[기본]
getwd() : work directory 확인
. : 현재 폴더 위치
.. : 현재 부모 폴더 위치
setwd() : work directory 변경
install.packages("") : pkgs(패키지) 설치
installed.packages("") : pkgs 설치 확인
library() : 설치된 pkgs 리스트 확인
library(pkgs) : pkgs 메모리에 올리기
detach() : pkgs 메모리에서 내리기
data(package = "") : 특정 pkgs dataset 확인
[dts 속성 확인 함수]
class() : 객체 Type 확인
dim() : 차원 정보, 1차원일 경우 m행 n열로 표시
head() : 앞 행 6줄 조회
head(,n) : 앞 행 n줄 조회
length() : colums의 개수 (테이블 길이)
typeof() : 객체 Type 확인
levels() : 범주형 데이터...
names() : column명 확인
str() : data type과 data 속성을 보여줌
summary() : 요약 통계량
tail() : 뒤 행 6줄 조회
tail(,n) : 뒤 행 n줄 조회
rownames() : 행 이름
View() : 원 자료 확인 명령어
[기타 함수]
1. 숫자 변수
c() : 여러 개의 값 할당
seq() : 데이터 간격이 규칙적일 경우
seq(시작, 끝, by=간격)
seq(시작, by=간격)
2. 문자 변수
char1 <- "aaa"
length(char1) # 1
char2 <- "Hello R programming"
length(char2) # 1
char3 <- c("Hello", "R", "programming")
length(char3) # 33. rep()
rep() : 반복문자값 생성 함수
rep(dts, each, times, length.out)
dts : datasets, each : data 하나 반복 횟수, times : data 전체 반복 횟수, length.out : 표현될 수 있는 data 사이즈(출력할 data 개수)
r1 <- rep(1,5)- r1 이미지

r2 <- rep(1:5,3)- r2 이미지

r3 <- rep(1:5, each=3)- r3 이미지

r4 <- rep(1:5, each=3, times=3, length.out=10)- r4 이미지

4. 집합 연산, set()
set1 <- seq(10, 100, by=2); set1
set2 <- seq(30, 150, by=4); set2
union() : 합집합, 중복 제거
union(set1, set2)
union(set1, set2) |> length() # 59
intersect() : 교집합
in_set <- intersect(set1, set2) # 변수 처리
intersect(set1, set2) |> length() # 18
setidff() : 차집합
setdiff(set1, set2)
setdiff(set1, set2) |> length() # 13
setdiff(set2, set1)
setdiff(set2, set1) |> length() # 28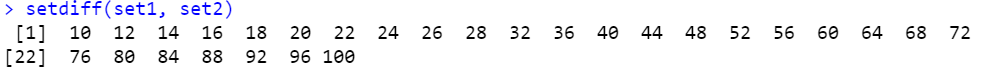
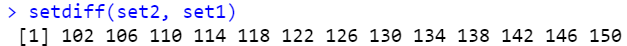
setequal() : 중복 제거 value 값만 비교,
setequal(set1, set2) # FALSE setequal(c(1,4,5), c(1,1,1,4,4,5,5,5,5,5)) # TRUE, 중복 값 제거 후 비교
is.element() : %in%과 같은 역할
is.element(11, set1) # FALSE is.element(12, set1) # TRUE
5. 숫자 랜덤 생성, sample()
sample(1:50) # 1부터 50까지 랜덤 나열
a <- sample(1:50,15) # 1부터 50까지 15개 랜덤 추출 6. dts[index | 조건]
dts[index | 조건] : 해당 index 값 출력 또는 조건에 맞는 값 출력
a <- sample(1:50,15)
a[1]
a[2]
a[3]
a[c(11,2,4)]
a[c(11,2,4)] <- NA # 데이터 값 update(sql에서도 값 하나만 삭제는 불가능,, 행단위로만 삭제 가능하므로 값만 바꿀때는 update사용했음)
a[c(11,2,4)]
7. 데이터 정렬 함수
rank() : NA를 포함한 데이터의 순위를 매김
a
rank(a) # 작은 수치를 1로 시작하여 순위를 매김(NA는 제일 후순위), 순위를 나타냄
rank(-a) # 큰 수치를 1로 시작하여 순위를 매김(NA는 제일 후순위)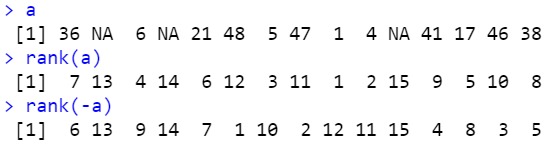
# NA
a
rank(a, na.last = T) # NA는 후순위로 보내라는 옵션.. default 값임
rank(a, na.last = F) # NA를 1로 시작하라는 옵션
rank(a, na.last = "keep") # NA는 순위를 매기지 말라는 옵션
rank(a, na.last = NA) # NA는 제거하여 출력도 하지 않겠다는 옵션
sort() : NA를 제외한 데이터 오름차순 정렬
a
sort(a)
sort(a, decreasing = T) # 데이터 내림차순 정렬
# NA를 표기하고 싶다면
sort(a, na.last = T) # 오름차순 정렬, NA 포함 및 후순위
sort(a, na.last = F) # 내림차순 정렬, NA 포함 및 선순위
order() : NA를 포함하는 정렬된 data를 기준으로 원 자료의 index number를 return
a # 원 자료
sort(a) # 정렬
order(a) 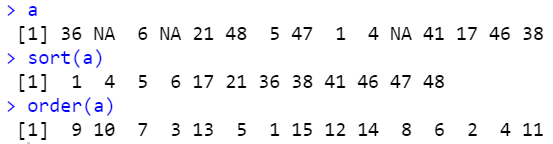
# 역정렬 관련
a
sort(a, decreasing = T)
order(-a) # NA는 후순위
# NA 표기
order(a)
order(a, na.last = T) # default
order(a, na.last = F)
# NA 제거
order(a, na.last = NA)

제리를 본받자.