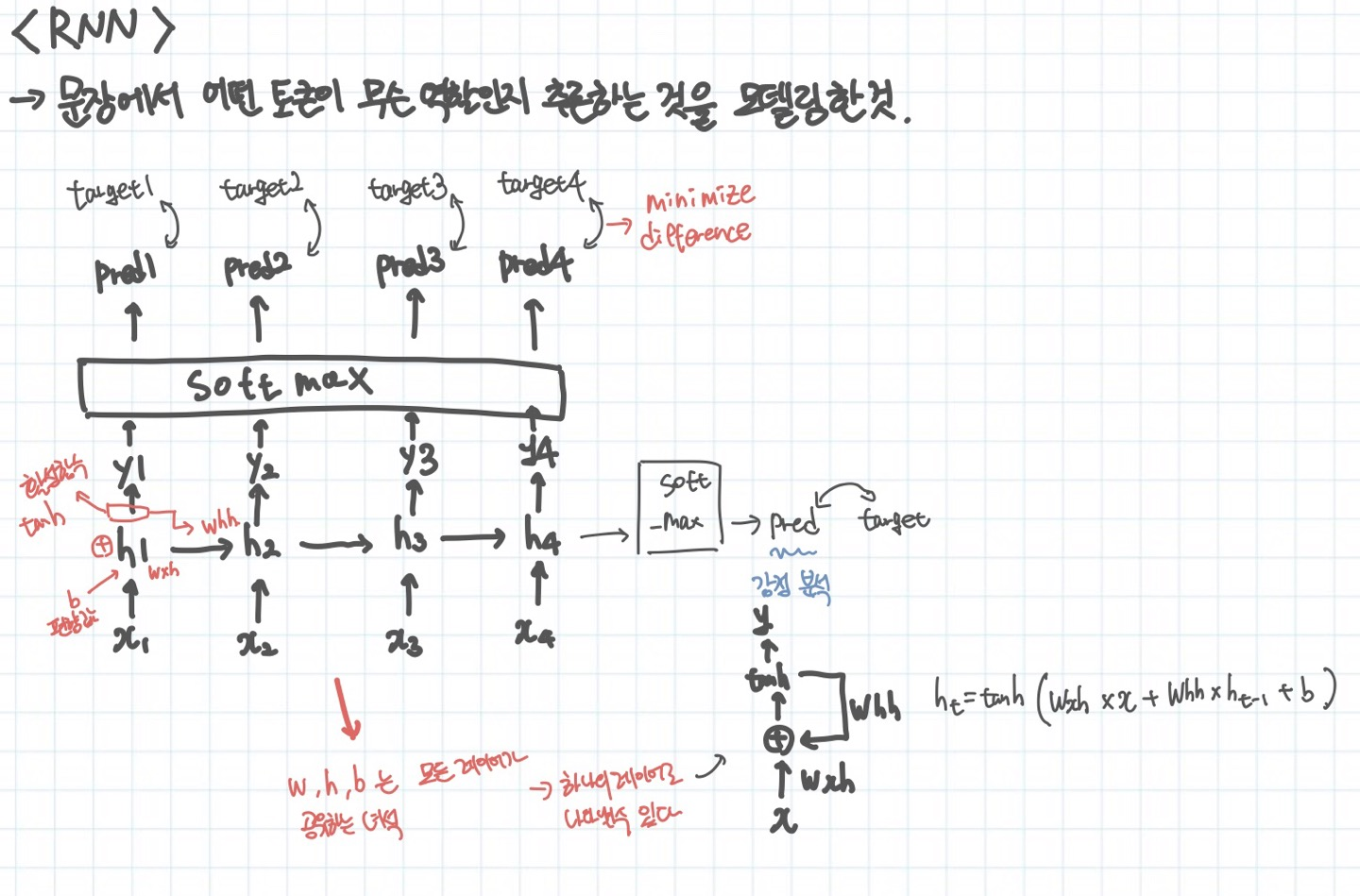
RNN이란
기본적인 딥러닝과 똑같지만 목적이 조금 다르다. 그렇기 때문에 계산을 하는 원리도 조금 다르다고 볼 수 있다. RNN의 목적은 자연어처리에 있다. 분류문제에서 어떤 input x가 어떤 라벨을 가지는지와는 달리 문장에는 순서가 존재한다. 그러므로 이러한 순서 정보를 가지고 순차적으로 계산할 필요가 있다.
그래서 위의 그림을 보면 h1 -> h2로의 어떤 정보가 전달되고 그 정보를 가지고 x2를 예측하는 식으로 흘러간다. 번역과 같은 문제에서는 input과 output의 토큰의 개수가 일치할 것이다. 만약 감정분석과 같은 문제를 처리한다면 h4에서 다음 단계로 전달되는 어떤 state를 softmax를 이용하여 확률로 나타내고 이것을 이용하여 감정을 예측한다.
해당 그림만 보더라도 문장이 엄청 길어지면 복잡한 연산이 이루어질 것이다. 왜냐하면 그림에서만 보아도 h4를 통해 예측된 pred4가 실제 target4와의 차이를 이용하여 학습을 진행하려면 엄청난 단계를 거쳐서 계산해야된다. 또한 이런 문제는 가중치가 거의 변하지 않거나 너무 들쑥날쑥하게 변하는 문제를 야기한다. 그리고 문맥을 이해하기 위해서 state를 계속 다음 단계로 전달해주는 것인데, 문장이 길어진다면 x1의 상태가 마지막 토큰에 올때쯤이면 거의 담겨져 있지 않을 수도 있다.
그래서 LSTM이 등장하게 된다.
LSTM이란
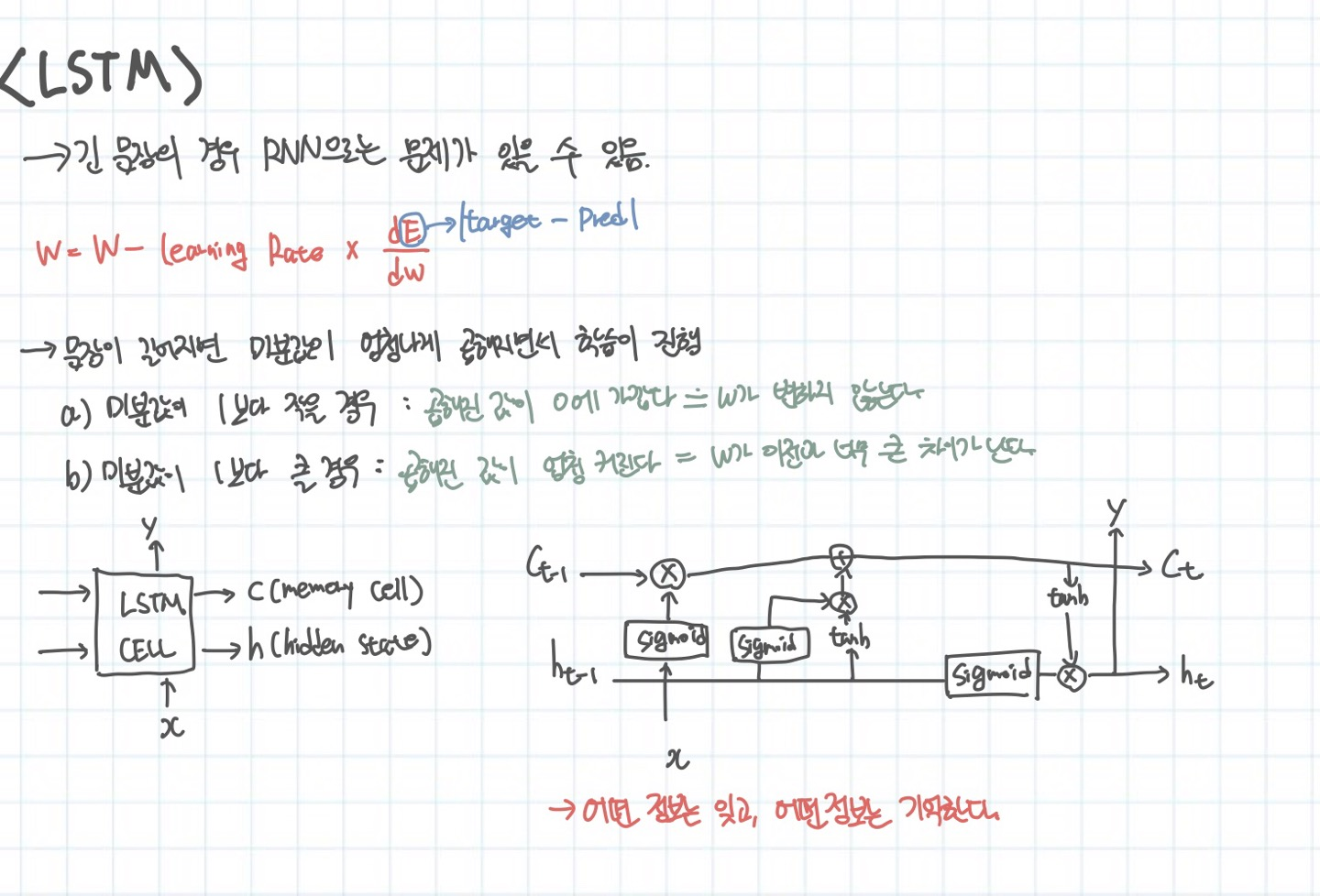
전에 말한바와 같이 RNN의 문제를 해결하기 위해서 진짜 중요한 정보만 담아서 넘기는 방식을 생각해내게 된다. 위의 그림에서는 이전 단락에서 설명한 RNN의 문제를 담고 있다.
기존에 h라는 state 값만 전달했다면 C라는 정보를 하나 더 전달한다. C에는 현재 토큰의 중요도를 계산해서 이전 단계에서 전달된 C의 일부 값만 담고 그 외에는 현재 토큰의 정보를 실어서 다음 단계로 전달한다. 그리고 h에 이 정보를 합쳐서 다음 셀에 전달한다.
결국, 어떤 정보는 잊고, 어떤 정보는 기억하는 특징을 가지고 있다. 이 방식이 중요한 점은 진짜 필요한 정보만 담아서 유지하는 것이다. 하지만 여전히 연산이 복잡한 것은 마찬가지이다.
Attention의 등장
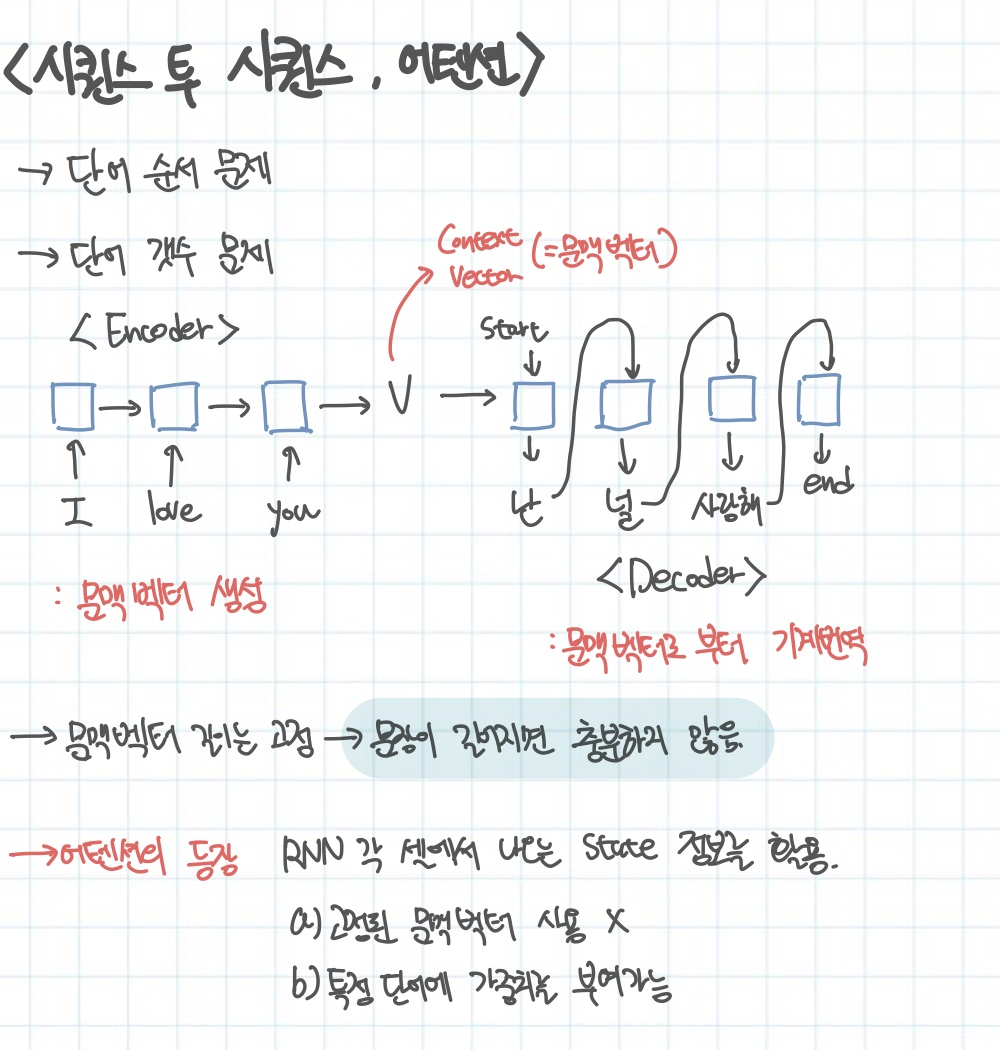
기본적인 RNN은 단어 순서를 유지하는 것, 그리고 단어 개수 문제가 있었다. 입력된 토큰과 똑같은 개수의 출력 토큰이 존재한다는 것이다. 위의 그림은 기본적인 RNN의 Encoder, Decoder 구조를 보여준다. 이때 문맥벡터인 V는 항상 고정이다. 문장이 100단어이든 1000단어이든 항상 고정이라는 문제가 있다. 그렇기 때문에 문장이 너무 길어지면 벡터에 그 문장의 의미가 다 담길 수 없는 문제가 있다.
그래서 등장한 것이 어텐션이다. RNN 각 셀에서 나오는 state 정보를 전부 활용하는 것이다. 이러한 장점은 고정된 문맥벡터를 사용할 필요가 없으며 특정 단어에 가중치를 부여하는 것이 가능하다.
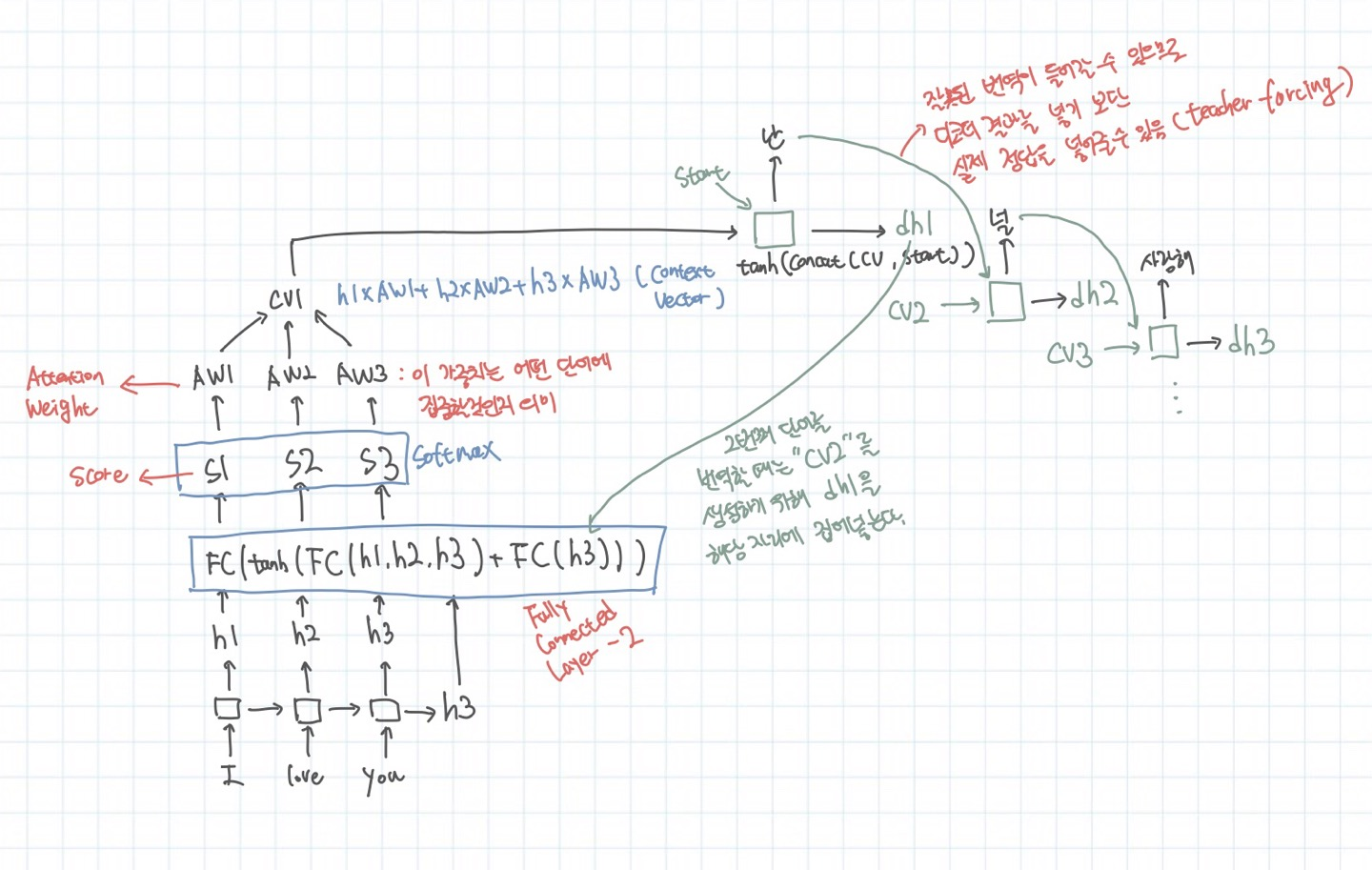
어텐션을 한눈에 요약하자면 다음 그림과 같다. 각 셀에서 나온 h1, h2, h3 그리고 최종 state가 FullyConnectedLayer에 들어가서 계산된 후에 Score가 매겨진다. 문맥백터를 생성한다. 그리고 이 문맥백터가 첫번째 Decoder셀에 start 시그널과 함께 들어가면 출력이 나온다. 이 출력이 다시 FullyConnectedLayer에 들어가서 다음 문맥벡터를 계산하고 해당 문맥벡터가 Decoder 2번째 셀에 들어가서 출력이 나오는 식으로 end 시그널이 나올때까지 진행된다.
하지만 여전히 순차적인 계산이 필요하다. 하지만 문맥벡터가 유동적인 점에서 장점을 지닌다.
어텐션 올 유 니드(Transformer)
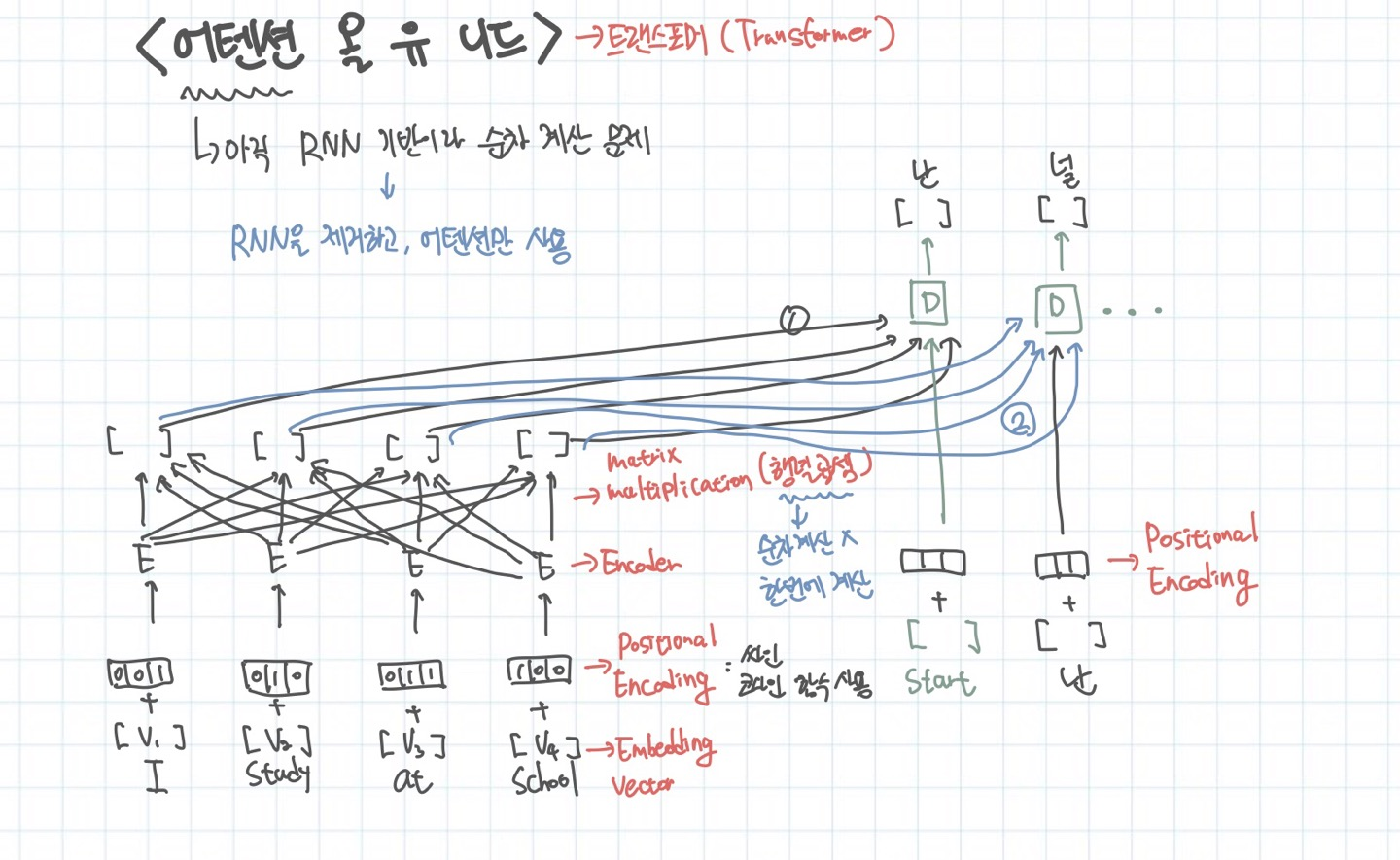
단순하지만 혁신적인 아이디어가 등장한다. 어텐션 올 유 니드는 해당 논문의 제목이다. 이 논문은 트랜스포머라는 것을 제안한다. 기존의 어텐션도 순차적인 계산을 하는 문제가 있었다. 왜냐하면 다음 셀에 이전의 state값을 여전히 전달하고 있었기 때문이다. 그러나 사람들은 이 정보 없이도 충분히 가능하다고 생각했고, 결국 해냈다.
각 토큰을 임베딩하고 포지셔널 인코딩 정보(토큰의 상대적 위치)를 합하여 Encoder에 집어 넣는다. 그리고 단순한 행렬 곱 연산을 통해 각 토큰의 정보(문장에서의 입지, 의미)를 가진 벡터가 계산되어진다. 이 정보가 디코더에 들어가서 출력 벡터를 뱉는다. 디코더는 현재까지 디코더에서 출력된 정보와 인코더에서 출력한 토큰의 임베딩 벡터 값을 입력으로하여 연산을 진행한다.
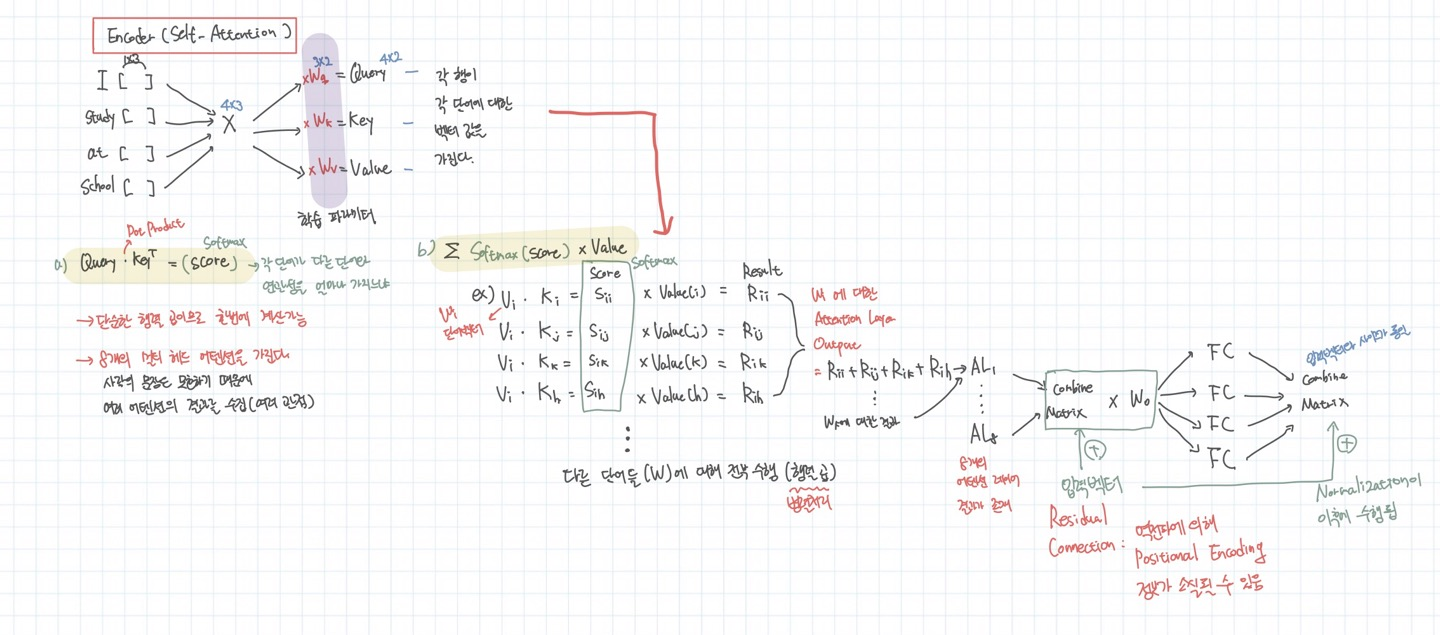
인코더의 내부를 들여다 보면 다음과 같다. 이 과정을 Self Attention이라고 부른다.
문장이 임베딩되고 이 벡터를 다 합쳐서 하나의 매트릭스를 만든다. 여기에 각각 쿼리 가중치, 키 가중치, 밸류 가중치를 곱하여 쿼리, 키, 밸류의 의미를 지니는 매트릭스로 변형한다. 이 후에 쿼리와 키, 밸류를 이용하여 행렬 곱 연산을 한다. 결국 하나의 단어가 해당 문장에서 어떠한 관련성을 갖는지를 계산하는 최종 벡터가 나온다. 그림에서는 해당 벡터가 Rii ~ Rih를 다 더한 값이다. 모든 단어에 대해 문장에서의 관련성을 계산해서 다 더하면 AL1이 된다. 이러한 8개의 셀프 어텐션이 존재하기 때문에 AL8까지 존재한다. 이 이유는 여러 관점에서 계산하여 오류를 줄이기 위해서이다. 머신러닝 동네에서의 앙상블을 의미하는 것 같다. 이후에 AL을 전부다 합쳐서 다시 FullyConnectedLayer를 통해 학습을 진행한다.
이때 입력 매트릭스의 사이즈와 출력 매트릭스의 사이즈는 동일하다. 물론 여기 그림에서 자세하게 나타나지 않은 것으로는 Residual Connection으로 RNN에서 기존 정보를 잃지 않기 위해 입력 값을 그대로 전달해주는 과정이 존재한다. 그리고 Residual Connection 뒤에는 항상 Normalize가 뒤따른다.
정말 복잡하다고 생각할 수 있지만 이런 AttentionLayer를 6개를 붙여서 학습한다. 이 때 중요한 점은 각 레이어마다 개별적으로 가중치가 학습된다.(각 레이어들이 학습에서 가중치를 공유하지 않는다)
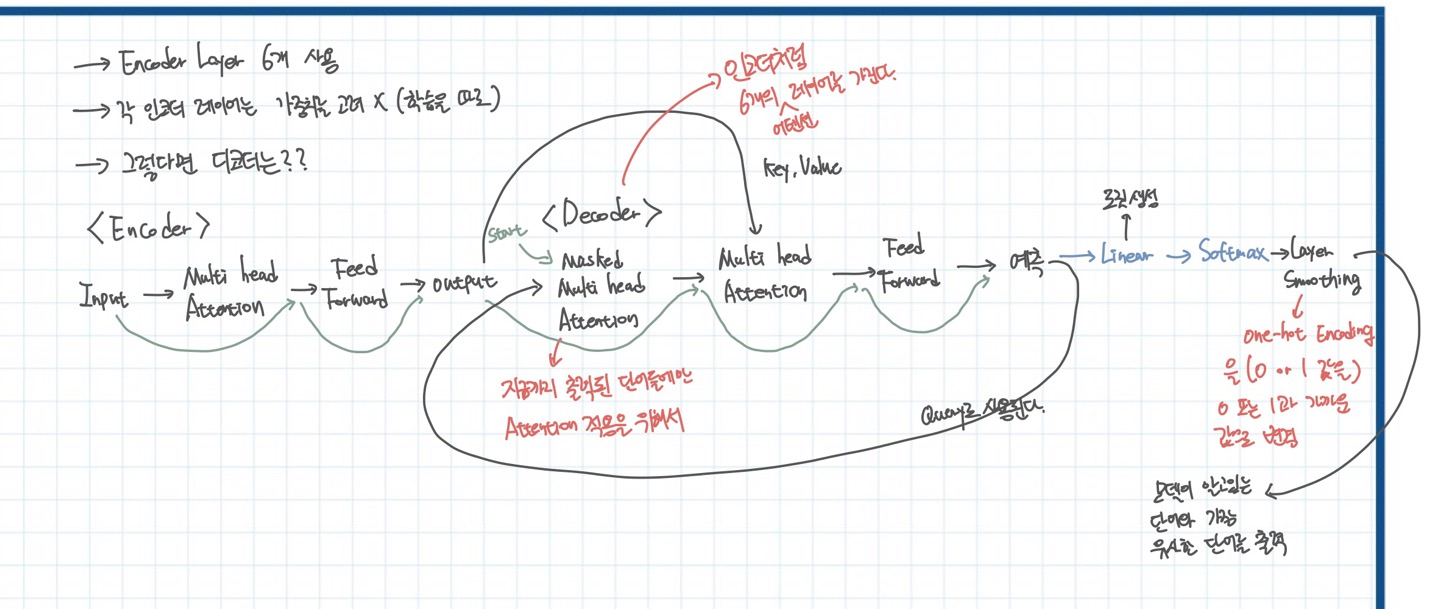
이제는 디코더를 알아보자. 디코더 역시 인코더와 동일하다. 하지만 초반의 Masked MultiHead Attention인 이유는 디코더는 항상 현재까지 디코더에서 나온 출력이 들어가야하기 때문이다. 원래의 어텐션이 한번에 다 들어가서 한번에 결과가 나오는 것과 달리 현재까지 예측된 단어들만 들어갈 수 있다!! 디코더 역시 Residual Connection이 존재한다. 그리고 인코더의 아웃풋이 어텐션에서 키와 밸류의 역할을 하게 된다. 최종적으로 Softmax에 들어가고 Layer Smoothing을 진행한다.
Layer Smoothing을 하는 이유는 yellow가 노란색 뿐만 아니라 누런색도 될 수 있는데, one-hot 인코딩으로 진행하게 되면 노란색을 나타내는 벡터와 누런색을 나타내는 벡터가 완전히 다르게 표현될 것이다. 하지만 Layer Smoothing을 하면 0과 가까운 값, 1과 가까운 값을 이용하여 표현하기 때문에 해당 상황에서 두 벡터간의 차이를 줄이고 학습의 효과를 증가시킬 수 있다.
BERT

항상 한쪽 방향으로만 진행하는 자연어 처리 방식에서 벗어나는 모델이다. GPT가 문장에서 다음 토큰을 예측하는 형태로 학습을 진행했다면, BERT는 문장에서 하나의 토큰을 마스크처리하고 해당 토큰을 예측하는 형태로 학습을 진행한다. Pretrain된 모델을 가지고 여러 Downstream Task를 처리하기 위해 Fine-Tuning하여 사용한다.
후기
사실 급하게 공부하느라 많이 찾아보지 못했다. 해당 게시글에서 가장 중요한 것은 Transformer이다. 현재 내가 듣고 있는 수업에서 강조하고 있는 부분이기도 하다. 그래서 BERT같은 경우 자세하게 설명하지는 않았다.
지금은 Transformer Layer에 Adapter를 붙여서 여러 Downstream Task를 위해 Full fine tuning을 하지 않고 Adapter만 학습시켜 학습 파라미터를 줄이고 전이학습에서의 효율성을 입증하는 논문을 읽고 있다.
또 Prompt Tuning을 효율적으로 진행하는 방식에 대한 논문도 존재한다.
이러한 논문에서 항상 등장하는 Transformer 구조라던가 비교되는 모델들을 이해하기 위해서는 자연어처리의 기본을 공부할 필요가 있었다. 공부하면서 덕지덕지 이어붙인 레이어들을 누가 생각해냈을까? 우연일까? 의도일까? 이런 것들을 생각하며 감탄하니까 금방 재미를 붙이고 공부를 할 수 있었던 것 같다!!
