
0827
1. 연결 리스트(linked list)란?
각 노드가 데이터와 포인터를 가지고 한 줄로 연결되어 있는 방식으로 데이터를 저장하는 자료구조
연결 리스트의 구성 요소로는
- 노드 : 데이터를 넣을 수 있는 공간과 주소를 넣을 수 있는 공간이 있는 것
- 데이터 공간 :
- 포인터 공간 : 다음 노드의 주소값을 가리킨다.
1.1. 장점
- 추가/삽입 및 삭제가 용이합니다.
- 크기를 마음껏 조정할 수 있습니다.
2. 연결 리스트의 구조
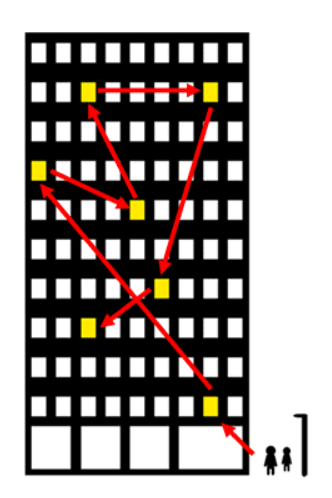 연결 리스트는 다음과 같은 아파트의 호실 형태라고 보시면 됩니다.
연결 리스트는 다음과 같은 아파트의 호실 형태라고 보시면 됩니다.
분명 방은 다 흩어져 있는데 연결이 되어있죠? 이것이 가능한 이유는 연결리스트의 구성요소인 노드가 데이터 공간과 함께 포인터 공간, 즉 다음 노드의 주소를 참조하고 있기 때문입니다.
더 쉽게 말하자면 노드1은 자신이 가지고 있는 노드2의 주소만을 따라가서 노드2와 연결되는 겁니다.
여기서 우리는 왜 연결리스트인지에 대해 알 수 있습니다.
연결리스트는 다른 것들과 다르게 그 위치가 흩어져 있어 서로 주소로 연결되어있어야 한다는 의미로 연결이라는 키워드가 사용된 것이죠.
3. 단일 연결 리스트 (Singly Linked List)
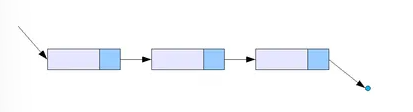
각 노드의 자료공간과 포인터 공간이 각각 한 개씩만 존재하는 리스트
여기서는 마지막 포인터를 제외한 나머지 노드가 다음 노드에 대한 참조만을 가집니다.
3.1. 시간 복잡도
| 단일 연결 리스트 | |
|---|---|
| 접근 | O(n) |
| 검색 | O(n) |
| 삽입 | O(1) |
| 삭제 | O(1) |
-
접근, 검색 : 가장 마지막 원소를 찾으려면 배열처럼 처음부터 끝까지 찾아봐야 하기 때문에 시간복잡도는 O(n) 을 갖습니다.
-
삽입, 삭제 : 연결리스트는 포인터가 주소를 참조하여 연결되는 방식이므로 원하는 값을 삽입 또는 삭제할 때 해당 주소로 가서 바로 삽입 또는 삭제가 가능합니다. 따라서 제일 빠른 시간복잡도인 O(1) 를 갖습니다.
3.2. 단점
- HEAD (첫 번째 데이터 노드)가 참조하는 주소를 잃어버린다면 나머지 데이터 전체를 못 쓴다.
일렬로 연결되는 구조의 특성상 중간에 어떤 한 참조주소만 잘못되어도 잘라진 것처럼 데이터가 유실될 수 있는 위험이 있습니다.
4. 이중 연결 리스트 (Doubly Linked List)
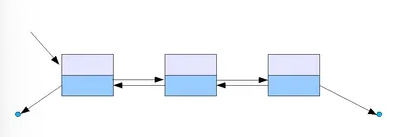
포인터 공간이 두 개이기 때문에 앞과 뒤의 노드 모두 가리킬 수 있는 리스트
4.1. 시간 복잡도
| 이중 연결 리스트 | |
|---|---|
| 접근 | O(n) |
| 검색 | O(n) |
| 삽입 | O(1) |
| 삭제 | O(1) |
-
접근, 검색 : 가장 마지막 원소를 찾으려면 배열처럼 처음부터 끝까지 찾아봐야 하기 때문에 시간복잡도는 O(n) 을 갖습니다.
하지만 이는 최악의 상황을 가정한 것이고, 만약 노드가100개인데99번째 노드에 접근하려고 한다면tail에서부터 접근하여 단 한 번의 이동만을 할 수 있습니다. -
삽입, 삭제 : 연결리스트는 포인터가 주소를 참조하여 연결되는 방식이므로 원하는 값을 삽입 또는 삭제할 때 해당 주소로 가서 바로 삽입 또는 삭제가 가능합니다. 따라서 제일 빠른 시간복잡도인 O(1) 를 갖습니다.
4.2. 단점
- 단일 연결리스트에 비해 구현이 복잡합니다.
양방향으로 접근하기 때문에 별도로 tail이라는 변수가 필요하며 양방향의 연결을 구현해야하기때문에 추가, 삭제 연산이 복잡합니다.
5. 순환 연결 리스트 (Circular linked list)
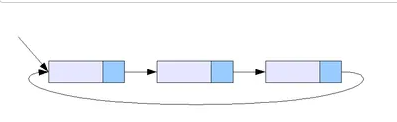
단순 연결리스트에서 마지막 포인터가 참조하는 주소를 null -> 처음 노드 주소를 가리키는 것으로 변경한 연결리스트
6. 연결 리스트 vs 배열
| 구분 | 배열 | 연결리스트 |
|---|---|---|
| 검색 | 데이터 검색 속도 빠름 | 데이터 검색 속도 느림 |
| 데이터 변경 | 데이터 추가/삭제 시 이동 | 데이터 추가/삭제 용이 |
| 기억 공간 | 정적 할당, 연속 공간 | 동적 할당, 불연속 공간 |
| 추가 기억 공간 | 추가 공간 없음 | 링크 필드 추가 |
7. 연결 리스트 활용 문제 풀어보기
Q1. 다음 함수를 실행했을 때의 결과값을 구하시오.
// listNode : [1,2,3,4,5]
void display(ListNode *h)
{
while (h != NULL) {
printf("%d ", h->data);
h = h->link;
}
printf("\n");
}Q2. 연결리스트와 배열을 비교했을 때, 각자의 빠른 연산들을 나열하시오.
- 연결리스트 :
- 배열 :
Q3. 이중 연결리스트의 네 개의 연산들 각각의 시간 복잡도를 서술하시오.
7.1. 정답
- 1 2 3 4 5
- 연결리스트(삽입/삭제), 배열(접근/검색)
- 접근검색(O(n)), 삽입삭제(O(1))
8. Reference
Linked list - Data Structure (자료구조)
나무위키 - 연결리스트
[자료구조 Java] 이중 연결리스트(Doubly Linked List) 핵심 정리
