__
너도 알고 나도 아는 그 판다스. 파이썬에서 제공하는 컨테이너보다 훨씬 빠른 속도와 편리성을 제공해서 데이터 분석 분야에선 거의 필수로 쓴다.
- 판다스랑 넘파이 불러오기.
!pip install pandas numpy
import pandas as pd
import numpy as np
데이터프레임 생성
참고로 코랩에 붓꽃데이터같은게 기본으로 있어서 가져다 쓰면 된다. 근데 울프람 매스메티카에도 그런거 있는거 보면 다른데도 기본적으로 다 있는듯??
data = {
'name' : ['영수','철수','영희','소희'],
'age' : [20,15,38,8]
}
df = pd.DataFrame(data)
df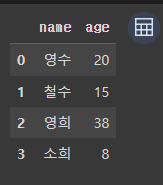
원소 추가
doc = {
'name':'세종',
'age':14,
}
df = df.concat(doc,ignore_index=True)- 마지막 행 뒤에 세종을 추가함
- ignore_index = True : 인덱스를 안 붙이고 마지막에 넣음
df['city'] = ['서울','부산','부산','서울','서울']- 'city' 열이 추가됨

원하는 행 가져오기
df[['name','city']] 이런 식으로 원하는 열만 출력할 수도 있다.
df[조건] 으로 True 인 행만 가져올 수도 있다.
cond = df['age'] < 20
df[cond]
- cond = (df['age'] < 20) & (df['age'] > 5) 처럼 조건을 여러 개 넣을 수도 있다.
df.iloc[-1,0] # 마지막 행
df.iloc[0,0] # 첫 행
리스트 슬라이랑 비슷하다
정렬
df.sort_values(by='age',ascending=True)
- age 열의 값을 기준으로 정렬함
- ascending : 오름차순 (False -> 내림차순)
조건에 맞는 열 추가
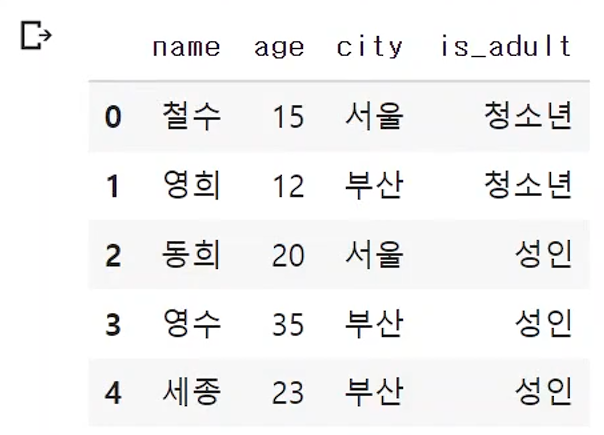
df['is_adult'] = np.where(df['age'] > 20,'성인','청소년')- age값 20 을 기준으로 청소년과 성인 값을 가지는 열을 추가함.
평균 구하기
df['age'].mean() # 평균
df['age'].max() # 최대값
df['age'].min() # 최소값
df['age'].count() # 나오는 횟수- describe() 매서드를 사용하면 전부 나온다.
파일 읽기
- 코랩이나 서버에 해당하는 이름의 파일이 있어야 한다.
df = pd.read_excel('종목데이터.xlsx') #엑셀 파일 불러옴
df.head(10) # 위에서 10 개 행 불러옴 (뒤에서부터 불러오는건 tail())pd.options.display.float_format = '{:.2f}'.format
소수점 둘째 자리까지만 나오게 함.
분석 직접 해보기
df[df['change_rate'] > 0]
# 어제 오른 종목들 골라보기
# per = 시가총액 / 순이익 = 주가 / 주당순이익
# -> 주가 = per * 주당순이익
df['close'] = df['per'] * df['eps']
# -> 순이익 = 시가총액 / per
df['earning'] = df['marketcap'] / df['per']열 없애기
del df['date'] #'date' 열을 삭제함