공부중인 내용이라,
혹시 틀리거나 좋은 방향성을 알려주시면 최대한 흡수해보겠습니다 :)
오늘은 2월 22일.
이제야, 밸로그를 쓰게되어서 앞내용은 추후 업데이트 하기로하고 지금 복습하는 내용을 위주로 포스팅해보자!
<머신러닝 분류분석 알고리즘>
04-1. (이진분류) Logistic Regression
04-2. (다지분류) Logistic Regression
패키지 로딩
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, f1_score, classification_report,roc_auc_score
import numpy as np
import pandas as pd데이터 로딩
from sklearn.datasets import load_iris
상기 sklearn의 datasets 패키지에는 일명 붓꽃데이터가 존재하는데, 잘 정제된 데이터로 다양한 모델링에 사용되고있다.
특히 해당 데이터의 경우,
따로 독립변수와 종속변수를 지정하지 않고 클래스를 통해 불러올 수 있다.
iris=load_iris()
x=iris.data
y=iris.target일반적인 데이터는 열을 슬라이싱 및 인덱싱하여 불러와야하지만,
~.data 로 독립변수를, ~.target으로 종속변수를 할당할 수 있다.
해당 데이터셋을 좀더 보기쉽게 독립변수와 종속변수를 포함한 데이터프레임으로 만들어보자.
df=pd.DataFrame(x,columns=iris.feature_names)
df['class']=y
df.head()
df['class'].value_counts()이렇게 panda를 활용하면 되는데,
먼저 독립변수 기준으로 데이터 프레임을 만들고,
pd.DataFrame(x,columns=iris.feature_names)
- ~.feature_names 클래스는 데이터셋의 열명을 가져온다. 데이터프레임의 columns와 유사하다.
종속변수를 'class'열에 y값으로 넣어준다.
df['class']=y
학습/평가 데이터 분리하기
추후 모델을 생성하면,
그 모델을 훈련시킬 데이터가 필요하고(학습데이터),
완성된 모델이 잘 작동하는지 확인할 데이터가 필요하다.(평가데이터)
x_train, x_test, y_train, y_test =
train_test_split(x, y, train_size=0.8, stratify=y, random_state=0)from sklearn.model_selection import train_test_split
해당 패키지 분리를 위한 클래스를 불러와,
<필수 파라미터>
- x, y = 분리할 데이터의 독립, 종속변수
- test_size, train_size(중 하나만) 학습/평가데이터의 비중
<부가 파라미터>
- stratify : 분류모델에 대해 분류된 클래스에서 1:1 비율로 데이터를 추출할것을 명시하는 것
- random_state : random 하게 추출한 데이터를 저장하는 seed로 뒤에 상수는 아무거나 적어도 된다.
모델 생성 및 훈련하기
데이터에 따라 알맞는 알고리즘의 모델을 생성한다.
아이리스는
y값이 0,1,2로 분류되는 다항/분류데이터이다.
그러므로
- 회귀모델이 아닌 분류분석모델을 선택해야하고,
- multi_class파라미터를 통해 다항데이터를 분석할 방식을 지정해야한다.
model=LogisticRegression(multi_class='ovr',max_iter=2000)
model.fit(x_train, y_train)해당 모델에서 "확인이 필요한 부분"
- multi_class : 'ovr' 또는 'multinominial' depends on solver
- ovr : (liblinear) one vs rest 로 이진형태의 데이터 비교분석
- multinominial : (이외)
모델 예측
만들어진 모델로,
테스트 데이터를 활용해 예측값을 출력하고
테스트 데이터 마다 클래스별 예측값의 확률을 확인한다.
y_hat=model.predict(x_test)
prob=model.predict_proba(x_test)prob의 경우 클래스당 예측확률을 보여주는 함수인데,
한 데이터가 여러 독립변수를 통해 어떤클래스에 속하게될지 그 확률을 보여준다.
<예시> 아래는 model.predict_proba(x_test)[0] 값으로
[0.001 0.361 0.638] 결과를 나타낸다.
결과값은 순서대로 클래스 0,1,2에 속할 확률을 의미하며
이 경우, y_hat의 값으로 클래스2가 출력하게 된다.
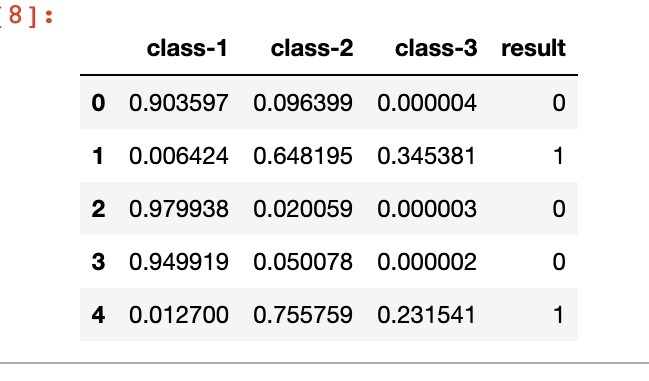
해당 결과값은 데이터프레임으로 정리해서 확인해보면
df=pd.DataFrame(prob[:5], columns=['class-1','class-2','class-3'])
df['result']=np.argmax(prob[:5], axis=1)
print(df)아래와 같이 출력된다.
모델 평가
accuracy & AUC
평가 부분은 모델의 종류에따라 상이하다.
회귀모델의 경우, R_square, MSE, RMSE, MAE 등
분류모델의 경우, accuracy, precision, recall, f1 등
이 있다.
그중 정확도(전체 중 맞춘 비율)과 AUC(임계값의 면적)을 출력해보자.
print(f'Accuracy: {accuracy_score(y_test, y_hat):.3f}')
print(f'AUC: {roc_auc_score(y_test, prob, multi_class="ovr"):.3f}')정확도를 알아보기위한 클래스에서는
1. 실제값과
2. 예측값
임계값의 면적을 알아보기위한 클래스에서는 아래 파라미터가 필요하다.
- 실제값과
- 실제값을 예측할 확률,
*prob=model.predict_proba(x_test) - 어떤 값을 positive로 평가할것인지
혼동행렬 & Report
혼동행렬
confusion_matrix(y_test, y_hat)Report)
종합적인 매트릭값(평가값)을 출력해주는 함수로
정확도, macro avg, weighted avg를 출력함
확인필요
~~정확도(accuracy)
macro avg = macro f1으로 산술평균로 클래스별 매크로제공
weighted avg = 가중평균
micro avg
~~
classification_report(y_test, y_hat)