[dplyr packages]
dplyr 패키지 : 데이터 가공의 필수 패키지
→ 데이터 가공 : 데이터 분석을 편하게 하기 위해 분석가의 관점에 따라 데이터를 편집하는 과정
# 패키지 설치 및 메모리
install.packages("dplyr")
library(dplyr)
# dts 설정
a <- ggplot2::mpg0. %>%
파이프 연산자 %>%
: 데이터나 결괏값을 새로운 변수에 저장하는 과정을 거치지 않고 데이터와 함수를 연결하여 사용 가능, 원래는 dplyr 등의 패키지를 사용해야만 쓸 수 있었지만 4.1 버전 이상에서는 global options에서 use native pipe operator를 사용하여 |> 를 파이프 연산자처럼 사용 가능
1. filter()
filter() : 조건에 맞는 데이터를 필터링하는 함수, 행 추출
# 1. manufacturer가 chevrolet인 경우
a %>%
filter(manufacturer=="chevrolet")
# 2. manufacturer가 chevrolet와 volkswagen인 경우
# 2-1)
a %>%
filter(manufacturer=="chevrolet" | manufacturer=="volkswagen" )
# 2-2)
a %>%
filter(manufacturer %in% c("chevrolet", "volkswagen"))
# 3. manufacturer가 chevrolet와 volkswagen가 아닌 경우
a %>%
filter(manufacturer!="chevrolet" & manufacturer!="volkswagen" )
# 4. manufacturer가 chevrolet이면서 hwy가 20 이상인 경우
a %>%
filter(manufacturer=="chevrolet" & hwy>=20)
# 5. manufacturer가 chevrolet이면서 hwy가 20 이하 또는 cty가 15 이상인 경우
a %>%
filter(manufacturer=="chevrolet" & (hwy<=20 | cty>=15))2. select(), pull()
select() : 지정한 변수만 추출하는 함수, 열 추출, return type은 data.frame
# 1. 전체 column 조회
a %>%
select() # A tibble: 234 × 0 라는 결과가 출력됨
a %>%
select(everything()) # select(everything()) : 전체 column 출력
# 2. manufacturer, model 열 전체 조회
a %>%
select(manufacturer, model)
# 3. trans, class 열을 제외하고 전체 조회
a %>%
select(-trans, -class)
# 4. manufacturer가 chevrolet인 model과 fl 조회
a %>%
filter(manufacturer=="chevrolet") %>%
select(model, fl)
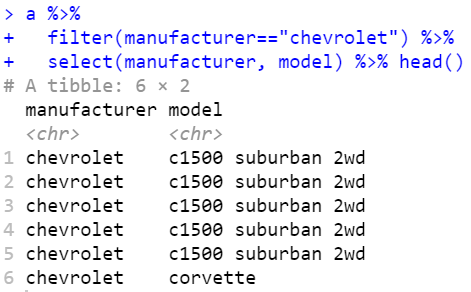
# manufacturer가 chevrolet인 model 조회
a %>%
filter(manufacturer=="chevrolet") %>%
select(manufacturer, model) %>% head()- select() 사용하면 data.frame으로 출력
pull() : 열 추출하는 함수, return type은 vector
# manufacturer가 chevrolet인 model 조회
a %>%
filter(manufacturer=="chevrolet") %>%
pull(manufacturer, model) %>% head()- pull() 사용하면 vector로 출력

3. arrange()
arrange() : 데이터를 오름차순 정렬하는 함수, 내림차순 정렬 시 desc() 함수를 사용, 숫자일 경우에는 –변수명 사용 가능
# 1. cty, hwy 오름차순 정렬
a %>%
arrange(cty, hwy)
# 2. cty, hwy 내림차순 정렬
# 2-1)
a %>%
arrange(desc(cty), desc(hwy))
# 2-2)
a %>%
arrange(-cty, -hwy)4. mutate()
mutate() : 데이터 세트에 열을 추가하는 함수, 파생변수(기존의 column을 사용해서 새로운 column 생성)를 생성, 한 번에 여러 파생변수 생성이 가능하고 생성이 완료되지 않은 파생변수도 사용이 가능하다.
# datasets
my_att <- datasets::attitude %>% head(3)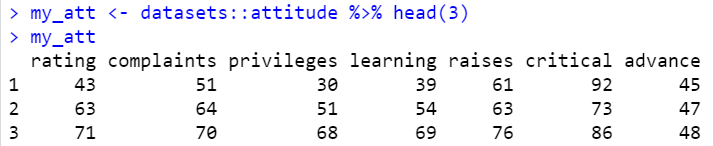
# 내장함수 방식 -- $
# rating, complaints 합계 파생변수 sum 생성
my_att$sum <- my_att$rating + my_att$complaints
# rating, complaints 평균 파생변수 avg 생성
my_att$avg <- my_att$sum / 2
# dplyr 방식 -- mutate()
# datasets
my_att2 <- datasets::attitude %>% head(3)
# rating, complaints 합계 파생변수 sum과 평균 파생변수 avg 생성 및
# avg가 70점 이상이면 "P", 아니면 "F" 출력하는 파생변수 test 생성
my_att2 <- my_att2 %>%
mutate(sum=rating+complaints, avg=sum/2, test=ifelse(avg>=70,"P","F"))

재밌당
우와